

Tune-A-Video论文解读
电子说
描述
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
1. 论文信息
标题:Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
作者:Jay Zhangjie Wu, Yixiao Ge, Xintao Wang, Weixian Lei, Yuchao Gu, Yufei Shi, Wynne Hsu, Ying Shan, Xiaohu Qie, Mike Zheng Shou
原文链接:https://arxiv.org/pdf/2212.11565.pdf
代码链接:https://tuneavideo.github.io/
2. 引言
坤坤镇楼:

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述

在这里插入图片描述
大规模的多模态数据集是由数十亿个文本图像对组成,得益于高质量的数据,在文本到图像 (text-to-image, T2I) 生成方面取得了突破 。为了在文本到视频 (T2V) 生成中复制这一成功,最近的工作已将纯空间 T2I 生成模型扩展到时空域。这些模型通常采用在大规模文本视频数据集(例如 WebVid-10M)上进行训练的标准范式。尽管这种范式为 T2V 生成带来了可喜的结果,但它需要对大型硬件加速器进行大规模数据集上的训练,这一过程既昂贵又耗时。人类拥有利用现有知识和提供给他们的信息创造新概念、想法或事物的能力。例如,当呈现一段文字描述为“一个人在雪地上滑雪”的视频时,我们可以利用我们对熊猫长相的了解来想象熊猫在雪地上滑雪的样子。由于使用大规模图像文本数据进行预训练的 T2I 模型已经捕获了开放域概念的知识,因此出现了一个直观的问题:它们能否从单个视频示例中推断出其他新颖的视频,例如人类?因此引入了一种新的 T2V 生成设置,即 One-Shot Video Tuning,其中仅使用单个文本-视频对来训练 T2V 生成器。生成器有望从输入视频中捕获基本的运动信息,并合成带有编辑提示的新颖视频。

