

最全计算机网络发展编年史:TCP/IP协议与Internet的诞生
通信网络
描述
作者:范桂飓,AWS Community Builder,EdgeGallery 开源社区成员。
自 2006 年以来,SDN 技术发展了近二十年,从狭义的OpenFlow SDN,到广义的SDN,再到现如今的P4 完全可编程网络,期间的纷纷扰扰乱入迷人眼,偶尔让人感到迷茫徘徊:网络何以至此?网络到底要如何发展?不妨让我们从网络的起源开始回顾历史,拨开云雾看清网络的初心与未来。
01
从冷战背景说起
第二次世界大战以后,当时的美国和苏联同为世界上的 “超级大国”,为了争夺世界霸权,一道铁幕在欧洲大陆落下,两国及其盟国展开了数十年的斗争。在这段时期,虽然双方分歧和冲突严重,但都尽力避免新一轮的世界范围战争(第三次世界大战),其对抗通常通过局部代理战争、科技和军备竞赛、太空竞赛、外交竞争等 “冷”方式进行,即“相互遏制,不动武力”,因此称之为 “冷战”。
02
APRA 成立
1957 年 10 月 4 日,苏联发射了人类第一颗人造卫星,斯普特尼克一号。这颗卫星的升空,轰动了整个世界,也让当时的美国政府震惊不已。他们恐惧,在日趋激烈的冷战对抗中,自己已经全面落后于苏联。
为了扭转这一局面,美国总统艾森豪威尔(Dwight D. Eisenhower)授权美国国防部于 1958 年 2 月组建了 APRA(Advanced Research Project Agency,美国国防部高级研究计划局)科研部门。ARPA 的主要工作,就是研究如何将那些具有潜在军事价值的 “黑科技”,应用于军事领域,包括弹道导弹防御、卫星导航、核试验检测等等。
1961 年 10 月,苏联成功发射 R-16 洲际导弹,结合 1949 年 8 月成功爆破的原子弹,这意味着美国本土正面临远程核导弹打击的威胁。为了保证自己能在苏联的第一轮核打击下具备一定的生存和反击能力,美国国防部授权 APRA 研究一种 “分布式“ 的指挥系统。它由无数的节点组成,当若干节点被摧毁后,其它节点仍能相互通信。
从此,ARPA 的核心项目之一就是建立一个可经受敌军打击的军用通信系统。
03
ARPANET 项目启动
这个任务最早交到 ARPA IPTO(Information Processing Techniques Office,信息处理技术办公室)负责。
1966 年,来自 NASA(美国航空航天局)的罗伯特·泰勒(Robert Taylor),成为 ARPA IPTO 的第三任主管。罗伯特·泰勒在上任后考察了 IPTO 当时构建的一个小型通信网络之后(由三个电传打字机和三台计算机组成),认为不兼容的计算机通信没有任何意义,应该建立一个兼容的协议,允许所有终端之间互相通信。并很快就完成了新型通信网络项目的内部立项,ARPA 将其命名为 ARPANET(阿帕网)。
为了完成 ARPANET 项目,罗伯特·泰勒到处搜罗人才,其中包括:
• 麻省理工学院(MIT)林肯实验室的拉里·罗伯茨(Lawrence G. Roberts);
• 提出 “分布式通信理论” 的兰德公司科学家保罗.巴兰(P.Baran);
• 美国加州大学洛杉矶分校(UCLA)的分组交换理论专家伦纳德.克兰罗克(L.Kleinrock);
其中,保罗.巴兰的 “分布式通信理论” 提出了 2 个重要思想:
• 网络的控制权应该完全分散;
• 网络应该采用分组交换(Packet switching)替代电路交换(Circuit Switching)。
分布式通信理论的思想让每个节点在进行数据路由时都具备同等地位,这成为未来互联网的最根本特征。
另外,拉里·罗伯茨(Larry Roberts)则被任命为 ARPANET 项目的项目经理和首席架构师。
1967 年 4 月,在美国密歇根州安娜堡召开的 ARPA IPTO PI 会议上,拉里·罗伯茨组织了有关 ARPANET 设计方案的讨论。不久后就发表第一篇关于 ARPANET 设计的论文《Multiple Computer Networks and Intercomputer Communication》(多计算机网络和计算机之间的通信)。
在罗伯茨的设计中,主机不应该处理数据路由的任务,这个任务应该由一个小型的廉价计算机来承担,命名为 IMP(Interface Message Processor,接口信号处理机)。
IMP 的作用是连接、调度和管理。主机把数据包发给 IMP,IMP 查看目标地址,或者把它传递到本地连接的主机,或者传递给另外一个 IMP。有了它,大型主机就不必 “亲自” 参与联网,从根本上解决了计算机系统不兼容的问题。后来,人们普遍将 IMP 视为路由器的雏形。
为了防止数据包丢失,Sender IMP 会暂存数据包,直到获得 Receiver IMP 的 ACK 确认为止,如果没能收到确认,它就重新发送。在那时,ACK 重传机制还是由中间路由节点来完成的,后面才逐步演进到由主机 TCP/IP 协议栈来完成。
1968 年,拉里·罗伯茨在研究报告《资源共享的计算机网络》中,着力阐述了让 ARPA 的计算机互相连接,从而使大家分享彼此的研究成果。同年夏天,美国国防部正式启动了 ARPANET 项目的商业招标。
04
ARPANET 的诞生
1969 年 1 月,来自马萨诸塞州坎布里奇市的 BBN(Bolt Beranek and Newman Inc.)公司赢得了这个价值 100 万美元的合同。同年,ARPA 建立了 IMP 的研发测试中心,IMP 的基础硬件是配有 12K Memory 的 Honeywell DDP-516 小型计算机。
• IMP 设备内部
• IMP 设备面板
项目的第一阶段,拉里·罗伯茨计划在美国西南部建立一个四节点的网络。节点分别是加州大学洛杉矶分校、斯坦福大学研究学院、加州大学圣巴巴拉分校和犹他州大学的 4 台大型计算机。
这 4 个节点之间,采用分组交换技术,通过专门的 IMP 设备和由 AT&T 公司提供的、速率为 50kbps 的通信线路进行连接。
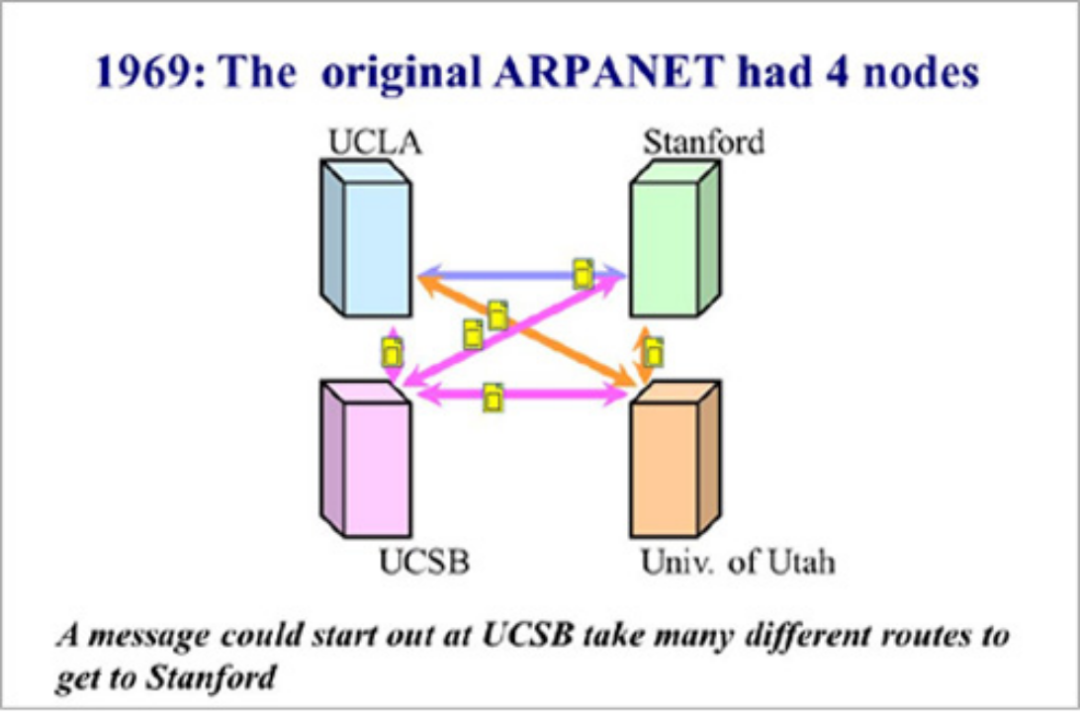
1969 年 8 月 30 日,来自 BBN 公司的第一台 IMP 运抵加州大学洛杉矶分校。校内的伦纳德.克兰罗克教授带着 40 多名工程技术人员和研究生进行安装和调试。
此后不久,被公认对 ARPANET 建成作出了巨大贡献的,来自 BBN 公司的鲍伯·卡恩(Bob Kahn,也称为:罗伯特·卡恩,Robert Elliot Kahn)也来到了加州大学洛杉矶分校,加入到 ARPANET 项目中。
• 加州大学洛杉矶分校现场机房
1969 年 10 月,第二台 IMP 运抵斯坦福大学研究院。
