

FPGA PCIe加速卡开源硬件及例程介绍
描述
FPGA PCIE加速卡开源硬件介绍
硬件介绍
基于Xilinx Artix-7系列FPGA芯片设计的M.2 M-Key FPGA加速卡,引出Artix7-484脚芯片的4条高速GT,最高支持PCIE2.0*4速率。高功率12A核心电源设计,可支持Artx7-XC7A35T,Artx7-XC7A50T,Artx7-XC7A75T,Artx7-XC7A100T 和Artx7-XC7A200T芯片。
加速卡板载硬件资源如图1-2所示。

图1-2 加速器板载硬件资源图
由于本PCIE加速卡只是将GT收发器以M2接口形式引出,所以可以通过M2接口座子转接出不同类型的应用底板,不局限于PCIE应用。例如SFP,USB3.0或者HDMI等。所以设计并制作了如图1-3所示的4路SFP光通信底板,可搭配用于光通信测试或是用于FPGA加速卡的供电。
例程介绍
例程没有一些低速IO口测试,主要涉及到PCIE XDMA、RIFFA(开源PCIe)、光口、SDI(规划中)、HDMI(规划中)等通过GT接口出来的高速接口测试,作者也是对例程step by step写了详细文档。下面是RIFFA的例程的摘抄:
RIFFA体系结构
RIFFA体系结构如图3-2所示。
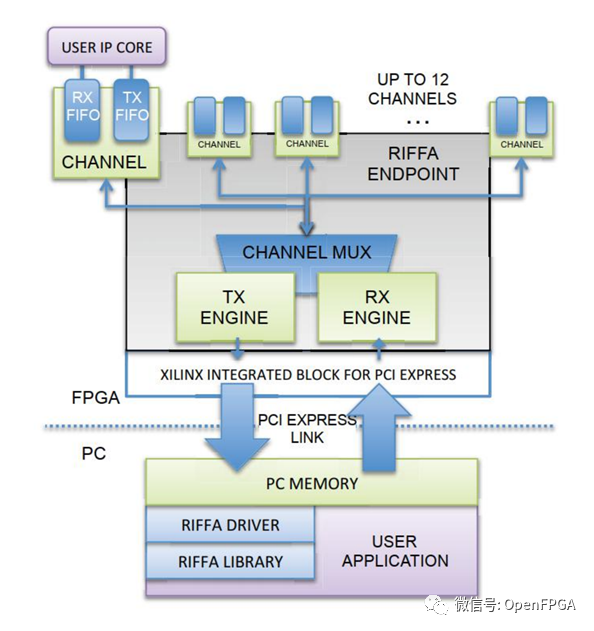
图3-2 RIFFA体系结构
在硬件方面,简化了接口,以便通过FIFO简便的将数据取出和存入。数据的传输由RIFFA的RX和TX DMA Engine模块用分散收集聚合方法来实现.RX Engin模块收集上位机传来的有效数据,收集完成发给Channel模块,TX Engin收集Channel模块传来的数据,打包发给PCI Express端点。根据PCIe链路配置,RIFFA接口支持32位,64位和128位宽度,计划为PCle Gen3端点的256位接口提供支持。
PC 接收 FPGA板卡数据是用户应用程序调用库函数 fpga_recv,然后由FPGA端启动。用户应用程序线程进入内核驱动程序,然后开始接收上游FPGA的读请求,将数据分包发送,如果没收到请求,将会等待它达到。
