

正则表达式(RegularExpression)使用指南
电子说
描述
在芯片开发过程中,正则表达式的使用非常常见。初次上手晦涩难懂,多用几次爱不释手!
本文将概述正则表达式以及实用的匹配规则,并给出使用表达式的辅助工具:CheatSheet和在线测试工具。
01 正则表达式概述
正则表达式,Regular Expression,或缩写regexp,是一种用于描述文本模式(pattern)的表达式。通过该文本模式,我们可以从文本中高效和准确地匹配查找到想要的字符串。
正则表达式的搜索和匹配功能非常强大,以至于几乎所有的脚本语言(比如Python, Perl,JavaScript),Java等高级编程语言,甚至grep等一些Linux命令,都支持正则表达式。
在芯片开发过程中,难免会有很多胶水脚本(glue script)用来串接各种流程,也就不可避免的需要对流程中产生的中间文件做处理,可能是提取、删除或者修改内容等等。另外,在代码review、仿真调试等阶段,通常需要对代码或者仿真日志做信息检索或数据有效性检查。
而这些,都是正则表达式在芯片开发过程中大显身手的地方。
02 Cheat Sheet
CheatSheet可作为日常工具手册,用户可以快速地查阅正则表达式的匹配规则。不过,实际经验告诉我,多用了几次之后,常用的匹配规则也就都记住了。

