

计算机编码全解析(中)
电子说
描述
4.MBCS、DBCS
前面说的ASCII,EASCII,ISO-8859中的每个字符使用的是8-bits表示的,所以称为“ 单字节字符集 ”(Single-Byte Character Set,简称SBCS)。
但是到了亚洲,如中,日,韩等国家每个文字就是一个字符,对于单字节的字符集来,远远放不下了,于是亚洲国家制定了自己的字符集“多字节字符集” (Multi-Bytes Character Sets,简称MBCS)
windows 系统中,本地字符集就是MBCS,不过由于大部分字符是2字节的,所以又称为“双字节字符集”(Double-Bytes Character Sets,简称DBCS),所以有的时候看到MBCS、DBCS,都是一回事。 MBCS是完全兼容标准ASCII码的 。
5.GB2312、GBK、
当计算机被引入中国后,相关部门设计了GB系列规范(GB为国家的拼音缩写)。按照GB系列编码方案,在一段文本中,如果一个字节是0~127,那么这个字节的含义与ASCII编码相同,否则,这个字节和下一个字节共同组成汉字(或是GB编码定义的其他字符)。因此,GB系列编码方案向下完全直接兼容ASCII编码方案。也就是说,如果当前文本中使用的字符全是ASCII中的字符,则其GB编码和ASCII编码是完成一样的。
GB2312是最早的GB编码格式,收入了不足一万个汉字,基本能满足日常需求,但是中国文件可是博大精深,区区一万字肯定无法满足,于是又在GB2312基础上进行了扩展, 扩展后的编码方案称之为GBK (K是扩的拼音缩写),后来又在GBK的基础上扩了GB18030编码方案,增加了一些少数名族的文字,一些生僻字被编到4个字节。
GB2312,GBK,GB18030(不包括GB13000)每次扩展都会完全兼容前一个版本 。这里要指出,虽然都用多个字节表示一个字符,但是GB类的汉字编码与后文的Unicode编码方案的UTF-8、UTF-16、UTF-32等字符编码方式是毫无关系的
不过,也正因为不得不使用多个字节来表示一个字符,相较于只使用单个字节的ASCII编码方案,GB系列编码方案与后面要介绍的Unicode编码方案一样,无疑导致了更高的复杂度(包括时间复杂度、空间复杂度等)。
比如, 当多字节字符与原先的ASCII字符混用时 :
- 1) 要么将原先的ASCII字符重新编码为多个字节表示,以便与其他多字节字符统一起来(UTF-16、UTF-32等采用的就是这种方法 );
- 2)要么保持ASCII字符为单个字节编码不变,但将其他多字节字符编码中的各个字节的最高位(即首位)设为1,以避免与字节最高位为0的ASCII编码相冲突(GB、UTF-8等采用的就是这种方法) 。
前者具有更高的空间复杂度,因为原先只需要单个字节表示的ASCII字符,现在也必须用多个字节来表示,显然更为耗费存储空间;后者则具有更高的时间复杂度,因为为了避免冲突以及其他种种考虑(比如扩展性、容错性等),使用了更为复杂的编码算法(Encoding Algorithm),无疑更为耗费计算时间。
GB2312
GB2312编码方案,即《信息交换用汉字编码字符集——基本集》,是由中国国家标准总局于1980年发布、1981年5月1日开始实施的一套国家标准,标准号为GB2312-1980。
GB2312编码适用于汉字处理、汉字通信等系统之间的信息交换,通行于中国大陆 ;新加坡等地也采用此编码。中国大陆几乎所有的中文系统和国际化的软件都支持GB2312。