本文提出了一种新的文本到视频(T2V)生成设置——单次视频调谐,其中只呈现一个文本-视频对。该模型基于大规模图像数据预训练的最先进的文本到图像(T2I)扩散模型构建。研究人员做出了两个关键观察:1)T2I模型可以生成代表动词术语的静止图像;2)将T2I模型扩展为同时生成多个图像表现出惊人的内容一致性。为了进一步学习连续运动,研究人员引入了Tune-A-Video,它包括一个定制的时空注意机制和一个高效的单次调谐策略。在推理时,研究人员采用DDIM反演为采样提供结构指导。大量定性和定量实验表明,我们的方法在各种应用中都具有显著的能力。
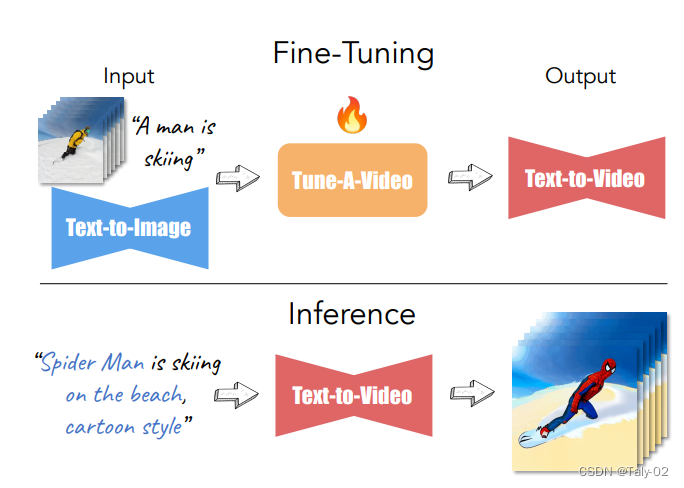
论文提出的one-shot tuning的setting如上。本文的贡献如下:1. 该论文提出了一种从文本生成视频的新方法,称为One-Shot Video Tuning。2. 提出的框架Tune-A-Video建立在经过海量图像数据预训练的最先进的文本到图像(T2I)扩散模型之上。3. 本文介绍了一种稀疏的时空注意力机制和生成时间连贯视频的有效调优策略。4. 实验表明,所提出的方法在广泛的应用中取得了显著成果。
3. 方法
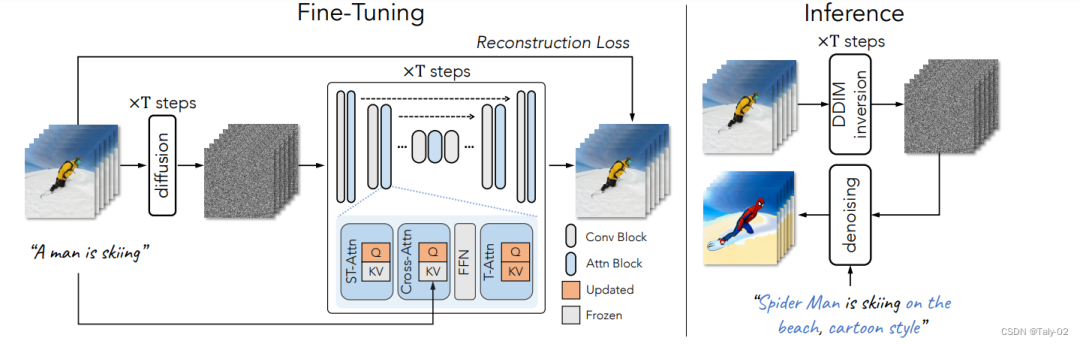
该论文提出了一种从文本生成视频的新方法,称为One-Shot Video Tuning。拟议的框架Tune-A-Video建立在经过海量图像数据预训练的最先进的文本到图像(T2I)扩散模型之上。该论文还提出了一种有效的调优策略和结构反演,以生成时间一致的视频。实验表明,所提出的方法在广泛的应用中取得了显著成果。
3.1 DDPMs的回顾
DDPMs(去噪扩散概率模型)是一种深度生成模型,最近因其令人印象深刻的性能而受关注。DDPMs通过迭代去噪过程,从标准高斯分布的样本生成经验分布的样本。借助于对生成结果的渐进细化,它们在许多图像生成基准上都取得了最先进的样本质量。
根据贝叶斯定律 and 可以表达为:
DDPMs的主要思想是:给定一组图像数据,我们逐步添加一点噪声。每一步,图像变得越来越不清晰,直到只剩下噪声。这被称为“正向过程”。然后,我们学习一个机器学习模型,可以撤消每一个这样的步骤,我们称之为“反向过程”。如果我们能够成功地学习一个反向过程,我们就有了一个可以从纯随机噪声生成图像的模型。
这其中又有LDMs这种范式的模型比较流行,Latent Diffusion Models(LDMs)是一种基于DDPMs的图像生成方法,它通过在latent space中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像。LDMs通过将图像形成过程分解为去噪自编码器的顺序应用,实现了在图像数据和其他领域的最先进的合成结果。此外,它们的公式允许引入一个引导机制来控制图像生成过程,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,因此优化强大的DMs通常需要数百个GPU天,并且推理由于顺序评估而昂贵。为了在有限的计算资源上启用DM训练,同时保留它们的质量和灵活性,我们在强大的预训练自编码器的潜在空间中应用它们。与以前的工作不同,训练扩散模型时使用这样一个表示允许首次在复杂度降低和细节保留之间达到近乎最优的平衡点,极大地提高了视觉保真度。
3.2 Network Inflation
T2I 扩散模型(例如,LDM)通常采用 U-Net ,这是一种基于空间下采样通道然后是带有跳跃连接的上采样通道的神经网络架构。它由堆叠的二维卷积残差块和Transformer块组成。每个Transformer块包括空间自注意层、交叉注意层和前馈网络 (FFN)。空间自注意力利用特征图中的像素位置来实现相似的相关性,而交叉注意力则考虑像素与条件输入(例如文本)之间的对应关系。形式上,给定视频帧 vi 的latent表征 ,很自然的可以想到要用self-attention机制来完成:
然后论文借助卷积来强化temporal coherence,并采用spatial self-attention来加强注意力机制,来捕捉不同视频帧的变化。
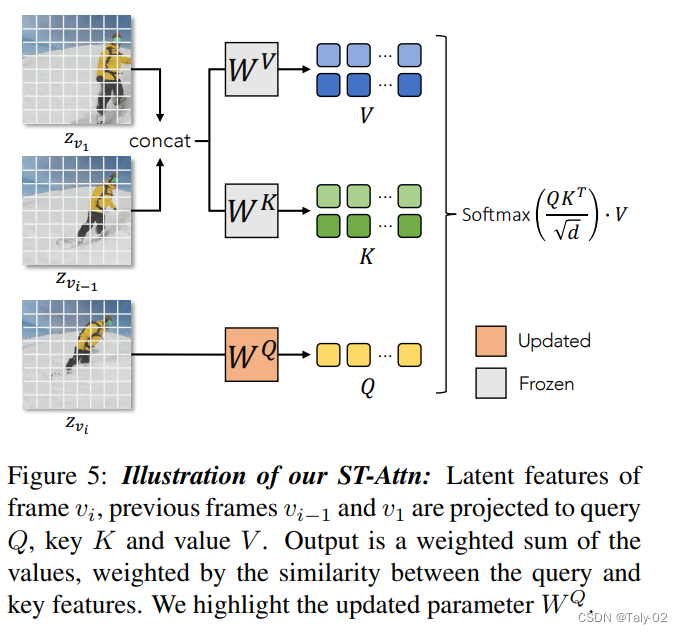
为了减少计算复杂度,Q采用相同的而K和V都是通过共享的矩阵来获取:
这样计算复杂度就降低到了,相对比较可以接受。
3.3 Fine-Tuning and Inference
Fine-Tuning是使预训练的模型适应新任务或数据集的过程。在提出的方法Tune-A-Video中,文本到图像(T2I)扩散模型是在海量图像数据上预先训练的。然后,在少量的文本视频对上对模型进行微调,以从文本生成视频。Fine-Tuning过程包括使用反向传播使用新数据更新预训练模型的权重。推理是使用经过训练的模型对新数据进行预测的过程。在提出的方法中,使用经过Fine-Tuning的T2I模型进行推断,从文本生成视频。
Inference过程包括向模型输入文本,模型生成一系列静止图像。然后将静止图像组合成视频。本发明提出的方法利用高效的注意力调整和结构反演来提高所生成视频的时间一致性。
4. 实验
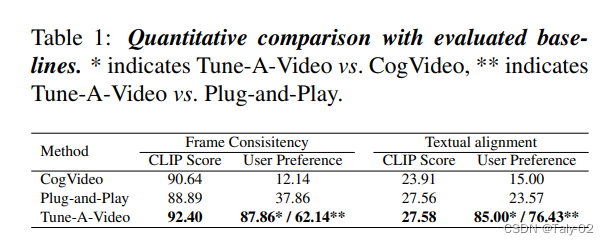
作者为了证明方法的有效性,进行了广泛的实验,以评估所提出的方法在各种应用中的性能。这些实验是在多个数据集上进行的,包括Kinetics-600数据集、Something-Something-Something数据集和YouCook2数据集。实验中使用的评估指标包括弗雷切特入口距离(FID)、盗梦分数(IS)和结构相似度指数(SSIM)。实验结果证明了所提出的文本驱动视频生成和编辑方法的有效性。
看一下可视化的效果:


