

结构体对齐为什么那么重要?
描述

typedef struct
{
int e_int;
char e_char1;
char e_char2;
}S2;
typedef struct
{
char e_char1;
int e_int;
char e_char2;
}S3;
S2 s2;
S3 s3;
你觉得这俩结构体所占内存是一样大吗?其实不是!
好像也没什么啊,一不一样大对于C语言程序员有什么所谓!
也许你还还感觉不到,上段代码:
S2 s2[1024] = {0};
S3 s3[1024] = {0};
对于32位系统,s2的大小为8K,而s3的大小为12K,一放大,就有很明显的区别了。
再举个例子:
unsigned char bytes[10]={0};
int* p = (int*)&bytes[3];
*p = 0x345678;
你觉得执行上面的代码会发生什么情况?Warining?只是Warning么?!
以前我也没觉得懂得这个结构体对齐或者内存对齐有多重要,直到已经从事了嵌入式开发经验不断积累,才慢慢体会到,这是一种很基础的知识,就因为这个东西不常用,而出现相关的问题是非常致命的,排查起来成本非常高。
有个小伙伴,因为一个内存对齐(结构体对齐相关知识点)问题导致的偶发性Exception问题,折腾了一个多星期。
由于项目接近尾声,出现这种问题,项目经理、老板都操心得不得了。天天不是奶茶水果,就是宵夜,把小伙伴当宝贝来哄,为的就是快速定位这个问题。
然而,他们日以继夜的排查了一个多星期,依然一脸懵逼。
直到让我参与进来支援,我通过仿真方式碰巧捕捉到了这种异常情况。问题的根本原因就是强制类型转换导致的内存对齐问题。篇幅有限,这个故事,以后慢慢细讲。
接下来先看看,结构体对齐的知识点。
结构体对齐,说不难吧,我研究了很多次,都没完全记住;说难吧,理解其原因本质,就易如破竹。结构体对齐,其实其本质就是内存对齐。
什么以最大元素变量为单位,什么最小公倍数等等法则,通通都是让你死记硬背的,没两天就忘了。
为什么要结构体对齐,原因就是内存要对齐,原因是芯片内存的制造限制,是制造成本约束,是内存读取效率要求。
如果你上学的时候认真学习过微机原理,应该还记得,芯片的地址总线和数据总线这个概念吧。没学过微机原理也没关系,8位单片机、16位单片机和32位单片机等等,这些总得听说过吧。
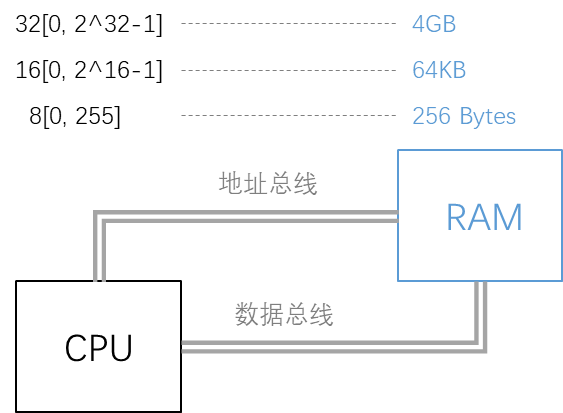
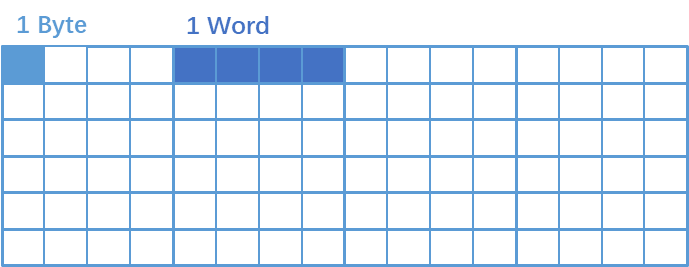 注意:字节,这个概念长度是固定的,就是8bit;而字,却不是固定的,跟CPU或系统位数有关,有时候还会出现字、双字这些概念,举例说明下:
32位计算机:1字=32位=4字节,64位计算机:1字=64位=8字节所以,对于C语言的变量的存放和访问,都会按着这单位来,例如32位系统中,char是一个字节的,就按Byte来,int是4字节的,那么按Word来。为什么要这样呢?
