

Firefly(流萤): 中文对话式大语言模型
描述
在本文中,笔者将介绍关于Firefly(流萤)模型的工作,一个中文对话式大语言模型。我们使用较小的模型参数量,如1.4B和2.6B,实现了不错的生成效果。
项目地址:
https://github.com/yangjianxin1/Firefly
进NLP群—>加入NLP交流群(备注nips/emnlp/nlpcc进入对应投稿群)
01
项目简介
Firefly(流萤)是一个开源的中文对话式大语言模型,使用指令微调(Instruction Tuning)在中文数据集上进行调优。同时使用了词表裁剪、ZeRO、张量并行等技术,有效降低显存消耗和提高训练效率。在训练中,我们使用了更小的模型参数量,以及更少的计算资源。
我们构造了许多与中华文化相关的数据,以提升模型在这方面的表现,如对联、作诗、文言文翻译、散文、金庸小说等。
流萤(萤火虫的别称)是中华传统文化的一个符号,虽说腐草为萤,带有悲悯意味,但萤火虽小,也能凭借其淡淡荧光,照亮夜空。本项目的名称取自杜牧的《秋夕》:银烛秋光冷画屏,轻罗小扇扑流萤。也希望本项目能够像流萤一般发出淡淡微光,为中文NLP开源社区尽绵薄之力,添砖加瓦。
《咏萤火》
唐.李白
雨打灯难灭,
风吹色更明。
若飞天上去,
定作月边星。
本项目的主要工作如下:
-
-
数据集:firefly-train-1.1M ,一份高质量的包含1.1M中文多任务指令微调数据集,包含23种常见的中文NLP任务的指令数据。对于每个任务,由人工书写若干指令模板,保证数据的高质量与丰富度。
