

如何使用Jina来构建一个使用Stable Diffusion生成图像的Executor呢
描述
什么是 Executor
Executor 是一个独立的 gRPC 微服务,它可以在 DocumentArray 上执行任务。Executor Hub 上有大量预构建的 Executor 可供选择,包含了各种常见的任务,如文本分类,图像识别、目标检测等。
Executor Hub: cloud.jina.ai/executors
为了让你能够更轻松地部署和管理微服务,我们正将 Executor 从 Flow 中分离出来。同时,也方便你更好地利用 Jina 的其他强大功能,比如:
利用 gRPC 和 protobuf 实现高效的网络传输和序列化,更快地处理数据和模型之间的通信;
使用 DocArray 更准确、灵活地表示多模态数据,以满足不同场景下的需求;
“Array-first”概念,将输入数据分批进行模型推理,可以大幅提高吞吐量,使你的模型处理更加高效;
轻松地将 ML 模型部署到生产环境中,享受云原生所带来的便利和丝滑。
此外,请密切关注即将推出的 Jina AI Cloud(cloud.jina.ai),在 Jina Cloud 上免费运行模型部署。
Jina 吉祥物
前段时间,我们在周五一起喝酒聊天的时候,突然聊到要不要给 Jina 选一个可爱的吉祥物,就像米其林轮胎人一样。
酒后头脑风暴之后,我们最终的决定是「彩虹独角兽蝴蝶小猫」,考虑到基因改造工程的复杂度,要怎么真正创造出这样一个神奇的新生物呢?我们决定先动手画张图:
但想一想,还有什么比使用 Jina 本身更好的方式来生成 Jina 的吉祥物呢?考虑到这一点,我们立马开发了一个图像生成的 Executor 和 Deployment。因此,在这篇文章中,我们将介绍如何将模型构建成 Executor、部署它、扩展它以及与全世界共享它。
构建 Executor
需要一个 GPU 才能在本地运行和部署这个 Executor。但你也可以调整代码,使用 Executor Hub Sandbox 版本,托管在 Jina AI Cloud上。
在 Jina 中部署服务时总是以 Executor 的形式进行。Executor是一个Python类,用于转换和处理 Document。可以将文本/图像编码为向量、OCR、从 PDF 中提取表格等等,不仅限于图像生成。
当然如果你只是想把它用起来,而不是从头开始构建它,可以直接跳到 Executor Hub 部分。
在本教程中,我们将重点关注 Executor 和 Deployment,而不会深入研究 Stable Diffusion 模型的复杂性。我们希望本教程适用于任何微服务或模型,而不是只适用特定用例。
以下大致就是我们希望 Executor 看起来的样子。用户传入提示词,Executor 使用该提示词生成图像,然后将该图像传回给用户:
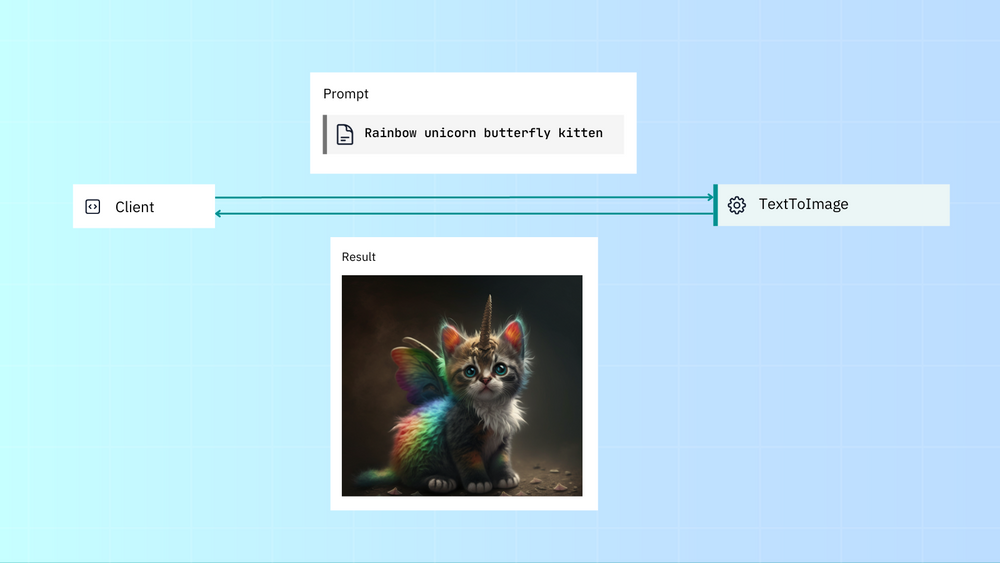
先决条件
您需要安装 Hugging Face Diffusers,pip install diffusers[torch]。
现在,让我们从整体上看一下 Executor 代码,然后逐节分析:
我们将从创建开始 text_to_image.py:
from docarray import DocumentArray
from jina import Executor, requests
import numpy as np
class TextToImage(Executor):
def __init__(self, **kwargs):
super().__init__(**kwargs)
import torch
from diffusers import StableDiffusionPipeline