如果,一块内存在地址上随便放的,CPU有可能就会用到多条指令来访问,这就会降低效率。
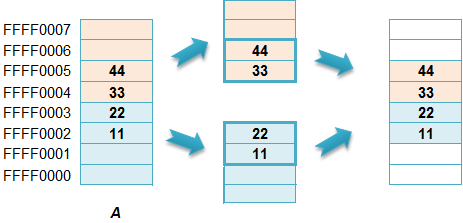
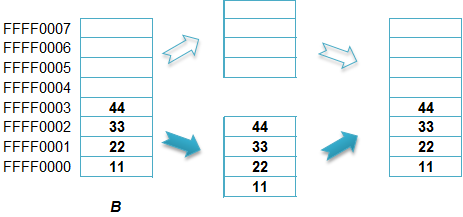
对于32位系统,如下图的A可能需要2条指令访问,而B只需1条指令。
注意:字节,这个概念长度是固定的,就是8bit;而字,却不是固定的,跟CPU或系统位数有关,有时候还会出现字、双字这些概念,举例说明下:
32位计算机:1字=32位=4字节,64位计算机:1字=64位=8字节所以,对于C语言的变量的存放和访问,都会按着这单位来,例如32位系统中,char是一个字节的,就按Byte来,int是4字节的,那么按Word来。为什么要这样呢?
如果,一块内存在地址上随便放的,CPU有可能就会用到多条指令来访问,这就会降低效率。
对于32位系统,如下图的A可能需要2条指令访问,而B只需1条指令。
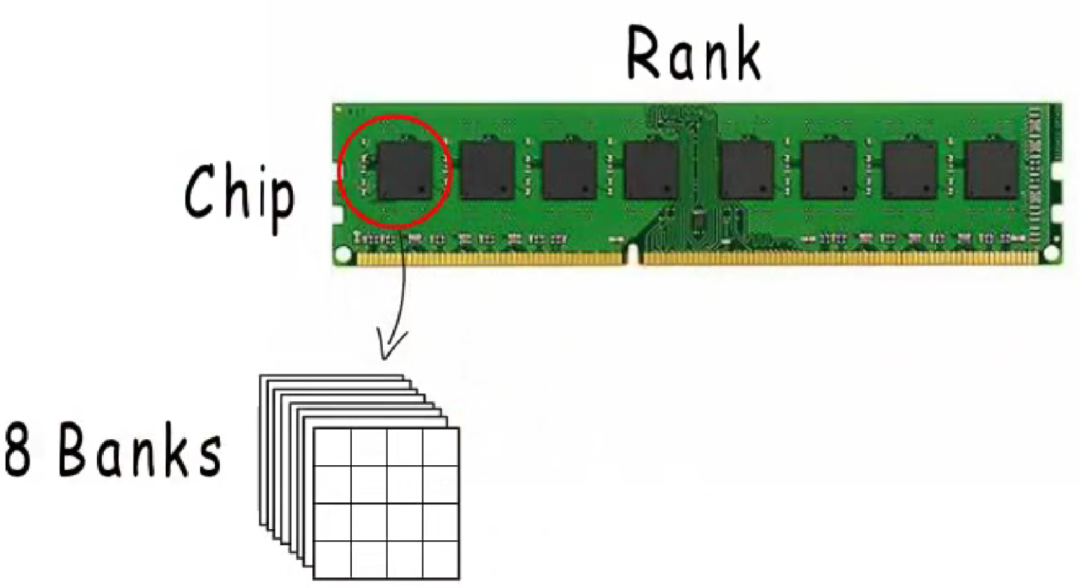
 不仅单片机这样,我们常用的计算机也是这样,你看内存条,长这样的:
不仅单片机这样,我们常用的计算机也是这样,你看内存条,长这样的:

你以为,通过总线的方式可以随便访问一个地址吗
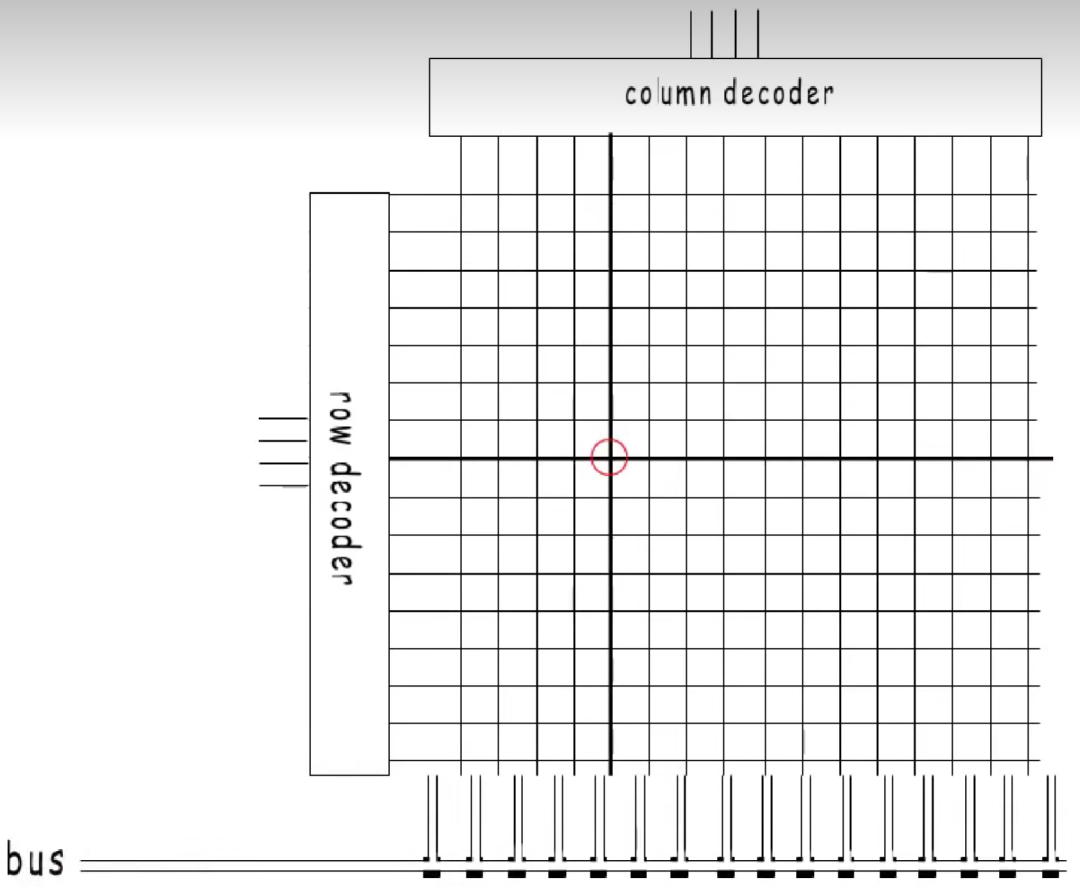
但是,为了提高访问速度,其设计是这样的:
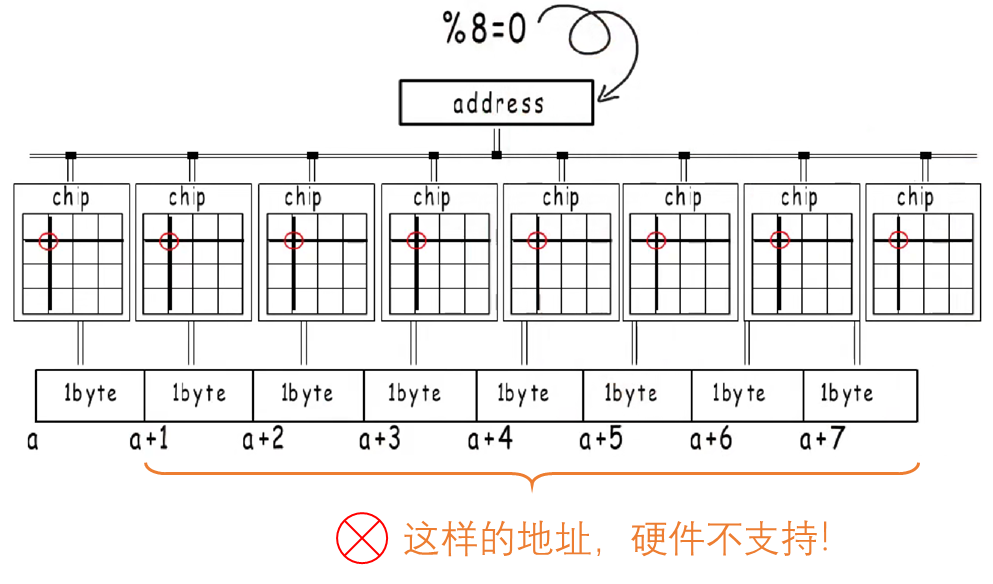
不要瞎猜,直接上代码。每个平台都不一样,请读者自行测试,以下我是基于Windows上MinGW的GCC测的。
void base_type_size(void)
{
BASE_TYPE_SIZE(void);
BASE_TYPE_SIZE(char);
BASE_TYPE_SIZE(short);
BASE_TYPE_SIZE(int);
BASE_TYPE_SIZE(long);
BASE_TYPE_SIZE(long long);
BASE_TYPE_SIZE(float);
BASE_TYPE_SIZE(double);
BASE_TYPE_SIZE(long double);
BASE_TYPE_SIZE(void*);
BASE_TYPE_SIZE(char*);
BASE_TYPE_SIZE(int*);
typedef struct
{
}StructNull;
BASE_TYPE_SIZE(StructNull);
BASE_TYPE_SIZE(StructNull*);
}
结果是:
void : 1 Byte
char : 1 Byte
short : 2 Bytes
int : 4 Bytes
long : 4 Bytes
long long : 8 Bytes
float : 4 Bytes
