

计算机视觉中的主动学习
描述
1. 什么是Active Learning?
Active Learning主动学习是机器学习 (ML) 的一个研究领域,旨在通过以智能方式查询管道的下一个数据来降低构建新机器学习解决方案的成本和时间。在开发新的 AI 解决方案和处理图像、音频或文本等非结构化数据时,我们通常需要人工对数据进行注释,然后才能使用它们来训练我们的模型。这个数据注释过程非常耗时且昂贵。它通常是现代 ML 团队中最大的瓶颈之一。
通过主动学习,您可以创建一个反馈循环,您可以在注释、训练和选择之间进行迭代。使用良好的选择算法,您可以减少训练模型以达到所需精度所需的数据量。
2. 不同的Active learning方法
在进行主动学习时,我们通常使用模型的预测。每当利用模型进行预测时,我们还会获得相关的预测概率。由于模型天生就无法了解自身的局限性,因此我们尝试在研究中使用其他技巧来克服这些局限性。在计算机视觉中,Active Learning 是一种主动学习方法,它可以通过最小化标记数据的量来提高机器学习模型的准确性和效率。以下是一些常见的 Active Learning 方法:
Uncertainty Sampling:选择那些让模型不确定的样本进行标记,如模型输出的概率值最大的前几个样本,或者模型预测结果的方差最大的前几个样本。
Query-by-Committee:从多个训练好的模型中挑选出相互矛盾的样本进行标记,以期望在后续的训练中降低模型的误差。
Expected Model Change:通过计算在当前模型下对标记某个样本的贡献,选择那些最有可能改善模型性能的样本进行标记。
Diversity Sampling:选择那些与当前已经标记的样本差异最大的样本进行标记,以期望能够提高模型的泛化能力。
Information Density Sampling:选择那些在当前模型下信息密度最大的样本进行标记,即选择对模型最有帮助的样本。
Active Transfer Learning:在已经标记的数据集和目标任务的数据集之间进行迁移学习,以期望能够提高模型的泛化能力和训练效率。
这些方法可以单独或结合使用,具体选择哪种方法取决于具体的问题和应用场景。
举个例子,我们不仅可以考虑单个模型,还可以考虑一组模型(集成)。这为我们提供了有关实际模型不确定性的更多信息。如果模型组都同意预测,则不确定性很低。如果他们都不同意,那么不确定性就很高。但是拥有多个模型非常昂贵。像“Training Data Subset Search with Ensemble Active Learning, 2020”这样的论文使用了 4 到 8 种不同的集成方法模型。
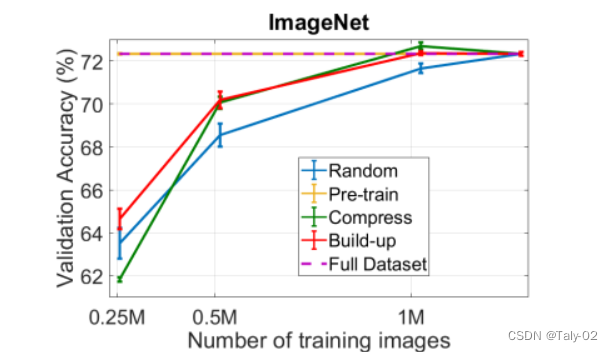
绘图来自“使用集成主动学习训练数据子集搜索,2020”论文,展示了他们的不同方法与 ImageNet 上的随机基线相比如何。
我们可以通过使用 Monte Carlo dropout 来提高效率,我们在模型的最后几层之间添加了 dropout。这允许我们使用一个模型来创建多个预测(使用 Dropout),类似于使用模型集成。但是,这样做的缺点是我们需要更改模型架构并添加 dropout 层。
3. 在Active Learning中利用embedding

