

自动驾驶上下求索之路—感知
描述
“一元复始,万象更新”。经历了去年自动驾驶的寒冬,自动驾驶行业正在重新孕育新生,以其坚韧的发展力量引领新一轮的科技变革。度尽劫波,自动驾驶的发展道路正愈发清晰——“渐进式”以一步一个脚印,稳打稳扎,指明了自动驾驶的发展道路。而随着自动驾驶的等级逐步提升,解决一个个corner cases就成了技术进步的关键,在这其中最先需要提升的便是自动驾驶的感知能力。
把自动驾驶当作一个工程项目来看的话,感知、规划、控制便是其中的一个模块。今天我们就来聊聊这个模块的头部——感知。
和人类一样,智能驾驶汽车想要自己开上路,首先需要对周围环境有一个认识,而智能汽车的”眼睛“、”耳朵“就是由多种传感器组成。
现在行业里喜欢提一个新名词:”行泊一体“。
其实无论是行车还是泊车,最常用的三种传感器便是摄像头、毫米波雷达和激光雷达。
有了这些传感器是不是就能实现自动驾驶呢?答案显然是否定的,我们还需要对采集到的数据进行处理,提取出对我们有用的信息,才能进行下一步的规划和控制。
俗话说”工欲善其事,必先利其器“。
只有打磨好自动驾驶感知算法,与优质的硬件相匹配,才能获得好的感知结果。接下来我们就按照三款传感器量产上车的时间顺序倒序来讲讲其基本的感知算法。
一、激光雷达感知算法
激光雷达的输出产物是点云,近处非常稠密、远处又非常稀疏的点云,数量以万计数。因此,Lidar的感知算法任务就是如何从这堆点云中完成目标的检测。这里的检测包括了物体的大小、位置、类别、朝向和速度等等,涵盖了目标的各种特征。

激光雷达生成的3D点云
Lidar的点云感知算法分为基于启发式的方法和基于深度学习的方法。在深度学习没有大规模运用之前,人们用的都是启发式的方法。
面对一个复杂问题,正常的思路也是从启发式入手。空间中这么多的点,我哪知道谁和谁是同一个物体的呢?但是有一点我是能确定的,这就像是点云空间的“公理”:空间上位置接近的点来自同一个障碍物。这很好理解,我点云是扫描到物体产生的,那产生的一坨靠在一起的点必然是来自同一个物体的,你不可能把FOV里两个相隔很远的点关联成一个物体吧。这个公理有个高大上的名字,叫空间平滑性假设。
有了这个假设,我们就可以把点云建成图,利用图论的知识来分割,实现切图聚类。
对于一个图G,有顶点V,边E和权重W。我们把所有的点云看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边赋低权重,而距离较近的两个点之间的边赋高权重,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重之和尽可能的低,而子图内的边权重之和尽可能的高,从而达到聚类的目的。
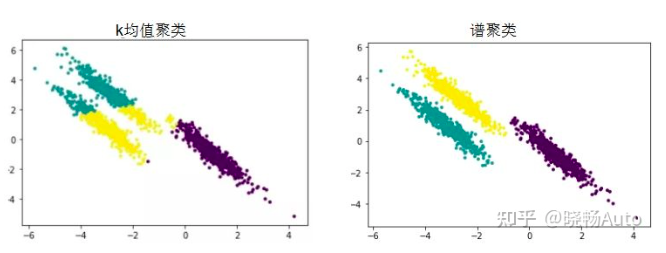
这种方法叫做谱聚类(spectral clustering)。这种方法的优点在于解释性非常好,如果出现什么bad case,只需要专门针对这种情况调整一下参数即可解决。但是缺点在于分割的规则过于简单,又丢失了语义信息,像道路旁的草丛这种边缘不清晰的就没法很好分割。
谱聚类(spectral clustering)原理总结那既然启发式的方法没法很好地像人一样进行目标分割,我们就来想想人是怎么做分割的,仅仅是通过距离远近我们就认为那些点云是属于同一个目标的吗?不,我们人类会首先根据它是个什么东西,来判断它应该有多大,边界在什么地方来为环境中的目标进行分割的。这层至关重要的信息就是启发式方法中丢弃的语义信息,而想要使用这层特征,就需要深度学习的方法,通过数据驱动,让模型去挖掘其中蕴含的语义信息,这就是深度学习做目标检测识别的原理。
深度学习方法在自动驾驶激光雷达目标检测中的应用始于2010年代。当时,研究人员使用卷积神经网络(CNN)来处理激光雷达数据,并在检测和分类目标方面取得了一些成功。随着深度学习技术的进步和数据量的增加,这些方法变得更加准确和高效。现在,深度学习方法已成为自动驾驶激光雷达目标检测的主流技术。
以点云卷积神经网络(PointNet)为例,这种模型能够处理点云数据,并在点云数据上实现目标检测。PointNet能够在没有明显结构的点云数据上取得较好的性能。
由于深度学习在激光雷达点云数据处理上方法层出不穷,且与图像数据进行融合处理成为一种主流趋势,因此就不在此过多介绍了,之后会结合具体论文与大家一同分析学习。
二、视觉感知算法
视觉感知任务作为机器模仿人类最重要的一环而早早地被安排上了汽车辅助驾驶系统。但在应用初期,其感兴趣范围还比较狭窄,只关注于前方的近距离目标、车道线的识别、行人的辅助检测等等,这些应用能够支持车辆进行纵向运动的控制。
这一时期的视觉算法主要是基于计算机图像处理技术的,基于规则的。通过提取各种各种的边缘算子完成模型边缘提取和分割。通过人工构造特征+浅层分类器实现感知任务。但随着视觉感知任务变得越来越重要,简单的目标检测已不能cover更高阶自动驾驶的需求,因其总体上是一种low-level的视觉算法。

