

Jetson Orin Nano纳米刷机介绍
描述
Jetson Orin Nano 介绍
NVIDIA Jetson Orin Nano 系列模组以最小的 Jetson 外形提供高达 40 TOPS 的 AI 算力,功耗在 7W 至 15W 之间,算力相当于是 NVIDIA Jetson Nano 的 80 倍。Jetson Orin Nano 提供 8GB 和 4GB两个版本,其中 开发套件是8GB 版本。
可以广泛应用于智能机器人开发、智能无人机开发、智能相机开发。从Jetson Orin Nano 到最高性能的 Jetson AGX Orin,有六个基于相同架构的不同模块,是端侧与边缘智能的理想开发载板。
显示器接口是DP的,必须买个DP转HDMI转接头才可以接到HDMI支持的显示器,最重要的这款支持WIFI了。以前的Jetson Nano是USB供电就可以了,这个是配有专门的电源线,19V电源输入,没办法算力强悍肯定得多耗电,相对来说还是低功耗。
JetPack5.1镜像制作
安装JetPack5.1之前先准备好一个microSD卡,最少是64G,推荐买128G的,因为Jetpack5.1安装程序烧录完成已经是20G,再安装一些其它第三方库比如pytorch、torchvision、pyqt5或者QT什么的,就没有多少应用程序开发与部署可用空间了。准备好microSD卡之后,就先下载镜像文件
必须NVIDIA的账号登录之后才可以下载。JetPack5.1已经预安装好了
- CUDA11.4.19 - cuDNN8.6.0 - TensorRT8.5.2 - OpenCV4.5.4还有其他的一些支持工具软件。下载好Jetpack5.1镜像包之后,先下载SD卡格式化软件,格式化SD卡。截图如下:
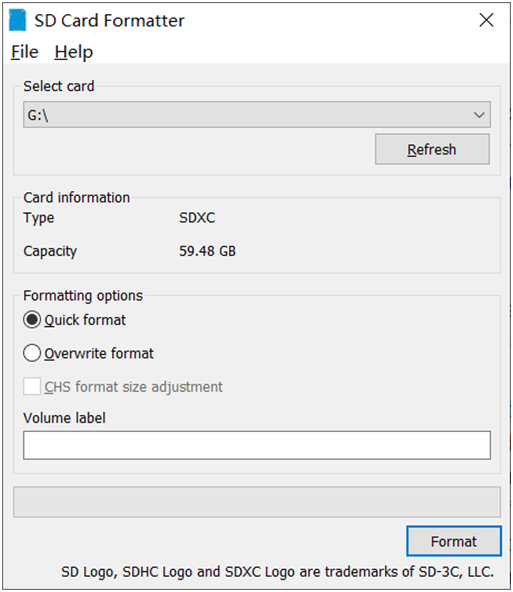
然后下载镜像制作软件
安装好之后选择镜像文件与SD卡,然后开始制作,显示如下:
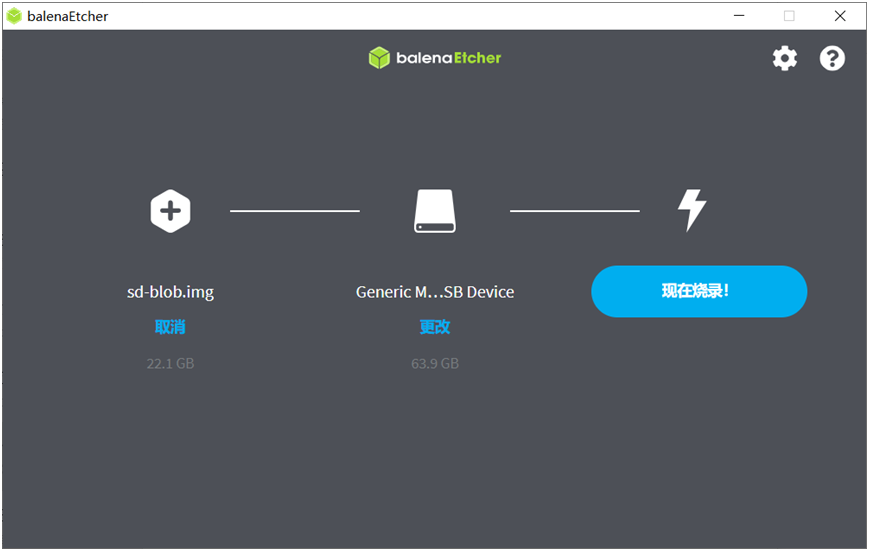
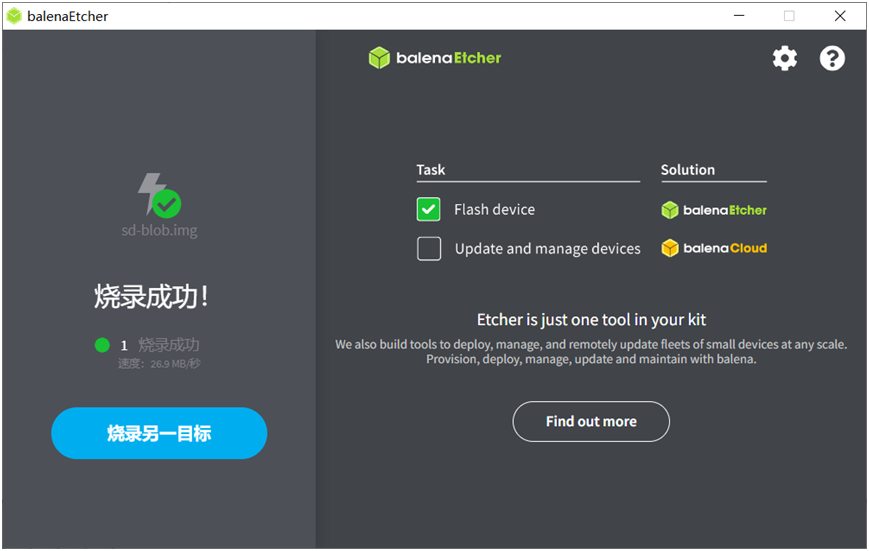
烧录完成以后插到Jetson Orin Nano开发板的风扇下方的卡槽中
安装pytorch与torchvision
安装好了Jetpack5.1之后,我才发现英伟达官方还没有正式发布适配的pytorch版本跟torchvision版本,
意思是用pytorch1.14版本,以此类推torchvision选择0.15.1版本。然后从这里直接下载1.14适配jetpack的版本文件,
下载好之后,别着急安装pytroch,先通过下面的命令行安装好依赖:
sudo apt-get -y install autoconf bc build-essential g++-8 gcc-8 clang-8 lld-8 gettext-base gfortran-8 iputils-ping libbz2-dev libc++-dev libcgal-dev libffi-dev libfreetype6-dev libhdf5-dev libjpeg-dev liblzma-dev libncurses5-dev libncursesw5-dev libpng-dev libreadline-dev libssl-dev libsqlite3-dev libxml2-dev libxslt-dev locales moreutils openssl python-openssl rsync scons python3-pip libopenblas-dev;国内安装经常会有网络无法连接发生各种错误,没事多执行几次命令行肯定可以安装成功的(我的个人经验)。 安装好pytorch相关依赖之后,安装pytorch就很简单:
pip3 install torch-1.14.0a0+44dac51c.nv23.02-cp38-cp38-linux_aarch64.whl安装好pytorch之后,使用下面的命令行从源码安装torchvision 0.15.1版本,先安装依赖,然后下载安装包,最后从源码编译安装,大概十分钟左右就好,相关命令行如下:
sudo apt install libjpeg-dev zlib1g-dev libpython3-dev libavcodec-dev libavformat-dev libswscale-dev pip3 install --upgrade pillow wget https://github.com/pytorch/vision/archive/refs/tags/v0.15.1.zip unzip v0.15.1.zip cd vision-0.15.1 export BUILD_VERSION=0.15.1 python3 setup.py install --user同样不行就执行几次,肯定会成功安装的,我安装与运行的截图如下:
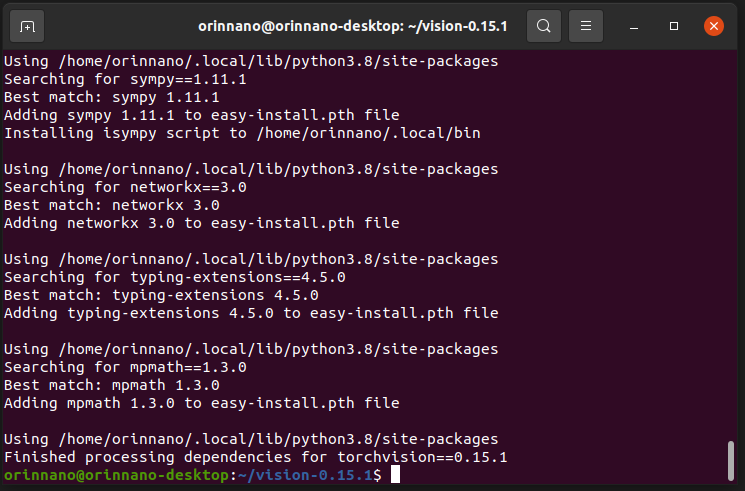
都安装好了用pip3 list查一下,然后我发现pip list显示没有TensorRT,但是我查一下已经有了,只是缺少python包支持,我记得jetpack4.x刷机之后就自动有了,这个怎么没有了,我晕!不过没关系,执行下面的命令行安装python TensorRT支持,执行完之后肯定有了!
最终验证测试如下:
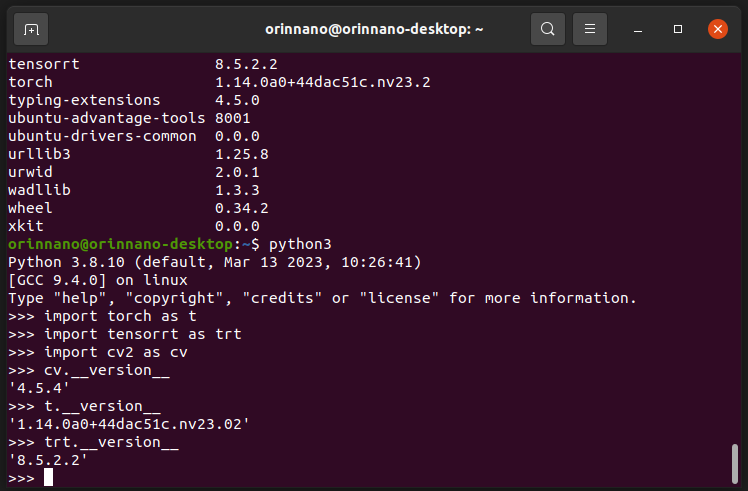
说明一切准备工作就绪了。
说明一下,安装过程中要求输入提示的都输入 y
ONNX2ENGINE
我发现我在TensorRT8.4上面转换的engine文件无法在TensorRT8.5上面成功加载,所以我直接把YOLOv8n的ONNX格式模型文件直接拷贝到Jetson Orin Nano上,然后通过命令行重新生成engine文件:
cd /usr/src/tensorrt/bin ./trtexec --onnx= --saveEngine=相关截图如下:
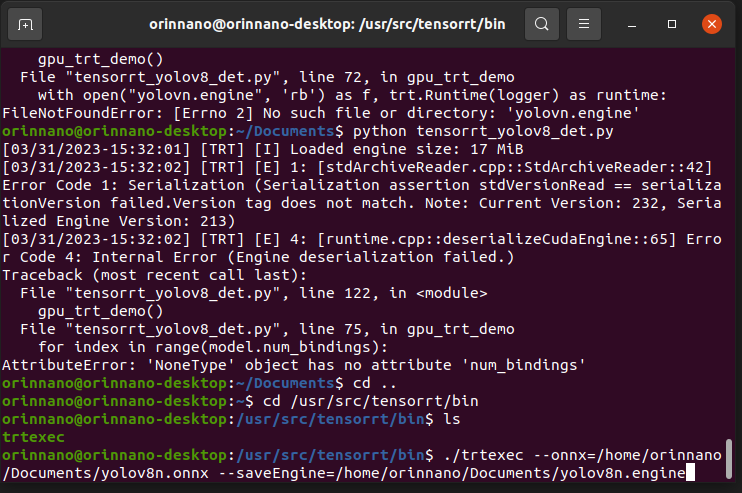
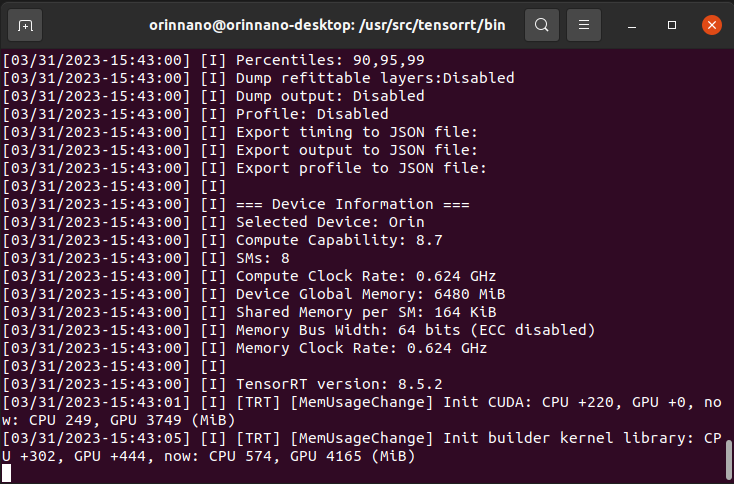
