

基于GLM-6B对话模型的实体属性抽取项目实现解析
描述
Zero-shot、One-shot以及Few-shot让人傻傻分不清,读了很多文章,也没搞清楚他们的差别,究竟什么叫zero-shot,其在应用过程中的no gradient update是什么含义,zero-shot是否为一个伪命题,成为了一些有趣的问题。
目前,直接使用以chatgpt为代表的大模型进行nlp任务处理成为了一个潮流,直接拼接prompt进行问答,就可拿到相应答案,例如最近的文章《ChatGPT+NLP下的Prompt模板工具:PromptSource、ChatIE代表性开源项目介绍》中所介绍的chatie,直接来解决zeroshot的任务。
但是,我们发现,如果引入incontext-learning这一思想,作为一个fewshot任务来提升ChatIE这类模型的性能,可能是一个很好的思路,在此基础上个配上一个开源项目进行解释能够增强了解。
因此,带着这个问题,本文先谈谈Zero-shot、One-shot以及Few-shot、从ChatIE:面向REEENER三种任务的伪zero-shot prompt说起、从伪zeroshot看In-Context Learning类比学习、将In-Context Learning引入伪zero-shot完成信息抽取任务四个方面进行介绍,供大家一起参考。
一、先谈谈Zero-shot、One-shot以及Few-shot
1、Zero-shot
Zero-shot就是希望模型能够对其从没见过的类别进行分类,是指对于要分类的类别对象,一次也不学习。
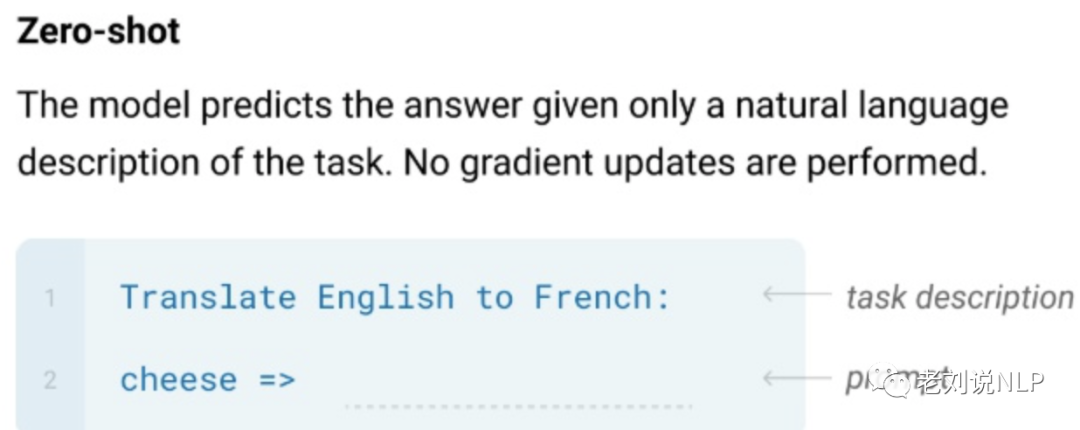
也就是说,只有推理阶段,没有训练阶段。这个常见于chatgpt中qa形式,直接通过问题prompt,基于已训练好的大模型,进行直接预测。
2、Few-shot与One-shot
如果训练集中,不同类别的样本只有少量,则成为Few-shot,如果参与训练学习,也只能使用较少的样本数。

如果训练集中,不同类别的样本只有一个,则成为One-shot, 属于Few-shot的一种特殊情况。
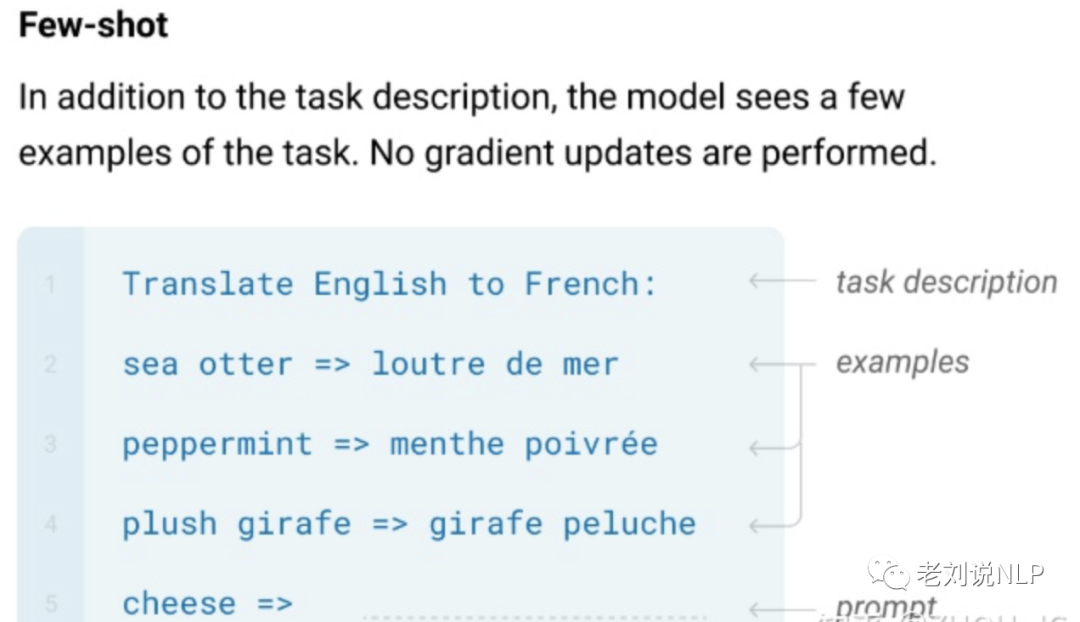
但其中的“no gradient update让人费解”,后面想了想,有2种理解:
1)单次微调,参数更新,但微调后模型不保存。
LLM由于参数量巨大,导致更新起来困难(费钱--费卡)。因此很少对训练好的LLM做微调。但是为了在特殊任务上有较好的表现(微调效果肯定要好于不微调的),但是又不固定微调后的模型,所以提出了one-shot、few-shot的方式,通过加入偏置,影响模型的最终输出。
而one-shot、few-shot可以变相的理解成用一个/多个example进行模型微调,但是微调后的模型不保存。每次提供inference都要微调一遍(输入一个example或者多个example来模拟微调过程),No gradient updates are performed.就是说提供inference的模型参数保持不变,但这其实是tuning的范畴。
2)直接不微调,参数直接不更新
如果不更新参数,那么这种学习就是瞬间的,不构成learning。预训练模型自身训练完后本身有一套参数,finetune就是在预训练基础上继续训练,肯定会有梯度更新,因为finetune后参数会变,参数变了梯度必然会更新。直接推理出答案,后台梯度也不更新。
