

陈纯院士报告分享:时序大数据流(图)实时计算及智能决策
电子说
描述
人类社会和物理空间在信息空间中映射有两种基本表达结构,分别是针对对象的特征空间结构和针对关系的关联图谱结构。在互联网、移动互联网出现之后,这两种结构所表达的数据都可以拥有时间戳。基于时间戳的数据被称为 “时序数据”,时序数据是从2013年开始提出了的概念。从计算机算法的角度来看,时序数据有几个特点:第一是增量的;第二是时序的,时间不能隔断;第三是动态的;第四需要处理复杂的时序变化。
在2015年的时候,我们开始研究时序数据,有别于历史数据和实时数据的处理,针对时序大数据流的实时计算,我们希望做到每秒千万级并发访问,千亿级流水和高实时。
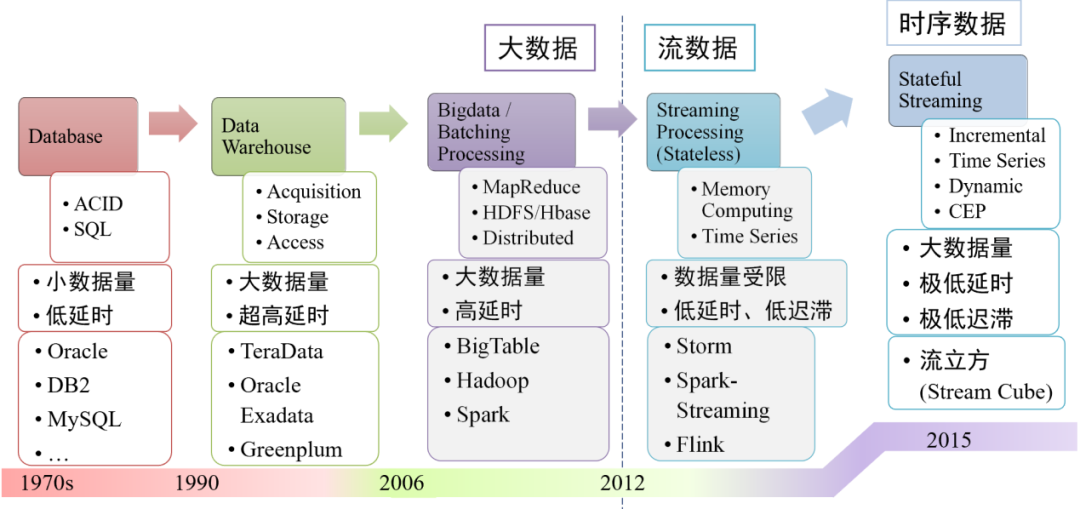
大数据、流数据到“时序大数据”发展历程
针对时序大数据的处理,我们的研究工作涉及到四项关键技术,分别是:
1. 面向复杂统计指标的实时增量计算。基于多项式拆解的复杂算子增量计算算法,实现了在长周期、多尺度、高密度时间窗口中的方差、协方差、K阶中心矩等数十种复杂算子实时计算。例如,从数学上,我们需要把计算协方差的方法重新写成增量的方法,以前的数据不是简单的原数据,而是通过计算以后的中间量,这需要花费很长的时间。我们用了十几年的时间,把每个算法从数学的角度重新定义。
2. 面向时序数据处理的动态时间窗口技术。时间窗口需要提供滚动、滑动的漂移能力,也要支持长周期时间窗口的动态精度控制,并且还要支持基于弹性时间窗口的实时ADHoc查询。
3. 多源时序数据的实时关联计算。关联分析非常重要,不仅仅是一个特征的时序分析,还需要关联起来,这个时候需要有一个关联分析的引擎。针对关联分析的引擎,我们必须在内存里面有非常大的空间,但是要做到实时也是非常难的。
4. 基于流的事件序列识别(复杂事件处理CEP)。主要是支持CEP的增量匹配及数理统计问题,要把增量匹配增量统计。
通过多年的努力,我们基本上解决了四大关键技术问题,形成了我们称之为的流立方技术。流立方能够和均匀流架构完全结合起来,具有历史数据的大数据量的处理能力,同时又具有流处理的实时能力。这是一个大数据处理的方式,因为在具体应用当中,大家会碰到很多大数据的分析,但是很多时候,都没有加上时间这个纬度的分析,当然没有加上时间纬度的分析也许能够解决问题,但是要花费很大的计算量。这四项关键是处理大数据实时时序的大数据流分析,后面结合AI的模型,可以形成一个实时的流的管理。
流立方,除了流之外,还可以在图上展示。特征空间的分析用特征向量就可以,加了一个在每个特征空间里面时间纬度,形成时序的时间分析。图的分析是关联分析,关联分析图也是可以加时间纬度。
如下图所示,在2017年的时候已经知道图数据的处理非常重要。同样的,到了2018年的时候,图越来越大,需要进行实时的图计算,这个时候我们想到很多的方式,分布式的实时图数据也有,类似于流处理,和以前的批处理的架构一样。以前所谓的图处理,现在是实时图处理,关键是加上时序分析。到了2018年有1.0版,目前我们希望有2.0版,这里有大量的工作需要做。尤其是图计算越来越重要,图计算能够产生80%的数据创新。通过图计算分析能够洞彻数据之间的关联关系,提高社会运行效率,这是战略的制高点。
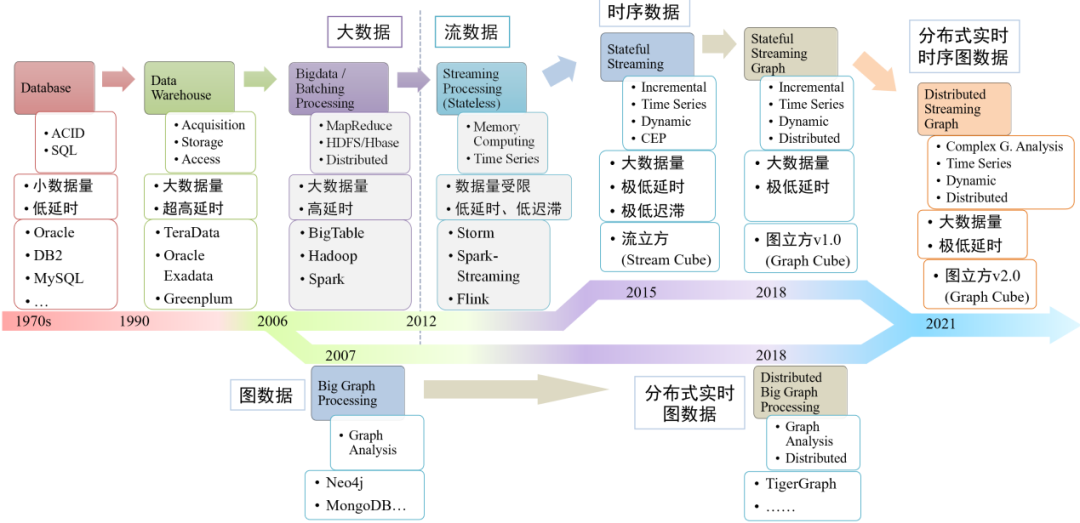
从“时序流”到“时序动态图”的发展历程
图计算也是非常难的,实时图计算,时序图的动态回溯和分析,百亿级顶点,万亿亿的边,两两都有边,时间轴会变一下,有的顶点增加,有的顶点减少,有的关联边没有了,有的边增加了,这个关联度要建立起来。这样的应用案例非常多,去年在新冠期间,在实时的时空关联中,有很多顶点,除了每个人是一个顶点之外,把时空分割起来也是一个顶点。所以,一个人在时间、空间上和你关联起来,就是时空关联。几百亿的顶点和边,怎么做都是困难的,这里通过时序图的实时增量计算和动态回溯,时序图的分布式处理,时序图的智能决策都有很大的挑战性。在我们的研究工作中,这里依然由四项关键技术。
