

什么是大数据?大数据技术有哪些?
电子说
描述
“大数据 ”这个概念火了很久,但又很不容易说得清楚(不然呢?怎么会是个位数的回答),这时候买本书来看看可能会更香。
先说结论——大数据技术,其实就是一套完整的“数据+业务+需求”的解决方案。
它其实是一个很宽泛的概念,涉及五个领域:
- 业务分析;2.数据分析;3.数据挖掘;4.机器学习;5.人工智能。
从1到5,越来越需要技术背景;从5到1,越来越贴近具体业务。
其实,除了像搜索引擎这样依靠数据技术而诞生的产品外,大部分互联网产品在生存期,即一个产品从0到1的阶段,并不是特别需要大数据技术的。而在产品的发展期,也就是从“1”到“无穷”的阶段,“大数据技术”对产品的作用才会逐渐体现。
主要原因是初期产品的功能和服务较少,也没有“积累的用户数据”用于模型研发。所以,我们常听说“构建大数据的壁垒”,这里面,“数据技术”是小壁垒,“大数据”本身才是大壁垒。
这里就从“大数据”开始说起。
什么是大数据?
“大数据 ”从字面上看,就是很“大”的“数据”。先别急着打我。有多大呢?
早N多年前,百度首页导航每天需要提供的数据超过1.5PB(1PB=1024TB),这些数据如果打印出来将超过5千亿张A4纸。
5千亿张,是不是很暴力了。
再来两个不暴力的:
“广西人最爱点赞,河北人最爱看段子,最关心时政的是山西人,最关注八卦的是天津。”
这组有趣的数据,是今日头条根据用户阅读大数据得出的结论。
而比这个更精准的数据,是三年前美国明尼苏达州的一则八卦新闻:
一位气势汹汹的老爸冲进Target的一家连锁超市,质问超市为什么把婴儿用品的广告发给他正在念高中的女儿。
但非常打脸的是,这位父亲跟他女儿沟通后发现女儿真的怀孕了。
在大数据的世界里,事情的原理很简单——这位姑娘搜寻商品的关键词,以及她在社交网站所显露的行为轨迹,使超市的营销系统捕捉到了她怀孕的信息。
你看,单个的数据并没有价值,但越来越多的数据累加,量变会产生质的飞跃。
脑补一下上面这个事件中的“女儿”,她在网络营销系统中的用户画像标准可能包括:用户ID、性别 、性格描述、资产状况、信用状况、喜欢的颜色、钟爱的品牌、大姨妈的日期、上周购物清单等等,有了这些信息,系统就可以针对这个用户,进行精准的广告营销和个性化购物推荐。
当然,除了获得大数据的个性化推荐,一不留神也容易被大数据割一波韭菜。
亚马逊在一次新碟上市时,根据潜在客户的人口信息、购物历史、上网记录等,给同一张碟片报出了不同的价格。这场“杀熟事件”的结局就是:亚马逊的 CEO 贝索斯不得不亲自出来道歉,解释只是在进行价格测试。
大数据 ,说白了,就是巨量数据集合。
大数据来源于海量用户的一次次的行为数据,是一个数据集合;但大数据的战略意义不在于掌握庞大的数据信息,而在于对这些含有意义的数据进行专业化处理。
在电影《美国队长2》里,系统能把一个人从出生开始的所有行为特征,如消费行为,生活行为等,作为标签存入数据库中,最后推测出未来这个人是否会对组织产生威胁,然后使用定位系统,把这些预测到有威胁的人杀死。
而在《点球成金》里,球队用数据建模的方式,挖掘潜在的明星队员(但其实这个案例并非典型的大数据案例,因为用到的是早已存在的数据思维和方法)。
麦肯锡全球研究所曾给出过大数据一个相当规矩的定义:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
上面这四个特征,也就是人们常说的大数据的4V特征(volume,variety,value,velocity),即大量,多样性,价值,及时性。
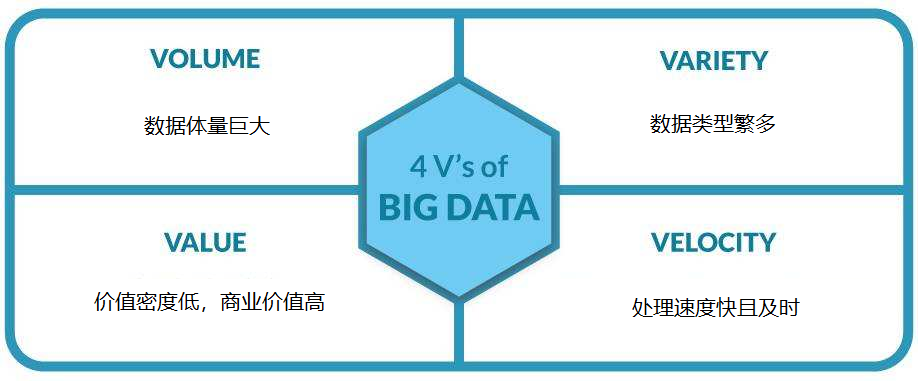
具体来说就是:
- 数据体量巨大(这是大数据最明显的特征),有人认为,大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T);这里按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB(进率2^10)。
不过,数据的体量有时可能并没那么重要。比如13亿人口的名字,只占硬盘几百M空间的数据,但已经是这个领域里非常大的数据。
- 数据类型繁多(也就是多维度的表现形式)。比如,网络日志、视频、图片、地理位置信息等等。
- 价值密度低,商业价值高。以视频为例,一小时的视频,在不间断的监控过程中,可能有用的数据仅仅只有一两秒。因此,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值(所谓“浪里淘金”吧),是最需要解决的问题。
- 处理速度快且及时。数据处理遵循“1秒定律”,可从各种类型的数据中快速获得高价值的信息。
事实上,关于这个“4V”,业界还是有不少争议的。比如阿里技术委员会的王坚博士,就直接把4V“扔”进了***堆。王坚在《在线》这本书里说过:“我分享时说‘大数据’这个名字叫错了,它没有反映出数据最本质的东西。”
他认为,今天数据的意义并不在于有多“大”,真正有意思的是数据变得“在线”了,这恰恰是互联网的特点。所有东西都能“在线”这件事(数据随时能调用和计算),远比“大”更能反映本质。
什么是大数据技术?
对于一个从事大数据行业人来说,一切数据都是有意义的。因为通过数据采集、数据存储、数据管理、数据分析与挖掘、数据展现等,我们可以发现很多有用的或有意思的规律和结论。
比如,北京公交一卡通每天产生4千万条刷卡记录,分析这些刷卡记录,可以清晰了解北京市民的出行规律,来有效改善城市交通。
但这4千万条刷卡数据 ,不是想用就能用的,需要通过“存储”“计算”“智能”来对数据进行加工和支撑,从而实现数据的增值。
而在这其中,最关键的问题不在于数据技术本身,而在于是否实现两个标准:第一,这4千万条记录,是否足够多,足够有价值;第二,是否找到适合的数据技术的业务应用。
下面就来简单说说上述提到的一些和“大数据“”形影不离的“小伙伴们”——
1.云计算
由于大数据的采集、存储和计算的量都非常大,所以大数据需要特殊的技术,以有效地处理大量的数据。
从技术上看,大数据与云计算的关系就像一枚硬币的正反面一样密不可分。大数据无法用单台的计算机进行处理,必须采用分布式架构。它的特色在于对海量数据进行分布式数据挖掘。但它必须依托云计算的分布式处理、分布式数据库和云存储、虚拟化技术。
可以说,大数据相当于海量数据的“数据库”,云计算相当于计算机和操作系统,将大量的硬件资源虚拟化后再进行分配使用。
整体来看,未来的趋势是,云计算作为计算资源的底层,支撑着上层的大数据处理,而大数据的发展趋势是,实时交互式的查询效率和分析能力, “动一下鼠标就可以在秒级操作PB级别的数据”。
2.Hadoop/HDFS /Mapreduce/Spark
除了云计算,分布式系统基础架构Hadoop的出现,为大数据带来了新的曙光。
Hadoop是Apache软件基金会旗下的一个分布式计算平台,为用户提供了系统底层细节透明的开源分布式基础架构。它是一款用Java编写的开源软件框架,用于分布式存储,并对非常大的数据集进行分布式处理,用户可以在不了解分布式底层细节的情况下,开发分布式程序,现在Hadoop被公认为行业大数据标准开源软件。
而HDFS为海量的数据提供了存储;Mapreduce则为海量的数据提供了并行计算,从而大大提高计算效率。它是一种编程模型,用于大规模数据集(大于1TB)的并行运算,能允许开发者在不具备开发经验的前提下也能够开发出分布式的并行程序,并让其运行在数百台机器上,在短时间完成海量数据的计算。
在使用了一段时间的 MapReduce 以后,程序员发现 MapReduce 的程序写起来太麻烦,希望能够封装出一种更简单的方式去完成 MapReduce 程序,于是就有了 Pig 和 Hive。
同时Spark/storm/impala等各种各样的技术也相继进入数据科学的视野。比如Spark是Apache Software Foundation中最活跃的项目,是一个开源集群计算框架,也是一个非常看重速度的大数据处理平台。
打个比方,如果我们把上面提到的4千万条记录比喻成“米”,那么,我们可以用“HDFS”储存更多的米,更丰富的食材;如果我们有了“Spark”这些组件(包括深度学习框架Tensorflow),就相当于有了“锅碗瓢盆”,基本上就能做出一顿可口的饭菜了。