10 月 29 日晚,伦纳德.克兰罗克教授安排他的助理、UCLA 大学本科生查理·克莱恩(Charley Kline)坐在 IMP 终端前,与 SRI 终端操作员进行对接。当时,查理·克莱恩戴着头戴式耳机和麦克风,以便通过长途电话随时与对方联系。
据查理·克莱恩回忆,伦纳德.克兰罗克教授那天让他首先传输 LOGIN(登录)这 5 个英文字母 ,以确认分组交换技术的传输效果。根据事前约定,他只需要键入 LOG 这 3 个字母传送出去,然后斯坦福那边的主机就会自动产生 IN 这两个字母,合成为 LOGIN。以此验证 2 个节点之间的通信成功。
随后,1969 年 11 月,第三台 IMP 抵达加州大学圣巴巴拉分校。
1969 年 12 月,最后一台 IMP 在第四节点犹他大学安装成功。
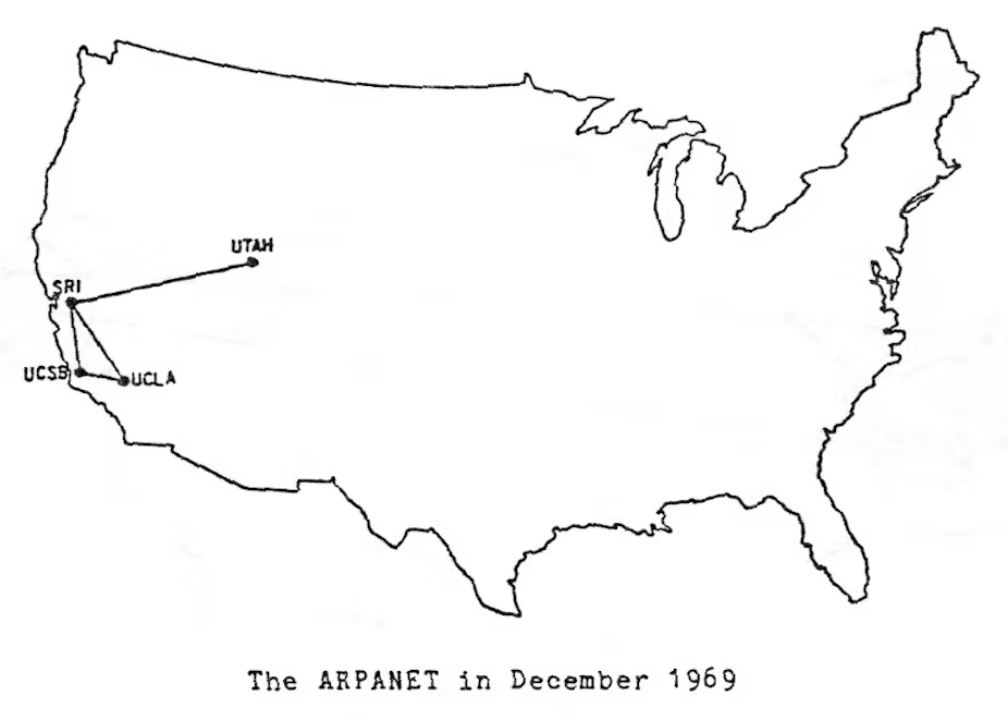
至此,第一个 ARPANET 就在 1969 年诞生了,将加利福尼亚州大学洛杉矶分校、加州大学圣巴巴拉分校、斯坦福大学、犹他州大学四所大学的 4 台大型计算机进行了互联。人类社会开始进入 “网络时代”。
05
TCP/IP 协议与 Internet 的诞生
在运行 ARPANET 不久后,大家才发现各个 IMP 在进行连接的时候,需要考虑使用一种 4 台 IMP 都能够统一识别的信号来作为开发和关闭通信管道,否则这些 IMP 不会知道什么时候应该接收信号,什么时候该结束。
对于这个问题,实际上在 1968 年 ARPANET 项目刚启动的时候,拉里·罗伯茨就成立了一个专门的研究小组,名为 NWG(Network Working Group),由 史蒂夫·克罗克(Steve Crocker)担任组长。这个小组试图通过编写主机与主机之间的通信软件来解决这个问题。
1970 年 12 月,NWG 通过软件的方式实现了最初的 ARPANET 通信协议,称为 NCP(网络控制协议)。
1972 年,鲍伯·卡恩在国际计算机通信大会(ICCC)上成功演示了 ARPANET 网络,那是 ARPANET 的首次公开亮相。经过几年的发展,在当年 ARPANET 已经拥有了 40 个节点,E-mail、FTP 和 Telnet 是当时最主要的网络应用。尤其是 E-mail,占据了 75% 的流量。
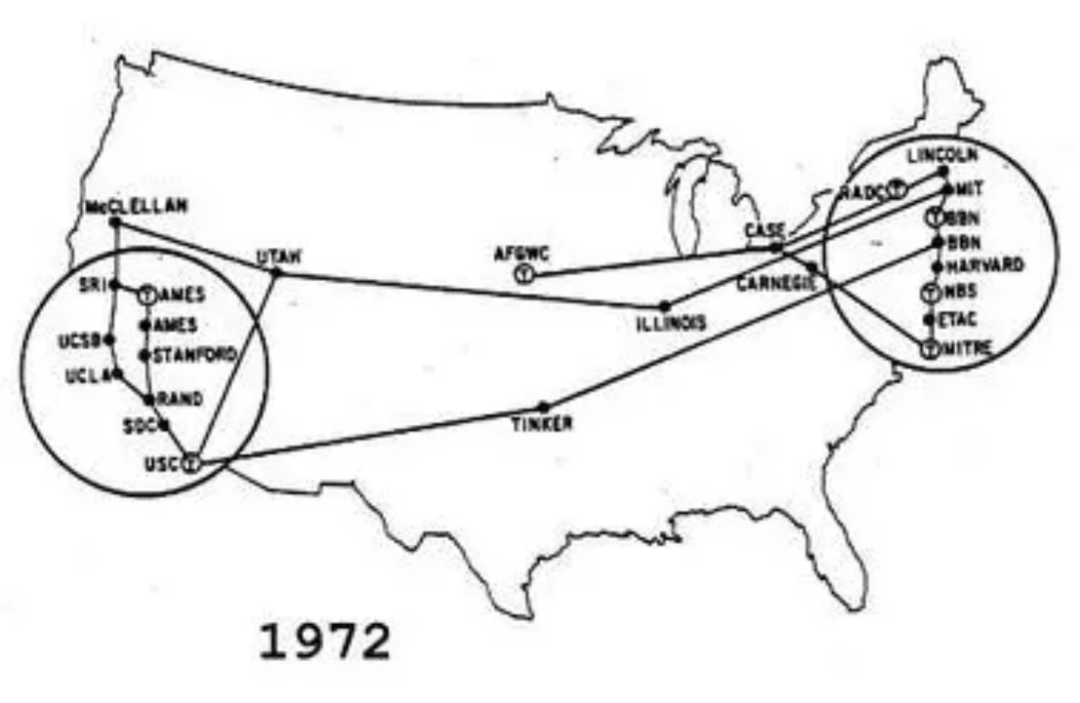
在 ARPANET 成功的激励下,计算机网络领域开始渐渐出现了其他的一些网络类型,例如:夏威夷建立了无线电网络,硅谷发明了以太网络,太空卫星也组建了卫星网络等等。
1973 年,ARPANET 通过卫星通信实现了与夏威夷、英国伦敦大学和挪威皇家雷达机构的联网。ARPANET 从美国本地互联网络逐渐进化成为了一张国际性的互联网络。
随着 ARPANET 的发展和用户对网络需求的不断提高,人们开始发现 NCP 协议存在着很多的缺点,比如 NCP 只能在同构环境中运行(指网络上的所有计算机都运行着相同的操作系统),又比如 NCP 支持的主机数量有限。对于一个分布广泛的网络而言,这些缺陷就必然成为了发展路上最大障碍。
1973 年,针对 NCP 协议存在的问题,鲍伯·卡恩认识到只有在深入理解了各种操作系统细节的基础上,才能建立一种对各种操作系统都使用的协议。于是鲍伯·卡恩提出了 “开放的网络架构” 思想。同年,来自斯坦福大学的温顿.瑟夫(Vinton G. Cerf)加入 ARPA,并负责领导基于 NWG 改建的 INWG 工作组。顺理成章的,鲍伯·卡恩邀请温顿.瑟夫一起研究新协议的各个细节,并在不久就共同提出了 TCP 传输协议。
为了验证 TCP 协议的可用性,INWG 开始试验基于 TCP 协议 Client 软件将一个数据发送到距离 10 万公里外的 Server。结果观察数据在传输过程中没有任何丢失,TCP 协议的可行性得到了验证,也一度引起相关领域的广泛关注。
1977 年,APRA 改建的 DARPA(美国国防部高级研究计划署)与 BBN 公司、斯坦福大学和伦敦大学学院签订商业合同,正式开始在不同的 CPU 硬件平台上开发 TCP 协议的验证版本:TCPv1 和 TCPv2。
随后 1977 年 11 月,鲍伯·卡恩和温顿.瑟夫给予 TCPv2 完成了一个具有里程碑意义的实验。数据包从一辆载有无线传输器的箱式货车发出,进入 APRANET,然后通过专用卫星链路到达伦敦,再通过卫星传输网络,到达 APRANET, 最后传回南加州大学信息科学研究所,行程 9.4 万英里,没有丢失一个比特的数据信息。
同时这也让很多组织机构见识到了计算机联网的重要性,纷纷开展研究。全球涌现了大量的新型网络,例如:计算机科学研究网络 CSNET、加拿大网络 CDnet、因时网 BITNET 等。
1978 年,温顿·瑟夫、鲍伯·卡恩、丹尼·科恩(Danny Cohen)和约翰·普斯特尔(Jon Postel)合力将 TCP 协议从分层思想的角度划分为 2 个协议,即:
1、传输层的 TCP 协议,负责可靠传输。
2、网络层的 IP 协议,负责在不同的网络之间进行互联。
它们合称 TCP/IPv3,并在不久的将来演进为稳定版本 TCP/IPv4。
• 温顿.瑟夫
• TCP/IP,现代 Internet 的基石。
1980 年,DARPA 开始研究如何将不同的网络类型连接起来,并启动了 The Interneting Project(互联网技术)项目。这个项目让刚刚崭露头角的 TCP/IPv4 协议获得了施展空间。
1981 年,DARPA 资助 BBN 公司和加州大学伯克利分校,把 TCP/IP 协议实现到 UNIX 操作系统。值得一提的是,当时还在上研究生的天才程序员 Bill Joy 对 TCP/IP 协议深感兴趣,但却对 BBN 提供的代码深痛欲绝。于是 Bill Joy 另起炉灶,只用了几天时间就在 BSD UNIX 发行版中实现了一个高性能的 TCP/IP 协议栈。当然那时的 TCP/IP 协议很很简单,但 BSD Socket 直到今天还在发挥着余热。
1982 年,ARPANET 开始采用 TCP/IP 协议替代 NCP 协议。
1983 年,美国国防部将 ARPANET 划分为军用和民用两部分。
1984 年, TCP/IP 协议得到美国国防部的肯定,成为计算机领域共同遵守的一个主流标准。
至此,基于 IP(Internet Protocol)协议标准的 Internet 诞生了。鲍伯·卡恩和温顿·瑟夫也因此被誉为 “互联网之父”。
实际上,TCP/IP 协议的发展也并非一帆风顺,其中最大的竞争对手就是国际标准化组织(ISO)。ISO 在制定国际化标准上经验十足,很快就提出了 OSI 七层模型,并大力推广。