不过,需要注意的是,如果以这个模型到底有没有见过标注样本,来划分zero-shot与其他的差别,就是主要见过,无论是在推理阶段(作为prompt)用【不更新梯度】,还是加入finetune阶段参与训练【更新参数】,那就肯定不是zero-shot,否则就是数据泄漏。
这也就是说,如果在prompt中是否加入一个或者多个正确的例子,例如分类任务中,加入一些正确的任务描述例子,都不能算作是zero-shot,但是问题是你怎么能保证模型训练没有用过这些数据,他们当时训练就可能搜集到了,模型说不定都见过,也就是说至少不存在严格意义的zero shot。
二、从ChatIE:面向REEENER三种任务的伪zero-shot prompt说起
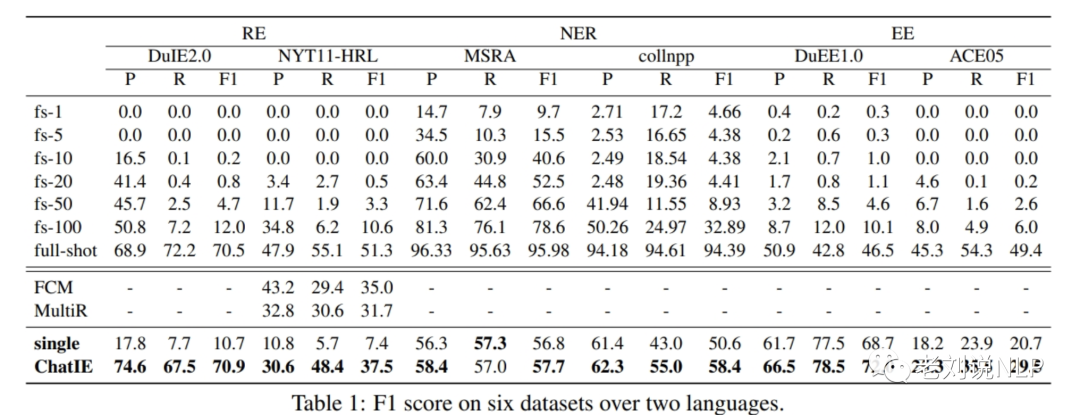
最近有篇文章《Zero-Shot Information Extraction via Chatting with ChatGPT》很有趣,该工作将零样本IE任务转变为一个两阶段框架的多轮问答问题(Chat IE),并在三个IE任务中广泛评估了该框架:实体关系三元组抽取、命名实体识别和事件抽取。在两个语言的6个数据集上的实验结果表明,Chat IE取得了非常好的效果,甚至在几个数据集上(例如NYT11-HRL)上超过了全监督模型的表现。
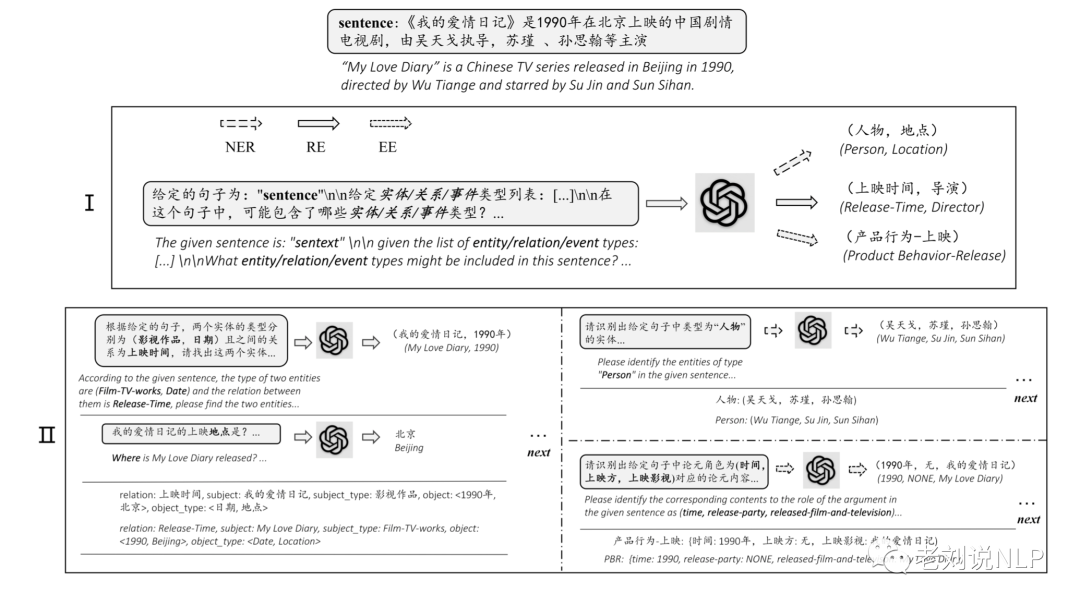
其实现基本原理为,通过制定任务实体关系三元组抽取、命名实体识别和事件抽取,并为每个任务设计了2个步骤的prompt-pattern,第一步用于识别类型,第二步用于识别指定类型的值。将抽取的任务定义(抽取要素)进行prompt填充,然后调用chatgpt接口,在取得结果后进行规则解析,结构化相应答案。
例如,关系抽取的具体执行步骤包括:针对每类prompt,分别调用prompt-pattern,得到相应结果,以事件抽取prompt为例,
1)任务要素定义:
df_eet = {
'chinese': {'灾害/意外-坠机': ['时间', '地点', '死亡人数', '受伤人数'], '司法行为-举报': ['时间', '举报发起方', '举报对象'], '财经/交易-涨价': ['时间', '涨价幅度', '涨价物', '涨价方'], '组织关系-解雇': ['时间', '解雇方', '被解雇人员'], '组织关系-停职': ['时间', '所属组织', '停职人员'], '财经/交易-加息': ['时间', '加息幅度', '加息机构'], '交往-探班': ['时间', '探班主体', '探班对象'], '人生-怀孕': ['时间', '怀孕者'], '组织关系-辞/离职': ['时间', '离职者', '原所属组织'], '组织关系-裁员': ['时间', '裁员方', '裁员人数'], '灾害/意外-车祸': ['时间', '地点', '死亡人数', '受伤人数'],
'人生-离婚': ['时间', '离婚双方'], '司法行为-起诉': ['时间', '被告', '原告'], '竞赛行为-禁赛': ['时间', '禁赛时长', '被禁赛人员', '禁赛机构'], '人生-婚礼': ['时间', '地点', '参礼人员', '结婚双方'], '财经/交易-涨停': ['时间', '涨停股票'], '财经/交易-上市': ['时间', '地点', '上市企业', '融资金额'], '组织关系-解散': ['时间', '解散方'], '财经/交易-跌停': ['时间', '跌停股票'], '财经/交易-降价': ['时间', '降价方', '降价物', '降价幅度'], '组织行为-罢工': ['时间', '所属组织', '罢工人数', '罢工人员'], '司法行为-开庭': ['时间', '开庭法院', '开庭案件'],