其实,大数据火起来的时候,很多做统计出身的人心里曾经是有一万个***的——因为大数据实在太火,以至于很多公司在招人的时候,关注的是这个人对计算工具的使用,而忽略了人对数据价值和行业的理解。
但目前统计学专业人士确实面临的一个现实问题是:随着客户企业的数据量逐渐庞大,不用编程的方式很难做数据分析。所以,越来越多的统计学家也拿自己开涮:“统计学要被计算机学替代了,因为现在几乎没有非大数据量的统计应用”。
总之,掌握编程的基础,大量的项目实践,是从事大数据技术领域的必要条件。
-
大数据技术是干嘛的 大数据核心技术有哪些2024-01-31 9714
-
什么是大数据2021-08-31 2098
-
大数据技术与应用是学什么的?2021-07-27 2027
-
大数据的定义及其应用2021-07-12 2568
-
大数据平台开发公司有哪些?2018-11-15 4528
-
基于hadoop的免费大数据平台有哪些?2018-11-07 3022
-
大数据开发核心技术详解2018-07-26 2934
-
大数据的数据类型2018-05-11 4306
-
大数据运用的技术2018-04-08 3810
-
常见大数据应用有哪些?2018-03-13 4148
-
如何从零学大数据?2018-03-01 3952
-
为什么小数据比大数据更重要2017-12-27 3050
-
大数据技术经验交流 场景化数据算法2017-06-01 2104
-
探寻大数据时代的商业变革2017-05-27 2160
全部0条评论

快来发表一下你的评论吧 !