面对挑战,那时温顿.瑟夫努力劝说让 IBM、DEC、HP 等主机大厂支持 TCP/IP 协议,但都遭到了拒绝。因为在他们看来 TCP/IP 只是一届研究项目,无力与在商业社会中获得过巨大成功的 ISO 抗衡。
而美国国防部的应对策略则是将 TCP/IP 协议与 UNIX 系统、C 语言捆绑在一起,并由 AT&T 向美国各个大学发放非商业许可证。这样才迫使这些跟 UNIX 系统有紧密联系的企业转向 TCP/IP 的怀抱。这为 UNIX 系统、C 语言、TCP/IP 协议的发展拉开了序幕,它们分别在操作系统、编程语言、网络协议这 3 个关键领域影响至今。
1985 年,TCP/IP 协议栈成为 UNIX 操作系统密不可分的组成部分。UNIX 的广泛传播也极大助力了 TCP/IP 的发展。后来,几乎所有的操作系统都开始支持 TCP/IP 协议。经典的 TCP/IP 五层模型已成气候。
后来,美国国家科学基金会(NSF)自己出资,基于 TCP/IP 协议,建立完全属于自己的 NSFnet 广域网。
NSFnet 的发展非常迅速,很快将全美各地的大学、政府和私人科研机构连接起来。同时,NSFnet 的网络速度也很快,比当时民用的 ARPANET 要快 25 倍以上。渐渐地,NSFnet 开始取代 ARPANET,成为 Internet 的主干网。
80 年代末,连接到 NSFnet 的计算机数量远远超过了 ARPANET 用户的数量。
直至 1990 年 6 月 1 日,ARPANET 正式退出历史舞台。
1990 年 9 月,由 Merit、IBM 和 MCI 公司联合建立了一个非盈利的组织 ANS(Advanced Network&Science Inc.,先进网络科学公司)。ANS 的目的是建立一个全美范围的 T3 级主干网,能以 45Mbps 的速率传送数据。
1991 年底,NSFnet 主干网与 ANS T3 级主干网进行互联互通,并宣布开始对全社会进行商业运营。
后来大家都知道,网络连接数量开始指数级增长。Internet 真正变成了全球互联网,开始走进人们的生活。
1994 年,举办互联网大会。
• 前排从左到右:Dave Walden, Barry Wessler, Truett Thach, Larry Roberts, Len Kleinrock, Bob Taylor, Roland Bryan, Bob Kahn.
• 后排从左到右:Marty Thrope, Ben Barker, Vint Cerf, Severo Ornstein, Frank Heart, Jon Postel, Doug Englebart, and Steve Crocker.
1998 年,美国成立非营利性民间组织 ICANN(Internet Corporation for Assigned Names and Numbers,互联网名称与数字地址分配机构),它由商务部的国家电信和信息管理局监督,负责全球互联网域名系统、根服务器系统、IP 地址资源的协调、管理和分配。由 ICANN 的下属机构 IANA(Internet Assigned Numbers Authority,互联网号码分配机构)负责管理全球互联网域名的根服务器。
2014 年,ICANN决定将监管权移交给一个由多方利益相关者管理的独立机构。
2016 年 10 月 1 日,ICANN 表示,正式将互联网的控制权移交给一个非盈利的全球互联网多方利益相关者组织。这标志着美国结束对这一互联网核心资源近 20 年的单边垄断,对于每一个网民来说都是一大喜事。
06
HTTP 协议与 Web 世界的诞生
再回到 1989 年,当时在瑞士日内瓦 CERN(核子研究中心)工作的 Tim Berners-Lee(蒂姆·伯纳斯·李)在论文中提出了一种可以在 Internet 上构建超链接文档的技术,即 HTTP/Web 技术,并提出了 3 点基本要素:
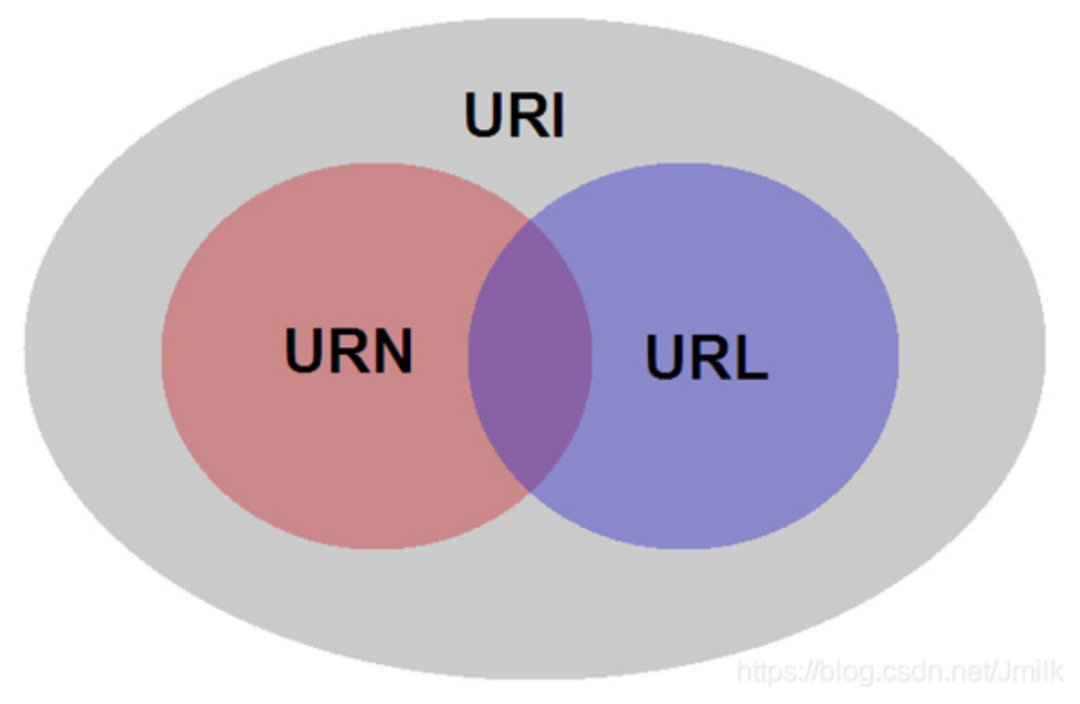
1、URI(Uniform Resource Identifier,统一资源标识符):Internel 中的统一资源标识符,用于唯一标识一个 Internet 上的资源。
2、HTML(Hyper Text Markup Language,超文本标记语言):使用 HTML 标签来构建超文本文档,HTML 标签将文字,图形、动画、声音、表格、链接等内容格式进行了统一。
3、HTTP(Hyper Text Transfer Protocol,超文本传输协议):最初设计来用于传输 HTML 的协议,处于 TCP/IP 应用层,传输的数据主体称为 Message(消息),基于 TCP 传输协议。
Tim Berners-Lee 所定义的 Resource,指的是 Internet 上的一个实体,它可以是一段文本、一张图片、一首歌曲、一种服务等。URI 就是在 Internet 中标识一个 Resource 的唯一 ID,包含了 URL 和 URN 这 2 种形式。
• URL(Uniform Resource Loader,统一资源定位符):侧重于 “定位”,类似一个地址,XX省XX市XX区XX单元XX室。
• URN(Uniform Resource Name,统一资源名称):侧重于 “命名”,类似身份证号。
由于 URL 更具有空间层次设计,所以如今已经成为了主流,但开发者仍应该清晰区分两者。
1990 年 12 月 25 日,Tim Berners-Lee 和罗伯特·卡里奥一起实现了基于 HTTP 协议的 Web Server,并通过 Internet 成功完成了 HTTP Client 和 Web Server 的第一次通信。
1991 年 8 月 6 日,Tim Berners-Lee 基于 HTTP 和 HTML 设计并开发了第一个网页浏览器,并发布了世界上第一个 Web 网站。它被称为 The First Website(第一个网站)或 InfoMesh(信息管理系统项目),运行在 CERN 的服务器上,旨在帮助研究人员共享信息和文献。基于 HTML,该网站可以提供一些链接,让用户通过单击超链接跳转到其他页面或文档,这种超链接的设计 Web 技术最重要的创新之一。
同年,Tim Berners-Lee 正式提出了 WWW(World Wide Web,万维网)的概念。
1992 年,几个 Internet 组织合并成立统一的 ISOC(因特网协会),此时的 Internet 已经注册了超过 100 万台主机,并持续指数级疯狂增长。
1994 年 10 月 1 日,Tim Berners-Lee 创建了非营利性的 W3C(World Wide Web Consortium,万维网联盟),邀集 Microsoft、 Netscape、 Sun、Apple、IBM 等共 155 家互联网上的著名公司。由 Tim Berners-Lee 担任 W3C 的主席,致力推动 WWW 协议的标准化,并进一步推动 Web 技术的发展。