插图来自“目标检测的可扩展主动学习,2020”
最近,论文也开始使用embedding。通过embedding,我们可以了解不同样本的相似程度。在计算机视觉中,我们可以使用嵌入来检查相似的图像甚至相似的对象。然后我们可以在embedding空间中使用距离度量,例如欧几里德距离或余弦相似度,并将其与预测的不确定性结合起来。
然而,使用来自同一个模型的embedding和预测有一个缺点,即两者都依赖于模型学习到的相同特征。通常,嵌入是预测前一层或几层模型的输出。为了克服这个限制,我们开始使用来自其他模型的嵌入,而不是我们所说的“任务”模型。任务模型就是您想要使用主动学习改进的实际模型。
我们自己的基准和与自动驾驶、卫星想象、机器人技术和视频分析等领域的数十家公司合作的经验表明,使用使用自我监督学习训练的模型具有最强大的嵌入。最近的模型,如 CLIP 或 SEER 都在使用自监督学习。
4. 我们可以利用active learning做什么?
首先,请注意主动学习是一种工具,与您使用的大多数其他工具一样,您必须微调一些参数才能从中获得最大价值。经过广泛的研究并尝试从最近的主动学习研究中复制许多论文,我们观察到这些基本规则似乎适用于我们认为是“好的”训练数据:
选择多样化的数据——拥有多样化的数据(多样化的图像、多样化的对象)是最重要的因素
平衡数据集——确保数据在你的模式(天气、性别、一天中的时间)之间保持平衡
与模型架构无关 — 根据我们自己的实验,看起来大型 ViT 模型的好数据对小型 ResNet 也有帮助
前两点表明,我们的目标应该是从所有模式中获取等量的多样化数据。第三点很高兴知道。这意味着,我们今天可以用一个模型选择训练数据,一年后训练一个全新的模型时,我们仍然可以重用相同的数据。请注意,这些只是观察。如果实施得当,主动学习可以显着提高模型的准确性。
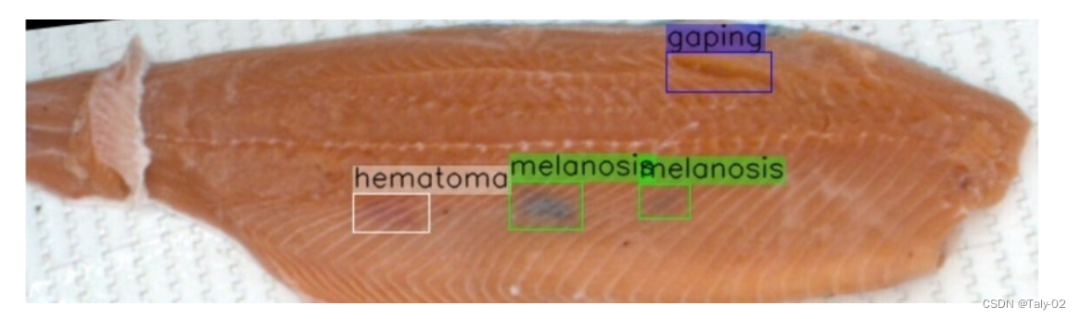
我们评估了结合 AL、多样性和平衡选择在检测鲑鱼片问题任务中的性能。目标是提高鲑鱼“血肿”的模型准确性,因为这是最关键的类别。
5. Active Learning Algorithms的简单Implement
以下是一个简单的Active Learning伪代码:
# 假设我们已经有了一批标记好的数据集合和一个未标记的数据池 labeled_dataset = ... unlabeled_pool = ... # 在每一轮迭代中,我们都会选择一些未标记的数据点并请求标记 while len(unlabeled_pool) > 0: # 从未标记的数据池中选择一些样本 selected_samples = select_samples(unlabeled_pool) # 请求这些样本的标签 labeled_samples = query_labels(selected_samples) # 将新标记的样本添加到已标记的数据集中 labeled_dataset = labeled_dataset + labeled_samples # 更新未标记的数据池,移除已经被标记的样本 unlabeled_pool = remove_labeled_samples(unlabeled_pool, labeled_samples) # 训练模型,根据当前的已标记数据集和模型更新策略 model = train_model(labeled_dataset) # 在验证集上评估模型表现 validation_accuracy = evaluate_model(model, validation_dataset) # 如果模型的表现已经满足了停止准则,则停止训练 if stopping_criterion(validation_accuracy): break
以上伪代码中的主要步骤包括:
从未标记的数据池中选择一些样本
请求这些样本的标签
将新标记的样本添加到已标记的数据集中
移除已经被标记的样本,更新未标记的数据池
根据当前的已标记数据集和模型更新策略训练模型
在验证集上评估模型表现
如果模型的表现已经满足了停止准则,则停止训练。
6. Active Learning的应用场景
Active Learning在计算机视觉中具有广泛的应用前景。以下是一些可能的应用:
目标检测:在目标检测任务中,每个图像都可能包含多个对象。Active Learning可以帮助减少需要手动标注的对象数量,从而降低人力成本。
语义分割:语义分割任务涉及将每个像素标记为特定的对象或类别。Active Learning可以帮助减少需要手动标注的像素数量,从而减少人工标注的工作量。
人脸识别:在人脸识别任务中,Active Learning可以帮助识别出哪些人的图像需要被标记,以及哪些特征可以提高识别准确性。
图像分类:在图像分类任务中,Active Learning可以帮助选择需要标注的图像,以便提高模型的准确性。
总之,Active Learning在计算机视觉中的应用前景非常广泛,可以帮助降低人力成本、提高模型准确性和提高算法的效率。随着技术的进步和数据集的不断扩大,Active Learning将变得越来越重要。
审核编辑:刘清
-
计算机视觉属于人工智能吗2024-07-09 3759
-
深度学习在计算机视觉领域的应用2024-07-01 2938
-
计算机视觉的主要研究方向2024-06-06 3415
-
计算机视觉中的九种深度学习技术2023-08-21 1384
-
计算机视觉的重要性及如何帮助解决问题2022-04-06 5094
-
深度学习与传统计算机视觉简介2021-12-23 2274
-
计算机视觉入门指南2020-11-27 4059
-
深度学习在计算机视觉上的四大应用2020-08-24 6148
-
计算机视觉的发展历史_计算机视觉的应用方向2020-07-30 9429
-
学习计算机视觉的建议有哪些2020-06-18 1832
-
请问计算机视觉与深度学习要看什么书?2020-05-21 2741
-
学习计算机视觉的必读和选读书籍清单你学习过吗2019-10-15 1353
-
计算机视觉与机器视觉区别2018-12-08 14478
全部0条评论

快来发表一下你的评论吧 !