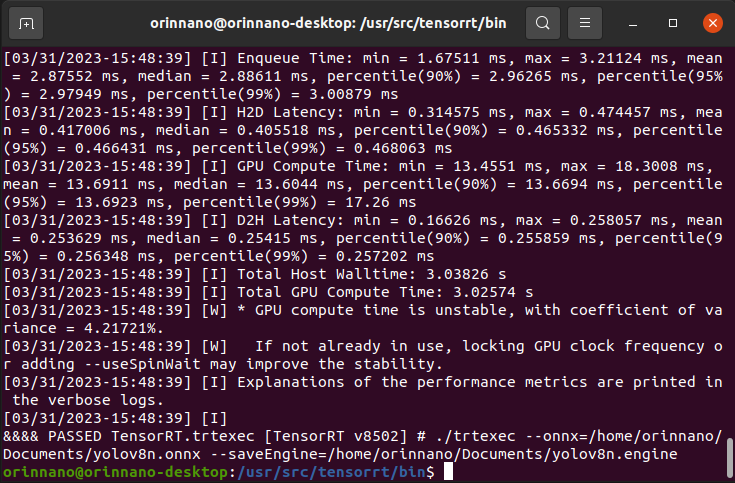
这个时间大概在五分钟左右,需要等一下才可以转换好。
YOLOv8对象检测演示
在此之前,我已经写好了YOLOv8 + TensorRT的测试程序,所以我直接把程序拷贝过来,然后用新生成的yolov8n.engine开启YOLOv8对象检测推理,测试视频运行如下:
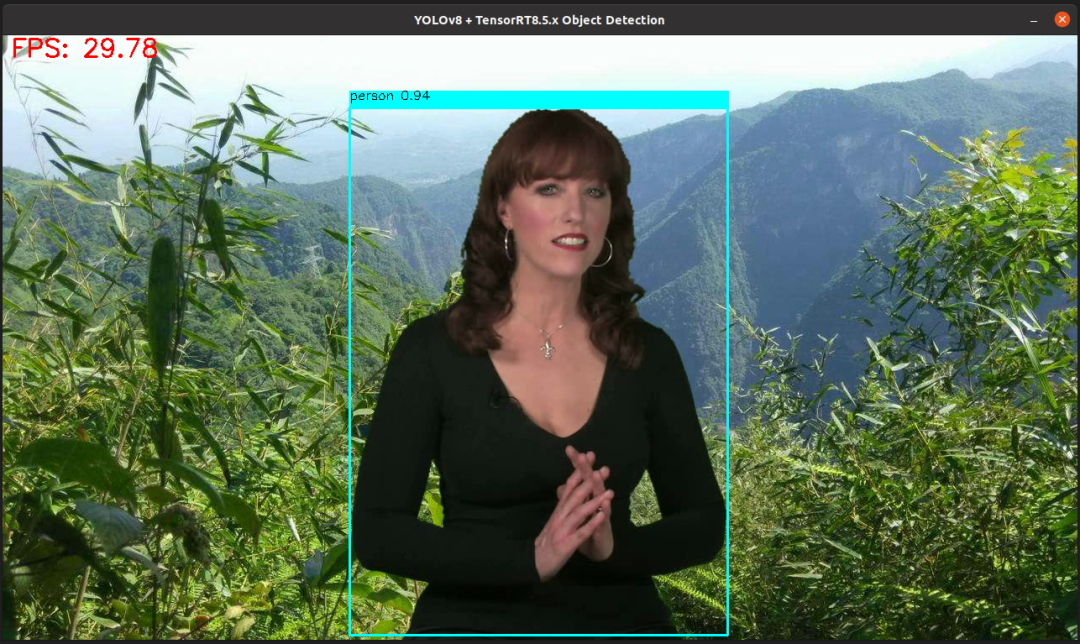

这里程序中FPS计算包含了前后处理,因为两个视频的分辨率不同,导致前后处理的耗时不同,对象我之前在Jetson Nano上的推理速度,我只能说太厉害了,因为我之前Python版本tensorRT的推理这个程序在Jetson Nano一跑过一会就要卡死的感觉,特别慢!相关的测试源码如下:
1import tensorrt as trt
2from torchvision import transforms
3import torch as t
4from collections import OrderedDict, namedtuple
5import cv2 as cv
6import time
7import numpy as np
8
9img_transform = transforms.Compose([transforms.ToTensor(),
10 transforms.Resize((640, 640))
11 ])
12
13def load_classes():
14 with open("classes.txt", "r") as f:
15 class_list = [cname.strip() for cname in f.readlines()]
16 return class_list
17
18
19def format_yolov8(frame):
20 row, col, _ = frame.shape
21 _max = max(col, row)
22 result = np.zeros((_max, _max, 3), np.uint8)
23 result[0:row, 0:col] = frame
24 result = cv.cvtColor(result, cv.COLOR_BGR2RGB)
25 return result
26
27def wrap_detection(input_image, output_data):
28 class_ids = []
29 confidences = []
30 boxes = []
31 out_data = output_data.T
32 rows = out_data.shape[0]
33
34 image_width, image_height, _ = input_image.shape
35
36 x_factor = image_width / 640.0
37 y_factor = image_height / 640.0
38
39 for r in range(rows):
40 row = out_data[r]
41 classes_scores = row[4:]