-
模型裁剪:我们开发了LLMPruner项目-大语言模型裁剪工具 。使用词表裁剪技术对多语种大语言模型进行权重裁剪,保留预训练知识的前提下,有效减少模型参数量,提高训练效率,并分享裁剪后的多种参数规模的Bloom模型权重。
-
权重分享:在bloom-1b4-zh和bloom-2b6-zh的基础上,进行指令微调,获得两种参数规模的中文模型:firefly-1b4和firefly-2b6。
-
训练代码:开源训练代码,支持张量并行、ZeRO、Gemini异构内存空间管理等大模型训练策略。可实现仅使用一张显卡,训练1B-2B参数量的模型。
-
各种资源链接详见文章结尾。
模型使用方法如下:
from transformers import BloomTokenizerFast, BloomForCausalLM
device = 'cuda'
path = 'YenugNLP/firefly-1b4'
tokenizer = BloomTokenizerFast.from_pretrained(path)
model = BloomForCausalLM.from_pretrained(path)
model.eval()
model = model.to(device)
text = input('User:')
while True:
text = '{}'.format(text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs = model.generate(input_ids, max_new_tokens=200, do_sample=True, top_p=0.8, temperature=0.35,
repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('', "")
print("Firefly:{}".format(output))
text = input('User:')
02
方法介绍
模型裁剪
关于LLMPruner,详见文章:
LLMPruner:大语言模型裁剪工具
LLMPruner项目链接:
https://github.com/yangjianxin1/LLMPruner
本项目首先使用LLMPruner项目对原始的Bloom模型进行词表裁剪,仅取出常用的中英文词表,大大降低了模型参数量,然后再对其进行指令微调。
Bloom是个多语言模型,由于需要兼容多语言,所以词表有25w之多,在中文领域中,大部分词表并不会被用到。我们通过删减冗余的词表,从多语言模型中提取常用的中英文词表,最终词表从25w减少到46145,缩减为原来的18.39%,在保留预训练知识的同时,有效减少参数量,提高训练效率。
我们在 bloom-1b4-zh与bloom-2b6-zh的基础上,进行指令微调,获得两种参数规模的中文模型:firefly-1b4和firefly-2b6,具有不错的效果。
裁剪后的模型如下表所示:
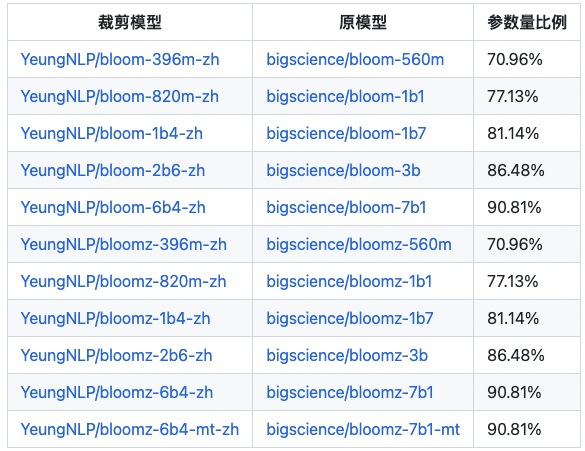
