

算法和数据结构基础知识分享(下)
电子说
描述
五 常见排序算法
1 十大经典排序算法
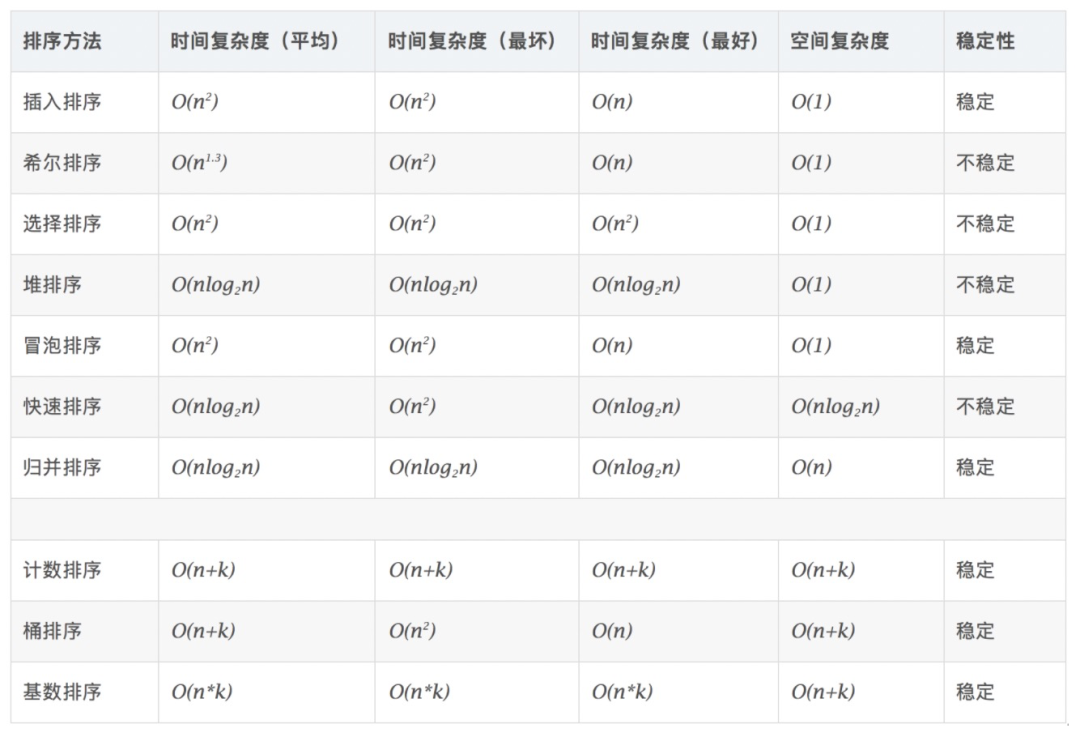
2 冒泡排序
1)算法描述
冒泡排序是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
2)实现步骤
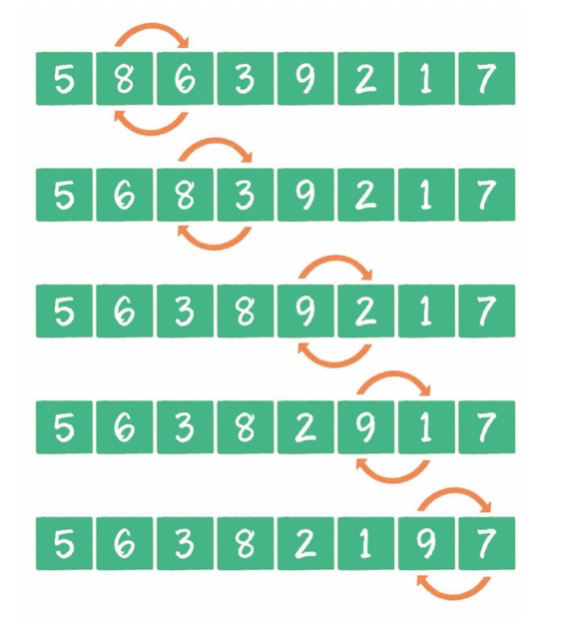
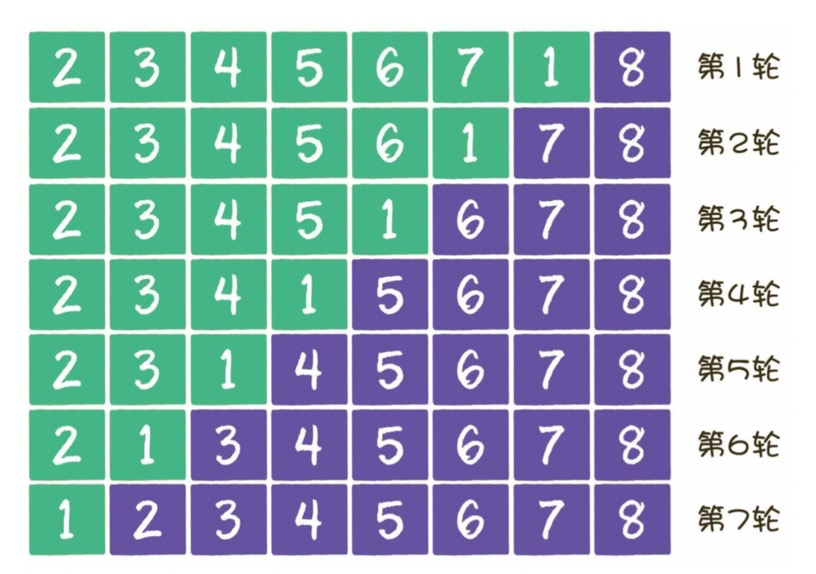
- 比较相邻的元素。如果第一个比第二个大,就交换它们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对,这样在最后的元素应该会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 重复步骤1~3,直到排序完成。
3)优缺点
- 优点:实现和理解简单。
- 缺点:时间复杂度是O(n^2),排序元素多时效率比较低。
4)适用范围
数据已经基本有序,且数据量较小的场景。
5)场景优化
(1)已经有序了还再继续冒泡问题
- 本轮排序中,元素没有交换,则isSorted为true,直接跳出大循环,避免后续无意义的重复。
(2)部分已经有序了,下一轮的时候但还是会被遍历
- 记录有序和无序数据的边界,有序的部分在下一轮就不用遍历了。
(3)只有一个元素不对,但需要走完全部轮排序
