

缓存与数据库一致性问题如何解决
电子说
描述
最近不是正好在研究 canal 嘛,刚巧前两天看了一篇关于解决缓存与数据库一致性问题的文章,里边提到了一种解决方案是结合 canal 来操作的,所以阿Q就想趁热打铁,手动来实现一下。
架构
文中提到的思想是:
- 采用先更新数据库,后删除缓存的方式来解决并发引发的一致性问题;
- 采用异步重试的方式来保证“更新数据库、删除缓存”这两步都能执行成功;
- 可以采用订阅变更日志的方式来清除 Redis 中的缓存;
基于这种思想,阿Q脑海中搭建了以下架构
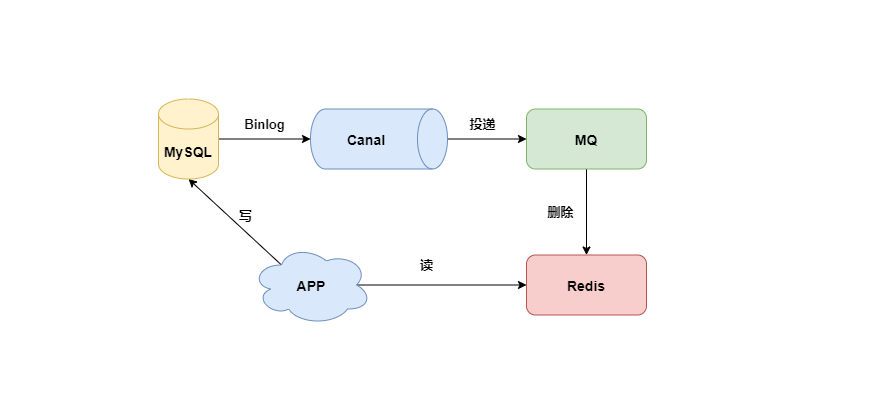
- APP 从 Redis 中查询信息,将数据的更新写入 MySQL 数据库中;
- Canal 向 MySQL 发送 dump 协议,接收 binlog 推送的数据;
- Canal 将接收到的数据投递给 MQ 消息队列;
- MQ 消息队列消费消息,同时删除 Redis 中对应数据的缓存;
环境准备
这篇文章中有 mysql 的安装教程:mysql 安装
这篇文章中有 canal 的安装教程以及对 mysql 的相关配置:canal安装
考虑到我们服务器之前安装过 RabbitMQ ,所以我们就用 RabbitMQ 来充当消息队列吧。
Canal 配置
修改 conf/canal.properties 配置
# 指定模式
canal.serverMode = rabbitMQ
# 指定实例,多个实例使用逗号分隔: canal.destinations = example1,example2
canal.destinations = example
# rabbitmq 服务端 ip
rabbitmq.host = 127.0.0.1
# rabbitmq 虚拟主机
rabbitmq.virtual.host = /
# rabbitmq 交换机
rabbitmq.exchange = xxx
# rabbitmq 用户名
rabbitmq.username = xxx
# rabbitmq 密码
rabbitmq.password = xxx
rabbitmq.deliveryMode =
修改实例配置文件 conf/example/instance.properties
#配置 slaveId,自定义,不等于 mysql 的 server Id 即可
canal.instance.mysql.slaveId=10
# 数据库地址:配置自己的ip和端口
canal.instance.master.address=ip:port
# 数据库用户名和密码
canal.instance.dbUsername=xxx
canal.instance.dbPassword=xxx
# 指定库和表
canal.instance.filter.regex=.*\\\\..* // 这里的 .* 表示 canal.instance.master.address 下面的所有数据库
# mq config
# rabbitmq 的 routing key
canal.mq.topic=xxx
然后重启 canal 服务。
数据库
建表语句
CREATE TABLE `product_info` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`price` decimal(10,4) DEFAULT NULL,
`create_date` datetime DEFAULT NULL,
`update_date` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
数据初始化
INSERT INTO cheetah.product_info
(id, name, price, create_date, update_date)
VALUES(1, '从你的全世界路过', 14.0000, '2020-11-21 21:26:12', '2021-03-27 22:17:39');
INSERT INTO cheetah.product_info
(id, name, price, create_date, update_date)
VALUES(2, '乔布斯传', 25.0000, '2020-11-21 21:26:42', '2021-03-27 22:17:42');
INSERT INTO cheetah.product_info
(id, name, price, create_date, update_date)
VALUES(3, 'java开发', 87.0000, '2021-03-27 22:43:31', '2021-03-27 22:43:34');
实战
项目引入的依赖比较多,为了不占用过多的篇幅,大家可以在公众号【阿Q说代码】后台回复“canal”获取项目源码!