GB2312编码为了兼容ASCII码,所有的编码的字节都是从0x7F之后开始的,一个汉字使用两字节来表示,一个高字节一个低字节,如果一个字节的小余0x7F的值,则表示的是一个ASCII码值。
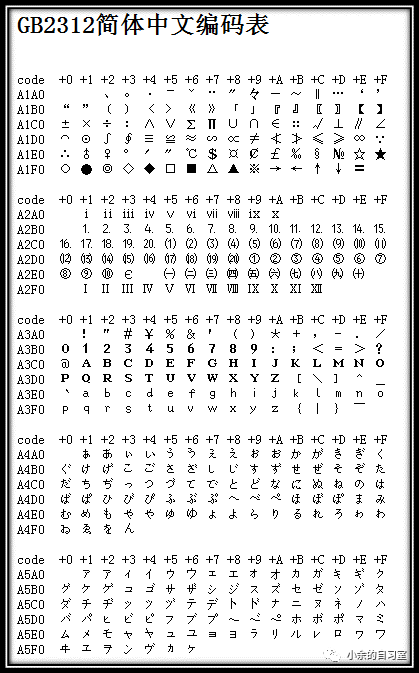
虽然GB2312完全兼容ASCII码,但是其并不兼容其他扩码,如EASCII。
GB2312标准共收录6763个汉字,其中一级汉字3755个,二级汉字3008个;同时,除了汉字,GB2312还收录了包括拉丁字母、希腊字母、日文平假名及片假名字符、俄语西里尔字母在内的 682个字符 。
可能是处于美观的考虑,除了汉字外的682个字符中,包括ASCII里本来就有的数字、标点、字母等字符,又再次编写了两字长的GB2312版本。 这682个双字节编码字符就是常说的“全角”字符,而这些字符所对应的单字节编码的ASCII字符就被称之为“半角”字符。
全角、半角
全角字符是中文显示及双字节中文编码的历史遗留问题。
早期的点阵显示器上由于像素有限,原先ASCII西文字符的显示宽度(比如8像素的宽度)用来显示汉字有些捉襟见肘(实际上早期的针式打印机在打印输出时也存在这个问题),因此就采用了两倍于ASCII字符的显示宽度(比如16像素的宽度)来显示汉字。
这样一来,ASCII西文字符在显示时其宽度为汉字的一半。或许是为了在西文字符与汉字混合排版时,让西文字符能与汉字对齐等视觉美观上的考虑,于是就设计了让西文字母、数字和标点等特殊字符在外观视觉上也占用一个汉字的视觉空间(主要是宽度),并且在内部存储上也同汉字一样使用2个字节进行存储的方案。这些与汉字在显示宽度上一样的西文字符就被称之为全角字符。
而原来ASCII中的西文字符由于在外观视觉上仅占用半个汉字的视觉空间(主要是宽度),并且在内部存储上使用1个字节进行存储,相对于全角字符,因而被称之为半角字符。
后来,其中的一些全角字符因为比较有用,就得到了广泛应用(比如全角的逗号“,”、问号“?”、感叹号“!”、空格“ ”等,这些字符在输入法中文输入状态下的半角与全角是一样的,英文输入状态下全角跟中文输入状态一样,但半角大约为全角的二分之一宽),专用于中日韩文本,成为了标准的中日韩标点字符。而其它的许多全角字符则逐渐失去了价值(现在很少需要让纯文本的中文和西文字符对齐了),就很少再用了。
现在全球字符编码的事实标准是Unicode字符集及基于此的UTF-8、UTF-16等编码实现方式。Unicode吸纳了许多遗留(legacy)编码,并且为了兼容性而保留了所有字符。因此中文编码方案中的这些全角字符也保留下来了,而国家标准也仍要求字体和软件都支持这些全角字符。
不过,半角和全角字符的关系在UTF-8、UTF-16等中不再是简单的1字节和2字节的关系了。具体参见后文。
GBK
GB2312-1980共收录6763个汉字,覆盖了中国大陆99.75%的使用频率,基本满足了汉字的计算机处理需要。
但对于人名、古汉语等方面出现的罕用字、生僻字,GB2312不能处理,如部分在GB2312-1980推出以后才简化的汉字(如“啰”)、部分人名用字(如歌手陶喆的“喆”字)、台湾及香港使用的繁体字、日语及朝鲜语汉字等,并未收录在内。
于是全国信息技术标准化技术委员会利用GB2312-1980未使用的码点空间,收录GB13000.1-1993的全部字符,于1995年12月1日发布了《汉字内码扩展规范(GBK)》(Guo-Biao Kuozhan国家标准扩展码,是根据GB13000.1-1993(GB13000下文有详细介绍),对GB2312-1980的扩展;英文全称Chinese Internal Code Specification)
