

FPGA原型平台到底能跑多快呢?
电子说
描述
前面有讲到过,FPGA原型设计是在芯片流片之前最接近芯片应用真实环境的场景,这个真实环境不仅仅是说外部物理环境接近,还在于性能速率是最接近的,当然真的比起ASIC芯片的实际速率还是差的很多的,当然这个速率已经是流片之前能模拟的最佳场景了,所以对于软件的debug作用就很大了。那么,FPGA原型平台到底能跑多快呢?
FPGA原型平台的性能估计与应用过程的资源利用率以及FPGA性能参数密切相关,甚至FPGA的制程也是一个因素。性能从相关的FPGA资源数据表中的时序信息中容易地提取特殊功能模块的估计。但要评估FPGA原型平台的整体速率是很困难的。但是,可以从综合工具获得整个设计比较好的性能估计。尽管综合工具会考虑布线的延迟,但布线实际延迟时间取决于FPGA的位置和布线过程,并且可能与综合工具的估计不同。在较高的利用率水平下,由于布线可能变得更困难,因此差异可能会很明显,但初始性能估计是一个非常有用的指导。
现代原型验证平台中采用的FPGA芯片,很多是多die封装的芯片(例如VU19P等),使用多die FPGA时,或多或少的都遇到过时序收敛问题;而这些时序收敛的问题很大程度上影响性能,FPGA性能在很大程度上取决于提供给综合工具的约束。而这些约束取决于FPGA工程师的经验,这些约束指导综合工具以及随后的布局布线工具如何最佳地实现期望的性能。以下的总结非常受到认可,因此直接引用过来。
多die芯片其实是SSI(Stacked Silicon Interconnect)芯片,其结构如下图所示。其实就是在一个封装里,把多个芯片,也就是我们说的SLR(Super Logic Region)用interposer“绑”在一起,SLR之间的连接用专用布线资源SLL(Super Long Line)。
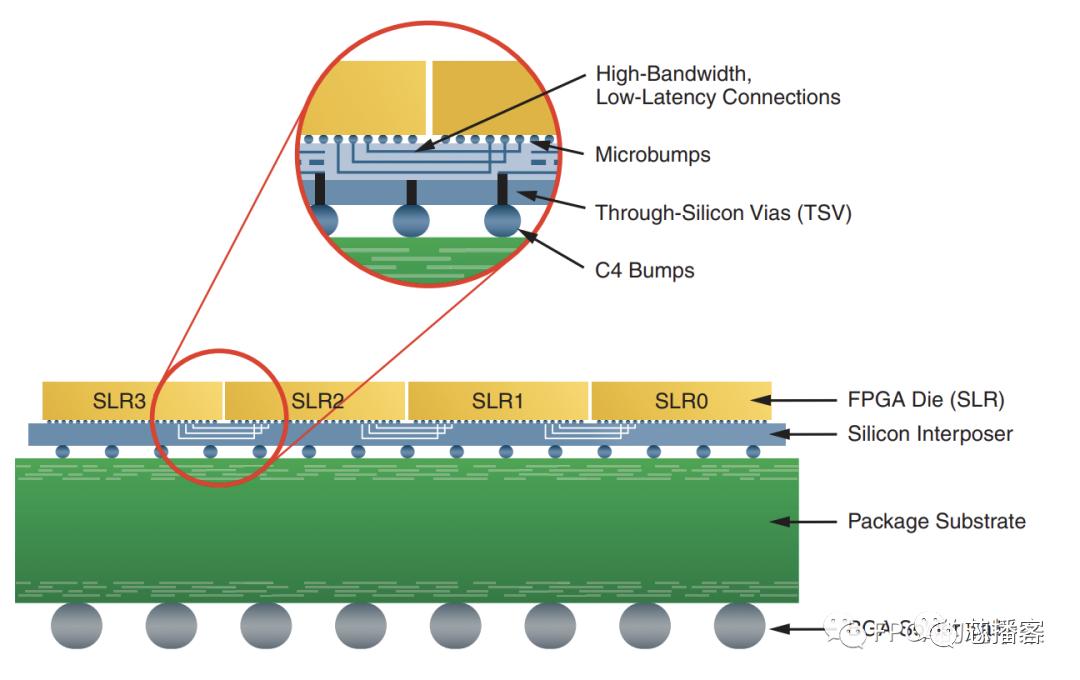
该截图来自xilinx文档872 - Large FPGA Methodology Guide (v14.3)