- 鸡尾酒排序:元素的比较和交换是双向的,就像摇晃鸡尾酒一样。
3 归并排序
1)算法描述
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法的一个非常典型的应用。递归的把当前序列分割成两半(分割),在保持元素顺序的同时将上一步得到的子序列集成到一起(归并),最终形成一个有序数列。
2)实现步骤
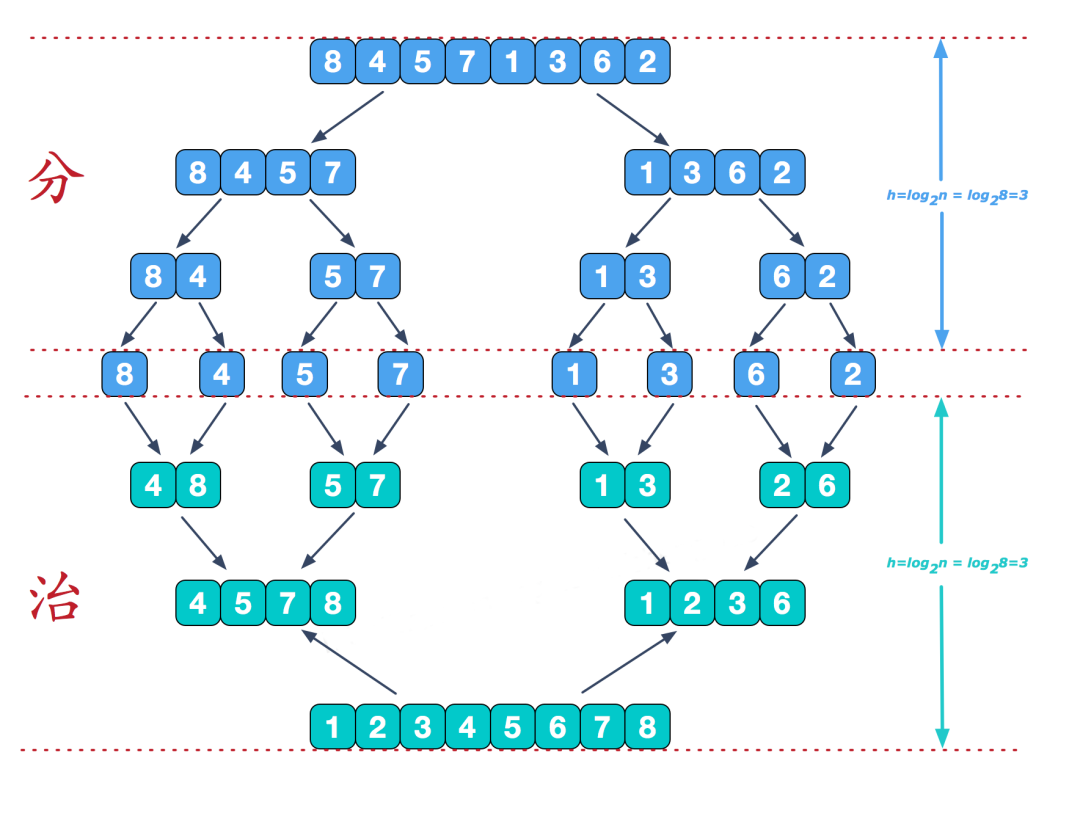
图源:https://www.cnblogs.com/chengxiao/p/6194356.html
- 把长度为n的输入序列分成两个长度为n/2的子序列。
- 对这两个子序列分别采用归并排序。
- 将两个排序好的子序列合并成一个最终的排序序列。
3)优缺点
优点:
- 性能好且稳定,时间复杂度为O(nlogn) 。
- 稳定排序,适用场景更多。
缺点:
- 非原地排序,空间复杂度高。
4)适用范围
大数据量且期望要求排序稳定的场景。
4 快速排序
1)算法描述
快速排序使用分治法策略来把一个序列分为较小和较大的2个子序列,然后递归地排序两个子序列,以达到整个数列最终有序。
2)实现步骤
- 从数列中挑出一个元素,称为 “基准值”(pivot)。
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地对【小于基准值元素的子数列】和【大于基准值元素的子数列】进行排序。
3)优缺点
优点:
- 性能较好,时间复杂度最好为O(nlogn),大多数场景性能都接近最优。
- 原地排序,时间复杂度优于归并排序。
缺点:
- 部分场景,排序性能最差为O(n^2)。
- 不稳定排序。
4)适用范围
大数据量且不要求排序稳定的场景。
5)场景优化
(1)每次的基准元素都选中最大或最小元素
- 随机选择基准元素,而不是选择第一个元素。
- 三数取中法,随机选择三个数,取中间数为基准元素。
(2)数列含有大量重复数据
- 大于、小于、等于基准值。
(3)快排的性能优化
- 双轴快排:2个基准数,例子:Arrays.sort() 。
5 堆排序
1)算法描述
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
2)实现步骤
- 将初始待排序关键字序列(R1,R2….Rn)构建成最大堆,此堆为初始的无序区。
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n]。
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
3)优缺点
优点:
- 性能较好,时间复杂度为O(nlogn)。
- 时间复杂度比较稳定。
- 辅助空间复杂度为O(1)。
缺点:
- 数据变动的情况下,堆的维护成本较高。
4)适用范围
数据量大且数据呈流式输入的场景。
5)为什么实际情况快排比堆排快?