self.pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
).to("cuda")
@requests
def generate_image(self, docs: DocumentArray, **kwargs):
# image here is in PIL format
images = self.pipe(docs.texts).images
for i, doc in enumerate(docs):
doc.tensor = np.array(images[i])
Imports
from docarray import DocumentArray from jina import Executor, requests import numpy as np
注:Documents 和 DocumentArrays 是 Jina 的原生 IO 格式。
Executor 类
class TextToImage(Executor):
def __init__(self, **kwargs):
super().__init__(**kwargs)
import torch
from diffusers import StableDiffusionPipeline
self.pipe = StableDiffusionPipeline.from_pretrained(
"CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
).to("cuda")
所有 Executor 都是从 Jina 的 Executor 类创建的。用户可定义的参数是方法中定义的参数__init__()。
Requests 装饰器
@requests
def generate_image(self, docs: DocumentArray, **kwargs):
# image here is in PIL format
images = self.pipe(docs.texts).images
for i, doc in enumerate(docs):
doc.tensor = np.array(images[i])
当你在一个 Executor 中定义了一个方法,并使用了 @requests 装饰器,那么你就可以通过端点调用这个方法。当你没有指定端点路径时,那么这个方法会成为默认处理程序。
这里我们没有像 @requests(on='/foo') 这样指定端点路径,只是使用了裸的 @requests,所以当调用 Executor 时,generate_image() 方法会成为默认处理程序。
部署我们的微服务
那么,现在我们有了 Executor,下一步当然就是部署啦!通过 Deployment,你可以运行和扩展 Executor,添加 replicas(副本), shards(分片) 和 dynamic batching(动态批处理)。此外,部署到 Kubernetes 或 Docker Compose 也很容易,我们将在本文后面介绍。
1. Deploy via Python API
运行 python deployment.py
from jina import Deployment
from text_to_image import TextToImage
with Deployment(uses=TextToImage, timeout_ready=-1, install_requirements=True) as dep:
dep.block()
2. Deploy via YAML
使用 CLI 运行 YAML 部署:jina deployment --uses deployment.yml
jtype: Deployment
with:
port: 12345
uses: TextToImage
py_modules:
- text_to_image.py # name of the module containing Executor
timeout_ready: -1
install_requirements: True
And run the YAML Deployment with the CLI: jina deployment --uses deployment.yml
无论您运行哪种 Deployment,您都会看到以下输出:
──────────────────────────────────────── Deployment is ready to serve! ───────────────────────────────────────── ╭────────────── Endpoint ───────────────╮ │ Protocol GRPC │ │ Local 0.0.0.0:12345 │ │ Private 172.28.0.12:12345 │ │ Public 35.230.97.208:12345 │ ╰──────────────────────────────────────────╯
与我们的微服务通信
我们可以使用 Jina Client 通过 gRPC 向我们的服务发送请求。如前所述,我们使用 Document 作为基本的 IO 格式:
运行 client.py 获得我们的梦中精灵猫。
from docarray import Document from jina import Client image_text = Document(text='rainbow unicorn butterfly kitten') client = Client(port=12345) # use port from output above response = client.post(on='/', inputs=[image_text]) response[0].display()
扩展我们的微服务
Jina 有开箱即用的可扩展功能,如副本、分片和动态批处理。这使您可以轻松增加应用程序的吞吐量。
让我们部署 Deployment,并使用副本和动态批处理对其进行扩展。我们将:
创建两个副本,每个副本分配一个 GPU。
启用动态批处理以并行处理传入同一模型的请求。
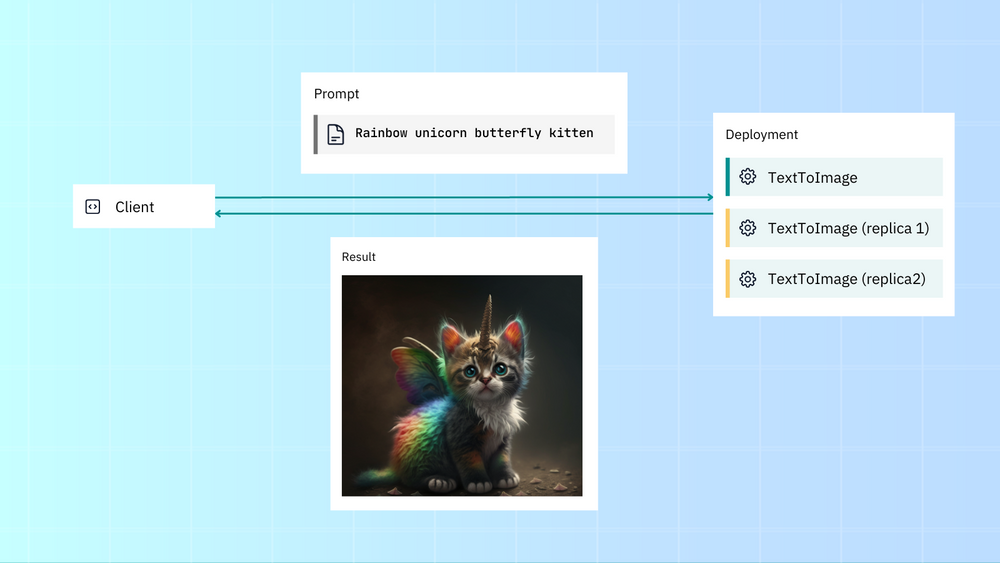
这是 Deployment 的原始(未扩展)deployment.yml:
jtype: Deployment with: timeout_ready: -1 uses: jinaai://jina-ai/TextToImage install_requirements: true
现在让我们扩大规模:
jtype: Deployment
with:
timeout_ready: -1
uses: jinaai://jina-ai/TextToImage
install_requirements: true
env:
CUDA_VISIBLE_DEVICES: RR
replicas: 2
uses_dynamic_batching: # configure dynamic batching
/default:
preferred_batch_size: 10
timeout: 200
我们通过 CUDA_VISIBLE_DEVICES添加了 GPU 支持,使用了两个副本(每个副本分配一个 GPU)和动态批处理,可以累积并批处理请求,再发送到 Executor。
假设您的机器有两个 GPU,使用扩展后的 Deployment YAML 会比普通部署获得更高的吞吐量。