虽然GBK跟GB2312一样是双字节编码,但GBK只要求第一个字节即高字节大于127就固定表示这是一个汉字的开始(即GBK编码高字节的首位必须是1;0~127当然表示的还是ASCII字符),不再像GB2312一样要求第二个字节即低字节也必须大于127(即GBK编码低字节首位既可以是0,也可以是1)。
正因为如此,作为同样是双字节编码的GBK才可以收录比GB2312更多的字符。
GBK字符集向后完全兼容GB2312,同时还支持GB2312-1980不支持的部分中文简体、中文繁体、日文(不过该字符集不支持韩国文字,也是其在实际使用中与Unicode字符集相比欠缺的部分),共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一体。

GBK的编码框架(Code Scheme):其中GBK/1收录除GB2312字符外的其他增补字符,GBK/2收录GB2312字符,GBK/3收录CJK字符,GBK/4收录CJK字符和增补字符,GBK/5为非中文字符,UDC为用户自定义字符
GB18030
中国国家质量技术监督局于2000年3月17日推出了GB18030-2000标准,以取代GBK。GB18030-2000除保留全部GBK编码汉字之外,在第二字节再度进行扩展,增加了大约一百个汉字及四位元组编码空间。
GB18030《信息交换用汉字编码字符集基本集的补充》是我国继GB2312-1980和GB13000-1993之后最重要的汉字编码标准,是我国计算机系统必须遵循的基础性标准之一。
2005年,GB18030编码方案在GB18030-2000的基础上又进行了扩充,于是又有了GB18030-2005《信息技术中文编码字符集》。
如前所述,GB18030-2000是GBK的升级版本,它的主要特点是在GBK基础上增加了CJK中日韩统一表意文字扩充A的汉字;而GB18030-2005的主要特点是在GB18030-2000基础上又增加了CJK中日韩统一表意文字扩充B的汉字。
微软也为GB18030定义了专门的代码页:CP54936,但是这个代码页实际上并没有真正使用(在Windows 7的“控制面板”-“区域和语言”-“管理”-“非Unicode程序的语言”中没有提供选项;在Windows cmd命令行中可通过命令chcp 54936更改,之后在cmd中可显示中文,但却不支持中文输入)。
GB13000
在所有的GB编码方案中,除了逐步扩展并保持向下兼容的GB2312、GBK、GB18030等GB系列编码方案,还有一个与GB2312、GBK、GB18030等GB系列编码方案不兼容的、 特殊的GB编码方案——GB13000编码方案 。(注意,虽然GBK的制定,主要目的就是为了收录GB13000中的所有字符,但G BK的编码方式与GB13000是完全不同的 。因此,习惯上所称的GB系列编码方案一般并不包括GB13000在内。)
为了对世界各个国家和地区的所有字符进行统一编码,以实现对世界上所有字符在计算机上的统一处理,国际标准化组织制定了新的编码标准——ISO/IEC 10646标准(即Universal Character Set通用字符集,简称UCS,与统一联盟制定的Unicode标准兼容,两者的关系详见后文)。
