

异构数据库排序一致性填坑教程
电子说
描述
不同数据库对于字符值的排序规则各不相同,要达成在不同数据库上对于同样数据集执行查询语句的输出结果顺序一致性目标,则必须进行相应的设置或改写,本文通过对五种数据库的分析,对该问题进行了较为深入的分析。
01
概述.
在异构数据库之间进行数据迁移之后,为验证数据一致性,就需要比对源库和目标库的同表数据是否一致。
为了提高比对效率,一般而言会将数据排序并抽取出来后进行比对。
在实际过程中发现,指定了ORDER BY的同样两条SQL语句在不同数据库执行后,输出结果集的顺序经常会不同,本文关注该问题的产生并提供了相应的解决方案。
02
数据准备.
本文涉及的数据库为:
- Oracle
- MySQL
- Postgres
- Gauss(华为open Gauss)
- GoldiLocks(科蓝)
所有的数据库均采用UTF8编码,且MySQL数据库不区分大小写建表。
在各数据库中创建一张测试表LEXSORT,该表仅有一个字符列NAME,具体语句如下:
CREATE TABLE LEXSORT ( NAME VARCHAR(10) );
然后将以下数据插入该表中:
INSERT INTO LEXSORT VALUES ('0');
INSERT INTO LEXSORT VALUES ('9');
INSERT INTO LEXSORT VALUES ('a');
INSERT INTO LEXSORT VALUES ('z');
INSERT INTO LEXSORT VALUES ('A');
INSERT INTO LEXSORT VALUES ('Z');
INSERT INTO LEXSORT VALUES ('_');
INSERT INTO LEXSORT VALUES ('~');
INSERT INTO LEXSORT VALUES (NULL);
03
查询结果.
在各个数据库中执行如下查询语句:
SELECT * FROM LEXSORT ORDER BY NAME;
其输出结果见下图:
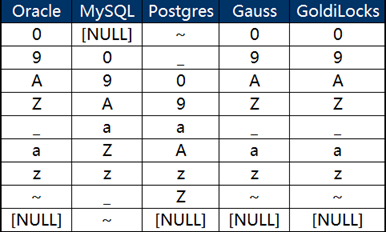
通过上面的结果可以发现:
其一,Oracle、Gauss和GoldiLocks的缺省排序保持一致,而与MYSQL和Postgres的各不相同。
其二,数据排序的不同体现在两个方面上
- NULL值与非NULL字符值之间的顺序
- 非NULL字符值之间的顺序
那么,这背后的机制是什么呢?又该如何解决呢?
04
数据库分析.
其实,产生这一现象的原因是各数据库的缺省排序规则各不相同所致。要解决这一问题,就需要从各数据库自身出发,了解其排序规则,并分别进行设置,才可能达到在不同数据库之间的一致性。
具体如何操作,后文将为您逐一展开。
Oracle数据库
**Oracle数据库提供了控制排序规则的参数,可以在系统级别和会话级别分别进行设置,一般而言,为了不影响其他应用,我们在会话级别进行设置即可。
**
1. NULL值的排序规则
Oracle支持在ORDER BY字句的每个字段上进行控制。可以指定为NULLS FIRST或NULLS LAST,即NULL值排在前面还是后面,缺省为NULLS LAST,即NULL值排在其它非NULL值的后面。
Postgres、Gauss和GoldiLocks也采用了同样的处理,后文不再赘述。
2. 非NULL值的排序规则
Oracle提供了控制参数NLS_SORT来指定排序规则,缺省的排序规则为BINARY,即按照字符串中每个字符的编码值进行排序,另一个常用排序规则为BINARY_CI,即按照二进制值进行排序,同时字母(A-Z,a-z)不区分大小写。
根据以上规则重新修改一下SQL语句或会话设置:
ALTER SESSION SET NLS_SORT=BINARY;
ALTER SESSION SET NLS_SORT=BINARY_CI;
SELECT * FROM LEXSORT ORDER BY NAME NULLS FIRST;
此时不同组合后查询的输出结果见下图:
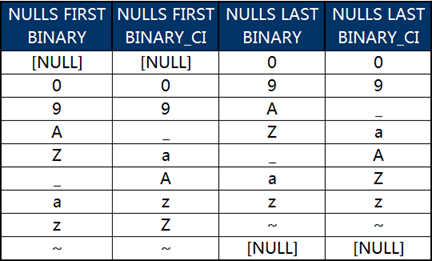
在上图中我们会注意到,不区分大小写排序时字符“_”的位置似乎有些“飘忽不定”。为了解决这个问题,我们把这些字符对应的编码数值出来看一下:

根据编码值就会发现,“飘忽不定”的符号“_”的编码正好位于大写字母和小写字母之间,与它存在同样情况的还有5个字符。这就意味着,Oracle在采用BINARY_CI方式忽略字母大小写排序时,会自动将所有的字母视为了小写字母。
MySQL数据库
MySQL数据库在排序控制方面较弱,首先对于NULL值,MySQL自动视为NULLS FIRST,在ORDER BY字句中无相应的控制选项。
再看一下字母的排序,MySQL在建表时可以指定区分大小写或不区分大小写,一旦指定无法再修改,除非重新建表。
因此对于区分大小写的库,其排序规则会与Oracle的BINARY规则保持一致。
那么不区分大小写的呢?其实在前面的截图中已经有了体现,不过为了清晰起见,我们将Oracle设置为NULL FIRST和不区分大小写,单独拿出来再进行一下比较:
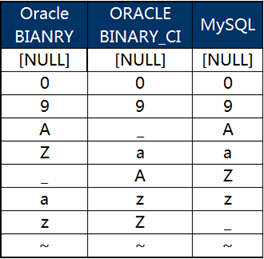
此时我们会发现Oracle和MySQL的排序依然不一致!发生问题的依然是那个“飘忽不定”的“_”。
显然,稍加分析后我们就会知道,在不区分大小写的情形下,MySQL自动将所有字母视为了大写字母进行排序,正是因为这个区别,位于大写和小写字母之间的那六个字符又一次给我们惹了麻烦。
这样,不区分大小写建表的MySQL数据库与Oracle数据库的排序一致性就不存在完美的解决方案!
Postgres数据库
Postgres数据库的缺省排序对我来说一直是个迷……

上图中,符号排在最前面,而“~”的编码却比“_”大,相当于降序;然后是数字和字母,而此时又是升序。鉴于本人对Postgres的研究有限,此处暂不作深究,只专注如何解决排序一致性问题。
Postgres提供了collate语句用以调整排序规则。将排序规则设置为C(必须用双引号括起来且为大写字母)或ucs_basic(如果用双引号括起则必须为小写)则代表按照字符编码排序,此时会区分大小写。
不区分大小写且又要按照编码值进行排序,目前暂未找到合适的方法。
需要注意指定collate和null first时的SQL语句顺序问题,当二者都需指定时示例语句如下,具体的输出结果大家可以自行测试:
SELECT * FROM LEXSORT ORDER BY NAME COLLATE ucs_basic NULLS FIRST;
Gauss数据库
大家都知道Open Gauss实际上是基于Postgres进行的定制,它在增加部分功能的同时也删减了部分Postgres的功能。不过对于ORDER BY子句,Gauss依然保留了Postgres的能力,也就是说collate子句同样适用于Gauss数据库,不过Gauss数据库的缺省排序规则即为按照字符编码值进行排序。
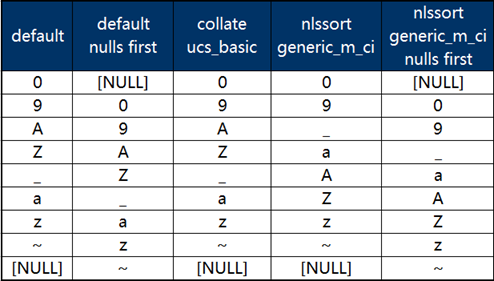
同时,Gauss数据库提供了排序函数NLSSORT,解决了不区分大小排序的问题,此时其排序结果与Oracle保持一致。使用该函数时需指定排序规则,不区分大小写的规则为generic_m_ci,具体SQL示例语句如下:
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci');
SELECT * FROM LEXSORT ORDER BY NLSSORT(NAME,'nls_sort=generic_m_ci') NULLS FIRST;
几种不同组合的查询结果见下图(未写明null first时均为nulls last):
****GoldiLocks数据库 ****
该数据库除了NULLS FIRST/LAST处理与Oracle保持一致外,并没有可以修改排序规则的参数,不过其缺省的排序规则即为按照字符编码值进行排序。因此在排序一致性方面依然可以与Oracle、Postgres、Gauss做到很好的兼容。
05
总结.
虽然本文起源于数据比对场景,不过通过上面的分析,我们可以意识到,排序一致性问题也是异构数据库迁移时必须考虑的问题之一。试想一下,如果不做SQL语句改造,原有的业务查询语句在新数据库中结果集排序可能会发生变化,进而导致后续处理结果也可能发生变化。
通过分析我们也发现,大多数数据库的排序一致性可以通过设置会话参数或修改SQL语句等来实现保持不变,不过部分数据库,例如本例中的MySQL,却缺乏完美的解决方案,那么我们就必须要分析其影响并进行应对。
-
异构计算下缓存一致性的重要性2024-10-24 3666
-
深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别2024-03-11 2417
-
DDR一致性测试的操作步骤2024-02-01 4576
-
Redis缓存与Mysql如何保证一致性?2023-12-02 2095
-
如何解决数据库与缓存一致性2023-09-25 2234
-
什么是数据库营销2023-07-13 1432
-
缓存与数据库一致性问题如何解决2023-03-24 1471
-
理解数据库的事务:ACID,CAP和一致性2020-05-04 1557
-
优化模型的乘性偏好关系一致性改进2018-03-20 976
-
分布式大数据不一致性检测2018-01-12 1082
-
时延异构多自主体系统的群一致性分析2017-12-19 914
-
加速器一致性接口2017-11-17 4629
-
一致性规划研究2009-04-06 728
全部0条评论

快来发表一下你的评论吧 !
