

报文解析规则定义 流水线划分提取方案
描述
编 者 按
之前看一篇论文《A Fast Approach for Generating Efficient Parsers on FPGAs》,里面主要讲的是如何将P4的报文解析通过流水线技术映射到FPGA上实现。我本身不研究P4,但这篇文章里面所提到的在构造报文解析流水线部分倒颇有意思,故作总结,感兴趣的小伙伴可以去翻看原文。
报文解析规则定义
这里采用原文中定义的报文头规则定义:
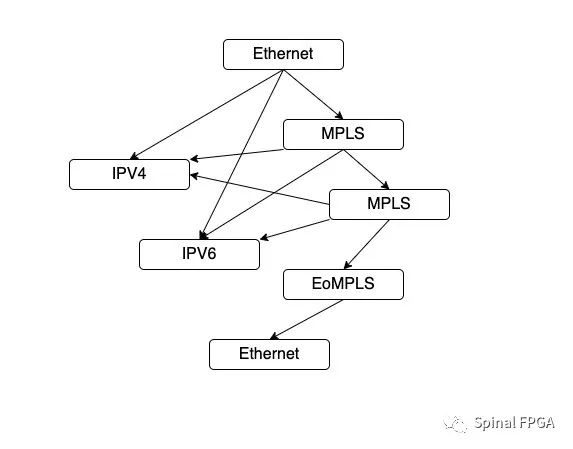
这里面定义了七种报文头规则(编号为A~G):
A:Ethernet—>MPLS—>MPLS—>EoMPLS—>Ethernet
B:Ethernet—>IPV4
C:Ethernet—>IPV6
D:Ethernet—>MPLS—>IPV4
E:Ethernet—>MPLS—>MPLS—>IPV4
F:Ethernet—>MPLS—>IPV6
G:Ethernet—>MPLS—>MPLS—>IPV6
流水线设计所需要尽可能的避免Stall,在真实的业务里,可能面临的是远比这些更复杂的协议。这里我们可以定义。
流水线划分提取
在网络报文解析里,只有当前一层报文头解析完后才能解析下一层报文规则,故而在流水线设计里,每一级流水线一般只解析一层报文头。以上面的流水线为例,首先找出最长路径:
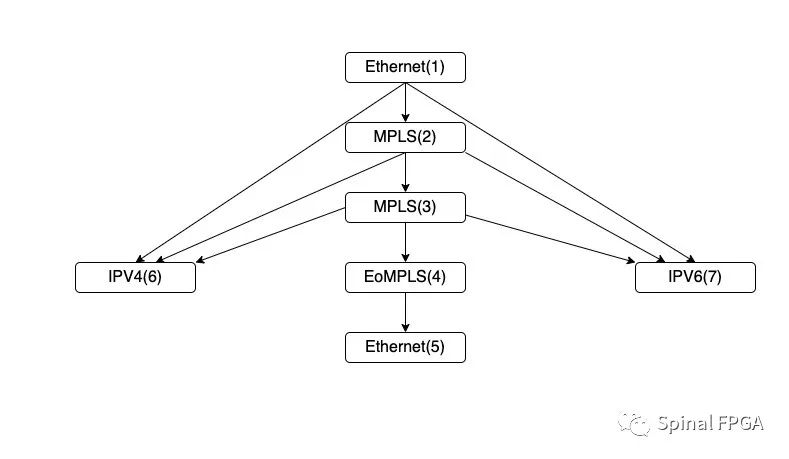
这里同时为各个报文头子规则进行编号。可以看到,最长规则包含了五个报文头规则,也就意味着流水线最长级数为5级。
接下来就是处理没有在最长路径上的节点。以IPV6为例。这里从(1)、(2)、(3)均有可能跳转至IPV6(7)。取其离根节(1)点最远的父节点并挂载在其下面,删除其他对应的跳转关系:
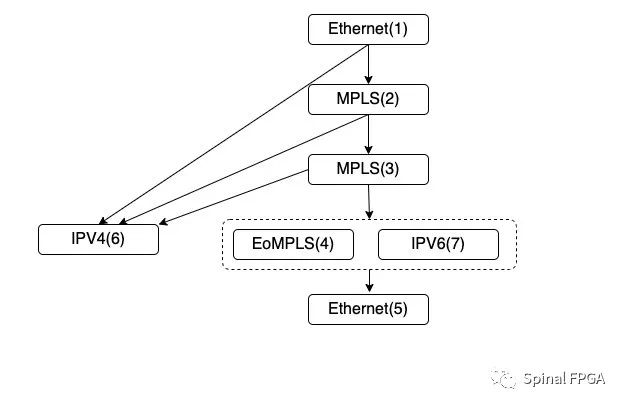
最终IPV6节点被放置在EoMPLS同一级节点处。处于流水线的第四级。这时针对IPV6报文头的解析,将被放置在流水线第四级进行处理:
Ethernet—>IPV6:第一级流水解析Ethernet,第二三级不做处理,第四级解析IPV6。
Ethernet—>MPLS—>IPV6:第一级解析Ethernet,第二级解析MPLS,第三级不做处理,第四级解析IPV6。
Ethernet—>MPLS—>MPLS—>IPV6:第一级解析Ethernet,第二级解析MPLS,第三级解析MPLS,第四级解析IPV6。 同样,按照相同的规则,我们可以来处理IPV4报文头:
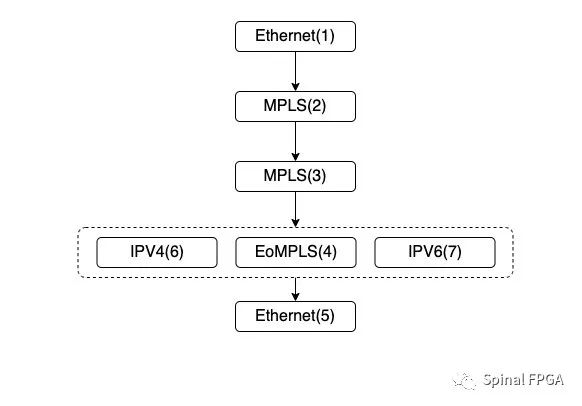
至此,整个流水线设计调度完成。流水线共分为五级。
针对上面的七种报文规则,我们可以一次编号为