MySQL 和 Redis 的相关配置在此不再赘述,有不懂的可以私聊阿Q:qingqing-4132;
RabbitMQ 配置
@Configuration
public class RabbitMQConfig {
public static final String CANAL_QUEUE = "canal_queue";//队列
public static final String DIRECT_EXCHANGE = "canal";//交换机,要与canal中配置的相同
public static final String ROUTING_KEY = "routingkey";//routing-key,要与canal中配置的相同
/**
* 定义队列
**/
@Bean
public Queue canalQueue(){
return new Queue(CANAL_QUEUE,true);
}
/**
* 定义直连交换机
**/
@Bean
public DirectExchange directExchange(){
return new DirectExchange(DIRECT_EXCHANGE);
}
/**
* 队列和交换机绑定
**/
@Bean
public Binding orderBinding() {
return BindingBuilder.bind(canalQueue()).to(directExchange()).with(ROUTING_KEY);
}
}
商品信息入缓存
/**
* 获取商品信息:
* 先从缓存中查,如果不存在再去数据库中查,然后将数据保存到缓存中
* @param productInfoId
* @return
*/
@Override
public ProductInfo findProductInfo(Long productInfoId) {
//1.从缓存中获取商品信息
Object object = redisTemplate.opsForValue().get(REDIS_PRODUCT_KEY + productInfoId);
if(ObjectUtil.isNotEmpty(object)){
return (ProductInfo)object;
}
//2.如果缓存中不存在,从数据库获取信息
ProductInfo productInfo = this.baseMapper.selectById(productInfoId);
if(productInfo != null){
//3.将商品信息缓存
redisTemplate.opsForValue().set(REDIS_PRODUCT_KEY+productInfoId, productInfo,
REDIS_PRODUCT_KEY_EXPIRE, TimeUnit.SECONDS);
return productInfo;
}
return null;
}
执行方法后,查看 Redis 客户端是否有数据存入

更新数据入MQ
/**
* 更新商品信息
* @param productInfo
* @return
*/
@PostMapping("/update")
public AjaxResult update(@RequestBody ProductInfo productInfo){
productInfoService.updateById(productInfo);
return AjaxResult.success();
}
当我执行完 update 方法的时候,去RabbitMQ Management 查看,发现并没有消息进入队列。
问题描述
通过排查之后我在服务器中 canal 下的 /usr/local/logs/example/example.log文件里发现了问题所在。
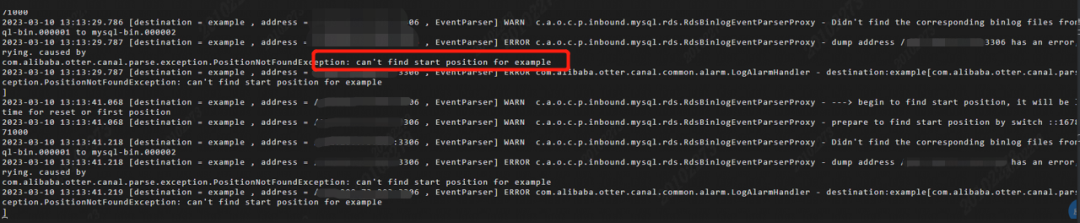
原因就是meta.dat中保存的位点信息和数据库的位点信息不一致导致 canal 抓取不到数据库的动作。
于是我找到 canal 的 conf/example/instance.properties 实例配置文件,发现没有将canal.instance.master.address=127.0.0.1:3306设置成自己的数据库地址。
解决方案
- 先停止 canal 服务的运行;
- 删除
meta.dat文件; - 再重启 canal,问题解决;
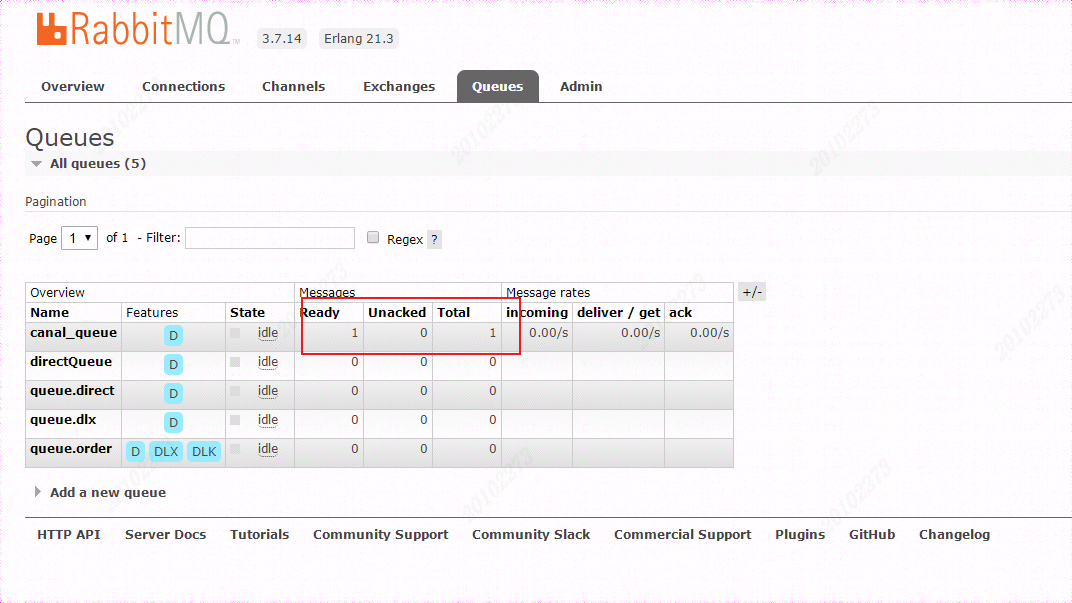