1. 时序图的实时增量计算,包括统计特征,聚合的统计,聚合边的关联。图和流不一样,图实时动,图的结构就变了,到了下一时刻,原来是两亿的点的图,变成了现在的2.3亿,增加三千万点。需要动态建图,并且时序图的增量匹配是个问题。事件驱动的图模式并行匹配,需要很大的工作量,除此之外,更难的是原有的图算法很多,需要进行图算法的增量计算,有大量工作要做。
2. 时序图的实时动态回溯。支持长周期、混合时间尺度的时序计算能力,以及支持弹性时间窗口的视图实时回溯能力。关系在变化,每个切面都要变,需要实时进行查询。
3. 时序图的分布式内存存储引擎。这么大的图做到实时,一定要把数据导进内存,能不能做一个分布式的内存架构显得非常重要。到目前为止,开源的流效益依然不高。我们做的时序图分布式存储引擎叫做cubebose,希望对图的结构更加有效。
4. 面向时序图的实时决策(三核智能决策引擎),把数据从实时采集到实时决策,指标计算特征提取这里面有图数据库,时间关系等。
针对时序图的应用,银行交易反欺诈系统是一个典型的案例。这个系统用到了流的处理引擎,是一个精巧的计算,可以不用大量的算力和计算机来做这个工作。银联要求每秒5万个并发,希望在50毫秒内全球要响应,IBM的硬件要一千多万,我们的算法只使用4台PC设备。如果没有时序流的计算,硬件不仅仅4台,可能要40台都不够。
第二案例是铁路12306,大量的爬票程序存在,需要在每秒170万的并发量,几千台设备管理买票都要宕机。阿里的双11支付的峰值是每秒60多万,铁路12306峰值达到180万,是阿里的双11的3倍。采用了我们的算法,仅仅使用了22台设备。现在铁路12306核心处理只有22台,安装了22个节点的流立方,可以做到每秒200万的处理能力。
在数字经济时代,数据怎么处理,从时间轴上面考虑,这是非常重要的。因为以前的算法没有时间这个纬度,我们通过很多AI模型来计算来解决这个问题,但是加上时间,一切问题迎刃而解。黑客攻击也是一样,以前没有时间戳,没有办法,加上时间戳很多问题很多模型都简化很多,所以我建议大家在具体的数字经济时代,当我们在处理数据的时候,结合场景,加一个纬度(时间)加上去看看,能不能起到一个很好的作用。
审核编辑 :李倩
-
常见大数据应用有哪些?2018-03-13 4171
-
ARMS: 原来实时计算可以这么简单!2018-06-19 3022
-
LabVIEW数据流语言的特点和有效控制方法2019-04-11 1747
-
LabVIEW数据流控制方法研究2009-07-30 706
-
基于数据流的Java字节码分析2009-12-25 1164
-
网络数据流存储算法分析与实现2011-05-26 652
-
基于大数据的流式计算2017-11-22 783
-
大数据环境下的分布式数据流处理关键技术探析2017-12-05 1070
-
数据流的网络实时入侵检测2018-01-17 1261
-
下一代大数据处理引擎,阿里云实时计算独享模式重磅发布2018-11-15 459
-
数据流是什么2019-02-27 8275
-
实时计算在贝壳的实践2020-03-15 1713
-
基于赛灵思提供的实时计算平台的超低时延视频流解决方案2021-04-16 3047
-
金融机构如何构建实时计算能力2022-01-20 2651
-
实时计算汽车数量开源分享2023-06-28 732
全部0条评论

快来发表一下你的评论吧 !