车道线检测技术而当前,深度学习在视觉感知中扮演了重要的角色。当前智能驾驶中的视觉感知算法主要包括深度学习方法,如卷积神经网络(CNN)和卷积神经网络检测器(YOLO,SSD等)。当然最新的方向包括Transformer以及BEV感知,还有去年Tesla AI Day上公开的Occupancy Network。
计算机视觉技术的突飞猛进自然带起了自动驾驶中的视觉感知,但是需要注意摄像头的视角约束与结构化道路的约束,它并不像CV图像里的一切皆有可能,而是发生在实实在在道路上的视觉感知。
同时这种感知已不简简单单是2D输出,而是对三维信息提出了要求,因此三维目标检测技术就会更加受到重视。
一般的视觉感知流程框图是像素信号输入进来,首先做detection,随后做2D到3D的投影转换,这部分可以和激光雷达数据结合起来,之后做Tracking。不同的架构中使用深度学习的地方不同,有只在检测任务里使用CNN的,后面两个模块仍使用传统方法,这样子可以保证实时性,因为自动驾驶对实时性要求很高,很多论文中花里胡哨的神经网络模型实际上没法部署到车上。而现在也有端到端训练的趋势,即把检测到追踪打包放进一个网络中训练,通过大量喂数据,直接得到最终的目标位置、距离等信息。同时,由于视觉感知不止目标检测追踪这一个任务,而其他任务使用的输入又都是相同的,因此可以在模型输出时采用多头结构,一套网络多个输出,同时完成检测、分类、分割等多重任务。
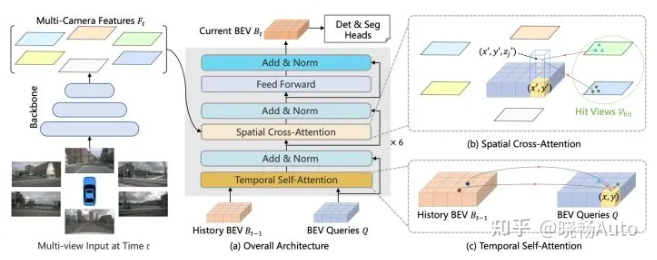
BEV Former
三、毫米波雷达感知算法
作为最早上车的感知零部件,毫米波雷达的感知算法往往是各家自动驾驶方案供应商所忽略的。究其根本并非是其不重要,而是这部分Know-how被牢牢把握在国际Tier1巨头手里,主机厂和自动驾驶公司只能拿到输出的目标,对他们而言,毫米波雷达感知就是一个黑盒。

