

一致性哈希算法简介
描述
最近有一位读者跟我交流,说除了算法题之外,系统设计题是一大痛点。算法题起码有很多刷题平台可以动手实践,但系统设计类的题目一般很难实践,所以看一些教程总结也只是一知半解,遇到让写代码实现系统的就懵了。
比如他最近被问到一个大型爬虫系统的设计题,让手写一致性哈希算法,加上一系列 follow up,就被难住了。
说实话这个算法的实现并不难,所以本文就结合一致性哈希算法在工程中的应用场景介绍一下这个算法算法,并给出代码实现,避免大家重蹈覆辙。
一致性哈希算法简介
这个名词大家肯定不陌生,应该也大概理解这个算法的逻辑,不过我这里还是要再介绍一下。
一致性哈希主要解决把数据平均分配到多个节点上的问题,并且某些节点上线/下线后依然能够做到自动负载均衡。
其原理就是抽象出一个哈希环,把服务器节点的 id 通过哈希函数映射到这个哈希环上:
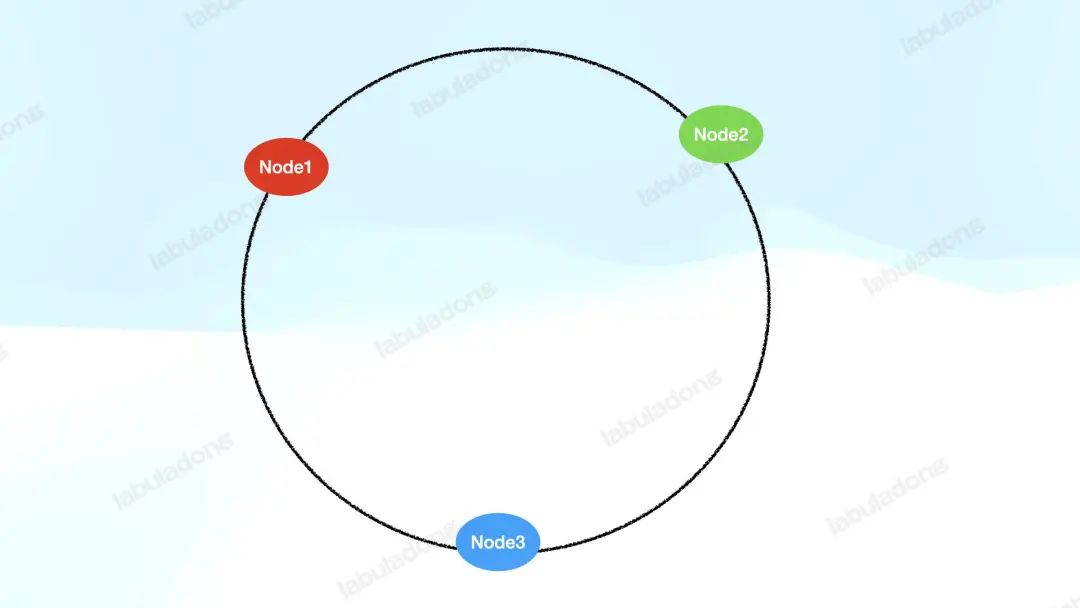
同时,把需要处理的数据也通过哈希函数映射到这个哈希环上,然后顺时针找,遇到的第一个服务器节点来负责处理这个数据:
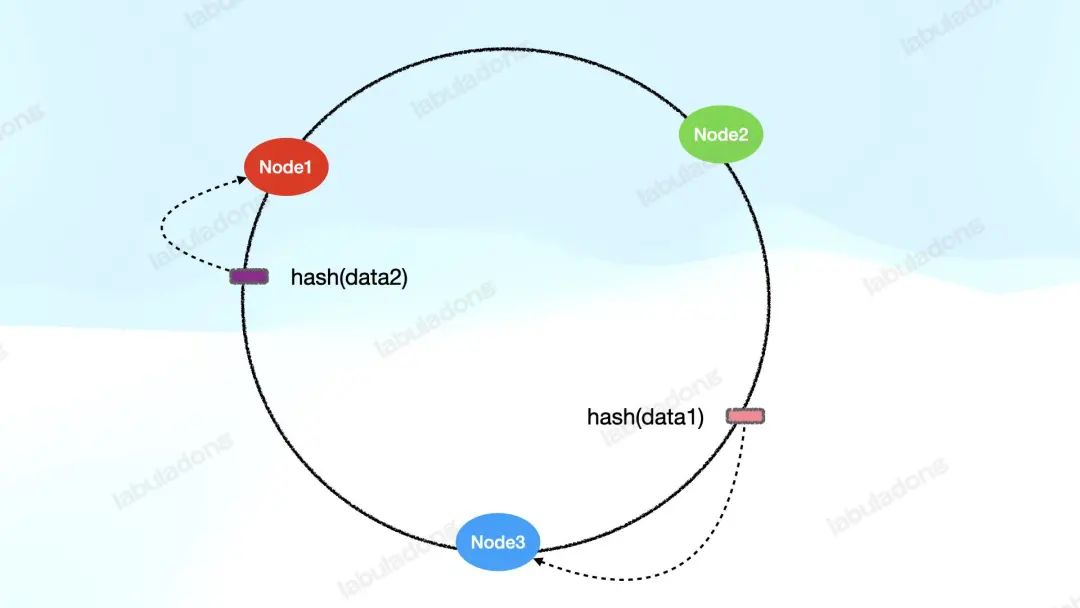
这样一来,我们其实已经提供了一种机制将若干数据分布在若干服务节点上了,不妨称它为 V1 版本的一致性哈希算法。
但 V1 版本的算法还有问题:负载分布很可能不均衡。由于哈希函数的结果是难以预测的,所以可能出现这种情况:
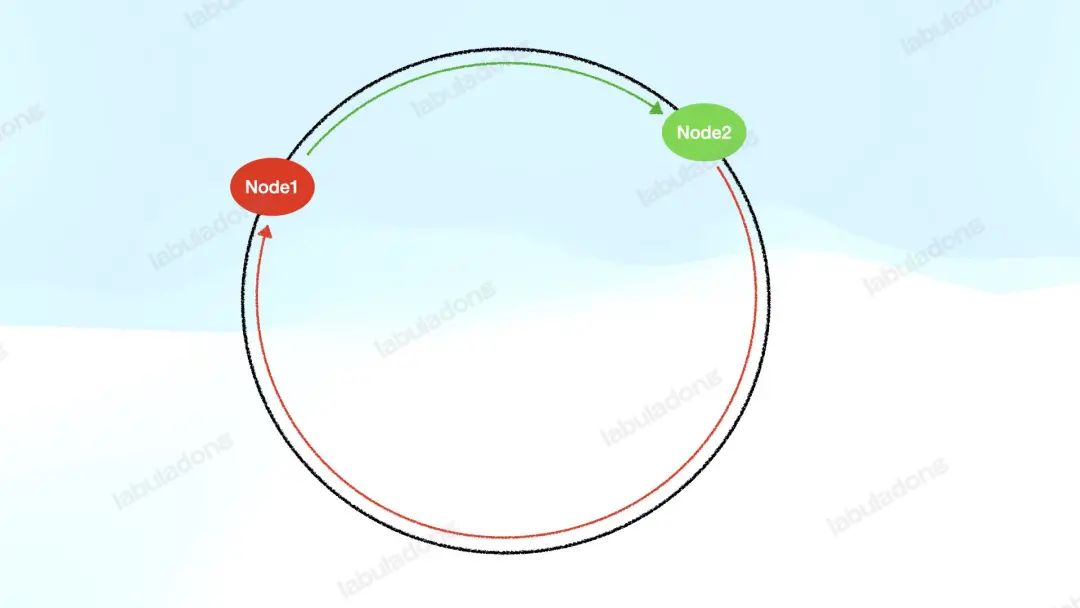
即某些服务器节点要负责的哈希环很长,而其他服务器负责的哈希环很短。这就会导致某些服务器负载很高,而其他的服务器负载很低,很不均衡。
而且,当某个服务器节点下线后,它的负载会顺时针转移到下一个节点上,那么某些特定的节点下线顺序很可能导致某些服务器节点负责的哈希环不断加长,负载不断增加。专业点说,这就是「数据倾斜」。
如何解决数据倾斜的问题呢?可以给每个服务器节点添加若干「虚拟节点」分布在哈希环上,我们不妨称其为 V2 版的一致性哈希算法:
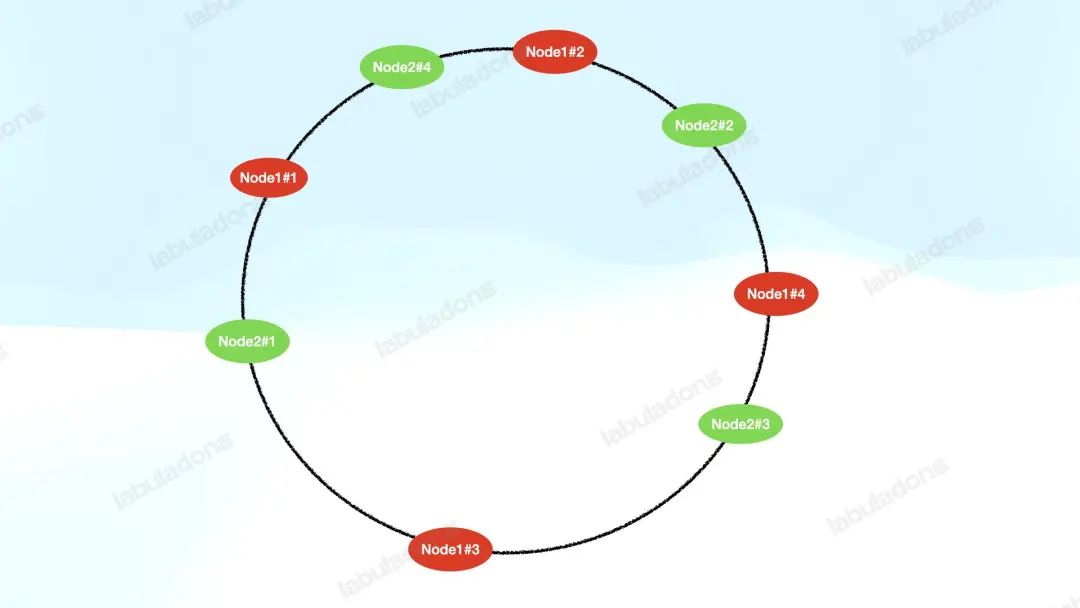
上图给每个 Node 设置了 4 个虚拟节点,这样一来,由于哈希函数的随机性,每个服务器节点的虚拟节点能够平均分布在哈希环上,那么数据就能够比较均匀地分配到所有服务器节点上。
如果某个服务器节点下线,那么该服务器节点的所有虚拟节点都会从哈希环上摘除,它们的负载会迁移到顺时针的下一个服务器节点上。
和 V1 版算法不同的是,因为虚拟节点有多个,它们的下一位不太可能是同一台服务器的虚拟节点,所以它们的负载大概率会均分到多台服务器的虚拟节点上。
综上,V2 版算法通过虚拟节点的方式完美解决了数据倾斜的问题,是不是很巧妙?不过俗话说,纸上得来终觉浅,绝知此事要躬行,我们需要实践才能真正写出正确的一致性哈希算法。