double : 8 Bytes
long double : 12 Bytes
void* : 4 Bytes
char* : 4 Bytes
int* : 4 Bytes
StructNull : 0 Byte
StructNull* : 4 Bytes
这些内容不用记住,不同平台是不一样的,使用之前,一定要亲自测试验证下。
这里先解释下“模数”的概念:
接着看网上流传一个表:每个特定平台上的编译器都有自己的默认“对齐系数”(也叫对齐模数)。
|
平台 |
长度/模数 |
char |
short |
int |
long |
float |
double |
long long |
long double |
|
Win-32 |
长度 |
1 |
2 |
4 |
4 |
4 |
8 |
8 |
8 |
|
模数 |
1 |
2 |
4 |
4 |
4 |
8 |
8 |
8 |
|
|
Linux-32 |
长度 |
1 |
2 |
4 |
4 |
4 |
8 |
8 |
12 |
|
模数 |
1 |
2 |
4 |
4 |
4 |
4 |
4 |
4 |
|
|
Linux-64 |
长度 |
1 |
2 |
4 |
8 |
4 |
8 |
8 |
16 |
|
模数 |
1 |
2 |
4 |
8 |
4 |
8 |
8 |
16 |
本文的的例子我用的是MinGW32的GCC来测试,你猜符合上表的哪一项?