数据集
我们收集了23个常见的中文数据集,对于每个任务,由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为115万,形成训练集firefly-train-1.1M。数据分布如下图所示:
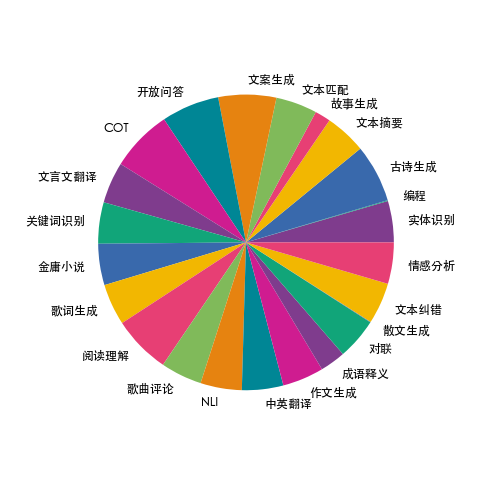
在此基础上,我们添加了Belle-train_0.5M_CN,最终得到165万的训练数据。每条数据的格式如下,包含任务类型、输入、目标输出:
{
"kind": "ClassicalChinese",
"input": "将下面句子翻译成现代文:
石中央又生一树,高百余尺,条干偃阴为五色,翠叶如盘,花径尺余,色深碧,蕊深红,异香成烟,著物霏霏。",
"target": "大石的中央长着一棵树,一百多尺高,枝干是彩色的,树叶有盘子那样大,花的直径有一尺宽,花瓣深蓝色,花中飘出奇异的香气笼罩着周围,如烟似雾。"
}
训练数据集的token长度分布如下图所示,绝大部分数据的长度都小于600:
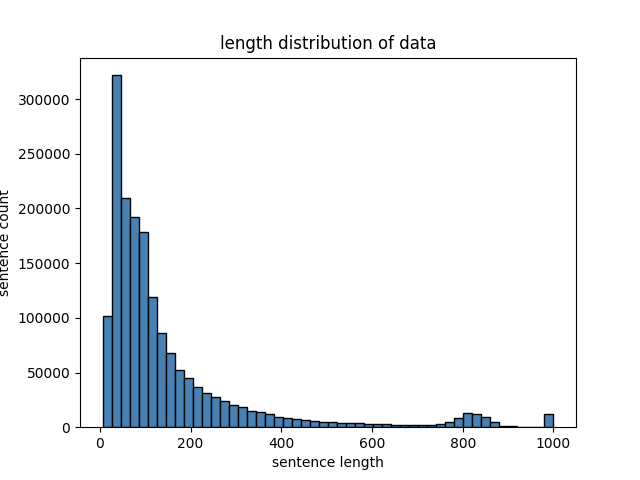
训练策略
在训练时,对于每条样本,我们将input与target拼接成如下格式,然后输出模型中,进行训练。
<s>inputs>s>targets>
我们将模型的最大输入设置为512,input部分不参与计算loss,只计算target部分的损失函数。训练的超参数设置如下表所示。