比方说,应该用什么数据结构实现哈希环?如果哈希函数出现哈希冲突怎么办?真正写代码的时候,这些细节问题都是要考虑的。
下面我们就结合代码和实际场景来看看一致性哈希算法的真实应用。
实际场景分析
就以消息队列的消费模型为例吧,我在前文 用消息队列做一个联机游戏 介绍过 Apache Pulsar 的消费模型,Pulsar 通过 subscription 的抽象提供多种订阅模式,其中 key_shared 模式比较有意思:
每条消息会有一个 key,Pulsar 可以根据这个 key 分发消息,保证带有相同 key 的消息分发到同一个消费者上。
官网的这幅图比较好理解,图中的K就是指消息的 key,V就是指消息的数据:
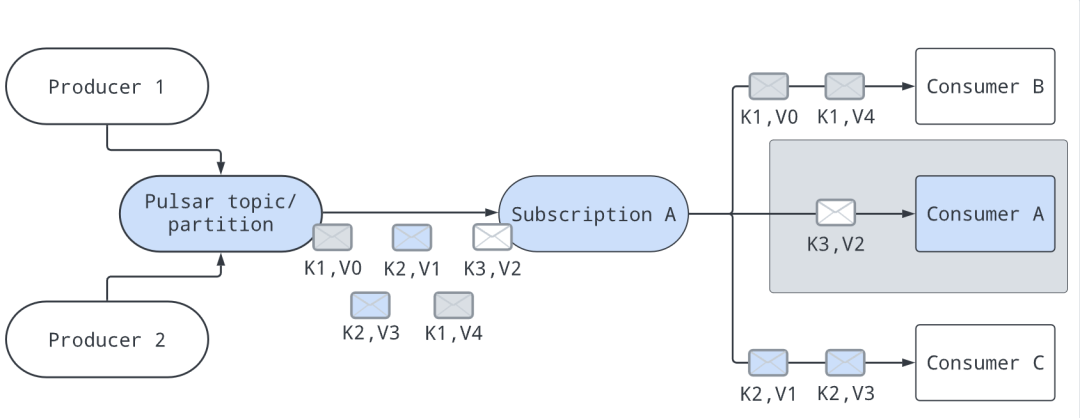
通过某些算法,所有的消息都会有消费者去处理,比如上图就是consumerA负责处理key=K3的消息,consumerB负责处理key=K1的消息,consumerC负责处理key=K2的消息。
当然,如果有 consumer 加入或者离开,消息的分配会重置。比如consumerA下线,那么key=K3的消息会被分配给其他消费者消费;如果有新的消费者consumerD加入,那么当前的分配方案也可能会改变。
简单总结就是:
1、在没有 consumer 加入或者离开的前提下,保证 key 相同的消息都会分配到固定的 consumer,不能一会儿分配到consumerA,一会儿分配给consumerB。
2、如果有 consumer 加入或者离开,可以重新进行分配每个 consumer 负责的 key,要求尽量把 key 平均分配给 consumer,避免出现某些 consumer 负责过多 key 的情况导致数据倾斜。
3、以上两个操作,尤其是给 consumer 重新分配 key 的操作,效率要尽可能高。
对于上述场景,你如何设计分配算法,把这些带有 key 的消息高效地、均匀地分配给所有 consumer 呢?
我们来看看 Pulsar 是如何做的,官网对这部分的实现原理描述的比较清楚,参考链接如下:
https://pulsar.apache.org/docs/next/concepts-messaging/#key_shared
结合我之前在 学习开源项目的套路 中介绍的查看源码背景信息的技巧,可以发现 Pulsar 的 key_shared 模式的消费者实现其实是经历了一些演进的。
最开始的默认实现方式叫做 Auto-split Hash Range,即抽象出来一个[0, 65535]的哈希区间,让每个 consumer 负责这个区间的一部分。比如有C1~C44 个 consumer,那么它们会平分整个哈希区间:
0 16,384 32,768 49,152 65,536 |------- C3 ------|------- C2 ------|------- C4 ------|------- C1 ------|
然后我们可以对每条消息的 key 计算哈希值并求模映射到[0, 65535]的区间中,这样我们就可以选出负责处理这条消息的 consumer 了,而且 key 相同的消息总会分配到这个 consumer 上。
那么如果有 consumer 上线或者下线怎么处理呢?
如果有 consumer 下线,那么它负责的哈希区间会直接交给右侧的 consumer。比如上例中C4下线,那么哈希区间就会变成这样:
0 16,384 32,768 65,536 |------- C3 ------|------- C2 ------|---------------- C1 ---------------|
当然这里也有个特殊情况,就是下线的那个 consumer 右边没有其他 consumer 的情况,我们可以让它左边的 consumer 顶上来。比如现在的C1下线,那么就让左边的C2负责C1的区间:
0 16,384 65,536 |------- C3 ------|-------------------------- C2 -----------------------|
如果有 consumer 上线,那么算法可以把最长的哈希区间平分,分一半给新来的 consumer。比如此时C5上线,我们就可以把C2负责的一半哈希区间分给C5:
0 16,384 40,960 65,536 |------- C3 ------|----------- C5 ----------- | ---------- C2 ----------|
这就是 Auto-split Hash Range 的方案,不算复杂,具体的实现可以看 Pulsar 源码中HashRangeAutoSplitStickyKeyConsumerSelector这个类,我在这里就不列举了。
这个方案的问题主要还是数据倾斜,比如上面的例子出现的这种情况,C2的负载显然比C3多很多:
0 16,384 65,536 |------- C3 ------|-------------------------- C2 -----------------------|
按照这个算法逻辑,一些 consumer 下线后很容易产生这种数据倾斜的情况,所以这个解决方案并不能均匀地把 key 分配给 consumer。
那么如何优化这个算法呢?就要用到一致性哈希算法了。
一致性哈希算法的实现
结合我在本文开头对一致性哈希算法的介绍,应该很容易想到优化思路。其实现在 Pulsar 就是使用一致性哈希算法来实现的 key_shared 订阅。