在流水线设计中,每一级报文解析完成后携带当前已成功解析的标志头headerType以及EthType。这里的流水线主要在于第四级的设计,其他级都较为简单,为单一的匹配。在第四级里,定义了7种可能的组合:
headerType=1,流水匹配中IPV4(6),则headerType=6,报文命中规则B
headerType=2,流水匹配中IPV4(6),则headerType=6,报文命中规则D
headerType=3,流水匹配中IPV4(6),则headerType=6,报文命中规则E
headerType=1,流水匹配中IPV6(7),则headerType=7,报文命中规则C
headerType=2,流水匹配中IPV6(7),则headerType=7,报文命中规则F
headerType=3,流水匹配中IPV6(7),则headerType=7,报文命中规则G
headerType=3,流水匹配中EoMPLS(4),则headerType=4,可能命中报文命中规则A(到第五级进一步判断)。
如此,经过五级流水线处理,我们可以判断出在报文是否命中定义的规则。
个人思考
论文中这种流水线的设计思想确实值得借鉴。然而真实的业务模型里面的报文规则远远比上面的复杂许多,所造成的流水线级数势必会更深更长。且考虑到报文头不定长度的存在,在每一级流水里都不可避免的出现数据位移。这种不定长度的数据位移在FPGA里面像现在普遍的512比特位宽情况下还是很消耗资源的(部分级流水可能只需要常数移位)。
作者的初衷在于建立P4到FPGA的通用映射,然而这里面所设计的带宽可能是远大于真实业务设计所需求的带宽的。如果想精简资源个人倒觉得可以借鉴这种报文解析调度方式采用状态机的形式来进行处理,毕竟在真实的业务场景里还是很少出现每拍处理一个报文头的场景。可以根据不同报文规则的长度,需要的带宽以及状态机的最大跳转次数(对应这里的流水线级数)放置相应数量的状态机个数,并通过RR调度保序输出来确保真实需要带宽。
审核编辑:汤梓红
-
流水线基本结构2025-11-21 299
-
什么是流水线 Jenkins的流水线详解2023-05-17 1847
-
新版本Jenkins推荐使用声明式流水线2023-01-13 1892
-
CPU流水线的问题2022-09-22 3259
-
嵌入式_流水线2021-10-20 1330
-
如何选择合适的LED生产流水线输送方式2021-08-06 1551
-
各种流水线特点及常见流水线设计方式2021-07-05 10460
-
FPGA中的流水线设计2020-10-26 3310
-
FPGA之为什么要进行流水线的设计2019-11-28 4488
-
电镀流水线的PLC控制2016-02-17 1350
-
CPU流水线的定义2011-12-14 5255
-
流水线中的相关培训教程[1]2010-04-13 1327
-
什么是流水线技术2010-02-04 4432
全部0条评论

快来发表一下你的评论吧 !
