

ChatGPT的朋友们:大语言模型经典论文
描述
要说2023刷屏最多的词条,ChatGPT可以说是无出其右。到最近的GPT-4,技术的革新俨然已呈现破圈之势,从学术圈到工业界再到资本圈,同时也真切逐步影响到普通人的日常生活与工作。
坦白来讲,对于大语言模型生成相关的工作,个人长期以来持保守态度,认为这个方向更多的是一种深度学习的理想追求。现在看小丑竟是我自己,也许优秀的工作正是需要对理想状态的持续追求,才叫优秀的工作。
言归正传,本系列打算跟风讨论一下关于ChatGPT相关技术,主要内容分为三部分,也会分为三篇文章:
1、经典论文精读 【this】:通过本文阅读可以了解ChatGPT相关经典工作的大致思路以及各个时期的关键结论;
2、开源实现技术 【soon】:总结最近几个月开源工作者们follow ChatGPT的主要方向和方法;
3、自然语言生成任务的前世今生和未来 【later】:大语言模型之外,谈谈自然语言生成的“传统”研究方向与未来畅想。
因为相关技术发展迅速,三部分内容也会定期更新。本文主要为第一部分经典论文学习,而相关的工作众多(如图),一一阅读并不现实,因此本文选择持续性最高的OpenAI系列和Google系列,以及近期影响力比较大的LLaMA,最后是中文适配比较好的GLM和ChatGLM。
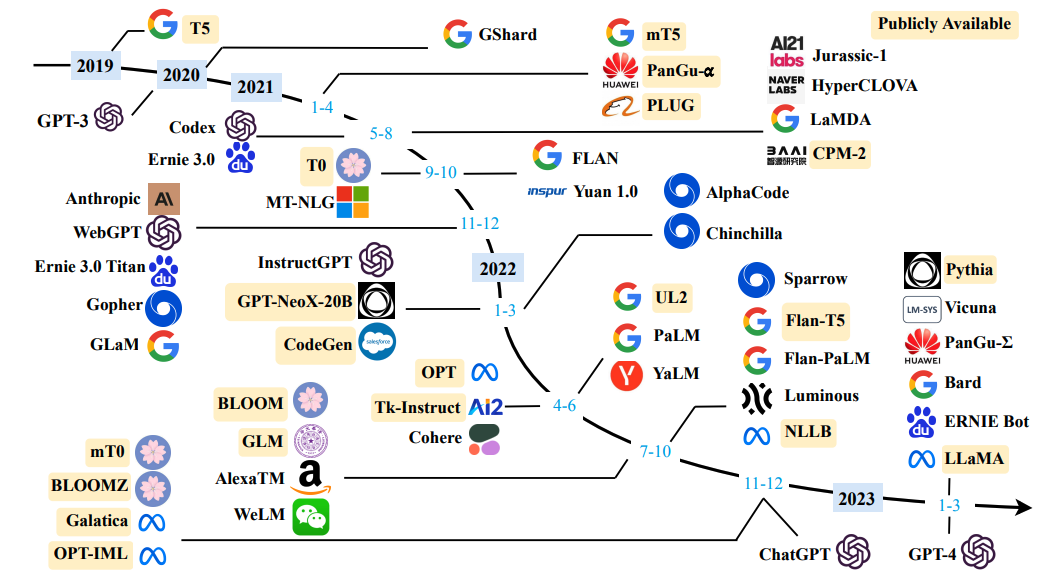
此外,本文阅读需要一定的NLP基础概念,比如知道什么是BERT和Transformer、什么是Encoder-Decoder架构、什么是预训练和微调,什么是语言模型等。
OpenAI 系列
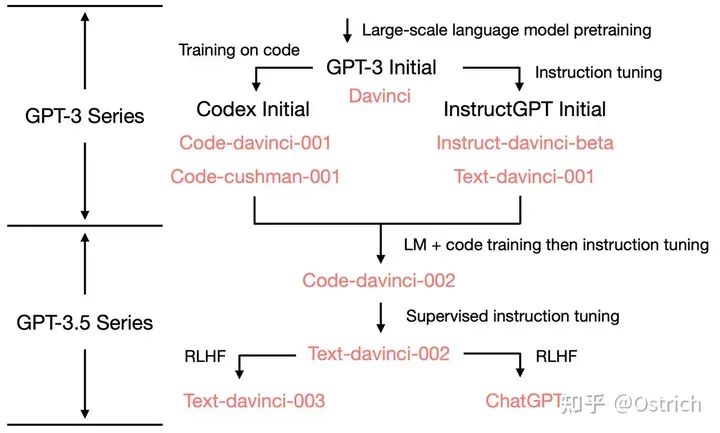
本节目标是通过OpenAI系列论文阅读细窥ChatGPT的主要原理,其先进的工作脉络可以概括为下图。从依赖往上追溯需要了解Codex 和 instructGPT、再往上是GPT-3、继而也需要了解GPT-2和GPT-1。(GPT-4暂时简单地看作是Plus版本的GPT-3.5,而且增加了多模态数据的处理能力,等更多的细节公开后再作讨论)
GPT-1
论文链接:《Improving Language Understanding by Generative Pre-Training》
动机
任务目标和BERT一致(但在BERT之前),希望通过大规模无标注数据进行预训练,下游任务微调的方式解决经典NLP任务,缓解有监督任务数据收集成本高的问题。GPT-1虽然不是第一个使用预训练-微调架构的工作,但也是使用Transformer-Decoder做相关任务的很早期工作了。
方案概述
-
模型结构:Transformer的Decoder部分
-
训练方法:自回归的生成方式进行语言模型预训练,判别式的结构进行下游任务微调。
一些细节
-
预训练:
-
Loss:经典的语言模型训练目标,将无标注的样本库表示为token 序列集合 U = {u_1, ...., u_n},最大化下面的似然估计。即通过一段话的前面的token,预测下一个token,其中k为上下文窗口。
-