'竞赛行为-退役': ['时间', '退役者'], '人生-求婚': ['时间', '求婚者', '求婚对象'], '人生-庆生': ['时间', '生日方', '生日方年龄', '庆祝方'], '交往-会见': ['时间', '地点', '会见主体', '会见对象'], '竞赛行为-退赛': ['时间', '退赛赛事', '退赛方'], '交往-道歉': ['时间', '道歉对象', '道歉者'], '司法行为-入狱': ['时间', '入狱者', '刑期'], '组织关系-加盟': ['时间', '加盟者', '所加盟组织'], '人生-分手': ['时间', '分手双方'], '灾害/意外-袭击': ['时间', '地点', '袭击对象', '死亡人数', '袭击者', '受伤人数'], '灾害/意外-坍/垮塌': ['时间', '坍塌主体', '死亡人数', '受伤人数'],
'组织关系-解约': ['时间', '被解约方', '解约方'], '产品行为-下架': ['时间', '下架产品', '被下架方', '下架方'], '灾害/意外-起火': ['时间', '地点', '死亡人数', '受伤人数'], '灾害/意外-爆炸': ['时间', '地点', '死亡人数', '受伤人数'], '产品行为-上映': ['时间', '上映方', '上映影视'], '人生-订婚': ['时间', '订婚主体'], '组织关系-退出': ['时间', '退出方', '原所属组织'], '交往-点赞': ['时间', '点赞方', '点赞对象'], '产品行为-发布': ['时间', '发布产品', '发布方'], '人生-结婚': ['时间', '结婚双方'], '组织行为-闭幕': ['时间', '地点', '活动名称'],
'人生-死亡': ['时间', '地点', '死者年龄', '死者'], '竞赛行为-夺冠': ['时间', '冠军', '夺冠赛事'], '人生-失联': ['时间', '地点', '失联者'], '财经/交易-出售/收购': ['时间', '出售方', '交易物', '出售价格', '收购方'], '竞赛行为-晋级': ['时间', '晋级方', '晋级赛事'], '竞赛行为-胜负': ['时间', '败者', '胜者', '赛事名称'], '财经/交易-降息': ['时间', '降息幅度', '降息机构'], '组织行为-开幕': ['时间', '地点', '活动名称'], '司法行为-拘捕': ['时间', '拘捕者', '被拘捕者'], '交往-感谢': ['时间', '致谢人', '被感谢人'], '司法行为-约谈': ['时间', '约谈对象', '约谈发起方'],
'灾害/意外-地震': ['时间', '死亡人数', '震级', '震源深度', '震中', '受伤人数'], '人生-产子/女': ['时间', '产子者', '出生者'], '财经/交易-融资': ['时间', '跟投方', '领投方', '融资轮次', '融资金额', '融资方'], '司法行为-罚款': ['时间', '罚款对象', '执法机构', '罚款金额'], '人生-出轨': ['时间', '出轨方', '出轨对象'], '灾害/意外-洪灾': ['时间', '地点', '死亡人数', '受伤人数'], '组织行为-游行': ['时间', '地点', '游行组织', '游行人数'], '司法行为-立案': ['时间', '立案机构', '立案对象'], '产品行为-获奖': ['时间', '获奖人', '奖项', '颁奖机构'], '产品行为-召回': ['时间', '召回内容', '召回方']},
