

机器学习之关联分析介绍
电子说
描述
数据挖掘中应用较多的技术是机器学习。机器学习主流算法包括三种:关联分析、分类分析、聚类分析。本文主要介绍关联分析。
一、关联分析概述
关联分析可发现大量数据中隐藏的相关性(统计学的相关性分析不能直接发现数据中隐藏的相关性,需先人为猜测各变量间可能相关,再通过统计学计算相关性强弱),进而描述事物同时出现的规律和模式,被描述出的规律和模式可应用于市场营销、事务分析等领域。
例如:某超市可通过关联分析得出消费者购买牛奶和购买面包隐含的相关性。如果有关购买牛奶和购买面包衡量指标大于某一阈值,说明此二者相关,超市可以通过将售卖牛奶和面包的货架靠近或推出牛奶和面包的组合装促销。
二、置信度与支持度
置信度与支持度是关联分析的衡量指标。
置信度是指包含关联规则所有特征(个人理解:特征可被理解为变量,包括自变量和因变量)的数据数量占包含自变量数据数量的比例。置信度高表示关联规则所表示的自变量与因变量的相关性高。
支持度是指包含关联规则的所有特征的数据数量占总数据数量的比例。支持度高表示关联规则的出现频率高,该关联规则的重要性高。如果关联规则的置信度高,但支持度低,表示该关联规则出现频率低,重要性低,利用价值低。
关联分析需寻找支持度和置信度分别高于预先设定的支持度阈值和置信度阈值的关联规则,该种关联规则被称为强关联规则。不小于支持度阈值的关联规则被称为频繁规则,不小于支持度阈值的特征集被称为频繁项集(项集可被理解为特征集,项、特征的具象化事物可以是商品,个人理解:频繁规则和频繁项集是一种事物两个维度的表述)。
三、Apriori定律
在大数据关联分析中,如果采用枚举的方式找出所有的频繁项集,则计算效率较低。因此,关联分析可通过以下定律,简化频繁项集的确定过程。
Apriori定律1:频繁项集的子集也是频繁项集。如图一所示,如果{C,D,E}是频繁项集,意味着{C,D,E}在大数据中出现的频率不小于支持度阈值,那么其子集如{C,D}在大数据出现的频率也一定不小于支持度阈值,即为频繁项集。 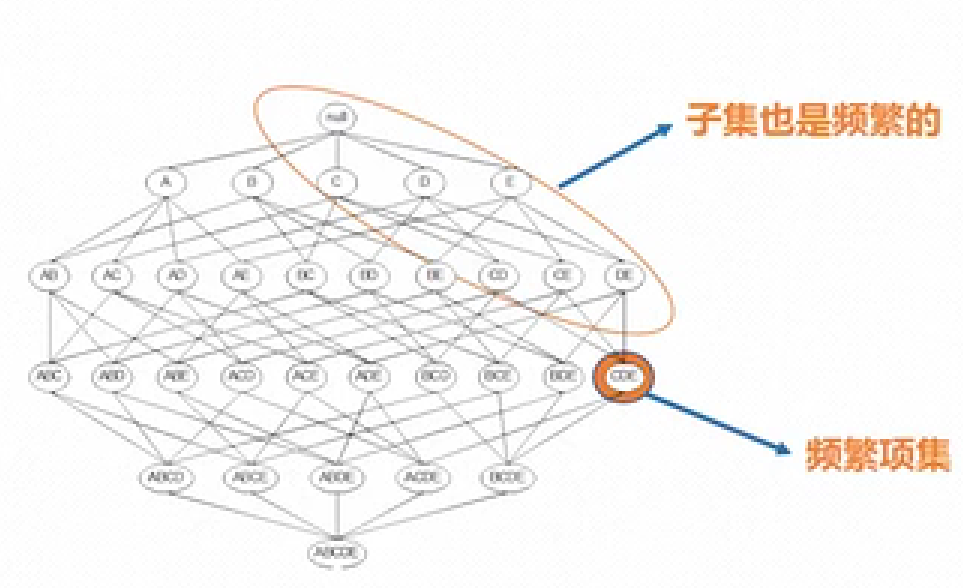