别急,再看一个例子:
typedef struct
{
int e_int;
double e_double;
}S11;
S11 s11;
STRUCT_E_ADDR_OFFSET(s11, e_int);
STRUCT_E_ADDR_OFFSET(s11, e_double);
结果是:
s11 size = 16 s11.e_int addr: 0028FF18, offset: 0
s11 size = 16 s11.e_double addr: 0028FF20, offset: 8
很明显,上表没有一项完全对应得上的。简单汇总以下我测试的结果:
|
长度/模数 |
char |
short |
int |
long |
float |
double |
long long |
long double |
|
长度 |
1 |
2 |
4 |
4 |
4 |
8 |
8 |
12 |
|
模数 |
1 |
2 |
4 |
4 |
4 |
8 |
8 |
8 |
所以,再强调一下:因为环境的差异,在你参考使用之前,请自行测试一下。
其实,这个模数是可以改变的,可以用预编译命令#pragma pack(n),n=1,2,4,8,16来改变这一系数,其中的n就是你要指定的“对齐系数”。例如
typedef struct
{
char e_char;
long double e_ld;
}S14;
想知道结构图元素内存如何对齐,其实非常简单。其实,你只需知道当前你使用的这个系统的基本类型的sizeof是多少,然后根据这个大小做对齐排布。例如,本文一开始的例子:
typedef struct
{
int e_int;
char e_char1;
char e_char2;
}S2;
typedef struct
{
char e_char1;
int e_int;
char e_char2;
}S3;
S2 s2;
S3 s3;
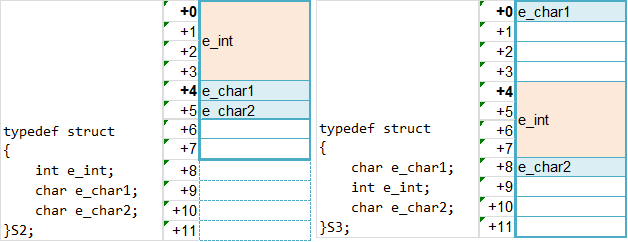
32位系统中,它们内存是这么对齐的:
简单解释下:
S2中的元素e_int是按4字节对齐的,其地址位4整数倍,而e_char1和e_char2就按1字节对齐,紧跟其后面就可以了;
而S3中的元素e_char1是按1字节对齐的,放在最前面,而e_int是按4字节对齐的,其地址位4整数倍,所以,只能找到个+4的位置,紧接着e_char2就按1字节对齐,跟其后面就可以了。
那么sizeof(s2)和sizeof(s3)各是多少怎么算?
也很简单,例如这个32位系统,为了提高执行效率,编译器会让数据访问以4字节为单位的,所以S2里有2个字节留空,即sizeof(s2)=8,而sizeof(s3)=12。
是不是很简单呢!
接着,来个复杂一点的:
typedef struct
{
char e_char1;
short e_short;
char e_char2;
int e_int;
char e_char3;
}S4;
S4 s4;
其内存分布如下:
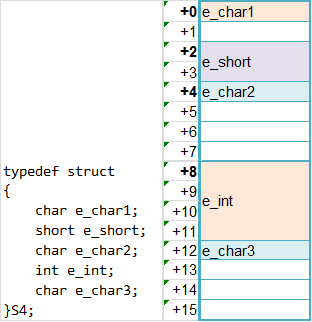 按上面的方法,也不难理解。e_int是不能从+5位置开始的,因为+5不是int的对齐位置,用int去访问+5位置是效率很低或者有问题的,所以它只能从+8位置开始。再复杂一点的呢?来看看union和struct结合的例子:
按上面的方法,也不难理解。e_int是不能从+5位置开始的,因为+5不是int的对齐位置,用int去访问+5位置是效率很低或者有问题的,所以它只能从+8位置开始。再复杂一点的呢?来看看union和struct结合的例子:
typedef struct
{
int e_int1;
union
{
char ue_chars[9];
int ue_int;
}u;
double e_double;
int e_int2;
}SU2;
SU2 su2;
得到:
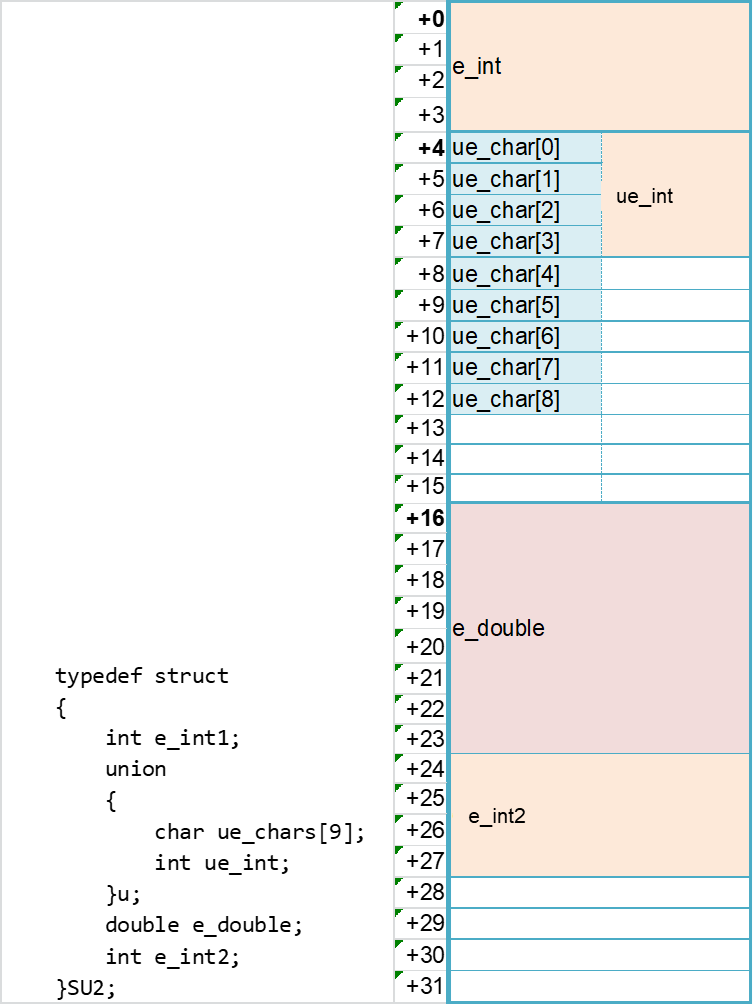
typedef struct
{
int e_int;
char e_char;
}S1;
typedef struct
{
S1 e_s;
char e_char;
}SS1;
typedef struct
{
short e_short;
char e_char;
}S6;
typedef struct
{
S6 e_s;
char e_char;
}SS2;
得出结果:

得出结论:结构体内的结构体,结构体内的元素并不会和结构体外的元素合并占一个对齐单元。
只要技术上面的对齐方法,这些都不难理解。如果你非要一些规则的话,我总结成这样:首先,不推荐记忆这些条条框框的文字,以下内容仅供参考:
- 结构体的内存大小,并非其内部元素大小之和;
- 结构体变量的起始地址,可以被最大元素基本类型大小或者模数整除;
- 结构体的内存对齐,按照其内部最大元素基本类型或者模数大小对齐;
- 模数在不同平台值不一样,也可通过#pragma pack(n)方式去改变;
- 如果空间地址允许,结构体内部元素会拼凑一起放在同一个对齐空间;
- 结构体内有结构体变量元素,其结构体并非展开后再对齐;
- union和bitfield变量也遵循结构体内存对齐原则。
里面涉及到很多测试源码,如果想要获取的话,可以关注公众号,回复"struct"即可获得下载链接。
审核编辑 :李倩
-
C语言结构体对齐介绍2023-07-11 3617
-
C语言-结构体对齐详解2017-07-12 4238
-
CCS3.3 结构体成员对齐2018-06-21 5901
-
请问在ccs4.2 中怎么设置结构体的字节对齐?2018-08-02 4428
-
请问z-stack结构体默认对齐方式是一字节吗?2018-08-18 2120
-
关于labview传入参数到DLL结构体2021-11-08 4565
-
结构体变量的定义与使用变量访问结构体成员2021-12-17 1523
-
测试结构体成员内存对齐的方式方法2021-12-21 851
-
为什么ST库函数结构体没加对齐地址是连续的?2023-10-15 490
-
固态硬盘4K对齐操作对齐的到底是什么?为什么它如此重要?2019-06-04 10265
-
解析C语言结构体字节如何对齐2021-06-12 4017
-
对结构体的对齐理解上有点偏差2022-08-10 2218
-
为什么要结构体对齐?为什么结构体对齐那么重要?2023-05-26 2313
-
什么是结构体的字节对齐现象2023-11-20 1585
-
keil arm工程中结构体1字节对齐如何实现2024-01-05 6775
全部0条评论

快来发表一下你的评论吧 !