'english': {'Justice:Appeal': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Justice:Extradite': ['Agent', 'Person', 'Destination', 'Origin', 'Crime', 'Time'], 'Justice:Acquit': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Life:Be-Born': ['Person', 'Time', 'Place'], 'Life:Divorce': ['Person', 'Time', 'Place'], 'Personnel:Nominate': ['Person', 'Agent', 'Position', 'Time', 'Place'], 'Life:Marry': ['Person', 'Time', 'Place'], 'Personnel:End-Position': ['Person', 'Entity', 'Position', 'Time', 'Place'],
'Justice:Pardon': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Business:Merge-Org': ['Org', 'Time', 'Place'], 'Conflict:Attack': ['Attacker', 'Target', 'Instrument', 'Time', 'Place'], 'Justice:Charge-Indict': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Personnel:Start-Position': ['Person', 'Entity', 'Position', 'Time', 'Place'], 'Business:Start-Org': ['Agent', 'Org', 'Time', 'Place'], 'Business:End-Org': ['Org', 'Time', 'Place'],
'Life:Injure': ['Agent', 'Victim', 'Instrument', 'Time', 'Place'], 'Justice:Fine': ['Entity', 'Adjudicator', 'Money', 'Crime', 'Time', 'Place'], 'Justice:Sentence': ['Defendant', 'Adjudicator', 'Crime', 'Sentence', 'Time', 'Place'], 'Transaction:Transfer-Money': ['Giver', 'Recipient', 'Beneficiary', 'Money', 'Time', 'Place'], 'Justice:Execute': ['Person', 'Agent', 'Crime', 'Time', 'Place'], 'Justice:Sue': ['Plaintiff', 'Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'],