启动发送函数后,服务器将建立一个散列收集元素的列表,将数据存储地址和长度等信息放入其中,将其写入共享缓冲区。用户应用程序将缓冲区地址和数据长度等信息发送给FPGA。FPGA读取散射收集数据,然后发出相应地址的数据写入请求,如果散列收集元素列表的地址有多个,FPGA将通过中断发出多次请求。
TX搬移的数据全部写入缓存区后,驱动程序读取FPGA写入的字节数,确认是否与发送数据长度一致。这样就完成了传输。其过程如图3-3所示。
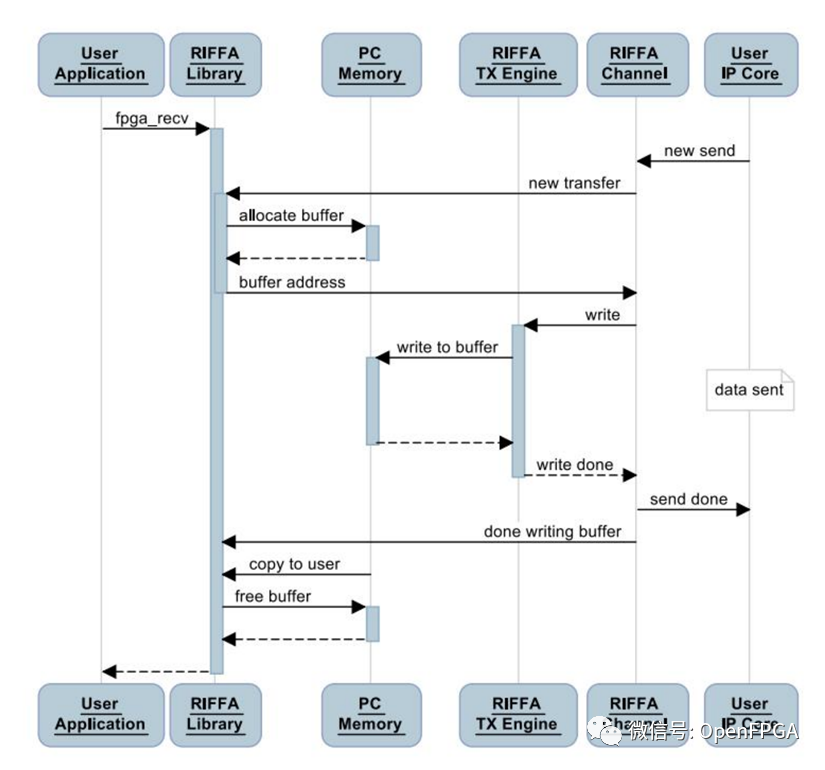
图3-3 FPGA传输到PC流程
PC 机发送数据到 FPGA 板卡过程与 PC 机接收 FPGA 板卡数据过程相似,如图3-4所示。刚开始也是用户应用程序调用库函数fpga_send,传输线程进入内核驱动程序,然后FPGA 启动传输。
启动fpga_send,服务器将申请一些空间,将要发送的数据写入其中,然后建立一个分散收集列表,将存储数据的地址和长度放入其中,并将分散收集列表的地址和要发生的数据长度等信息发给FPGA。FPGA收到列表地址后,读取该列表的信息,然后发出相应地址和长度的读请求,然后将数据存储,最后一起发给FPGA板卡。
当然后续还有光口等测试例程,就不一一展示了。
审核编辑:刘清
-
PCIe加速卡设计资料:416-基于Kintex Ultrasacle的万兆网络光纤 PCIe加速卡2026-07-09 193
-
FPGA硬件加速卡设计原理图:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡 PCIe半高 XCKU115-3-FLVF1924-E芯片2026-02-12 779
-
求一种基于Xilinx XCKU115的半高PCIe x8 硬件加速卡2021-06-25 1576
-
基于加速卡的FPGA生态系统布局是怎样的?2021-06-17 2521
-
XCKU115板卡资料:1-基于Xilinx XCKU115的半高PCIe x8 硬件加速卡2019-10-25 2995
-
基于Xilinx XCKU115的半高PCIe x8硬件加速卡2018-08-22 5124
-
基于Xilinx XCKU115的半高PCIe x8 硬件加速卡解决方案2018-07-27 6240
-
高性能FPGA计算加速卡2016-03-04 2922
全部0条评论

快来发表一下你的评论吧 !