堆排序的过程可知,建立最大堆后,会将堆顶的元素和最后一个元素对调,然后让那最后一个元素从顶上往下沉到恰当的位置,因为底部的元素一定是比较小的,下沉的过程中会进行大量的近乎无效的比较。所以堆排虽然和快排一样复杂度都是O(NlogN),但堆排复杂度的常系数更大。
6 计数排序
1)算法描述
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
2)实现步骤
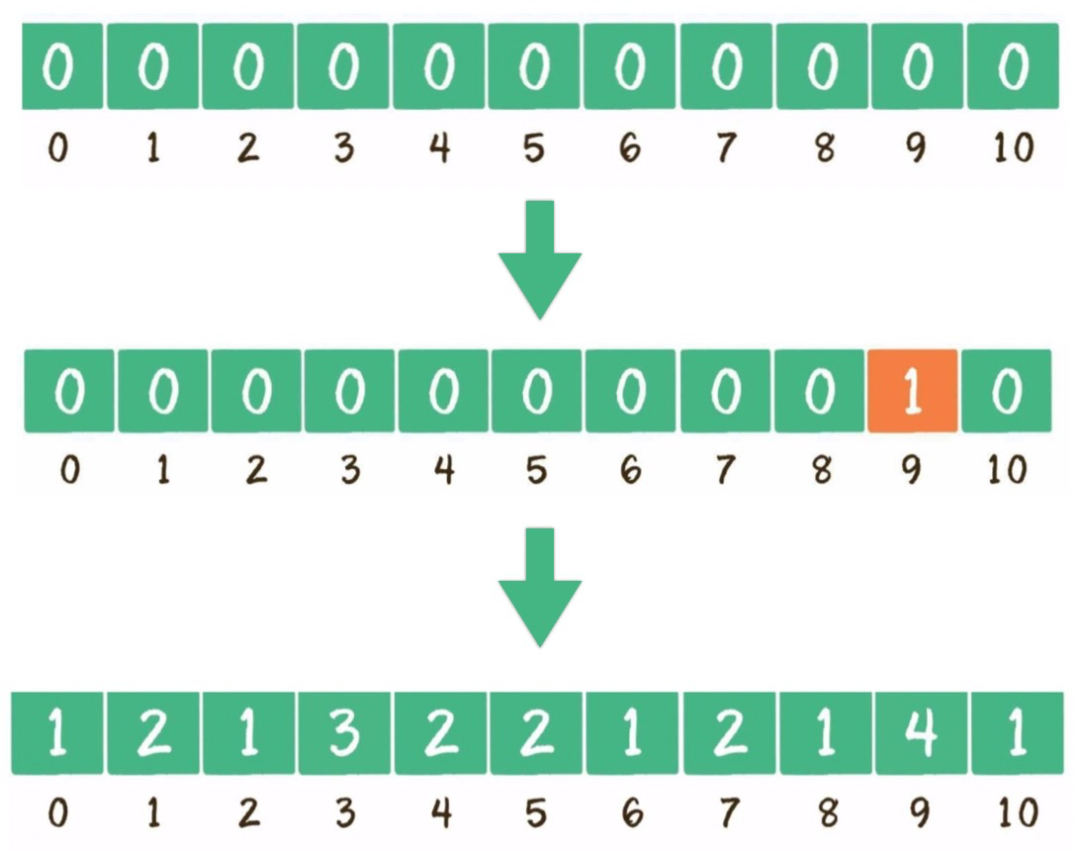
- 找出待排序的数组中最大元素。
- 构建一个数组C,长度为最大元素值+1。
- 遍历无序的随机数列,每一个整数按照其值对号入座,对应数组下标的值加1。
- 遍历数组C,输出数组元素的下标值,元素的值是几就输出几次。
3)优缺点
优点:
- 性能完爆比较排序,时间复杂度为O(n+k),k为数列最大值。
- 稳定排序。
缺点:
- 适用范围比较狭窄。
4)适用范围
数列元素是整数,当k不是很大且序列比较集中时适用。
5)场景优化
(1)数字不是从0开始,会存在空间浪费的问题
- 数列的最小值作为偏移量,以数列最大值-最小值+1作为统计数组的长度。
7 桶排序
1)算法描述
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。实现原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排序)。
2)实现步骤
- 创建桶,区间跨度=(最大值-最小值)/(桶的数量-1)。