'Justice:Arrest-Jail': ['Person', 'Agent', 'Crime', 'Time', 'Place'], 'Justice:Trial-Hearing': ['Defendant', 'Prosecutor', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Movement:Transport': ['Agent', 'Artifact', 'Vehicle', 'Price', 'Origin'], 'Contact:Meet': ['Entity', 'Time', 'Place'], 'Personnel:Elect': ['Person', 'Entity', 'Position', 'Time', 'Place'], 'Business:Declare-Bankruptcy': ['Org', 'Time', 'Place'], 'Transaction:Transfer-Ownership': ['Buyer', 'Seller', 'Beneficiary', 'Artifact', 'Price', 'Time', 'Place'],
'Justice:Release-Parole': ['Person', 'Entity', 'Crime', 'Time', 'Place'], 'Conflict:Demonstrate': ['Entity', 'Time', 'Place'], 'Contact:Phone-Write': ['Entity', 'Time'], 'Justice:Convict': ['Defendant', 'Adjudicator', 'Crime', 'Time', 'Place'], 'Life:Die': ['Agent', 'Victim', 'Instrument', 'Time', 'Place']},
}
2)构造prompt的pattern:
ee_s1_p = {
'chinese': '''给定的句子为:"{}"
给定事件类型列表:{}
在这个句子中,可能包含了哪些事件类型?
请给出事件类型列表中的事件类型。
如果不存在则回答:无
按照元组形式回复,如 (事件类型1, 事件类型2, ……):''',
'english': '''The given sentence is "{}"
Given a list of event types: {}
What event types in the given list might be included in this given sentence?
If not present, answer: none.
Respond as a tuple, e.g. (event type 1, event type 2, ......):'''
}
ee_s2_p = {
'chinese': '''事件类型"{}"对应的论元角色列表为:{}。
在给定的句子中,根据论元角色提取出事件论元。
如果论元角色没有相应的论元内容,则论元内容回答:无
按照表格形式回复,表格有两列且表头为(论元角色,论元内容):''',
'english': '''The list of argument roles corresponding to event type "{}" is: {}.
In the given sentence, extract event arguments according to their role.