42 class_id = np.argmax(classes_scores)
43 if (classes_scores[class_id] > .25):
44 class_ids.append(class_id)
45 confidences.append(classes_scores[class_id])
46 x, y, w, h = row[0].item(), row[1].item(), row[2].item(), row[3].item()
47 left = int((x - 0.5 * w) * x_factor)
48 top = int((y - 0.5 * h) * y_factor)
49 width = int(w * x_factor)
50 height = int(h * y_factor)
51 box = np.array([left, top, width, height])
52 boxes.append(box)
53
54 indexes = cv.dnn.NMSBoxes(boxes, confidences, 0.25, 0.25)
55
56 result_class_ids = []
57 result_confidences = []
58 result_boxes = []
59
60 for i in indexes:
61 result_confidences.append(confidences[i])
62 result_class_ids.append(class_ids[i])
63 result_boxes.append(boxes[i])
64
65 return result_class_ids, result_confidences, result_boxes
66def gpu_trt_demo():
67 class_list = load_classes()
68 device = t.device('cuda:0')
69 Binding = namedtuple('Binding', ('name', 'dtype', 'shape', 'data', 'ptr'))
70 logger = trt.Logger(trt.Logger.INFO)
71 with open("yolov8n.engine", 'rb') as f, trt.Runtime(logger) as runtime:
72 model = runtime.deserialize_cuda_engine(f.read())
73 bindings = OrderedDict()
74 for index in range(model.num_bindings):
75 name = model.get_binding_name(index)
76 dtype = trt.nptype(model.get_binding_dtype(index))
77 shape = model.get_binding_shape(index)
