

GPGPU流式多处理器架构剖析(上)
电子说
描述
流式多处理器(Stream Multi-processor,SM)是构建整个 GPU的核心模块(执行整个 Kernel Grid),一个流式多处理器上一般同时运行多个线程块。每个流式多处理器可以视为具有较小结构的CPU,支持指令并行(多发射)。流式多处理器是线程块的运行载体,但一般不支持乱序执行。每个流式多处理器上的单个Warp以SIMD方式执行相同指令。
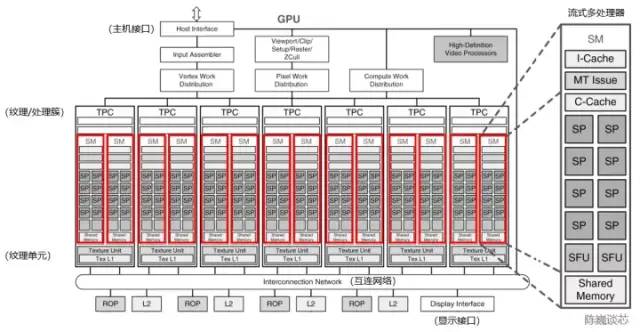
图 3-1 流式多处理器在GPU架构中的位置(以NVIDIA Tesla架构为例,修改自NVIDIA)
3.1 整体微架构
图 3-3是流式多处理器(SM,AMD称之为计算单元)微架构(根据公开文献和专利信息综合获得)。
流式多处理器按照流水线可以分为SIMT前端和SIMD后端。整个流水线处理划分为六个阶段,包括取指、译码、发射、操作数传送、执行与写回。

图 3-2 GPGPU的流式多处理器结构划分
SIMD即单指令多数据,采用一个控制器来控制多组计算单元(或处理器),同时对一组数据(向量)中的每一个数据分别执行相同的操作从而实现空间并行性计算的技术。
SIMT即单指令多线程,多个线程对不同的数据集执行相同指令。SIMT的的优势在于无须把数据整理为合适的矢量长度,并且SIMT允许每个线程有不同的逻辑分支。
按照软件级别,SIMT层面,流式多处理器由线程块组成,每个线程块由多个线程束组成;SIMD层面,每个线程束内部在同一时间执行相同指令,对应不同数据,由统一的线程束调度器(Warp scheduler)调度。
一般意义上的CUDA核,对应于流处理器(SP),以计算单元和分发端口为主组成。
线程块调度程序将线程块分派给 SIMT 前端,线程在流式多处理器上以Warp为单位并行执行。

图 3-3 GPGPU的流式多处理器微架构
流式多处理器中的主要模块包括:
取指单元(I-Fetch):负责将指令请求发送到指令缓存。并将程序计数器 (PC)指向下一条指令。
指令缓存(I-Cache):如来自取指单元的请求在指令缓存中被命中,则将指令传送给译码单元,否则把请求保存在未命中状态保持寄存器(MSHR)中。
译码单元(Decode):将指令解码并转发至I-Buffer。该单元还将源和目标寄存器信息转发到记分牌,并将指令类型、目标地址(用于分支)和其他控制流相关信息转发到 SIMT 堆栈。
SIMT 堆栈(SIMT Stack):SIMT堆栈负责管理控制流相关的指令和提供下一程序计数器相关的信息。
记分牌(Scoreboard):用于支持指令级并行。并行执行多条独立指令时,由记分牌跟踪挂起的寄存器写入状态避免重复写入。
指令缓冲(I-Buffer):保存所有Warp中解码后的指令信息。Warp 的循环调度策略决定了指令发射到执行和写回阶段的顺序。
后端执行单元:后端执行单元包括CUDA核心(相当于ALU)、特殊功能函数、LD/ST单元、张量核心(Tensor core)。特殊功能单元的数量通常比较少,计算相对复杂且执行速度较慢。(例如,正弦、余弦、倒数、平方根)。
共享存储:除了寄存器文件,流式多处理器也有共享存储,用于保存线程块不同线程经常使用的公共数据,以减少对全局内存的访问频率。
3.2 取指与译码

图 3-4 GPU执行流程(修改自 GPGPU-Sim)
取指-译码-执行,是处理器运行指令所遵循的一般周期性操作。
取指一般是指按照当前存储在程序计数器(Program Counter,PC)中的存储地址,取出下一条指令,并存储到指令寄存器中的过程。在取指操作结束时,PC 指向将在下一个周期读取的下一条指令。
译码一般是指将存储在指令寄存器中的指令解释为传输给执行单元的一系列控制信号。