If the argument role does not have a corresponding argument content, then the argument content answer: None
Respond in the form of a table with two columns and a header of (argument role, argument content):'''
}
三、从伪zeroshot看In-Context Learning类比学习
In Context Learning(ICL)的关键思想是从类比中学习。《A Survey on In-context Learning》一文(https://arxiv.org/pdf/2301.00234.pdf)对In Context Learning(ICL)进行了综述。
该工作认为,ICL的强大性能依赖于两个阶段:(1)培养LLMsICL能力的训练阶段,以及LLMs根据特定任务演示进行预测的推理阶段。就训练阶段而言,LLMs直接接受语言建模目标的训练,如从左到右的生成,并将整个研究分成了训练和推理两个部分,如下图所示。

如下图所示:给出了一个描述语言模型如何使用ICL进行决策的例子。首先,ICL 需要一些示例来形成一个演示上下文。这些示例通常是用自然语言模板编写的。然后 ICL 将查询的问题(即你需要预测标签的 input)和一个上下文演示(一些相关的 cases)连接在一起,形成带有提示的输入,并将其输入到语言模型中进行预测。
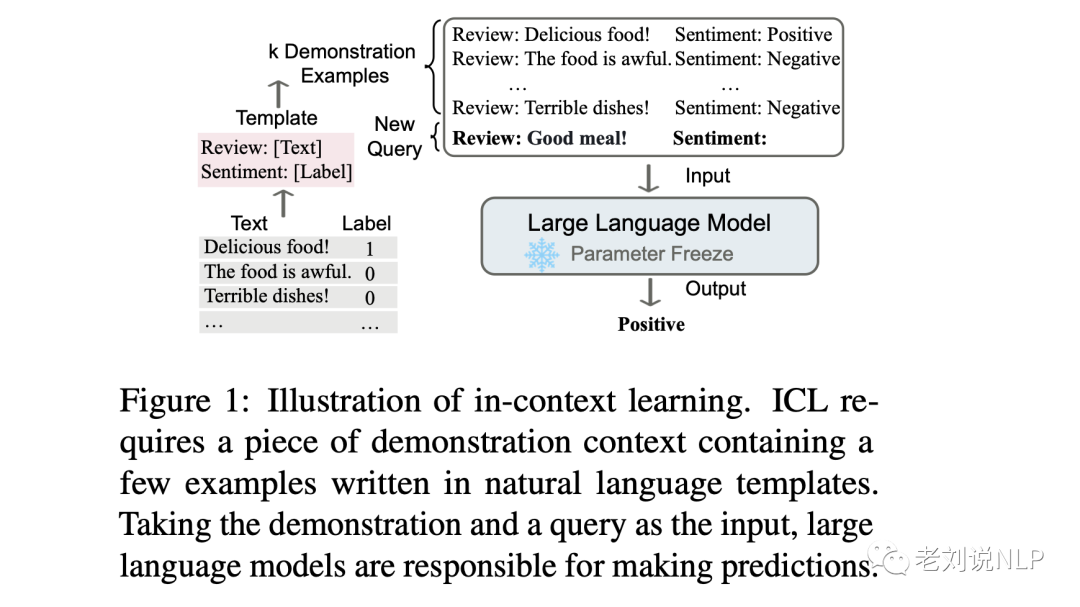
值得注意的是,首与需要使用后向梯度来更新模型参数的训练阶段的监督学习不同,ICL不进行参数更新,而是直接对语言模型进行预测。
四、将In-Context Learning引入伪zero-shot完成信息抽取任务
开源项目中,借鉴In-Context Learning思想,给出了一个基于GLM-6B的zero-shot信息抽取方案,最终效果如下:

其本质思想在于,针对zero-shot问题,使用同一个大模型,对不同任务设计其独有的 prompt,以解决不同的任务问题针对信息抽取任务,则采用2轮问答的方式进行抽取,首先进行实体类型分类,给定句子以及实体类别,要求识别出其中的实体类型,其次根据识别出的实体类型,再进行实体属性要素抽取。在构造prompt的过程中,通过列举一些正确的例子,作为In-Context Learning学习的上下文。(按照第一节的理解,这其实不能算作zero-shot,已经是fewshot)
因此,如何设计指定任务的promt,以及如何合理的引入In-Context是整个工作的一个核心。
1、调用chatglm6b进行推理抽取
加载chatglm-6b模型,对模型进行预测,下面是使用huggingface调用chatglm6b的代码:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
其中,整个history会作为一个部分,拼接进行prompt当中,从中可以看到,多轮对话最多做到8轮。
def build_prompt(history):
prompt = "欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序"
for query, response in history:
prompt += f"
用户:{query}"
prompt += f"
ChatGLM-6B:{response}"
return prompt
def main():
history = []
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
while True:
query = input("
用户:")
if query == "stop":
break
if query == "clear":
history = []
os.system(clear_command)
print("欢迎使用 ChatGLM-6B 模型,输入内容即可进行对话,clear 清空对话历史,stop 终止程序")
continue
count = 0
for response, history in model.stream_chat(tokenizer, query, history=history):
count += 1
if count % 8 == 0:
os.system(clear_command)
print(build_prompt(history), flush=True)
os.system(clear_command)
print(build_prompt(history), flush=True)
最后,我们对模型进行推理,将上述构造的两个任务作为history
def inference(sentence,custom_settings):
with console.status("[bold bright_green] Model Inference..."):
sentence_with_cls_prompt = CLS_PATTERN.format(sentence)
cls_res, _ = model.chat(tokenizer, sentence_with_cls_prompt, history=custom_settings['cls_pre_history'])
if cls_res not in schema:
print(f'The type model inferenced {cls_res} which is not in schema dict, exited.')