5. 讨论
该论文在处理输入视频中的多个物体和物体交互方面存在局限性。这是由于拟议框架中使用的文本到图像(T2I)模型的固有局限性。该论文建议使用其他条件信息,例如深度,使模型能够区分不同的物体及其相互作用。但是,这种研究途径留待将来使用。
6. 结论
该论文介绍了一项名为 One-Shot Video Tuning 的从文本生成视频的新任务。该任务涉及仅使用一对文本视频和预先训练的模型来训练视频生成器。拟议的框架Tune-A-Video对于文本驱动的视频生成和编辑既简单又有效。该论文还提出了一种有效的调优策略和结构反演,以生成时间一致的视频。实验表明,所提出的方法在广泛的应用中取得了显著成果。
审核编辑 :李倩
-
Auto Tune Vocal EQ均衡器永久版发布2022-09-11 29440
-
A-Tune系统性能自优化软件2022-04-28 1145
-
欧拉(openEuler)Summit 2021:欧拉demo分享——A-Tune2021-11-10 2019
-
App Tune-up Kit Pofiler工具使用介绍2018-09-21 1869
-
X1_Tune_v1.32016-01-15 628
-
Design and Layout of a Video G2010-10-02 712
-
Digital Video Standards The 192010-07-11 1030
-
Video and Image Processing Up2009-11-24 699
-
allegro如何走蛇行线(delay tune)2009-09-06 2499
-
EL4501 pdf datasheet (Video Fr2009-01-16 627
-
Video Amplifier with Sync Stri2008-09-21 833
-
How to Tune and Antenna Match2008-09-17 1837
-
Composite Video Separation Tec2008-08-19 1012
全部0条评论

快来发表一下你的评论吧 !