在当时的浏览器热潮下,Tim Berners-Lee 也曾考虑过成立一家叫做 Websoft 的公司做网页浏览器。但很快他就放弃了,他担心这么做会导致激烈的市场竞争,开发出技术上互不兼容的浏览器、最终把 WWW 割裂成一个个利益集团。
• Tim Berners-Lee,万维网之父
最初,由于那时候网络资源匮乏,HTTP/0.9 版本相对简单,采用纯文本格式,且设置为只读,所以当时整个 HTTP Request Message 只有一行,比如:GET www.leautolink.com。只能使用 GET 的方式从 Web 服务器获得 HTML 文档,响应以后则关闭。响应中也只包含了文档本身,无响应头,无错误码,无状态码。
1995 年,由 Brian Behlendorf 发布了基于 HTTP/0.9 的 Apache HTTP Server 开源项目。同年,网景和微软开启浏览器大战,但好在 Tim Berners-Lee 担心的 “撕裂“ 并未发生,HTTP 协议已经逐成气候。
随着 Apache HTTP Server 的诞生,以及同时期其他的多媒体等技术发展迅速,都进一步促使 HTTP 协议的演进。紧跟着 1996 年,HTTP/1.0 发布,更好的支持采用图文网页形式。具体而言增加了以下几个特性:
增加 HTTP Header 格式。
增加协议版本号。
增加 POST 方法。
增加 HEAD 方法。
增加文件处理类型。
增加响应状态码。
提供国际化支持。
经过几年的发展,1999 年,HTTP/1.1 发布并成为标准,写入 RFC。至此,HTTP 协议已然成为了 Web 世界的奠基石。
增加 PUT 等方法。
增加缓存处理机制:在 Header 增加了如:Entity tag,If-Unmodified-Since,If-Match,If-None-Match 等可供选择的 Request Body 来控制缓存策略。
增加带宽优化机制:在 Header 增加了 Range 字段,它允许只请求资源的某个部分,而不是一揽子返回,得以更充分地利用带宽和网络连接。
增加错误通知的管理:新增了 24 个错误状态响应码。
增加 Host 虚拟主机:支持 HTTP Server 虚拟主机技术。可以在一台物理服务器上存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个 IP 地址,通过不同 Hostname 区分。
增加长连接机制:默认使用长连接,应对日益复杂的网页(网页内的图片、脚本越来越多了)。
等等。
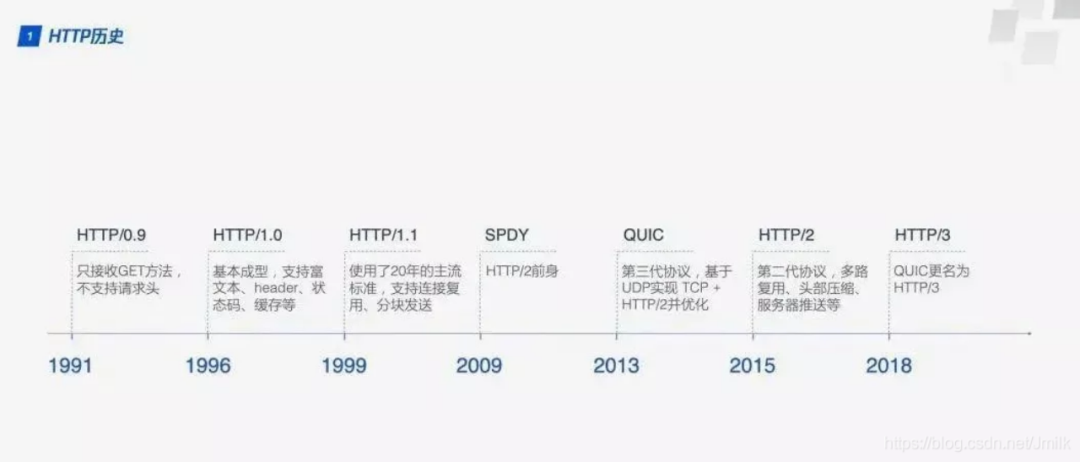
随着 HTTP/1.1 被纳入 RFC 标准,同在 1992 年,由 HTTP/1.0 和 1.1 的主要设计者 Roy Thomas Fielding 宣布成立了 Apache 软件基金会,并作为 Apache 基金会的第一任主席,从此,Apache Web Server 和 HTTP 协议携手共生共荣。 除了 HTTP 协议,Apache 软件基金会旨在促进各种开源软件项目的开发和使用,其中 Apache HTTP Server 作为首个核心项目。这为 Apache HTTP Server 的长期发展奠定了良好的基础,同时也缔造了繁荣的开源生态系统,孵化了包括:Tomcat、Hadoop、Lucene、OpenOffice 等开源项目。 至今而至,Apache 软件基金会已成为了全球最大的开源组织之一。
07
REST 系统架构的诞生与 API 经济的腾飞
2000 年,Apache 基金会的第一任主席 Roy Thomas Fielding 在博士论文《Architectural Styles and the Design of Network-based Software Architectures(架构风格和基于网络的软件架构设计)》中提出了 REST(Representational State Transfer,表现层状态转移)的理念。
顾名思义,Roy Thomas Fielding 在这篇论文中主要讨论的是:如何在符合架构原理的前提下,理解和评估以网络为基础的应用软件的架构设计,得到一个功能强、性能好、适宜通信的架构。
可见,REST、HTTP 协议、Web 服务器,这 3 者之间天生关系紧密。所以,开发者要清晰理解 Representational State Transfer 含义,应该先对 HTTP 协议有一个清晰的认识。
通过拆词法,尝试对 Representational State Transfer 的含义进行以下解构:
• Representational(表现层):即 Resources 的表现层。上述我们知道 Resource 是一种抽象,它具有多种表现形式,而最终把 Resource 具体呈现出来的形式,就叫做它的 “表现层”。例如:一个文本资源可以使用 TEXT 格式表现,也可以使用 HTML、XML、JSON 等格式表现。在 HTTP/1.0 中,Roy Thomas Fielding 为 HTTP Header 设计了 Accept/Content-Type 字段来描述这个 Resource 的 Representational。
所以,需要注意的是:URI 仅用于标识一个 Resource,而不应该在 URI 中描述表现层的内容,一个优雅的 RESTful API 应该使用 Accept/Content-Type 字段来描述 Resource 的表现层。
Accept: Application/json
Content-Type: Application/json
• State Transfer(状态转移):Resource 作为 C/S 交互的实体,必然存在着状态的变化,然而 HTTP 是一种 Stateless(无状态)的协议(不传输资源状态的描述)。这意味着:Resource 的状态都保存在 Server,而 Client 想要操作某个 Resource(改变其状态)就必须通过某种手段让 Resource 在 Server 上发生状态的 “转移”,而且这种 “转移” 必然是建立在 Resource 的 “表现层” 之上的,例如:创建一个图片资源、删除一个图片资源;启动一个服务,关闭一个服务。故称之为 "表现层状态转移"。
Client 可以使用的手段就是 Roy Thomas Fielding 在 HTTP 请求行中设计的 Request Methods(HTTP/0.9 引入 GET,HTTP/1.0 引入 POST、HEAD,HTTP/1.1 引入 PUT 等)。