78 data = t.from_numpy(np.empty(shape, dtype=np.dtype(dtype))).to(device)
79 bindings[name] = Binding(name, dtype, shape, data, int(data.data_ptr()))
80 binding_addrs = OrderedDict((n, d.ptr) for n, d in bindings.items())
81 context = model.create_execution_context()
82
83 capture = cv.VideoCapture("test.mp4")
84 colors = [(255, 255, 0), (0, 255, 0), (0, 255, 255), (255, 0, 0)]
85 while True:
86 _, frame = capture.read()
87 if frame is None:
88 print("End of stream")
89 break
90 fh, fw, fc = frame.shape
91 start = time.time()
92 image = format_yolov8(frame)
93 x_input = img_transform(image).view(1, 3, 640, 640).to(device)
94 binding_addrs['images'] = int(x_input.data_ptr())
95 context.execute_v2(list(binding_addrs.values()))
96 out_prob = bindings['output0'].data.cpu().numpy()
97 end = time.time()
98
99 class_ids, confidences, boxes = wrap_detection(image, np.squeeze(out_prob, 0))
100 for (classid, confidence, box) in zip(class_ids, confidences, boxes):
101 if box[2] > fw * 0.67:
102 continue
103 color = colors[int(classid) % len(colors)]
104 cv.rectangle(frame, box, color, 2)
105 cv.rectangle(frame, (box[0], box[1] - 20), (box[0] + box[2], box[1]), color, -1)
106 cv.putText(frame, class_list[classid] + " " + ("%.2f"%confidence), (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, .5, (0, 0, 0))
107
108 inf_end = end - start
109 fps = 1 / inf_end