多die芯片为什么容易出现时序问题了,一个是SLL资源有限,两个SLR之间的SSL资源是有限的。第二个就是本身die之间的走线延时相对比较长。
第一、从方案架构设计的角度看,FPGA的设计其实是数据流0和1的流动路径的设计,即数据流在不同模块之间进行传递。多die的FPGA中,关键就是处理相关数据流跨die传输的问题。在方案设计阶段,首先要考虑一级模块在不同die中的分布。如何合理分配一级模块的布局,主要从以下2个方面考虑。
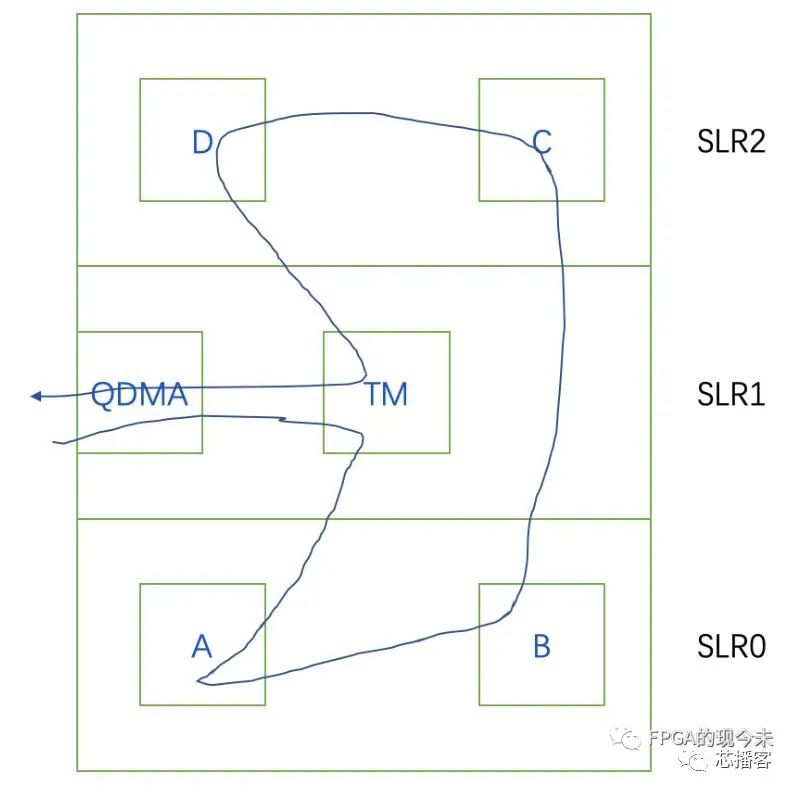
(1)资源,各个一级模块分布在各个die的时候,要进行合理的资源评估,考虑到资源占用情况,建议每个die中LUT在60%左右(原文是不超过70%),REG资源不超过80%,RAM资源不超过80%。即moudle A + moudle B的资源尽量不要超过上述限制,如果超过,就要考虑把一个模块做拆分,移入SLR1或者SLR2中。如果想跑的更快,建议资源利用率在50%左右。
(2)数据流,以die为单位,做到高内聚、低耦合。一级模块(越往顶层的方向)之间的接口要简单,尽量采用流式接口。数据流也要简单,数据流不要在各个die之间来回穿越(input和output减少交互)。即一级模块划分的时候,不但要考虑资源,还要考虑数据流的走向。
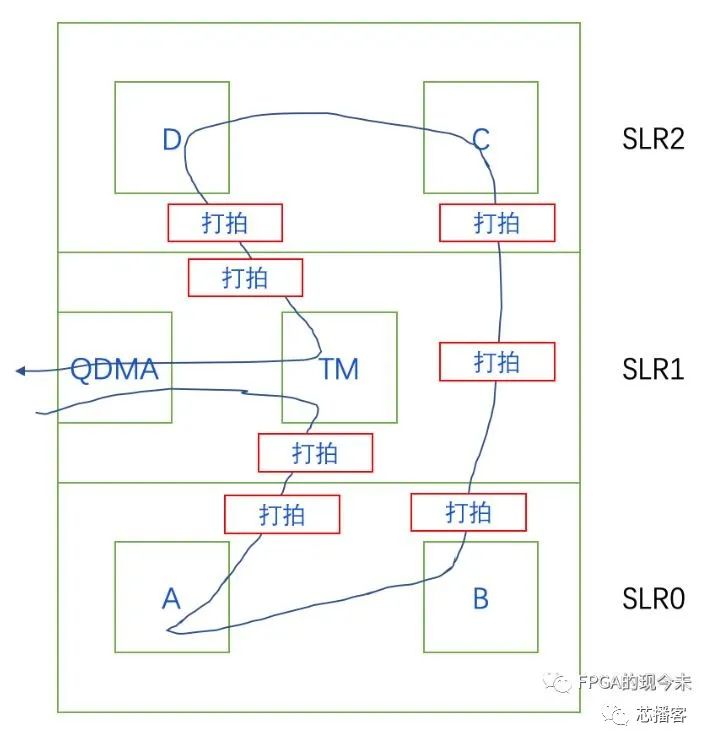
第二、在具体实现中,对于跨die的信号处理,官方的文档(ug949)中提供了2种方式,一种是通过约束的方式使用LAGUNA寄存器,一种是通过自动流水打拍的方式。秉承问题的解决能用代码就不用约束的思想,这里介绍一种和官方指导的第二种方案类似的方法,但是是用RTL代码解决,可移植性更好。如下图所示,红色打拍逻辑(将所有的跨die信号打2-3拍)插入在跨die数据流的两侧。对于穿越整个die的数据流,比如module B到module C的数据流,可以在中间die插入一个过桥的打拍模块。这种方案在实践中被证明也能很好地解决时序收敛问题。