03 常用关系特性
从CheatSheet可以直接看到正则表达式最基础的匹配规则,包括匹配数字、字母、空白、通配符、开头、结尾等等。但在实际使用中,还需要考虑一些匹配关系,这也是本小节想要呈现的内容。
> 捕获分组(capturing group)和非捕获分组(non-capturing group)
在正则表达式中,可以使用圆括号对表达式进行分组。在匹配完成后,就可以使用分组编号来对圆括号中的内容进行提取。默认情况下,整个表达式的分组编号是0,之后从左往右每遇到一个”(”就分配一个递增的分组编号。举个栗子:
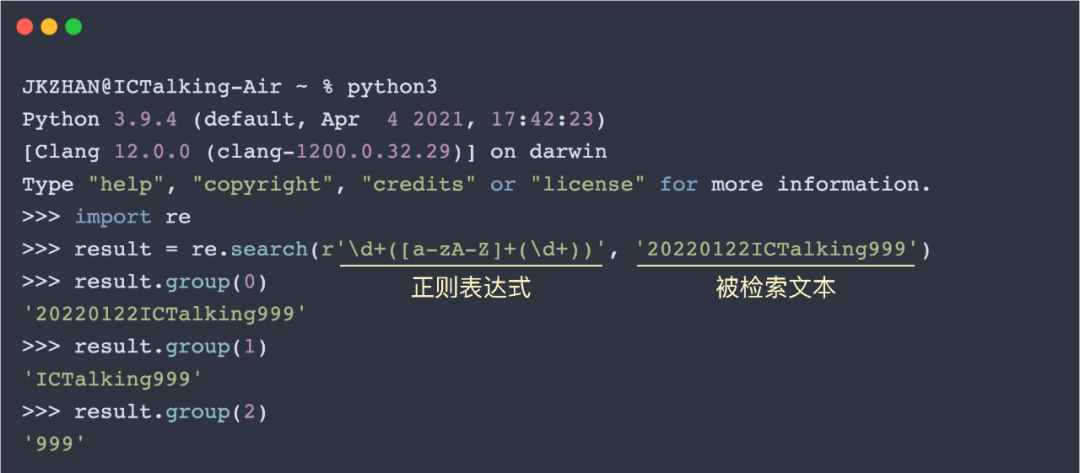
除了如上图所示直接使用分组编号对匹配结果进行索引,我们还可以在表达式内进行分组命名,这样就可以是使用组名来进行索引。举个栗子:
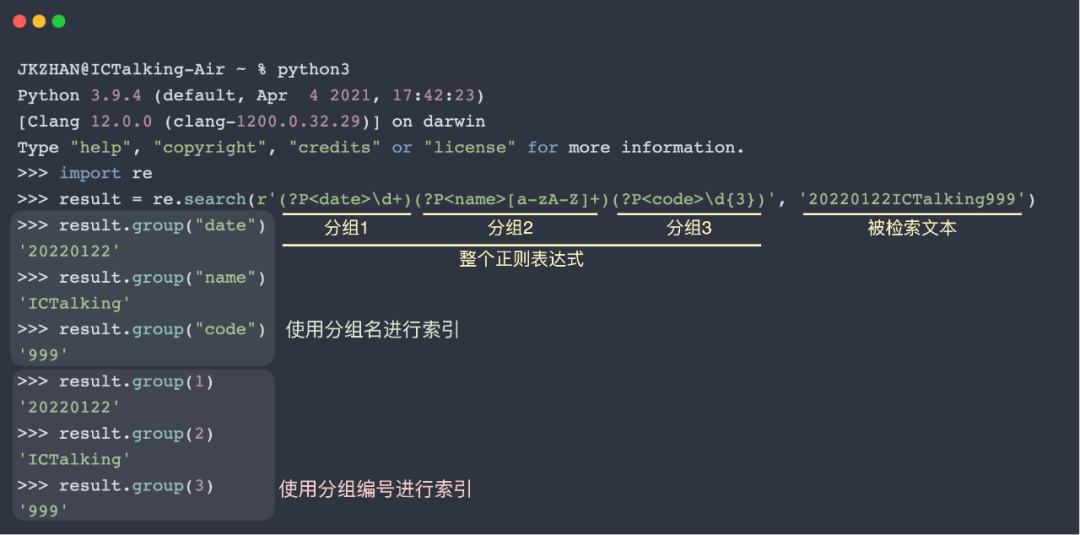
非捕获分组同样使用小括号来进行匹配,其格式是(?:exp)。非捕获分组只能在当前的位置匹配文本,不会被分配分组编号,也即是说,在匹配完成之后无法通过分组编号对其进行索引。
> 前向匹配(lookahead)和后向匹配(lookbehind)
前向匹配和后向匹配,严格来讲也是非捕获分组。在有些地方会叫做环视(lookaround),意味着在匹配的时候需要先“环顾四周”。前后向匹配在实际应用中非常常用。
前向匹配(?=exp),用来匹配右边跟着指定字符串的文本;后向匹配(?<=exp),用来匹配左边跟着指定字符串的文本。举个栗子,匹配2022年且日期为22号的月份:
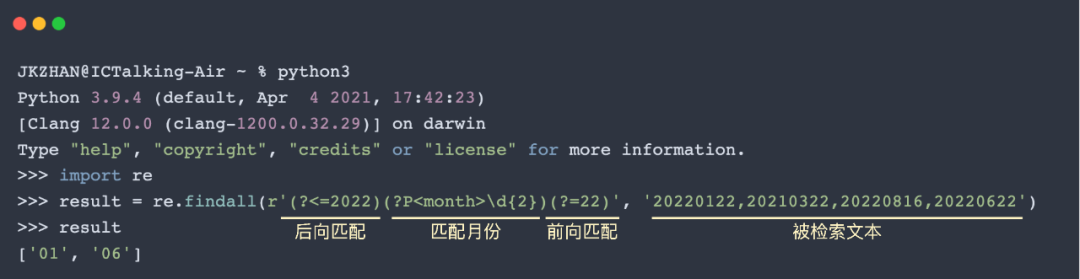
相反,通过把前后匹配表达式中的”=“改成”!”,即(?
> 贪婪匹配(greedy)和非贪婪匹配(non-greedy)
贪婪程度指的是正则表达式匹配停止的条件,贪婪模式会尽可能多的匹配,非贪婪模式会尽可能少的匹配。
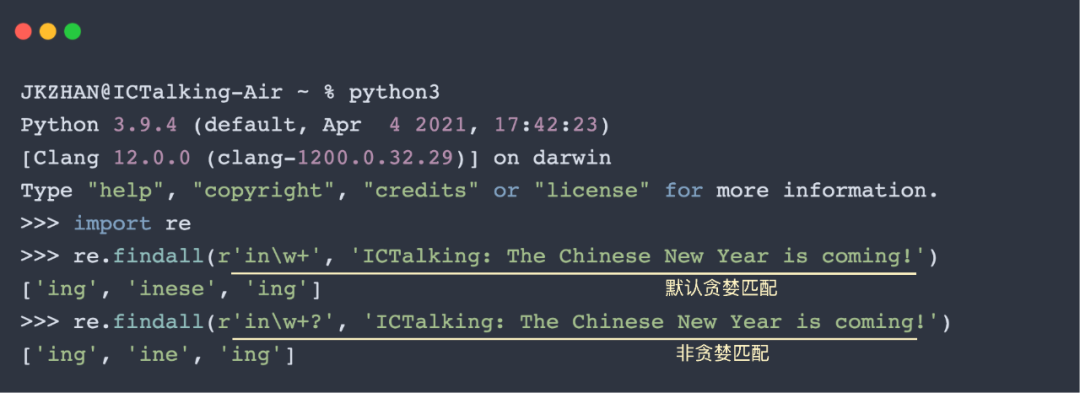
默认的匹配模式是贪婪模式,举个栗子:d+可以匹配大于1个数字的字符串,那么针对被检索文本“20220122”,正则表达式默认尽可能多的匹配,即匹配整个“20220122”,因为它都满足“大于1个数字的字符串”这个pattern,而不是只匹配第一个数字“2”或匹配部分数字“20220”。
非贪婪匹配也是非常常用的匹配模式,有些地方会叫做懒惰匹配(lazy),但都是一个意思:通过添加?来改变正则表达式匹配停止的条件。举个栗子:
04 测试工具
这里推荐正则表达式的在线测试工具。在该网站上,提供了正则表达式的使用参考,并且可以供用户测试自己写出来的正则表达式是否符合预期。
审核编辑:汤梓红
-
什么是正则表达式?正则表达式如何工作?哪些语法规则适用正则表达式?2023-11-03 6397
-
shell正则表达式学习2015-07-25 2881
-
深入浅出boost正则表达式2010-09-08 576
-
PHP正则表达式2016-04-18 514
-
精通正则表达式2016-05-16 835
-
关于java正则表达式的用法详解2017-09-27 677
-
快速入门IPv6和正则表达式2018-03-30 10220
-
Python正则表达式教程之标准库的完整介绍及使用示例说明2019-01-23 1418
-
Python正则表达式的学习指南2020-09-15 1177
-
Python正则表达式指南2021-03-26 1054
-
C语言如何使用正则表达式2022-03-16 5992
-
python正则表达式中的常用函数2022-03-18 2647
-
Linux入门之正则表达式2023-05-12 2046
-
shell脚本基础:正则表达式grep2023-05-29 2472
-
Python中的正则表达式2023-06-21 1943
全部0条评论

快来发表一下你的评论吧 !