# Client
GET /resource
Accept: text/html
# Server
Content-Type: text/html;charset=utf-8
Response code: 200
至此,我们回头再看,REST 讨论的其实是一个:如何将软件和网络两个领域进行交叉融合,继而得到一个功能强、性能好、适宜通信的互联网软件架构的问题。
2006 年,正值 AWS 孵化的初期,时任 Amazon CTO Werner Vogels 在一封邮件中强调:
1、AWS 必须是一种 Resilient software architecture(具有韧性/弹性的软件架构)。
2、不使用 RESTful API 的员工将被辞退。(注:RESTful API 就是符合 REST 架构设计思想的软件 API 风格,*-ful 在西文语境中常用于表示一种风格)
直到 2013 年笔者接触 OpenStack(OpenStack 初期常被认为是 AWS 的开源对标版本)之后才更深刻地体会到了其内涵和精髓。大型分布式软件的各个组件之间必须具备解耦和扩展的能力,而网络(Network-base)就是组件之间通信的唯一依赖,且对资源的操作具有唯一的确定性。
我们可以选取一个角度来比较一下 RESTful 与另外两种常见的分布式架构风格的区别:
• RESTful 抽象的是资源:资源的抽象不需要依赖开发平台或编程语言,C/S 架构完全松耦合。
• DO(Distributed Objects,分布式对象)抽象的是对象:不同的编程语言对对象的定义有很大差别,所以 DO 架构通常会与某种编程语言(.NET)绑定,若跨语言交互,实现则会非常复杂。典型有 RMI、EJB/DCOM、.NET Remoting 等。
• RPC(Remote Procedure Call,远程过程调用)抽象的是过程:这要求 C/S 之间具有很强的 RPC 通信模型耦合度,否则双方无法理解对方的意图。典型有 SOAP、XML-RPC、Flash AMF 等。
AWS 在后面很长的时间内一直都奉行着 RESTful API 的铁律,使其得以在几年间飞速扩展至上百个核心组件,成为了极具韧性/弹性和良好生态的公有云架构。现在的软件公司基本都会采用 RESTful API 风格,让产品可以通过 API 的方式融入到行业生态中,形成 APIs 经济效益。
08
Future Internet(未来互联网)思想萌芽
21 世纪初,随着 Internet 的全球普及,随之也逐渐暴露出了在可扩展性、安全性、可管理性、带宽性能等多方面的问题。
以安全性为例子,传统 Internet 的网络设计源自 ARPANET,认为所有的用户都是可信的、自律的,并没有内生考虑在基础网络结构上确保网元不受攻击。更具体地说,TCP/IP 是一套开放的协议和标准,Sender 和 Receiver 之间不存在固定的互联电路和信令系统,网络中的 Sender 可以向其它任何 Receiver 发送任何内容,而 Receiver 却无法拒绝接收。这也意味着网络上的任何人都可以使用这些协议和标准来攻击其他人或组织,而且很难防止这种攻击。
1、第一代科研型互联网:军事与科研网。
2、第二代消费型互联网:万维网(突发性,尽力而为、不安全、难管理、不强调 QoS)。
3、第三代生产型互联网:未来互联网(确定性、差异性、安全、易于管理、强调 QoS,与实体经济深度融合)。
可见,传统 Internet 的发展早已经走到了十条路口,Future Internet(未来互联网)的演进成为了业界关注的焦点。
并且长期以来,计算机网络领域对 Future Internet 的发展都存在着 2 种不同观点:
1、演进派:认为 Internet 应像过去那样继续存在,遇到什么样的问题,就打什么样的补丁,安全性此类问题并不是由网络基础架构本身引起的。应该采用网络重叠的方式来提供所需安全性和性能,而不触动现有的基础设施。2008 年 12 月,互联网创建人之一 Bob Kahn 在印度海德拉巴举办的 “互联网治理论坛”上发言,提出了 “数字对象架构” 的新标准,旨在使信息能在互联网上更顺畅地传输。他坚持认为这样就能解决问题,而又不损害基本的架构。
2、革命派:则认为 Internet 应该被 “重新发明“,不断打补丁的方式,会增加 Internet 的复杂性,使其变得更难以管理、对突破性的新型应用更不友好,且使 Internet 的技术体系逐步僵化,现有体系可能已快走到尽头,还能修补的余地已经不大。2005 年,作为 Internet 协议的总设计师之一的 Dave Clark 教授发表了一篇题为《互联网不再联》的文章,指出:“Internet 的本质缺陷让商家花费了几十亿成本,但却阻碍了新发明,威胁到了国家安全。现在到了从头再来的时候了。” 革命派倡导新路线有可能孵化更多种类的网络体系,并创造持续创新的环境。在走革命路线的过程中,也会为演进路线提供更多的改进机会。
显然的,演进派的拥趸主要来自商业社会,而革命派则得到了学术界和国家机构的支持。
2005 年 8 月,NSF(美国国家科学基金会)投资了 GENI(Global Environment for Networking Innovations,全球网络创新研究环境)和 FIND(Future Internet Network Design,未来的互联网设计)两个项目。
GENI 项目是一个开放的、大规模的、真实的、分布式的,用于研究未来互联网技术(Future Internet technologies)的全国性网络创新试验床基础设施。通过为研究者提供一个可自定义的、可重复实现的虚拟网络试验床基础设施的协作方式,加速 Future Internet 的研究,继而改变传统网络体系研究所遵循的 “打补丁” 的演进方式,借此从根本上思考 Future Internet 的体系和功能,并以此指导未来网络体系的演化。
GENI 希望网络的新体系结构具有以下 4 个基本特征:
良好的安全性与可管理性。
允许各种计算设备,包括 PC、手机、传感器、嵌入式处理器与此网络连接,以实现普适计算。
能实现对其他重要基础设施必要的控制与管理。
引入一些使网络变得更有弹性、更容易管理的技术,便于业务提供商能更好地开展新业务。
在技术层面,GENI 通过虚拟化技术和分布式技术,从物理空间和时间两个方面,将资源以虚拟化切片的形式进行交付,为不同网络实验者提供他们所需求的试验床资源(如:计算、存储、带宽、网络拓扑等),并提供试验床资源的可操作性、可测性和安全性。