- 遍历数列,对号入座。
- 每个桶内进行排序,可选择快排等。
- 遍历所有的桶,输出所有元素。
3)优缺点
优点:
- 最优时间复杂度为O(n),完爆比较排序算法。
缺点:
- 适用范围比较狭窄。
- 时间复杂度不稳定。
4)适用范围
数据服从均匀分布的场景。
8 性能对比
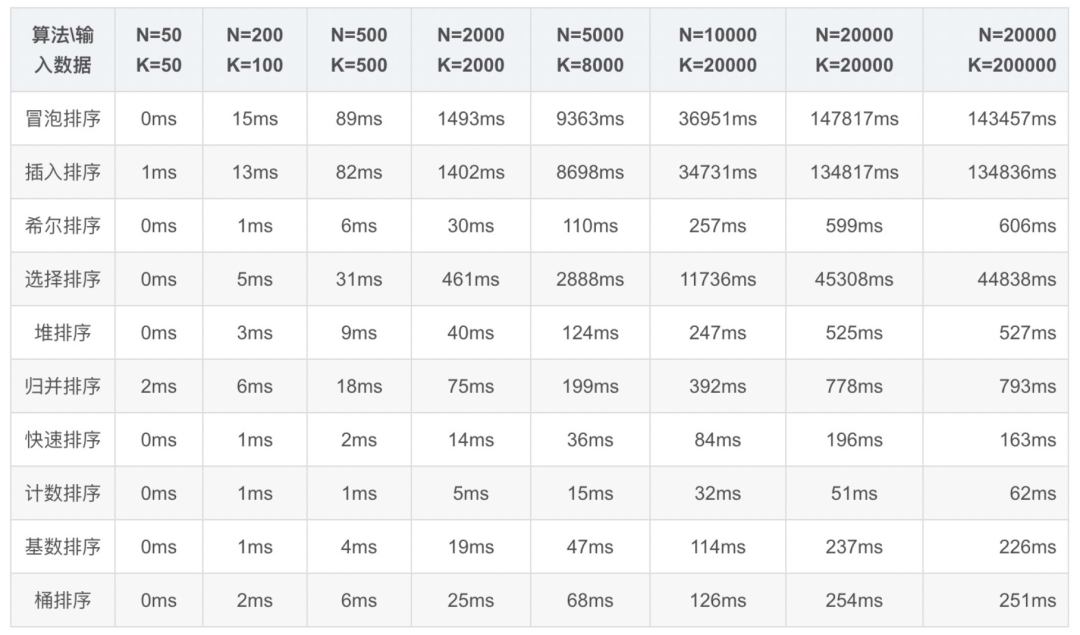
随机生成区间0 ~ K之间的序列,共计N个数字,利用各种算法进行排序,记录排序所需时间。
-
算法和数据结构基础知识分享(上)2023-04-06 1692
-
程序设计和数据结构(嵌入式)2022-04-18 737
-
数据结构预算法核心知识点总结概述2021-12-21 1059
-
数据结构与算法分析中的二叉树与堆有关知识汇总2021-11-03 835
-
数据结构的几个重要知识点2020-02-27 2124
-
数据结构与算法知识点有哪些?2020-01-10 9468
-
请问学习stm32以及ucos ii ucgui需要学习数据结构算法之类的知识吗?2019-06-09 1202
-
大牛分享平时如何学习数据结构与算法2018-11-02 3806
-
算法与数据结构——接口2017-09-19 9651
-
数据结构与算法2016-03-30 694
-
数据结构与算法习题2016-03-03 807
-
数据结构与算法分析2012-06-05 3464
-
数据结构与算法分析(Java版)(pdf)2008-12-20 4740
全部0条评论

快来发表一下你的评论吧 !