首先抽象出一个值在[0, MAX_INT]的哈希环,然后给每个 consumer 分配 100 个虚拟节点映射到这个哈希环上。接下来,我们把 key 的哈希值放在哈希环上,顺时针方向找到最近的 consumer 虚拟节点,也就找到了负责处理这个 key 的 consumer。
哈希环我们一般用 TreeMap 实现,直接看 Pulsar 源码中ConsistentHashingStickyKeyConsumerSelector的实现吧,我提取了其中的关键逻辑并添加了详细的注释:
class ConsistentHashingStickyKeyConsumerSelector {
// 哈希环,虚拟节点的哈希值 -> consumer 列表
// 因为存在哈希冲突,多个虚拟节点可能映射到同一个哈希值,所以值为 List 类型
NavigableMap> hashRing = new TreeMap<>();
// 每个 consumer 有 100 个虚拟节点
int numberOfPoints = 100;
// 将该 consumer 的 100 个虚拟节点添加到哈希环上
public void addConsumer(Consumer consumer) {
for (int i = 0; i < numberOfPoints; i++) {
// 计算虚拟节点在哈希环上的位置
String key = consumer.consumerName() + i;
int hash = Murmur3_32Hash.getInstance().makeHash(key.getBytes());
// 把虚拟节点放到哈希环上
hashRing.putIfAbsent(hash, new ArrayList<>());
hashRing.get(hash).add(consumer);
}
}
// 在哈希环上删除该 consumer 的所有虚拟节点
public void removeConsumer(Consumer consumer) {
for (int i = 0; i < numberOfPoints; i++) {
// 计算虚拟节点在哈希环上的位置
String key = consumer.consumerName() + i;
int hash = Murmur3_32Hash.getInstance().makeHash(key.getBytes());
// 删除虚拟节点
if (hashRing.containsKey(hash)) {
hashRing.get(hash).remove(consumer);
}
}
}
// 通过 key 的哈希值选择 consumer
public Consumer select(int hash) {
if (hashRing.isEmpty()) {
return null;