感谢 YAML 语法,你可以直接注入部署配置,不用修改 Executor 代码。当然了,所有这些也可以通过 Python API 完成。
Kubernetes, Docker Compose and OpenTelemetry
使用 Kubernetes 和 Jina 很容易
jina export kubernetes deployment.yml ./my-k8s kubectl apply -R -f my-k8s
同样的,Docker Compose 也很容易
jina export docker-compose deployment.yml docker-compose.yml docker-compose up
甚至,使用 OpenTelemetry 进行 tracing(跟踪) 和 monitoring (监视) 也很简单。
from docarray import DocumentArray
from jina import Executor, requests
class Encoder(Executor):
@requests
def encode(self, docs: DocumentArray, **kwargs):
with self.tracer.start_as_current_span(
'encode', context=tracing_context
) as span:
with self.monitor(
'preprocessing_seconds', 'Time preprocessing the requests'
):
docs.tensors = preprocessing(docs)
with self.monitor(
'model_inference_seconds', 'Time doing inference the requests'
):
docs.embedding = model_inference(docs.tensors)
您可以集成 Jaeger 或任何其他分布式跟踪工具,来收集和可视化请求级别和应用级别的服务操作属性。这有助于分析请求-响应生命周期、应用程序行为和性能。要使用 Grafana,你可以下载这个 JSON 文件并导入 Grafana:
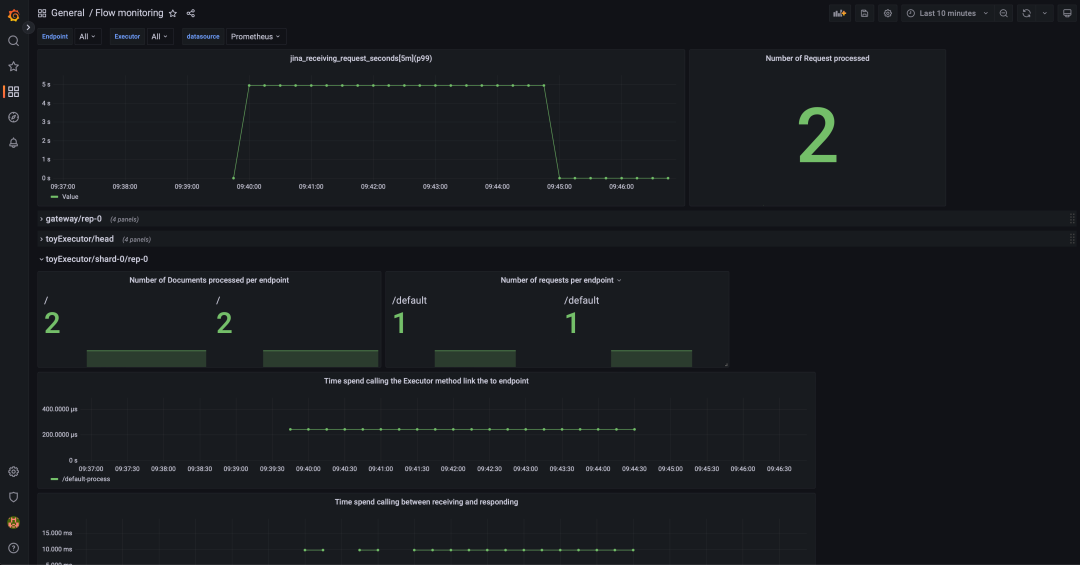
共享你的 Executor
使用 Executor Hub 共享你的 Executors 或使用公共/私有 Executors,几乎不需要担心依赖关系。
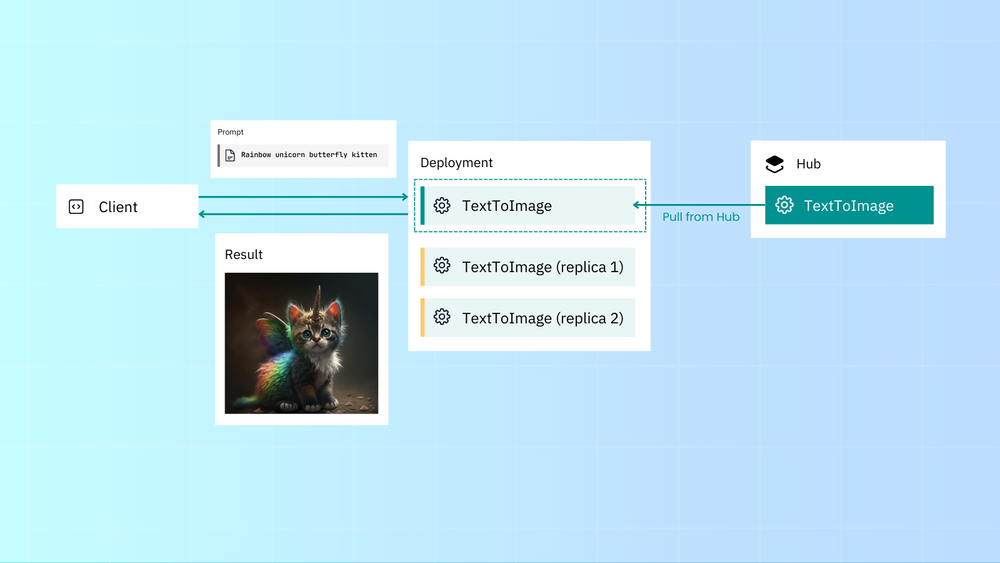
创建 Hub-ready Executor:
jina hub new
将其推送到 Executor Hub:
jina hub push
您可以通过 Python 在 Deployment 中使用 Hub Executor:
Deployment(uses='jinaai://jina-ai/TextToImage', install_requirements=True) # download and run locally Deployment(uses='jinaai+docker://jina-ai/TextToImage') # run in Docker container Deployment(uses='jinaai+sandbox://jina-ai/TextToImage') # run in hosted sandbox
或者 YAML:
uses: jinaai://jina-ai/TextToImage # download and run locally install_requirements: true uses: jinaai+docker://jina-ai/TextToImage # run in Docker container uses: jinaai+sandbox://jina-ai/TextToImage # run in hosted sandbox