2007 年 3 月,NSF 通过 GENI 和 FIND 项目资助几项大学研究,斯坦福大学的一个跨学科研究项目 Clean Slate Program(意为:白手起家,或从头再来)就是其中之一。Clean Slate 项目的最终目的是要重新发明 Internet,旨在改变设计已略显不合时宜,且难以革命性进化发展的传统网络基础架构。该课题除了得到 NSF 的支持外,后来还逐渐得到了 Cisco、德国电信、NTT DoCoMo、NEC 和 Xilinx 等商业伙伴的支持。
09
OpenFlow 与 SDN 的诞生
2006 年,斯坦福教授 Nick McKeown(时任 Clean Slate 项目主任)的博士学生 Martin Casado,在 RCP 和 4D 论文的基础上提出了一种逻辑上集中控制的企业安全解决方案 SANE,希望通过集中控制的方式来解决安全问题。集中控制思想是对保罗.巴兰最初在 “分布式通信理论” 中提出的分散控制思想的一种颠覆。
2007 年,Martin Casado 在 SANE 基础上开始领导面向企业网络安全与管理的 Ethane 项目。该项目试图通过一个集中式的 Controller(控制器),让网络管理员方便地定义基于网络流的安全控制策略,并将这些安全策略应用到各种网络设备中,从而实现对整个网络通讯的安全控制。
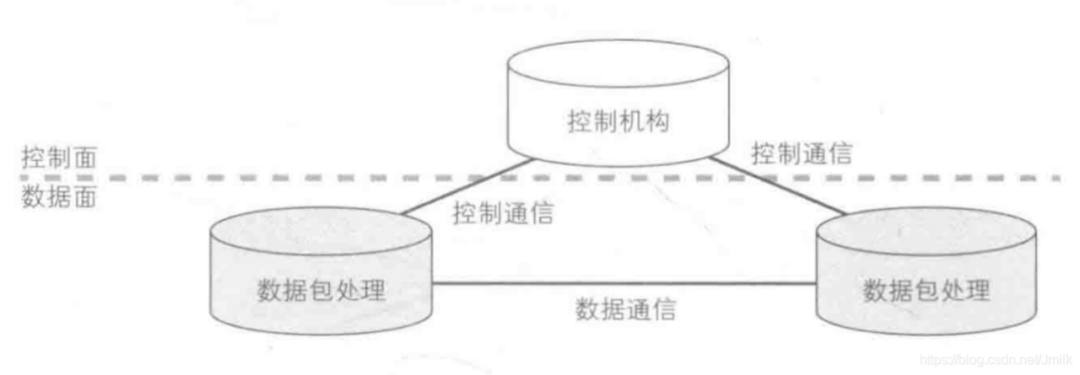
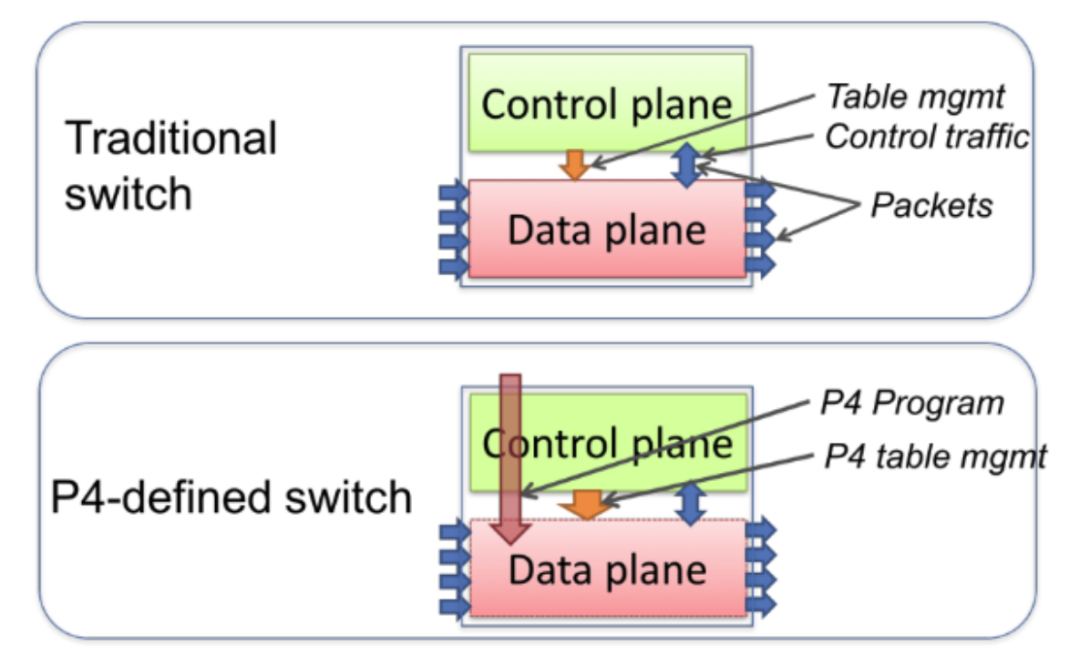
后来,受 Ethane 项目的启发,Martin Casado 和他的导师 Nick McKeown 教授发现,如果将 Ethane 的设计更简化,将传统网络设备的数据转发(Data Plane)和路由控制(Control Plane)两个功能模块相分离,并通过集中式的 Controller 以标准化的接口对各种网络设备进行管理和配置,那么这将为网络资源的设计、管理和使用提供更多的可能性,从而更容易推动网络的革新与发展。
同年,Nick Mckeown 教授、Scott Shenker 教授和 Martin Casado 博士在硅谷一起创办了 Nicira(后被 VMware 收购),这是 SDN 历史上第一个初创公司。
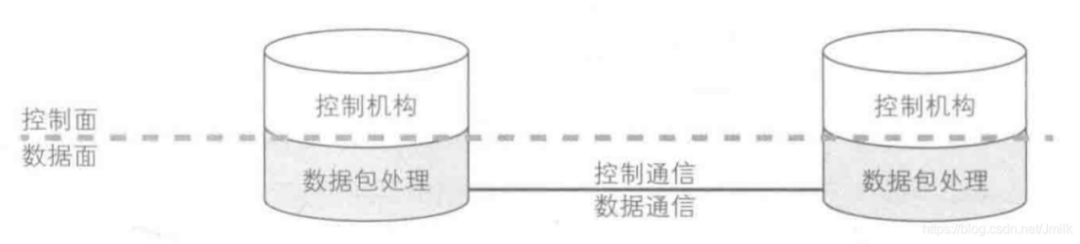
• 控制面、数据面统一的传统路由器设备:
• 控制面、数据面分离的 SDN 网络架构:
2008 年,Nick McKeown 教授等人在 ACM SIGCOMM 发表了题为《OpenFlow: Enabling Innovation in Campus Networks》(OpenFlow:校园网的创新使能)的论文,首次详细地介绍了 OpenFlow 和 OpenFlow Switch 的概念。
该篇论文首次详细地介绍了 OpenFlow 的概念、工作原理,列举了 OpenFlow 的几大应用场景。包括:
校园网络中对实验性通讯协议的支持;
网络管理和访问控制;
网络隔离和 VLAN;
基于 Wi-Fi 的移动网络;
非 IP 网络;
基于网络包的处理。
OpenFlow Switch 相较于传统 Switch 有着本质不同。OpenFlow Switch 将控制权上交给集中控制器,以此解决了 “难管理" 的问题,也让网络基础设施具备了内生的安全性。OpenFlow 很久就在 GENI 项目中得到了应用。
同年,Nick McKeown 教授带领的斯坦福大学研究团队发布了首个开源 SDN Controller NOX。紧接着,2009 年又发布了 Python 版的 SDN Controller POX,以及 OpenFlow1.0 协议和开源网络虚拟化软件 FlowVisor。2010 年,Nick McKeown 的团队又发布了 Mininet。迄今为止,Nick McKeown 团队发布的这些软件依然被业界广泛使用。
OpenFlow/SDN 可以说是 “革命派” 在未来互联网技术研究上的关键成果。
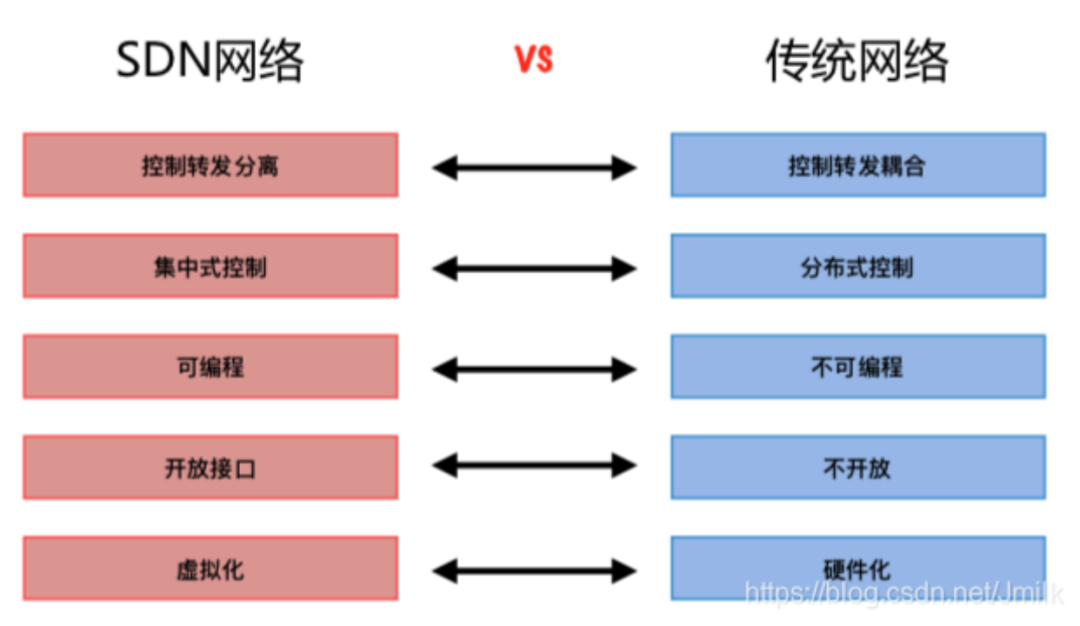
集中式的 Controller 通过 OpenFlow 协议对 OpenFlow Switch 中的 Flow Table 进行控制。Controller 会为特定的工作负载计算最佳路径,从而对 Switch 的数据转发定义路径。控制转发分离的架构由 Controller 对网络中的各种 Switch 设备进行综合管理,这种行为就像对网络进行整体 “编程” 一样。
2009 年,基于 OpenFlow 为网络带来的可编程特性,Nick McKeown 教授团队与加州大学伯克利分校的 Scott Shenker 教授进一步提出了 SDN(Software Defined Network,软件定义网络)的概念。
2010 年,Google 开始将数据中心与数据中心之间的网路连线(G-scale),转换成 SDN 架构。
2011 年 5 月,NEC 面向虚拟化数据中心和云服务市场,推出了第一台可商用的 OpenFlow 交换机。
2011 年 10 月,Cisco 在数据中心官方 Blog 上宣布会在 Nexus 交换机上提供对 OpenFlow 的支持。
2011 年 10 月,Juniper 开始在 Junos 操作系统 SDK 中添加 OpenFlow 代码。
由 OpenFlow 带来了两项革命性的网络创新成就:“控制转发分离架构” 和 “可编程性”,也成为了 SDN 思想的核心理论。
10
SDN 蛮荒混战
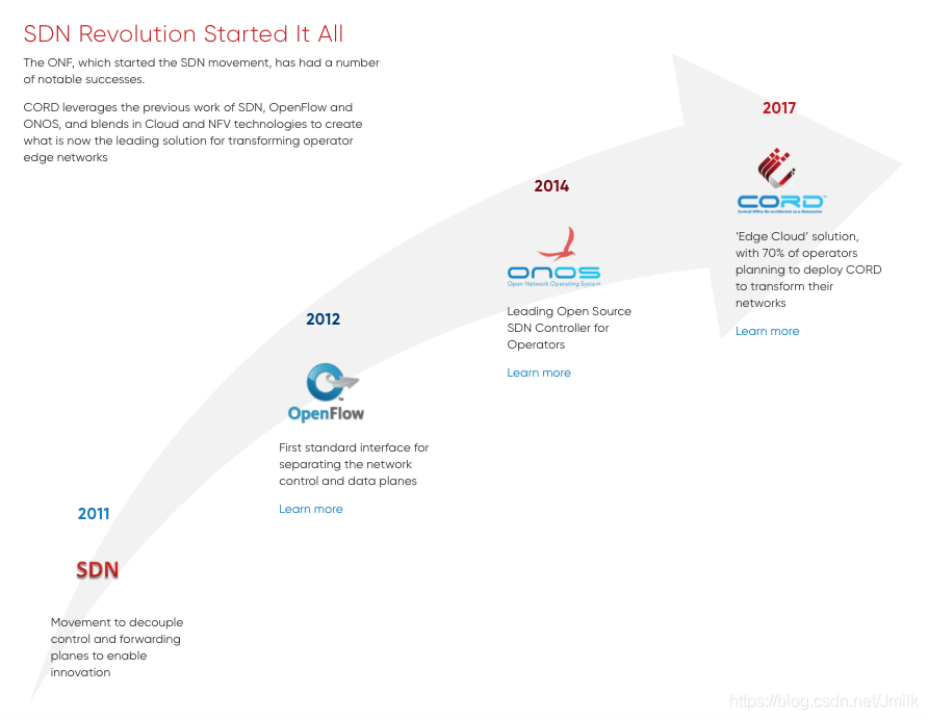
Open Networking Foundation 成立
2011 年,在 Nick McKeown 教授等研究学者的推动下,成立了开放网络基金会(ONF,Open Networking Foundation)。
ONF 最初的主要发起成员包括德国电信、Facebook、Google、Yahoo、Microsoft 等公司。这些公司要么是网络服务提供商,要么是电信运营商,唯独没有一家网络设备提供商。
ONF 成立的目的,是为了推动 SDN 和 OpenFlow 协议的发展,由非网络设备提供商组成的 “软件定义网元” 战线联盟。他们希望以此摆脱网络设备提供商长久以来的枷锁,获得更加灵活且契合自身需求的、更加低耗高效的网络基础设施。ONF 的成立标志着 OpenFlow 从散兵游勇的野蛮状态正式过渡到产业化发展的轨道中。
同年,ONF 召开了第一届开放网络峰会(Open Networking Summit),并发表了 SDN 白皮书《Software Defined Networking:The New Norm forNetworks》,为 OpenFlow 和 SDN 在学术界和工业界都做了很好的介绍和推广。