图 3-5 取指译码结构
在GPGPU中,译码之后要对指令进行调度,以保证后继执行单元的充分利用。这一调度通过线程束调度器(Warp Scheduler)实现。
线程束是为了提高效率打包的线程集合(NVIDIA称之为Warps,AMD称为Wavefronts)。在每一个循环中的调度单位是Warp,同一个Warp内每个线程在同一时刻执行相同命令。
取指与译码操作过程如下:
取指模块(I-Fetch)根据PC指向的指令,从内存中获取到相应的指令块。需要注意的是,在GPGPU中,一般没有CPU中常见的乱序执行。

图 3-5 取指模块
-
指令缓存(I-Cache)读取固定数量的字节(对齐),并将指令位存储到寄存器中。
-
对I-Cache的请求会导致命中、未命中或保留失败(Reservation fail)。保留失败发生于未命中保持寄存器 (MSHR) 已满或指令缓存中没有可替换的区块。不管命中或者未命中,循环取指都会移向下一Warp。
在命中的情况下,获取的指令被发送到译码阶段。在未命中的情况下,指令缓存将生成请求。当接收到未命中响应时,新的指令块被加载到指令缓存中,然后Warp再次访问指令缓存。
-
指令缓冲(I-Buffer)用于从I-Cache中获取指令后对译码后的指令进行缓冲。最近获取的指令被译码器译码并存储在 I-Buffer 中的相应条目中,等待发射。
-
每个 Warp 都至少对应两个 I-Buffer。每个 I-Buffer 条目都有一个有效位(Valid)、就绪位(Ready)和一个存于此 Warp 的已解码的指令。有效位表示在 I-Buffer 中的该已解码的指令还未发射,而就绪位则表示该Warp的已解码的指令已准备好发射到执行流水线。

图 3-4 指令缓冲
当Warp内的I-Buffer 为空时,Warp以循环顺序访问指令缓存。(默认情况下,会获取两条连续的指令)这时对应指令在I-Buffer中的有效位被激活,直到该Warp的所有提取的指令都被发送到执行流水线。
当所有线程都已执行,且没有任何未完成的存储或对本地寄存器的挂起写入,则 Warp 完成执行且不再取指。当线程块中的所有Warp都执行完成且没有挂起的操作,标记线程块完成。所有线程块完成标记为内核已完成。
相对于CPU,GPU的前端一般没有乱序发射,每个核心的尺寸就可以更小,算力更密集。
3.3 发射
发射是指令就绪后,从指令缓冲进入到执行单元的过程。
在(译码后的)指令发射阶段,指令循环仲裁选择一个Warp,将I-Buffer中的发射到流水线的后级,且每个周期可从同一Warp发射多条指令。
所发射的有效指令应符合以下条件:
- 在Warp里未被设置为屏障等待状态;
- 在I-Buffer中已被设置为有效指令(有效位被置为1);
- 已通过计分板(Scoreboard)检查;
- 指令流水线的操作数访问阶段处于有效状态。
在GPU中,不同的线程束的不同指令,经由SIMT堆栈和线程束调度,选择合适的就绪的指令发射。
在发射阶段,存储相关指令(Load、Store等)被发送至存储流水线进行相关存储操作。其他指令被发送至后级SP(流处理器)进行相关计算。
-
对称多处理器和非对称多处理器的区别2024-10-10 3871
-
基于VPX6-460的多处理器通信设计2023-11-13 530
-
基于VPX6—460的多处理器通信设计2023-11-08 575
-
GPGPU流式多处理器架构剖析(下)2023-04-03 3195
-
GPGPU流式多处理器架构及原理2023-03-30 4240
-
多处理器通信和LIN模式区别是什么?2021-12-08 1336
-
什么是MSP430多处理器?MSP430多处理器有哪些技术要点?2021-05-27 1769
-
什么是STM8多处理器通信?2020-11-12 1207
-
什么是同步多处理器2020-06-02 1657
-
请问有谁做过串口的多处理器通信吗?2019-09-05 2406
-
多处理器分组实时调度算法2009-12-18 1018
-
基于NiosII的SOPC多处理器系统设计方法2009-10-17 1571
-
总线可重配置的多处理器架构2009-06-13 603
全部0条评论

快来发表一下你的评论吧 !
