

Linux内核的链表数据结构
描述
Linux内核实现了自己的链表数据结构,它的设计与传统的方式不同,非常巧妙也很通用。
我们先看一下传统的定义
struct xxx{
void * p;
struct xxx * next,* prev;
}
这种方式将数据和链表指针定义在一起,整个链表也是通过整个结构体连接起来的。 这种链表不具有通用性,换一个不同的结构体需要重新定义。
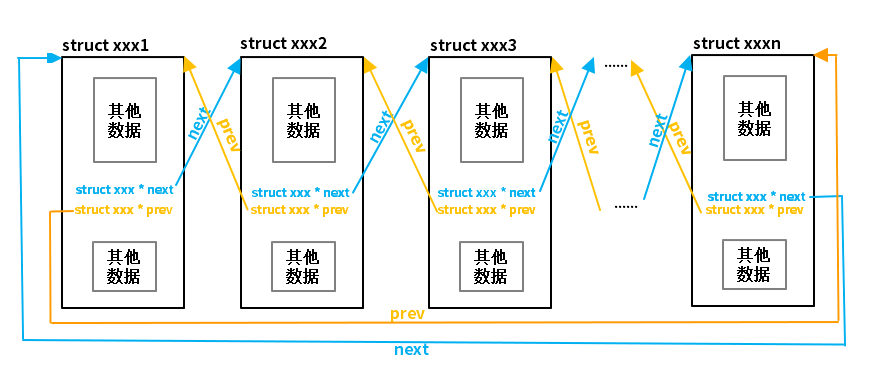
内核使用了不同的方式,它把链表的指针抽象出来,独立定义。
struct list_head{
struct list_head *next, *prev;
};
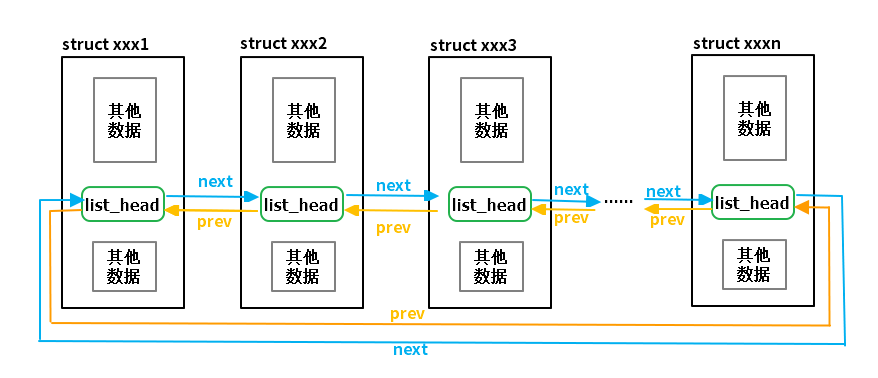
使用的时候嵌入到结构体中即可。
这种方式将数据和链表剥离开来,去除了链表和数据的耦合,这样就可以定义统一的接口,使得链表的管理和操作变得非常简洁。
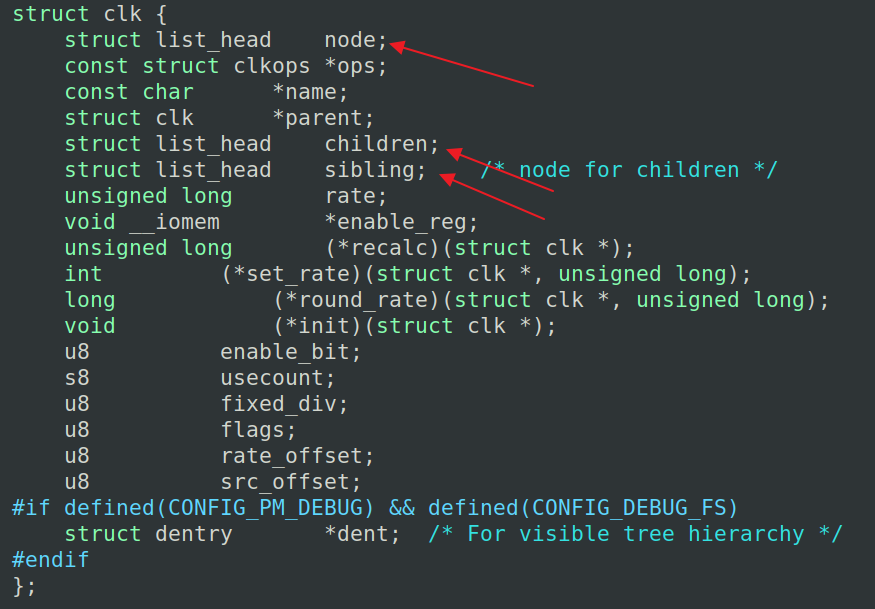
内核在
大家发现一个问题没有,我们如何获得链表所在结构体其他数据呢?