第三、复位信号的处理。跨die逻辑中有一类时序收敛问题就是复位信号的问题。笔者曾遇到一个问题,如下左图所示,复位逻辑在中间的die,复位3个die的所有逻辑。每个die的资源消耗比较高,LUT在70%,RAM在80%,REG相对好点,不到50%。最终因为扇出较大,导致Recovery不满足。
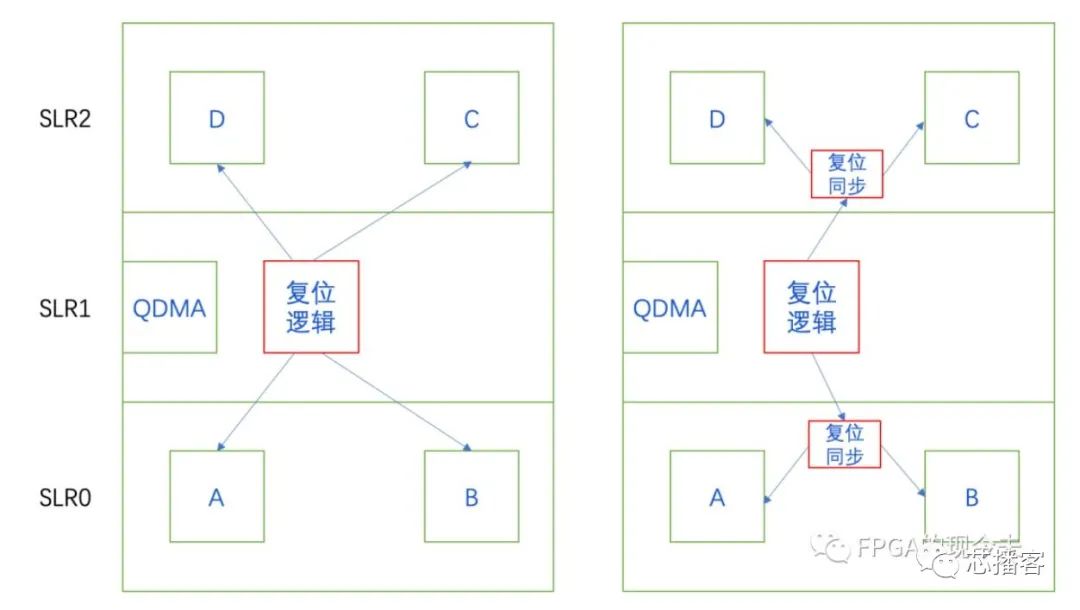
解决方案很简单,就是将复位信号先同步到各个die后,只复位一个die的逻辑,这样很好地解决了大量复位信号跨die问题,如下右图所示。
总结,解决多die FPGA的时序收敛问题,就是合理规划数据流、复位的方案,跨die数据流做好“桥接”。
有许多因素影响映射到多FPGA系统设计的时钟速率,如下所述:
设计类型:高度流水线化的设计可以更好地映射到FPGA的资源架构中,并利用其丰富的FF,可能比流水线化程度较低的设计运行得更快。
设计内部连接:具有复杂连接的设计(其中许多节点具有较高的扇出)将比具有较低扇出连接的设计运行得慢,因为可能存在较长的布线延迟。在设计中也很难找到分区解决方案的位置,因为只有很少的IO可以容纳在FPGA面积内。更高的互连设计将更可能需要将多个信号复用到相同的IO引脚上。
资源利用率级别:通常利用率级别越高,设计越拥挤,导致内部延迟越长,时钟速率越慢。
FPGA性能:FPGA本身的性能。即使采用了比较合适的优化的FPGA版本设计,我们最终也会达到FPGA结构的上限。然而,在大多数情况下,在FPGA的绝对内部时钟速率之前,设计的非优化性质和工具的效率将被视为一个极限。
FPGA间时钟:在多FPGA系统中,FPGA到FPGA的时钟偏移和连接延迟会限制系统时钟速率。虽然FPGA理论上可以以数百兆的时钟速率运行内部逻辑,但其标准IO速度明显较慢,通常是限制系统时钟速率的主要因素。
外部接口:映射到FPGA原型系统中的SoC设计可能以比SoC目标时钟慢的时钟速率运行。除了预期的性能损失外,这并不是很大对于没有外部刺激运行的封闭系统或刺激可以以较慢的速率运行以匹配系统时钟速率的系统而言,这是一个问题。在某些情况下,原型系统必须与无法减缓的刺激交互。
