

Rust流处理新秀,即将抗衡Flink霸主地位
电子说
描述
Arroyo是一个使用Rust编写的分布式流处理引擎,旨在高效地对数据流进行有状态的计算。与传统的批处理不同,流处理引擎可以同时处理有界和无界的数据源,并在结果可用时立即得出结果。
废话不多说,先上github:
https://github.com/ArroyoSystems/arroyo
简而言之:Arroyo可让你对大量实时数据提出复杂问题,并在亚秒级时间内获得结果。
说到这里,感觉就是Flink在Rust中的完美替代品。如果真的可以稳定使用,那么将是Rust撼动Java在大数据流式处理计算的第一枪。
我们看下, 官网的宣传图:
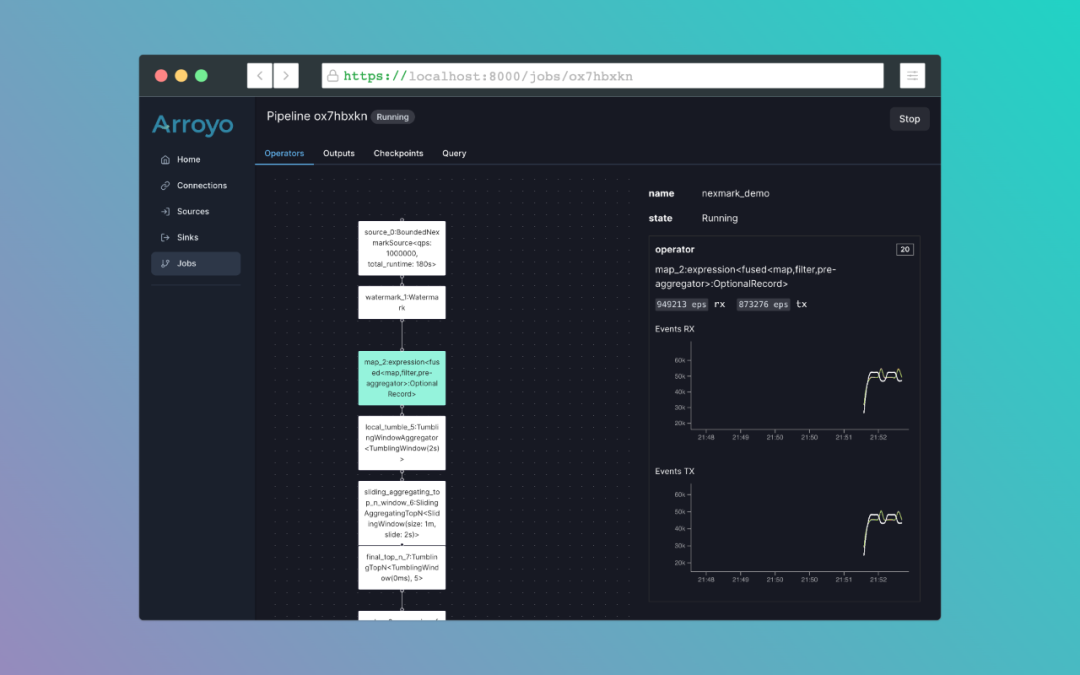
官方标榜主要特性有:
支持SQL和Rust流水线
可扩展到每秒数百万事件
支持状态操作,如窗口和连接
支持状态检查点功能,以实现流水线的容错和恢复
通过Dataflow模型进行及时的流处理
用例
检测欺诈和安全事件
实时产品和业务分析
实时数据摄取到您的数据仓库或数据湖中
实时机器学习特征生成
为什么选择Arroyo
现在已经有一些现有的流引擎,包括Apache Flink, Spark streaming和Kafka Streams。为什么要搞一个新的呢?
官方也给出了具体的说明:(可以说非常炸裂)
无服务器运维:Arroyo管道被设计为在现代云环境中运行,支持无缝扩展、恢复和重新调度。
高性能SQL:SQL是一流的关注点,具有始终优秀的性能。
专为非专家设计:Arroyo从其内部实现中清晰地分离了管道API。使用者不需要成为流处理专家即可构建实时数据pipeline。
如何开始
可以通过运行以下Docker命令来使用只有单个节点的Arroyo群集:
$ docker run -p 8000:8000 -p 8001:8001 ghcr.io/arroyosystems/arroyo-single:multi-arch
然后可以在浏览器打开:http://localhost:8000
深入学习
官方文档:https://doc.arroyo.dev/getting-started(看了下,文档写的非常好)
使用复杂SQL构建你的第一个pipeline
https://doc.arroyo.dev/tutorial/first-pipeline
总结
之前也有Rust尝试做大数据套件,但是都没有很成功的案例。或许Arroyo将是第一个用Rust编写的分布式流处理引擎成功的案例,这样将再次证明Rust在大数据基建领域的可行性。
后面我也会继续关注Arroyo,并写一系列的使用教程发布到本公众号,并做一些Flink和Arroyo的深入对比。
谢谢大家支持, 做第一个吃螃蟹的人。
审核编辑 :李倩
-
Flink集群的部署方法2019-04-23 1874
-
流式处理新秀Flink原理与实践2019-07-08 1840
-
浅析Flink程序2019-09-09 1246
-
开篇 | 揭秘 Flink 1.9 新架构,Blink Planner 你会用了吗?2019-09-25 1731
-
Flink SQL 系列 | 5 个 TableEnvironment 我该用哪个?2019-10-11 1898
-
为什么 C 语言仍然占据统治地位?2020-04-22 2791
-
AMD首款ARM处理器正式登场 挑战英特尔霸主地位2016-01-15 1073
-
三星高度依赖芯片业务 能否长久占据霸主地位2018-02-05 1304
-
来看看Spark和Flink各自的优劣和主要区别2019-03-15 32406
-
企业实践 | 如何更好地使用 Apache Flink 解决数据计算问题?2019-11-14 778
-
为什么阿里云要做Apache Flink2021-01-04 2575
-
Go/Rust挑战Java/Python地位2023-03-06 1342
-
rust语言基础学习: rust中的错误处理2023-05-22 3297
-
Rust语言中错误处理的机制2023-09-19 2757
-
Flink学习精要2023-09-25 437
全部0条评论

快来发表一下你的评论吧 !