exit()
properties_str = ', '.join(schema[cls_res])
schema_str_list = f'“{cls_res}”({properties_str})'
sentence_with_ie_prompt = IE_PATTERN.format(sentence, schema_str_list)
ie_res, _ = model.chat(tokenizer, sentence_with_ie_prompt, history=custom_settings['ie_pre_history'])
ie_res = clean_response(ie_res)
print(f'>>> [bold bright_red]sentence: {sentence}')
print(f'>>> [bold bright_green]inference answer: ')
print(ie_res)
def test():
console = Console()
device = 'cuda:0'
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half()
model.to(device)
sentence = '张译(原名张毅),1978年2月17日出生于黑龙江省哈尔滨市,中国内地男演员。1997年至2006年服役于北京军区政治部战友话剧团。2006年,主演军事励志题材电视剧《士兵突击》。',
custom_settings = init_prompts()
inference(sentence,custom_settings
)
2、第一步:实体类型识别
先做实体类型识别(这个有点像事件抽取中的事件检测),其中需要构造
1)sentence_with_cls_prompt
sentence_with_cls_prompt = CLS_PATTERN.format(sentence),先对句子进行实体类型识别,构造prompt:
CLS_PATTERN = f"“{{}}”是 {class_list} 里的什么类别?"
例如,针对句子:“张译(原名张毅),1978年2月17日出生于黑龙江省哈尔滨市,中国内地男演员。1997年至2006年服役于北京军区政治部战友话剧团。2006年,主演军事励志题材电视剧《士兵突击》。”
构造prompt后变为:
“张译(原名张毅),1978年2月17日出生于黑龙江省哈尔滨市,中国内地男演员。1997年至2006年服役于北京军区政治部战友话剧团。2006年,主演军事励志题材电视剧《士兵突击》。”是 ['人物', '书籍', '电视剧'] 里的什么类别?
2)cls_pre_history实体类型识别的例子
利用cls_pre_history作为incontext-learning学习的上下文,进行拼接,例如,cls_pre_history形式为:
cls_pre_history:
[
("现在你是一个文本分类器,你需要按照要求将我给你的句子分类到:['人物', '书籍', '电视剧']类别中。", '好的。'),
(
"“岳云鹏,本名岳龙刚,1985年4月15日出生于河南省濮阳市南乐县,中国内地相声、影视男演员。2005年,首次登台演出。2012年,主演卢卫国执导的喜剧电影《就是闹着玩的
》。2013年在北京举办相声专场。”是 ['人物', '书籍', '电视剧'] 里的什么类别?",
'人物'
),
(
"“《三体》是刘慈欣创作的长篇科幻小说系列,由《三体》《三体2:黑暗森林》《三体3:死神永生》组成,第一部于2006年5月起在《科幻世界》杂志上连载,第二部于2008年5
月首次出版,第三部则于2010年11月出版。”是 ['人物', '书籍', '电视剧'] 里的什么类别?",
'书籍'
),
(
"“《狂飙》是由中央电视台、爱奇艺出品,留白影视、中国长安出版传媒联合出品,中央政法委宣传教育局、中央政法委政法综治信息中心指导拍摄,徐纪周执导,张译、
张颂文、李一桐、张志坚、吴刚领衔主演,倪大红、韩童生、李建义、石兆琪特邀主演,李健、高叶、王骁等主演的反黑刑侦剧。”是 ['人物', '书籍', '电视剧'] 里的什么类别?",
'电视剧'
)
]
3、第2步:实体属性抽取
根据识别的实体类型结果做实体属性抽取(这个有点像事件抽取中的事件要素抽取),
根据上一步得到的实体类型,进一步生成问句sentence_with_ie_prompt和in-context learning上下文,其中:
1)sentence_with_ie_prompt
sentence_with_ie_prompt指的是对任务的描述,其中需要用到不同实体对应的属性schema以及问题的promt模版。
schema如下:
schema = {
'人物': ['姓名', '性别', '出生日期', '出生地点', '职业', '获得奖项'],
'书籍': ['书名', '作者', '类型', '发行时间', '定价'],