FPGA间连接:当所有FPGA间IO连接耗尽时,可以使用引脚复用。在多时域复用(TDM)中,多个信号通过以比复用在一起的单个信号的数据速率更快的时钟运行而共享单个引脚。例如,当复用四个信号时(TDM为1:4),假设要每个信号以20MHz的速率运行,组合信号将需要至少以80MHz的速率运行并且实际上更高,以便允许第一个和最后一个采样信号的定时。由于FPGA到FPGA的数据速率受到物理FPGA引脚和电路板板间传播延迟的限制,因此本示例中单个信号的有效数据速率将仅小于最大FPGA间数据速率的四分之一。
审核编辑:刘清
-
fpga原型验证平台与硬件仿真器的区别2024-03-15 3074
-
原型平台是做什么的?proFPGA验证环境介绍2024-01-22 3917
-
多台FPGA原型验证平台可自由互连2023-04-11 2092
-
如何建立适合团队的FPGA原型验证系统平台与技术?2023-04-03 2475
-
ARM Cortex-m3到底可以做多快2022-10-26 2735
-
lstm8l152c8t6的dac到底能跑多快2022-02-21 1147
-
STM8L的DAC能跑多快(一)2021-12-27 647
-
FACE-VUP:大规模FPGA原型验证平台2020-05-19 3608
-
“加水就能跑1000公里的车”到底是黑科技还是骗局呢?2019-08-08 6347
-
高频RFID芯片的FPGA原型验证平台的设计及结果介绍2019-06-18 3874
-
高频RFID芯片的FPGA原型验证平台设计及验证2019-05-29 2916
-
CAN FD的波特率到底能跑多快?2018-09-17 17184
-
细数全球十大最快电动车辆大比拼,究竟能跑多快?2012-03-16 84933
-
FPGA设计频率计算方法2011-11-11 2073
全部0条评论

快来发表一下你的评论吧 !