Nick McKeown 教授还与 Scott Shenker、Guru Parulkar、Larry Peterson 教授等人创建了 ON.Lab(开放网络实验室)。ONF 和 ON.Lab 两大组织的成立,主要致力于推动 SDN 架构、OpenFlow 标准和规范的维护和发展,成功地将 SDN 推到前台,并获得业界的广泛关注,为推动 SDN 被业界广泛采用奠定了基础。
2012 年召开的第二届 Open Networking Summit 上,Google 宣布已经在其全球各地的数据中心骨干网络中大规模地使用 OpenFlow。完成 SDN 改造之后,Google B4 网络将全面运行在 OpenFlow 上,并且通过 10G 网络链接分布在全球各地的 12 个数据中心,使广域线路的利用率从 30% 提升到 90% 以上,接近 100%。
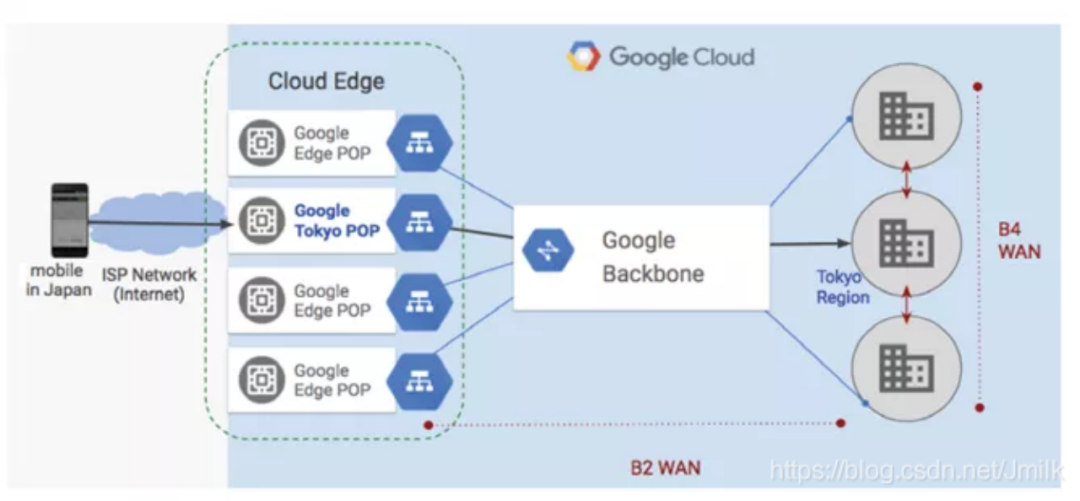
Google B4 是世界上首个跳出数据中心网络,而在骨干网络上取得巨大成功的 SDN 案例,这标志着 OpenFlow 技术 SDN 完成了从实验技术向网络部署的重大跨越,这样的结果毫无疑问是令人震撼的,也坚定了行业对 SDN 的信心,从而开启了 SDN 网络新时代。
同年 8 月,VMware 以 12.6 亿美金收购了 Nick Mckeown 教授的 SDN 创业公司 Nicira,其核心产品是基于 OpenFlow 协议创建了网络虚拟平台(NVP)。VMware 宣称会将 Open vSwitch 等核心技术合并到自己的虚拟网络软件产品组合中。
2013 年,Google 在 SIGCOMM 上发表了论文《B4: Experience with a Globally-Deployed Software Defined WAN》,详细介绍了 Google 的 WAN 加速 SDN 方案。论文中提及,Google 使用的控制器名叫 ONIX。
2013 年,AT&T 发布了 Domain2.0 计划,并发布 Domain2.0 白皮书,通过 SDN/NFV 技术将网络基础设施从 “以硬件为中心” 转向 “以软件为中心”,实现基于云架构的开放网络,率先打造 ECOMP 网络编排系统,首次将 SDN 技术用于电信运营商大网的编排管理。
OpenDayLight 成立
面对 SDN 和 ONF 提出的网元软件化,作为传统的网络设备厂商当然不能无动于衷,他们组建了 “软件定义网管” 捍卫同盟,开始向 OpenFlow 的致命弱点发起了攻击。
以 Cicso、Juniper、HUAWEI 为代表的设备厂商,认为纯粹 OpenFlow 网元有很大的问题。比如,OpenFlow 不支持 IPv6、MAC-in-MAC 运营商骨干桥接、Q-in-Q 虚拟局域网栈、QoS 服务质量、流量整形能力、容错和弹性等功能,这些缺陷限制了 OpenFlow 协议和 SDN 在电信网络中的应用。所以他们提出了:转发层面仍然基于现有协议体系,但设备应该开放更多的北向 API 供调用,即:通过网管来实现 Controller 的功能。
2013 年 4 月 8 日,在 Linux 基金会的支持下,作为网络设备商中的领导者,Cisco、Juniper、博通、IBM 等网络设备厂商联合成立了 OpenDayLight(打开天窗说亮话)开源项目。
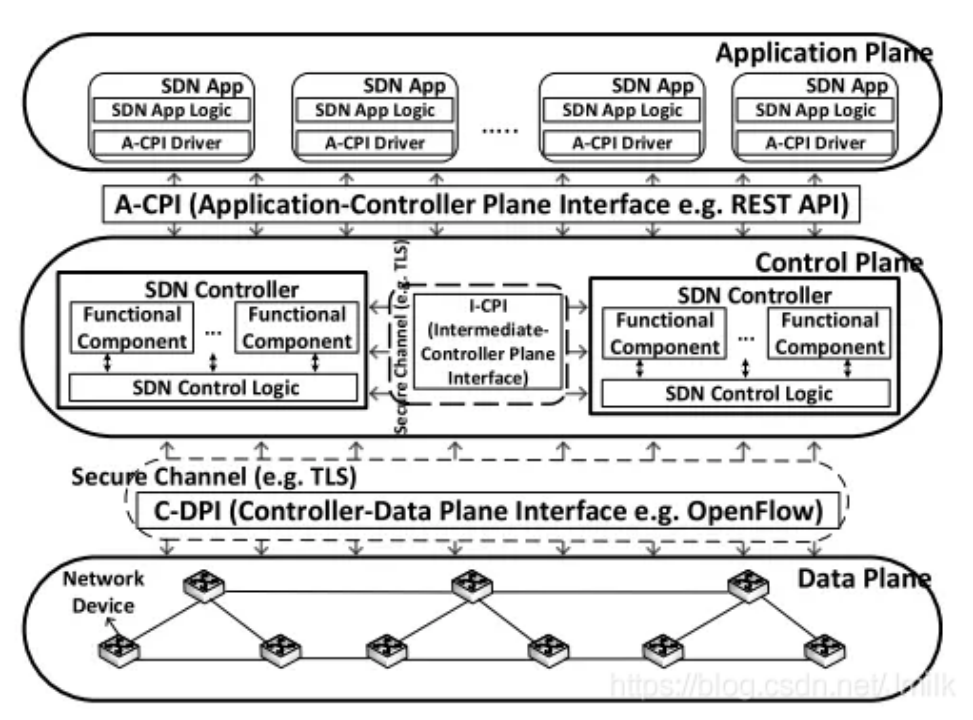
OpenDaylight 强调,SDN 不等于 OpenFlow,SDN 需要重新被定义。也就是说,OpenDaylight 强调 SDN Controller 不仅仅局限于 OpenFlow,而是应该支持多种南向协议。同时,OpenDaylight 还强调,应该采用分布式的 Controller 来取代集中式的 Controller。这样可以管理更大的网络,提供更强劲的性能,还能增强系统的安全性和可靠性。
OpenDaylight 对 SDN 的定义进行了更高层次的抽象,模糊了 OpenFlow 的存在:
控制与转发分离。
逻辑上的集中控制。
控制平面与转发平面之间提供可编程接口。
但是,由于商业社会残酷的竞争,OpenDaylight 在成立之初就留下了矛盾的隐患。软件防火墙与 VPN 供应商 Vyatta 的 CEO Kelly Herrell 就曾公开指出:Cisco 依赖于大量昂贵硬件的销售,这与 SDN 的未来是 “矛盾的”。
但无论如何,激烈的商业竞争也同样意味着产业的发展势头欣欣向荣,大量的 SDN 项目破土而出,例如:Cisco OpFlex、Juniper Tungsten Fabric、BigSwitch Floodlight 等等。
New Open Networking Foundation 改建
2014 年 12 月 5 日,为了向 ODL 予以还击,ON.Lab 推出了一款创新性的网络操作系统 ONOS(Open Network Operating System)。
ON.Lab 还一度严格要求加入的成员不得为任何网络设备厂商工作,以此防范引入设备商们的利益纠葛。后来由于 ON.Lab 的组织者和职能都与 ONF 重叠。所以,在 2016 年 10 月 19 日,两个组织宣布正式合并,改建了新的 ONF。
就这样,围绕 SDN 控制器和协议,各大流派及厂商进行了十多年的明争暗斗,至今仍在发生着。
11
狭义 SDN 已死,广义 SDN 永生
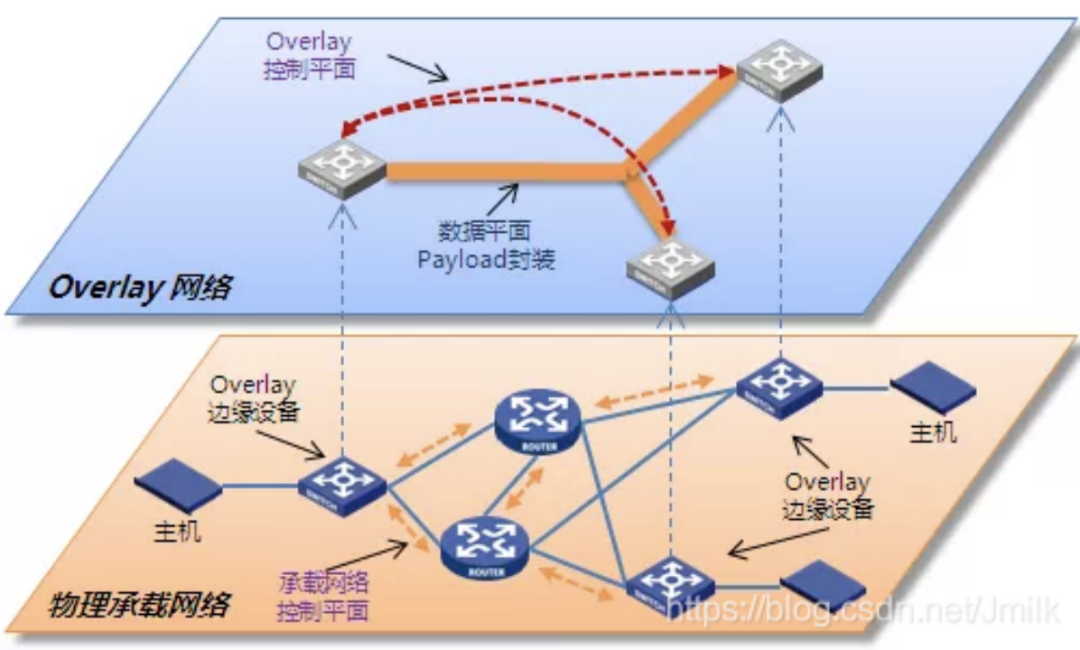
Overlay 虚拟网络
在经历了 ODL 的阵痛之后,网络设备商们也纷纷开始押注走向另外一条更熟悉的道路,即:面向数据中心网络的、基于标准协议(VxLAN、GRE、MPLSoGRE/UDP)的 Overlay 虚拟网络。
2011 年 8 月,IETF 发布了 RFC 7348 草案《Virtual eXtensible Local Area Network (VXLAN): A Framework for Overlaying Virtualized Layer 2 Networks over Layer 3 Networks》,主要由 VMware 与 Cisco 公司草拟。该技术利用 L2 over UDP 机制传输原始报文、利用 VxLAN 头中 24bits 的 VNI 信息将传统 VLAN 标记扩展至 16MB。
2011 年 9 月,IETF 发布了 RFC 7637 草案《NVGRE: Network Virtualization Using Generic Routing Encapsulation》,主要由 Microsoft 公司草拟。该技术利用 L2 Over GRE 机制传输原始报文、利用 GRE Key 字段中的高 24bits 将 VLAN 数据扩展至 16MB。