图一,图片来源:哔哩哔哩《数据科学导论》
Apriori定律2:非频繁项集的超集(个人理解:某集合的超集是包含该集合的集合)也不是频繁项集。如图二所示,如果{A,B}不是频繁项集,意味着{A,B}在大数据中出现的频率小于支持度阈值,那么其超集如{A,B,C}在大数据出现的频率也一定小于支持度阈值,即不是频繁项集。 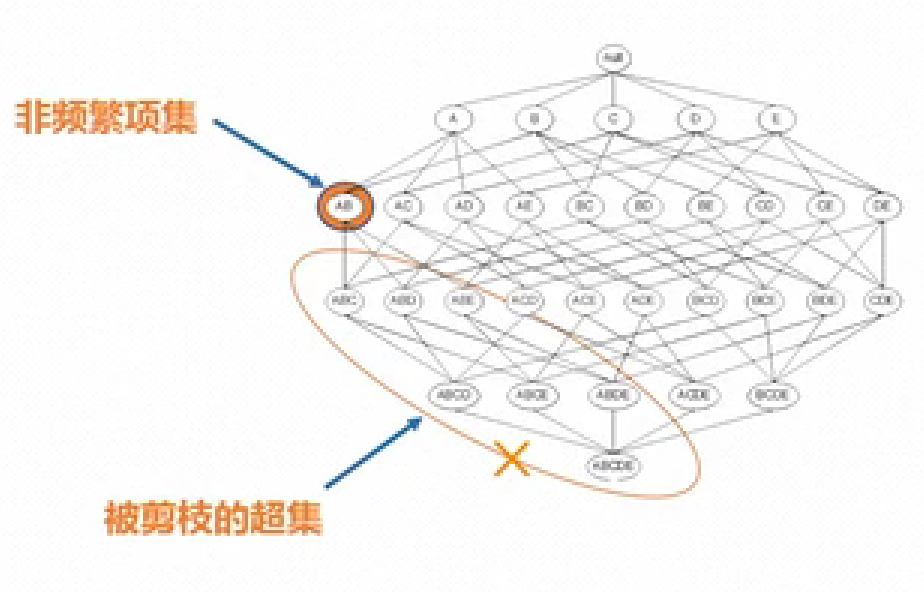
图二,图片来源:哔哩哔哩《数据科学导论》
以上两定律在Apriori算法中被应用,Apriori算法是一种关联分析算法。
四、关联规则学习步骤
(1)找出所有的频繁项集。
(2)根据频繁项集生成频繁规则。
(3)根据置信度指标进一步筛选频繁规则。
五、确定候选项集的注意事项
在选择候选项集(个人理解:候选项集指未进行置信度筛选的频繁项集)需注意:
(1)应当避免产生太多不必要的候选项集。
(2)候选项集中不遗漏频繁项集。
(3)不产生重复候选项集。
审核编辑:刘清
-
机器学习算法入门 机器学习算法介绍 机器学习算法对比2023-08-17 2104
-
机器学习之分类分析与聚类分析2023-03-27 7057
-
机器学习和预测分析两者之间如何相互关联?2022-10-25 2032
-
机器学习简介与经典机器学习算法人才培养2022-04-28 30553
-
机器学习的基础内容2022-02-09 1247
-
机器学习的基础内容介绍2022-01-12 1505
-
Python机器学习入门之pandas的使用提示2021-08-13 2091
-
机器学习KNN介绍2020-04-07 2925
-
十大机器学习算法中的线性判别分析的详细介绍2020-02-03 8282
-
深度学习与机器阅读2019-09-20 4148
-
关于机器学习的相关分析介绍2019-09-16 3443
-
对于机器学习的熟练度分析和介绍2019-09-11 3065
-
【下载】《机器学习》+《机器学习实战》2017-06-01 199245
全部0条评论

快来发表一下你的评论吧 !