'电视剧': ['电视剧名称', '导演', '演员', '题材', '出品方']
}
属性抽取的prompt如下:
IE_PATTERN = "{}
提取上述句子中{}类型的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。"
变成:
张译(原名张毅),1978年2月17日出生于黑龙江省哈尔滨市,中国内地男演员。1997年至2006年服役于北京军区政治部战友话剧团。2006年,主演军事励志题材电视剧《士兵突击》。 提取上述句子中“人物”(姓名, 性别, 出生日期, 出生地点, 职业, 获得奖项)类型的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。
2)ie_pre_history属性抽取的例子
ie_pre_history属性抽取的例子给定了一些正确抽取的实际例子,如下所示:
[
(
"现在你需要帮助我完成信息抽取任务,当我给你一个句子时,你需要帮我抽取出句子中三元组,并按照JSON的格式输出,上述句子中没有的信息用['原文中未提及']来表示,多
个值之间用','分隔。",
'好的,请输入您的句子。'
),
(
"岳云鹏,本名岳龙刚,1985年4月15日出生于河南省濮阳市南乐县,中国内地相声、影视男演员。
提取上述句子中“人物”(姓名, 性别, 出生日期, 出生地点, 职业,
获得奖项)类型的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'{"姓名": ["岳云鹏"], "性别": ["男"], "出生日期": ["1985年4月15日"], "出生地点": ["河南省濮阳市南乐县"], "职业": ["相声演员", "影视演员"], "获得奖项":
["原文中未提及"]}'
),
(
"《三体》是刘慈欣创作的长篇科幻小说系列,由《三体》《三体2:黑暗森林》《三体3:死神永生》组成,第一部于2006年5月起在《科幻世界》杂志上连载,第二部于2008年5月首
,第三部则于2010年11月出版。
提取上述句子中“书籍”(书名, 作者, 类型, 发行时间,
定价)类型的实体,并按照JSON格式输出,上述句子中不存在的信息用['原文中未提及']来表示,多个值之间用','分隔。",
'{"书名": ["《三体》"], "作者": ["刘慈欣"], "类型": ["长篇科幻小说"], "发行时间": ["2006年5月", "2008年5月", "2010年11月"], "定价": ["原文中未提及"]}'
)
]
3、第三步:对模型输出进行后处理
def clean_response(response: str):
if '```json' in response:
res = re.findall(r'```json(.*?)```', response)
if len(res) and res[0]:
response = res[0]
response.replace('、', ',')
try:
return json.loads(response)
except:
return response
总结
本文先谈谈Zero-shot、One-shot以及Few-shot、从ChatIE:面向REEENER三种任务的伪zero-shot prompt说起、从伪zeroshot看In-Context Learning类比学习、将In-Context Learning引入伪zero-shot完成信息抽取任务四个方面进行介绍,供大家一起参考。
审核编辑:刘清
-
利用OpenVINO部署GLM-Edge系列SLM模型2024-12-09 3180
-
智能硬件接入主流大模型做语音交互(附文心一言、豆包、kimi、智谱glm、通义千问示例)2024-08-21 14350
-
【附实操视频】聆思CSK6大模型开发板接入国内主流大模型(星火大模型、文心一言、豆包、kimi、智谱glm、通义千问)2024-08-22 4166
-
中文专利属性值对抽取技术及应用2017-12-01 799
-
基于远距离监督和模式匹配的属性抽取方法2017-12-23 1397
-
基于WebHarvest的健康领域Web信息抽取方法2017-12-26 928
-
节点属性的海量Web信息抽取方法2018-02-06 1026
-
模型NLP事件抽取方法总结2020-12-31 11120
-
借助局部实体特征的事件触发词抽取方法2021-05-26 1181
-
实体关系抽取模型CasRel2022-07-21 5369
-
如何用一种级联的并解决嵌套的实体的三元组抽取模型?2023-02-08 2193
-
ChatGLM-6B的局限和不足2023-06-25 6553
-
智谱AI发布全新多模态开源模型GLM-4-9B2024-06-07 1795
-
智谱GLM-Zero深度推理模型预览版正式上线2025-01-02 1249
全部0条评论

快来发表一下你的评论吧 !