| 参数 | firefly-1b4 | firefly-2b6 |
| Batch size | 16 | 8 |
| Learning rate | 3e-5 | 3e-5 |
| Warmup step | 3000 | 3000 |
| Lr schedule | cosine | cosine |
| Max_seq_length | 512 | 512 |
| Training step | 90k | 260k |
03
生成效果
下面展示的是firefly-1b4的部分生成效果。
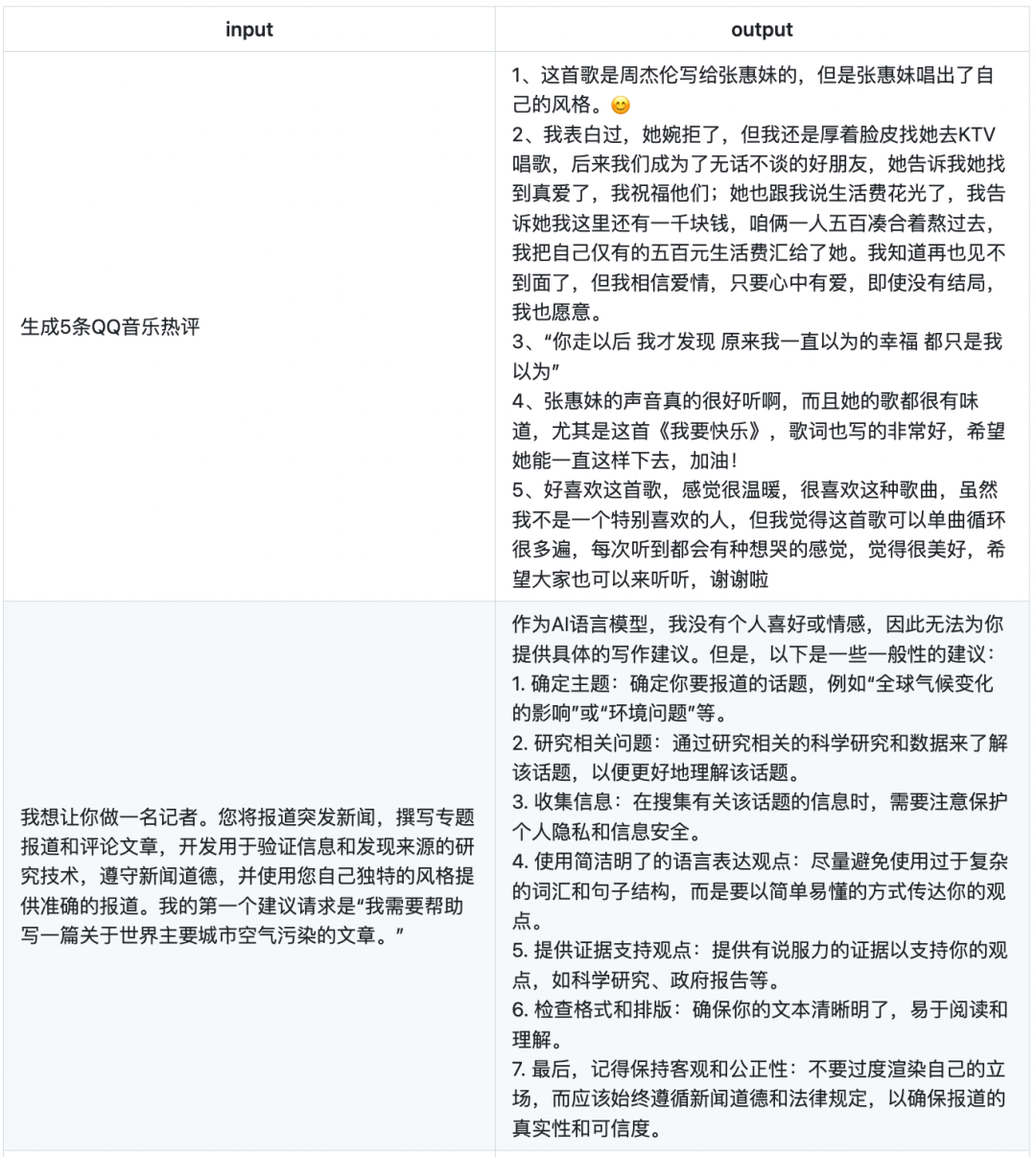
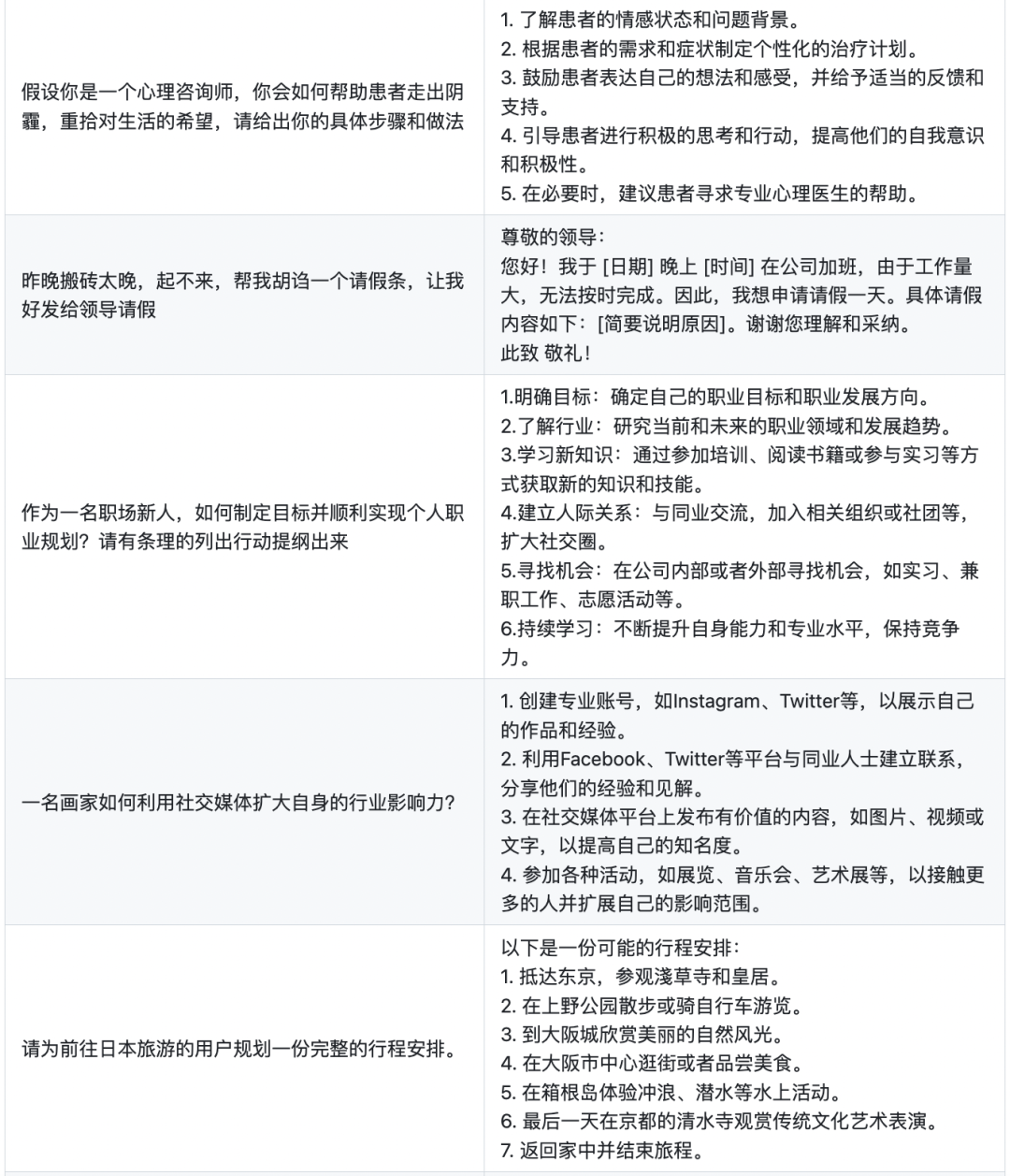

下面是Firefly模型更具特色的一些例子,Firefly对于文言文、诗词、对联、武侠小说、散文、歌词、文案生成、情感分析等中文任务具有非常优秀的表现。
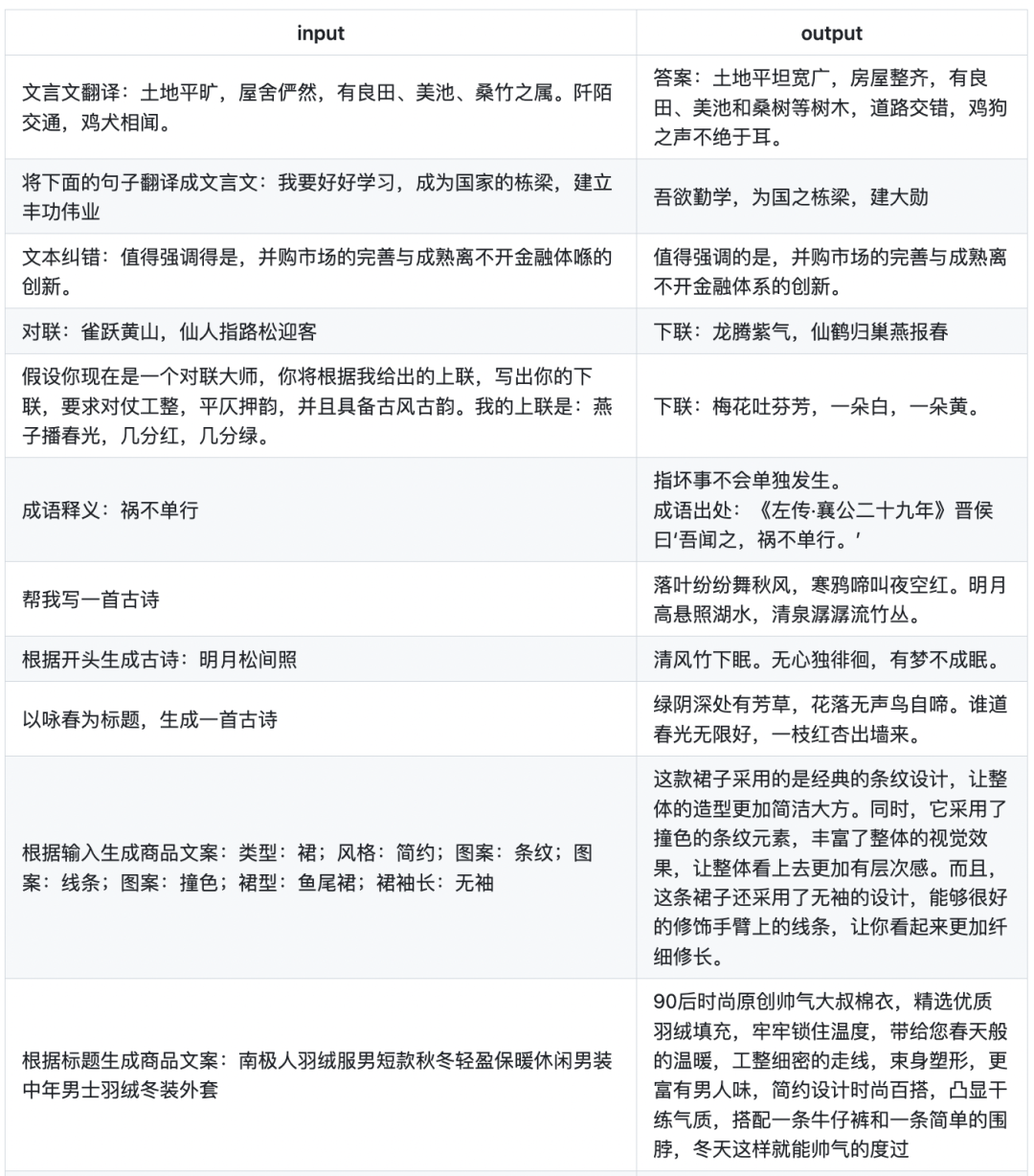
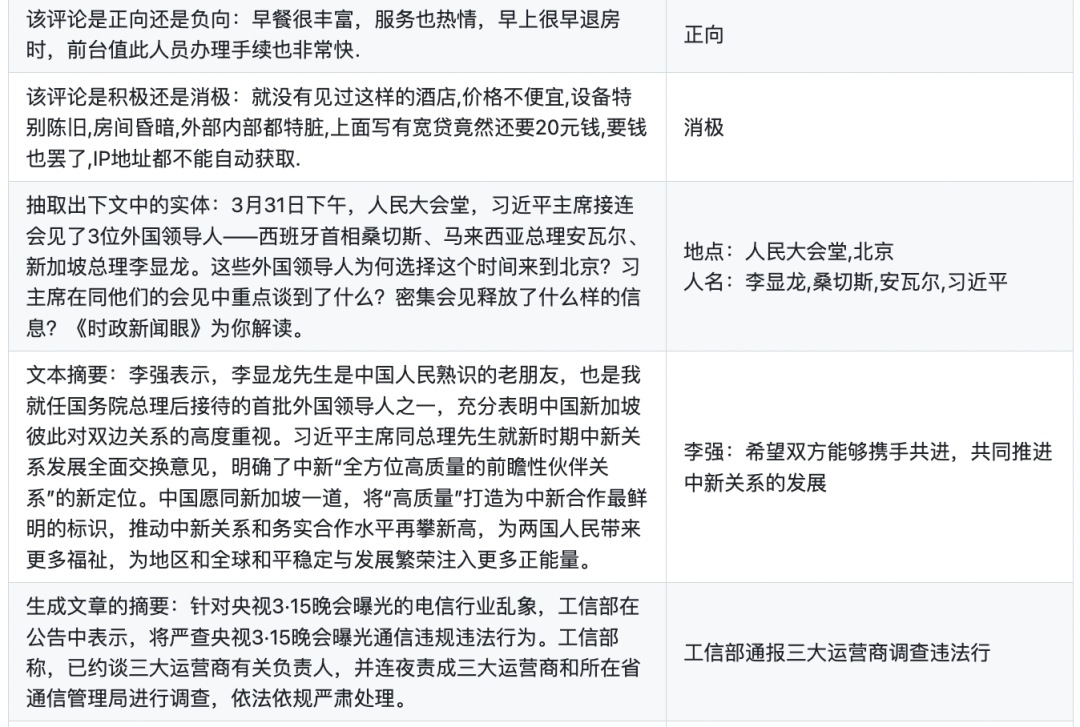

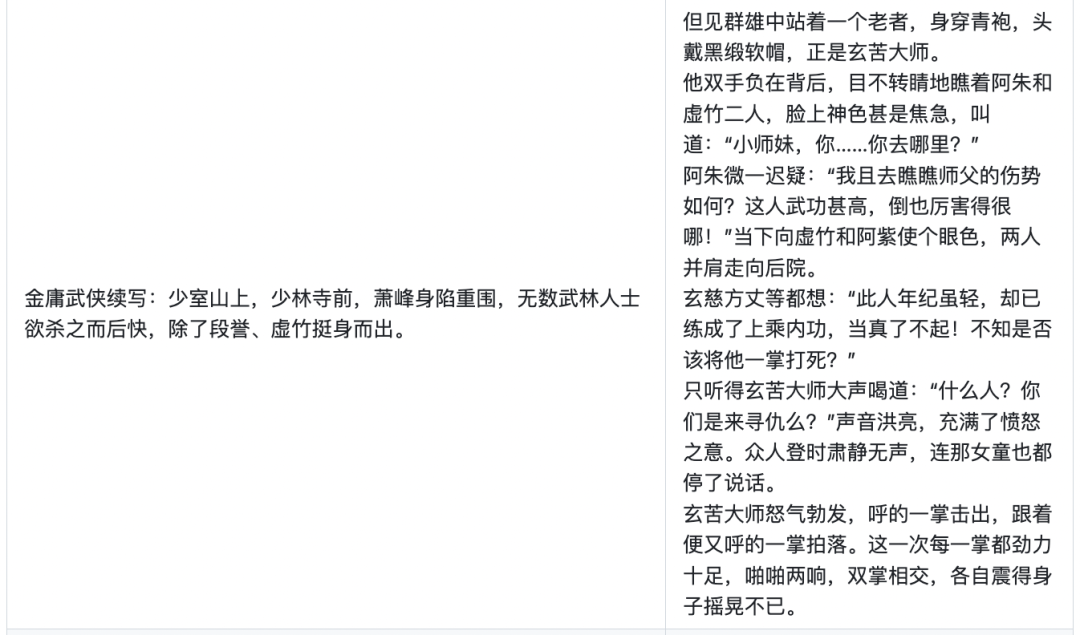

04
结语
经过词表裁剪后,我们的模型参数量仅为1.4B和2.6B,参数量远远小于ChatGPT和LLaMA等上百亿上千亿的模型,甚至远远小于当前主流如Belle、ChatGLM等7B左右的模型。所以在效果上仍存在以下问题:
-
-
对于事实性知识,容易产生错误的回复。