110 fps_label = "FPS: %.2f" % fps
111 cv.putText(frame, fps_label, (10, 25), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)
112 cv.imshow("YOLOv8 + TensorRT8.5.x Object Detection", frame)
113 cc = cv.waitKey(1)
114 if cc == 27:
115 break
116 cv.waitKey(0)
117 cv.destroyAllWindows()
118
119
120if __name__ == "__main__":
121 gpu_trt_demo()
总结:
Jetson Orin Nano从系统烧录到安装好pytorch、torchvision、部署运行YOLOv8推理演示程序基本没有什么坑,唯一需要注意的是numpy别用1.24的最新版本。Jetson Orin Nano算力相比Jetson Nano感觉是一个天上一个地下。
审核编辑:刘清
-
英伟达推出Jetson Orin Nano模组最高40TOPS性能,为机器人和边缘AI提供强动力2022-09-21 10119
-
可适配NVIDIA Jetson Orin NX和Orin Nano的工业级准系统,研华EPC-R7300助力产品开发2023-04-26 1742
-
Jetson Nano简介2021-07-26 1407
-
Jetson Nano具有哪些优势?Jetson Nano怎么安装?2021-09-28 5035
-
Jetson Nano是什么?有何作用2022-01-12 1765
-
NVIDIA推出全新Jetson Orin Nano系统级模组2022-09-22 3237
-
研扬同步在GTC中宣布NVIDIA Jetson Orin Nano 边缘计算AI平台BOXER-8621AI上市2022-09-27 2716
-
将Jetson AGX Orin开发者套件转化为任何Jetson Orin模块2022-09-30 4211
-
使用NVIDIA Jetson Orin Nano解决入门级边缘人工智能挑战2022-10-11 4388
-
NVIDIA Jetson Orin Nano的性能基准2022-10-12 5308
-
GTC23 | 使用 NVIDIA Jetson Orin Nano 开发套件开发 AI 机器人及智能视觉系统2023-03-29 3344
-
NVIDIA发布小巧高性价比的Jetson Orin Nano Super开发者套件2024-12-19 1930
-
研华NVIDIA Jetson Orin Nano系统支持Super Mode2025-03-10 950
-
NVIDIA Jetson系列开发者套件助力打造面向未来的智能机器人2025-12-13 3771
-
NVIDIA Jetson_AGX_Orin模组刷机教程2026-05-13 465
全部0条评论

快来发表一下你的评论吧 !