Executor Hub 管理后端的所有内容,包括:
云端自动构建;
高效且经济地存储、部署和交付 Executor;
自动解决版本冲突和依赖;
通过 Sandbox 即时交付任何 Executor,而无需将任何内容 pull 到本地;
将微服务串联成 pipeline 中
有时你可能希望将微服务串联成一个 pipeline。这就是 Flow 的用武之地。我们将在以后的博客中更深入地介绍如何构建 Flow,目前您可以查看我们的 README。
Readme: get.jina.ai
总结
正如用 Executor 和 Deployment 包装微服务或模型一样,我们也必须总结这篇文章。总结一下我们所涵盖的内容:
使用 Jina,你可以将模型包装为 Executor,通过 Deployment 可以直接部署这些 Executor,或者将他们串联成 pipeline 作为 Flow 去部署。
Jina 与 Kubernetes、Docker Compose 和 OpenTelemetry 集成轻而易举。
你可以在 Executor Hub 轻松找到和共享所有内容。
如果您想继续深入了解,请查看我们的文档以获取有关 Executors 和 Deployments 的更多信息,或者使用 Jina Flows 查看 pipeline。您还可以联系我们的 Slack 社区jina.ai/community。
多多和我们互动吧!这样我们才更加有动力分享出更多好文章,未来我们将发布更多文章深入探讨作为人人可用的多模态数据平台,如何利用 Jina 地云原生,MLOps 和 LMOps 技术,让每个企业和开发者都能享受到最好的搜索和生成技术。
Jina 吉祥物之彩虹独角兽蝴蝶小猫排行榜
像所有图像生成一样,我们花了很长时间才生成一只完美的可爱小猫。
审核编辑:刘清
-
本地部署Stable Diffusion实现AI文字生成高质量矢量图片应用于电子商务2025-11-28 1097
-
如何开启Stable Diffusion WebUI模型推理部署2024-12-11 1532
-
UL Procyon AI 发布图像生成基准测试,基于Stable Diffusion2024-03-25 2070
-
韩国科研团队发布新型AI图像生成模型KOALA,大幅优化硬件需求2024-03-01 1650
-
Stability AI试图通过新的图像生成人工智能模型保持领先地位2024-02-19 1973
-
Stability AI推出Stable audio的文本到音频生成人工智能平台2023-09-20 2360
-
Stable Diffusion的完整指南:核心基础知识、制作AI数字人视频和本地部署要求2023-09-07 5029
-
树莓派能跑Stable Diffusion了?2023-07-26 2646
-
基于一种移动端高性能 Stable Diffusion 模型2023-06-12 2210
-
优化 Stable Diffusion 在 GKE 上的启动体验2023-06-03 1860
-
使用OpenVINO™在算力魔方上加速stable diffusion模型2023-05-12 2574
-
一文读懂Stable Diffusion教程,搭载高性能PC集群,实现生成式AI应用2023-05-01 3344
-
大脑视觉信号被Stable Diffusion复现图像!2023-03-16 1467
-
Stability AI开源图像生成模型Stable Diffusion2022-09-21 3929
全部0条评论

快来发表一下你的评论吧 !