-
由于未经过无害化微调,可能会产生歧视、危害、违背伦理道德的言论。
-
在代码、推理上的能力仍有欠缺。
-
基于以上模型的局限性,我们要求本项目的代码、数据、模型等仅用于学术研究,不得用于商业用途,且不得用于对社会造成危害的用途。
后续笔者将从以下方向对项目进行迭代:丰富训练数据且保证数据质量,优化训练流程,尝试更大参数量的模型。
若使用本项目的数据、代码或模型,请引用本项目。
@misc{Firefly,
author = {Jianxin Yang},
= {Firefly(流萤): 中文对话式大语言模型},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/yangjianxin1/Firefly}},
}
Firefly项目地址:
https://github.com/yangjianxin1/Firefly
LLMPruner项目地址:
https://github.com/yangjianxin1/LLMPruner
Firefly权重地址:
https://huggingface.co/YeungNLP/firefly-1b4
https://huggingface.co/YeungNLP/firefly-2b6
firefly-train-1.1M 数据集:
https://huggingface.co/datasets/YeungNLP/firefly-train-1.1M
Belle-train_0.5M_CN数据集:
https://huggingface.co/datasets/BelleGroup/train_0.5M_CN
审核编辑 :李倩
-
Llama 3 语言模型应用2024-10-27 1485
-
大语言模型:原理与工程实践+初识22024-05-13 1706
-
大语言模型:原理与工程时间+小白初识大语言模型2024-05-12 1461
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1934
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
大语言模型简介:基于大语言模型模型全家桶Amazon Bedrock2023-12-04 1736
-
本地化ChatGPT?Firefly推出基于BM1684X的大语言模型本地部署方案2023-09-09 2860
-
FPGA加速器支撑ChatGPT类大语言模型创新2023-09-04 1443
-
对话文本数据是培养大模型的智能与交流之源2023-08-14 1285
-
一文读懂大语言模型2023-06-16 1850
-
“伶荔”(Linly) 开源大规模中文语言模型2023-05-04 2113
-
中文对话式大语言模型Firefly-2b6开源,使用210万训练数据2023-04-14 2649
-
大型语言模型有哪些用途?2023-02-23 6359
-
中文多模态对话数据集2023-02-22 2482
全部0条评论

快来发表一下你的评论吧 !