再次执行 update 方法,会发现 RabbitMQ Management中已经有我们想要的数据了。
MQ接收数据
编写 RabbitMQ 消费代码的逻辑
@RabbitListener(queues = "canal_queue")//监听队列名称
public void getMsg(Message message, Channel channel, String msg) throws IOException {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
log.info("消费的队列消息来自:" + message.getMessageProperties().getConsumerQueue());
//删除reids中对应的key
ProductInfoDetail productInfoDetail = JSON.parseObject(msg, ProductInfoDetail.class);
log.info("库名:"+ productInfoDetail.getDatabase());
log.info("表名: "+ productInfoDetail.getTable());
if(productInfoDetail!=null && productInfoDetail.getData()!=null){
List
当我们再次调用 update接口时,控制台会打印以下信息

从图中打印的信息可以看出就是我们的库和表以及消息队列,Redis 客户端中缓存的信息也被删除了。
拓展
看到这,你肯定会问:RabbitMQ 是阅后即焚的机制,它确认消息被消费者消费后会立刻删除,如果此时我们的业务还没有跑完,没来的及删除 Redis 中的缓存就宕机了,岂不是缓存一直都得不到更新了吗?
首先我们要明确的是 RabbitMQ 是通过消费者回执来确认消费者是否成功处理消息的,即消费者获取消息后,应该向 RabbitMQ 发送 ACK 回执,表明自己已经处理消息了。
为了不让上述问题出现,消费者返回 ACK 回执的时机就显得非常重要了, 而 SpringAMQP 也为我们提供了三种可选的确认模式:
- manual:手动 ack,需要在业务代码结束后,调用 api 发送 ack;
- auto:自动 ack ,由 spring 监测 listener 代码是否出现异常,没有异常则返回 ack,抛出异常则返回 nack;
- none:关闭 ack,MQ 假定消费者获取消息后会成功处理,因此消息投递后立即被删除;
由此可知在 none 模式下消息投递最不可靠,可能会丢失消息;在默认的 auto 模式下如果出现服务器宕机的情况也是会丢失消息的,本次实战中,阿Q为了防止消息丢失采用的是 manual 这种模式,配置信息如下:
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual #开启手动确认
所以在代码中也就出现了
//用于肯定确认
channel.basicAck(deliveryTag, true);
//用于否定确认
channel.basicReject(deliveryTag ,true);
当然此种模式虽然不会丢失消息,但是会导致效率变低。
-
如何解决数据库与缓存一致性2023-09-25 2084
-
理解数据库的事务:ACID,CAP和一致性2020-05-04 1523
-
如何解决stm32 H7 DMA串口发送数据一致性问题?2021-12-06 1105
-
Cache一致性协议优化研究2017-12-30 1178
-
缓存一致性问题及缓存并发问题2018-08-09 5729
-
干货:解决分布式缓存与数据库的双存储双写2020-09-03 3291
-
管理基于Cortex®-M7的MCU的高速缓存一致性2021-04-01 981
-
Redis缓存更新一致性的方式2022-11-21 1463
-
聊聊缓存数据库一致性2023-01-30 1579
-
异构数据库排序一致性填坑教程2023-03-29 2006
-
缓存与数据库双写一致性几种策略分析2023-04-21 1527
-
虹科干货 | 什么是数据库一致性?2023-07-13 1305
-
使用MPLAB Harmony v3基于PIC32MZ MCU在运行时使用高速缓存维护操作处理高速缓存一致性问题2023-09-19 573
-
如何保证缓存一致性2023-10-19 2682
-
Redis缓存与Mysql如何保证一致性?2023-12-02 1980
全部0条评论

快来发表一下你的评论吧 !