为了与国际标准接轨,中国于是制定了与ISO/IEC 10646.1:1993标准相对应的中国国家标准——GB13000.1-1993 《信息技术通用多八位编码字符集(UCS)第一部分:体系结构与基本多文种平面》。
2010年又发布了其替代标准——GB13000-2010《信息技术通用多八位编码字符集(UCS)》,此标准等同于国际标准ISO/IEC 10646:2003《信息技术通用多八位编码字符集(UCS)》。
GB13000与国际标准ISO/IEC10646及Unicode标准目前在基本平面(即BMP,详见后文)上基本保持一致。
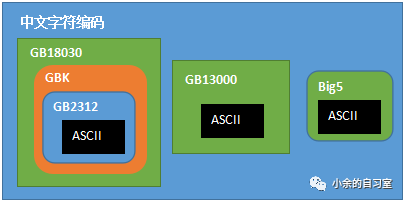
各汉字(中文字符)编码方案之间的关系(Big5为繁体汉字编码方案,主要通行于港澳台地区,本文不作详细介绍)
6.ANSI 编码
ANSI原意是指美国国家标准协会,但是在windows系统中,ANSI编码意思却代表“本地编码”。 。也就是说,在中国代表GBK,在台湾代表Big5,在日本代表JIS,所以windows编程中常说的ANSI字符串,就是指本地编码的字符串,在中国,就是一种DBCS,用1个和2个字节表示一个字符的编码。
这也就是我们使用Notepad++进行文件编写的时候,会默认给我们提供ANSI的编码格式,其实就是GBK编码啦。
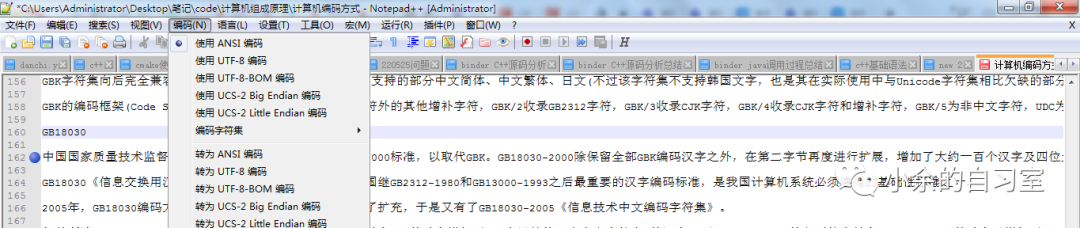
事实上并没有ANSI编码,ANSI是什么,是American National Standards Institute美国国家标准协会,协会,机构而已。ANSI也有自己的ASCII标准。但是我们看到的这个ANSI并不是特指ANSI的ASCII标准,这个应该指所有的本地化编码。
这个是微软的锅 。一开始只有英文操作系统,用ANSI表示ANSI的Extend ASCII编码。但是到了欧洲就是ISO-8859-1编码,到中国应该是GBK编码,日本应该是JIS编码等等,为了把实际编码的差异隐藏起来,用所谓的ANSI编码来表示所有Windows系统上的地区化编码,然后操作系统自己做转换,不同的国家地区,就会对应不同的编码规范。ANSI应该叫地区化编码,只出现在Windows系统中,就好像一种工厂模式,被Windows系统用来统一地区化编码的叫法。
-
DRAM在计算机中的应用2024-07-24 6690
-
工业计算机与普通计算机的区别2024-06-06 3674
-
计算机编码全解析(上)2023-03-30 2267
-
什么是计算机2021-09-10 1554
-
什么是计算机系统、计算机硬件和计算机软件?2021-07-22 2464
-
计算机在教学中的应用2021-07-19 1711
-
计算机算术运算实现原理全解2021-03-26 1029
-
从5个方面来解析计算机中的字符编码概念2018-01-16 8773
-
量子计算机的优点_量子计算机的应用_量子计算机的未来应用2017-11-28 13372
-
可穿戴计算机中的语音识别、编码和合成等技术的介绍2017-09-26 839
-
在计算机与第三方设备通信时,常用的计算机编码2015-07-10 2418
-
用SD卡设计8086全硅计算机的硬盘2010-11-09 879
-
计算机应用基础课程2009-05-15 813
-
计算机应用基础教案2008-09-25 1164
全部0条评论

快来发表一下你的评论吧 !