2012 年 2 月,IETF 发布了 RFC 7665 草案《A Stateless Transport Tunneling Protocol for Network Virtualization (STT) 》,主要由 Nicira 草拟。该技术利用 L2 Over Stateless TCP 机制在传输原始报文、利用 STT 头中的 64bits Context ID 标识二层网络分段。
当然,Overlay 网络诞生的诱因并不完全是因为 SDN 领域激烈的竞争,更多是由云计算/数据中心快速发展所带来的业务驱动。但 Overlay 网络确实很好地继承了来自 “狭义 SDN“ 的良好思想,在传统网络设备架构不需要进行大规模修改的前提下,叠加了 “中央管控“ 和 “可编程接口“ 机制,实现了应用和网络的感知与协同。目前 Overlay 已经大规模被部署到各个云计算数据中心网络中。
P4 可编程网络
同样的,Nick McKeown 教授等人也深刻领会到 OpenFlow 从纯软件方向切入的无力感,于是继续从更本质的硬件层面探索 SDN 的可能性。
2014 年,Nick McKeown 教授联合普林斯顿大学的 Jennifer Rexford 教授等人发布了成果论文《P4: Programming Protocol-Independent Packet Processors》。
论文中介绍了一种具有协议无关性、目标无关性、以及现场可重配置能力的 P4 DSL(专用芯片编程语言)编程语言。不久后,Nick McKeown 教授又联合创立了数据平面可编程芯片公司 Barefoot Networks,并推出了 Barefoot Tofino DSA(专用芯片架构)可编程网络芯片。
从 Nick McKeown 教授的表述中,可以将 P4 诞生的需求背景归纳为以下几点:
一方面,可编程 CPU 无法满足日益增长的网络流量处理需求:目前最好的 ASIC 交换芯片可以处理大约 12.8Tbps,而目前最先进的 CPU 的网络处理能力仅略高于 100Gbps;一个 ASIC 交换机以 10Tbps 的速度处理 40 种协议需要 400W 功耗,而一颗 CPU “等效的” 以 10Tbps 速度仅处理 4 个协议就需要 25KW 功耗;在可预见的未来,高性能交换机将完全基于 ASIC 芯片。
但另一方面,ASIC 的开发者并不是来自最终用户:ASIC 无法让最终用户根据自己的需要编写代码,真正编写代码的还是设备商。但是,设备商并不运营大型网络,所以他们倾向于简单地实施现有的标准。他们永远不会主动成为创新的人,所有这些都使得引入新想法变得困难,因此一切都趋于停滞。当用户希望在 ASIC 中添加一个新的协议时,其开发周期可能是 4 年。
在这样的背景下,用户越来越强烈地需求一款新的针对特定领域的处理器芯片。并且与 CPU 上的通用计算一样,所有特定领域的处理器都有相应的高级编程语言和编译器。而网络领域的 DSL 和 DSA 就是 P4 编程语言(软件)和 Barefoot Tofino 可编程交换芯片(硬件)。
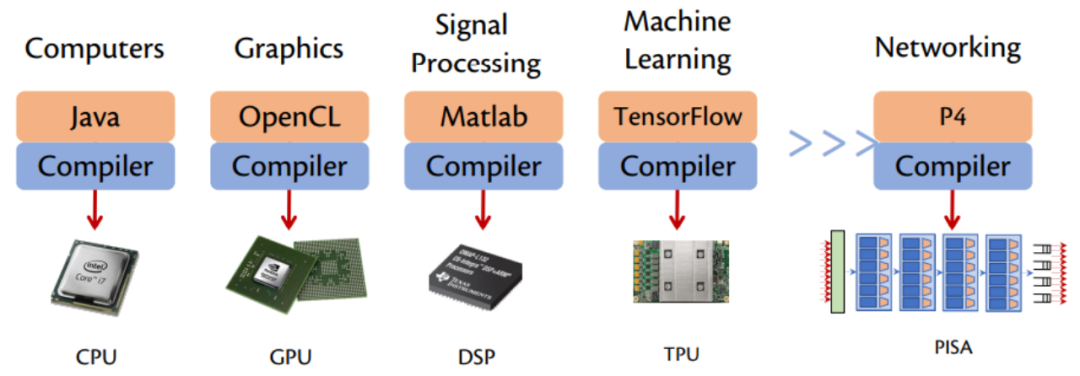
在 OpenFlow 时代,传统交换机结合 OpenFlow 协议,通过 Control Plane 正确设置 ASIC 芯片的各种 Flow Table Entries 来控制 Data Plane 的转发行为。但前提是,不能超出 ASIC 芯片原本没有支持的功能范围。可见,OpenFlow 只是从软件层面提供了一种 Control Plane 和 Data Plane 交互的协议,其功能完全受制于硬件的特性。
而 P4 可以说是 OpenFlow 的接棒者,以期解决 OpenFlow 编程能力不足和可拓展性差等问题。Tofino 可编程芯片的本身并不具备任何网络协议功能,而是根据开发者编写的 P4 程序来自定义转发芯片的功能。P4 将网络功能和协议设计交给了广大开发者而不是传统的网络设备厂商,从而实现:
• 最大化地加速网络创新;
• 缩短协议部署周期;
• 开发者自顶向下网络设计,拥有完整的创新实验平台;
12
未来:基于软硬件融合的完全可编程网络
2019 年 6 月,Intel 收购 Barefoot Networks 公司,并由 Nick McKeown 教授出任 Intel SVP,继续领导网络研发团队(现已退居二线)。在同年的 ONF Connect 2019 演讲中,Nick McKeown 教授第一次定义了 SDN 发展的 3 个阶段:
2010–2020 年:通过 OpenFlow 将控制面和数据面分离,用户可以通过集中的控制端去控制每个交换机的行为;
2015–2025 年:通过 P4 编程语言以及可编程 FPGA 或 ASIC 实现数据面可编程,这样,在包处理流水线加入一个新协议的支持,开发周期从数年降低到数周;
2020–2030 年:展望未来,网卡、交换机以及协议栈均可编程,整个网络成为一个可编程平台。
这预示着,未来互联网技术的发展还将继续,这场从 21 世纪初开始直至今天的 “革命“ 仍未结束。
正如计算机体系结构领域的权威、图灵奖得主 David A. Patterson 和 John L. Hennessy 在 2018 年联合发布的论文《A New Golden Age for Computer Architecture》(计算机体系结构的新黄金时代)中所提到的 —— 未来将是计算机体系结构的黄金十年。
希望这也会是未来互联网技术实现彻底革新的十年。
编辑:黄飞
-
计算机网络各层作用及协议2021-10-20 6069
-
初学者快速入门STM32以及计算机网络2021-08-03 1504
-
计算机网络笔记 精选资料分享2021-07-27 2171
-
计算机网络基础知识了解2021-07-26 1514
-
计算机网络概述2021-07-22 2537
-
LWIP的源代码和谢希仁的《计算机网络》这本书怎么理解?2020-03-27 1545
-
【下载】《计算机网络(第五版)》2018-02-07 23244
-
新编TCP IP协议与计算机网络互联技术2016-04-19 873
-
计算机网络协议及其应用分析2011-06-07 956
-
计算机网络概论2009-06-27 698
-
计算机网络潘爱民pdf2008-11-25 10517
-
谢希仁计算机网络课件2008-10-23 7012
-
计算机网络基础2008-08-04 1393
全部0条评论

快来发表一下你的评论吧 !