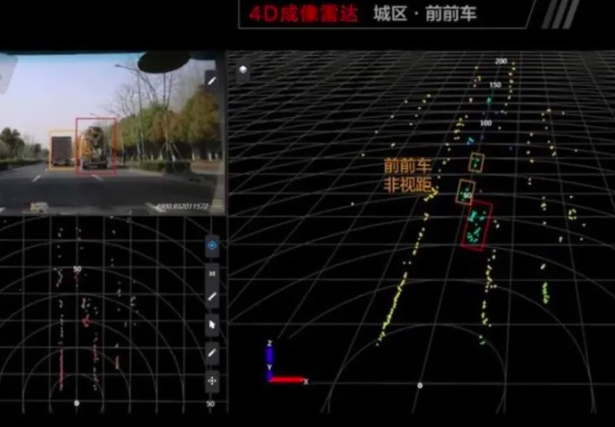
Continental ARS540全球第一款量产4D毫米波雷达
但实际上,由于毫米波雷达不受光线、雨雾天气影响,并且探测距离特别远,在ACCAEB功能上应用非常纯熟,因此毫米波雷达的感知结果相当重要。即使在视觉主导的感知体系中,由于雷达能直接探测目标的距离和速度,因此这两者的权重相比于摄像头的检测是要高很多的。
毫米波雷达与激光雷达同为雷达,因此得到的输入其实都是点云。但是毫米波雷达的点云要比激光雷达稀疏的多,哪怕是反射比较强烈的金属物体,例如车身,毫米波雷达依旧只能打出十几个点,而对于行人这种RCS小得多的目标,能打出一两个点就很不错了。这就是为什么毫米波雷达做行人检测和目标分类不擅长的原因。
由于点云非常稀疏,这就导致依赖大量数据训练的神经网络发挥不了其特长,故而毫米波雷达的感知算法还是基于规则的方法,以一个个人工手动调的参数作为阈值,组成了毫米波雷达感知算法的框架。
与激光雷达感知类似,毫米波雷达也是首先对点云进行聚类,这里面常用的就是JPDA这样的关联算法,通过与目标关联,获得每一帧点云的具体位置和速度。生成目标后,对目标进行维护,这里的维护就包括预测和更新的卡尔曼滤波手法,从而实现多目标的稳定跟踪。在FOV视野范围内,确保目标保持同一个ID,连续不断地进行追踪。
在主线任务外,还会做一些目标长宽、orientation、存在概率等的属性的判断,帮助感知系统确认这是一个真实的可以使用的目标。
除了对目标的检测追踪,毫米波雷达感知算法还能够给出车道线的预测、道路边界描述以及Freespace等感知信息。
由于传统的毫米波雷达天线不具有测高能力,具有测高功能的4D毫米波雷达已进入量产。4D毫米波雷达由于天线通道成倍增加,因此获得的点云数量有了大幅度提升,因此具备了深度学习的应用条件。这部分感知算法还处于研发当中,算是毫米波雷达感知中非常前言的东西。
总结路漫漫其修远兮,自动驾驶的道路不是一帆风顺的,Corner case也是不断出现的。只有不断提升感知硬件的能力、完善感知算法的模型,才能确保在当前人工智能水平下智能汽车完成高级别自动驾驶功能。
审核编辑 :李倩
-
未来已来,多传感器融合感知是自动驾驶破局的关键2024-04-11 2201
-
FPGA在自动驾驶领域有哪些应用?2024-07-29 8174
-
自动驾驶真的会来吗?2016-07-21 14086
-
自动驾驶的到来2017-06-08 7305
-
即插即用的自动驾驶LiDAR感知算法盒子 RS-Box2017-12-15 5982
-
迈向自动驾驶和电动汽车之路研讨会2018-10-25 3034
-
UWB主动定位系统在自动驾驶中的应用实践2018-12-14 3186
-
车联网对自动驾驶的影响2019-03-19 3437
-
如何让自动驾驶更加安全?2019-05-13 3622
-
智能感知方案怎么帮助实现安全的自动驾驶?2019-07-31 3162
-
自动驾驶汽车中传感器的分析2020-05-14 3470
-
基于视觉的slam自动驾驶2021-08-09 2911
-
汽车自动驾驶产业链深度研究报告:自动驾驶驶向何方 精选资料分享2021-08-27 2860
-
自动驾驶技术的实现2021-09-03 3076
-
自动驾驶感知系统的未来之路2023-02-20 1415
全部0条评论

快来发表一下你的评论吧 !