}
// 选择顺时针方向的第一个 consumer
Map.Entry> ceilingEntry = hashRing.ceilingEntry(hash);
List consumerList;
if (ceilingEntry != null) {
consumerList = ceilingEntry.getValue();
} else {
// 哈希环顺时针转一圈,回到开头寻找第一个节点
consumerList = hashRing.firstEntry().getValue();
}
// 保证相同的 key 都会分配到同一个 consumer
return consumerList.get(hash % consumerList.size());
}
}
当消息被发送过来后,Pulsar 可以通过select方法选择对应的 consumer 来处理数据;当新的 consumer 上线时,可以通过addConsumer将它的虚拟节点放到哈希环上并开始接收消息;当有 consumer 下线时,可以通过removeConsumer将它的虚拟节点从哈希环上摘除,由其他 consumer 承担它的工作。
因为每个 consumer 有 100 个虚拟节点,所以在 consumer 下线时,负载其实是均匀地分配给了其他 consumer,因此一致性哈希算法能够解决之前 Auto-split Hash Range 方案数据倾斜的问题。
审核编辑:刘清
-
顺序一致性和TSO一致性分别是什么?SC和TSO到底哪个好?2022-07-19 2742
-
一致性规划研究2009-04-06 728
-
CMP中Cache一致性协议的验证2010-07-20 1077
-
加速器一致性接口2017-11-17 4627
-
分布式一致性算法Yac2017-11-27 903
-
基于轨迹标签的谣言一致性维护算法2017-12-17 854
-
Cache一致性协议优化研究2017-12-30 1252
-
优化模型的乘性偏好关系一致性改进2018-03-20 976
-
一致性哈希是什么?为什么它是可扩展的分布式系统架构的一个必要工具2018-07-17 5182
-
哈希图一致性算法已被验证为异步拜占庭容错2018-10-23 2141
-
基于改进一致性的多无人机编队控制算法2021-06-22 1142
-
Dubbo负载均衡策略之一致性哈希2023-06-16 2012
-
如何保证缓存一致性2023-10-19 2889
-
DDR一致性测试的操作步骤2024-02-01 4575
-
深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别2024-03-11 2417
全部0条评论

快来发表一下你的评论吧 !