内核使用container_of()函数实现,这个函数能够通过结构体内部成员的地址找到结构体本身的地址,这样就可以通过链表的地址得到数据结构体的地址,然后就可以获得其他数据了。 这些在链表的操作方法中都已经实现了。
链表在内核中非常重要,比如所有进程就是通过链表管理,进程的子进程、兄弟进程也是链表管理,这些在进程描述符中都可以看到。
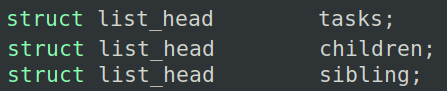
一个结构中可以包含多个不同的链表节点,分别从属于不同的链表,构成一个错综复杂的网络结构。
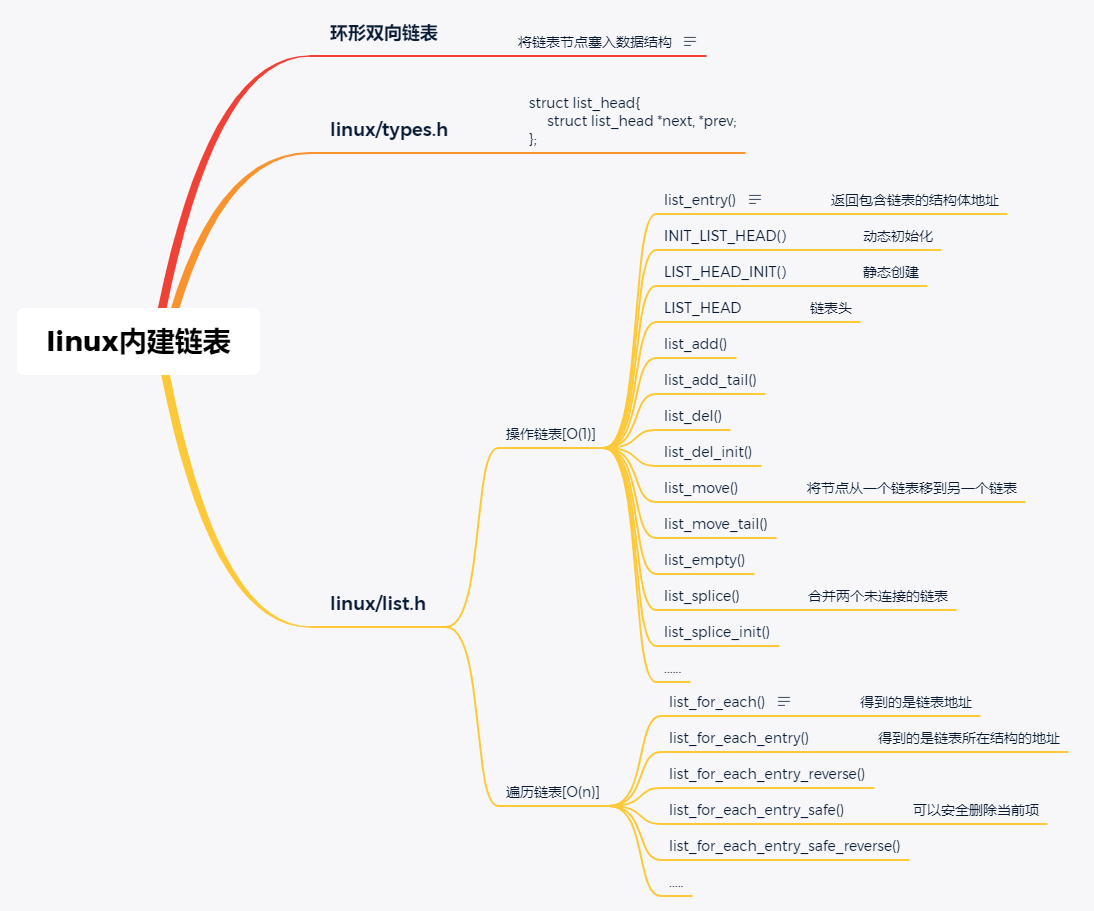
小结:
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
Linux内核中使用的数据结构2023-11-09 1456
-
Linux内核代码中常用的数据结构有哪些?2023-07-20 1098
-
数据结构中最简单的链表2023-06-13 803
-
OpenHarmony——内核IPC机制数据结构解析2022-09-05 7269
-
linux内核中llist.h文件中的链表宏讲解2022-05-23 2880
-
Linux内核中的数据结构的一点认识2022-04-20 4098
-
数据结构链表的基本操作2021-12-22 1613
-
Linux0.11-进程控制块数据结构2019-05-15 1320
-
Linux 内核数据结构:位图(Bitmap)2019-05-14 4092
-
详细介绍Linux内核链表2019-04-28 883
-
Linux Kernel数据结构:链表2018-09-25 2091
-
算法与数据结构——双向链表2017-09-19 8068
-
Linux内核的链表操作2017-08-29 3377
全部0条评论

快来发表一下你的评论吧 !