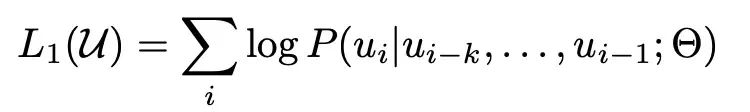
-
-
模型:使用多层Transformer decoder建模P,简化的公式表达如下。W_e为token embedding矩阵,W_p为位置向量矩阵,通过多层transformer block,最后每个token通过transformer block成为编码后的向量h_n,最后经过一个线性层+softmax,即为下一个token的预测分布。
-
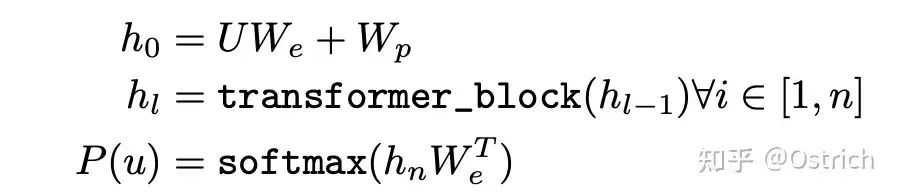
-
-
数据:早期数据并没有非常夸张,GPT-1的主要数据有两个:
-
BooksCorpus dataset:包括7000多本未发表的书籍;
-
1B Word Benchmark(可选)。
-
-
-
微调:
-
模型改动:通过增加特殊token作为输入的开始[Start]和结束[Extract]等,以结束[Extract]的隐层输出接入全连接层,并进行下游的分类和其他变种任务。如图所示:
-
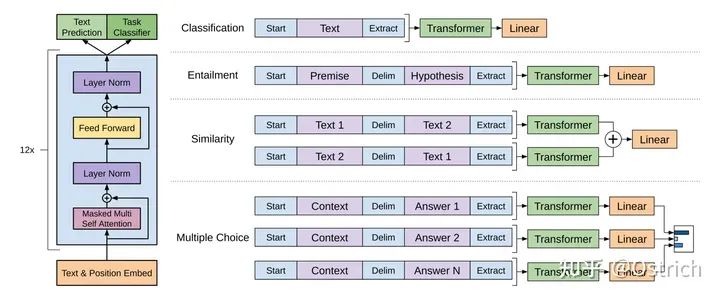
-
-
loss:
-
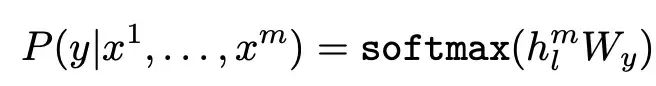
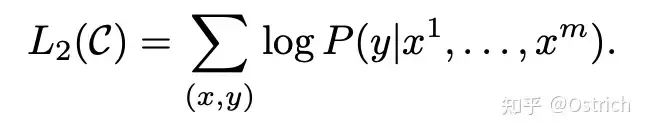
-
-
小细节:微调过程中,在下游任务目标基础上,加入预训练目标,效果更好。
-
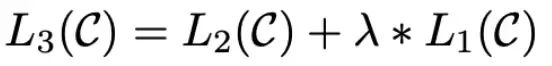
结果与讨论
-
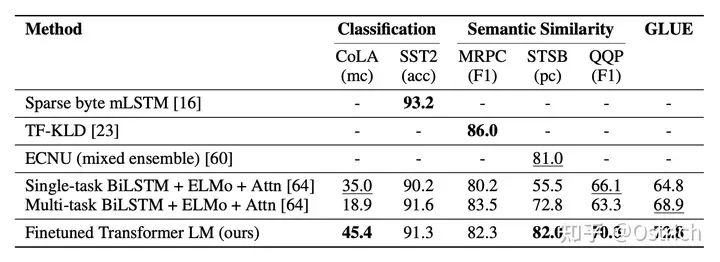
主要验证方法:文章主要是通过下游任务的效果进行策略的有效性验证,通过一些经典任务数据集。结论来看,在不少数据集上都还有着不错的效果,以分类为主的数据集为例,如图所示。可以看到,这时的对比项还没有BERT的踪影。
GPT-2
论文链接:《Language Models are Unsupervised Multitask Learners》
动机
GPT-1之后不久,BERT出现,刷榜各种任务。GPT-1尝试增加模型大小,但在预训练+微调的训练框架下,仍打不过同参数大小的BERT;但研究还得继续,尝试换个打法,以Zero-Shot作为卖点,效果不错。
方案概述
GPT-2实现Zero-Shot的方法在现在看来比较简单:将所有的NLP任务统一看作是p(output|input)的建模,而如果统使用一个足够容量的模型实现,还要告诉模型需要完成什么任务,这时建模目标可以表达为p(output|input, task)。
对于统一大模型的选择,网络结构与GPT-1相同,使用方式也很自然:task和input均使用自然语言的方式作为输入交给GPT,模型继续一步步地预测下一个最大可能的token,直到结束。如翻译任务:模型输入“翻译中文到英文,原文‘我爱深度学习’”,模型输出“I love deep learning.”。又如阅读理解任务,模型输入“回答问题,内容‘xxx’, 问题‘xxx?’”,模型输出问题的答案。
没错,就是早期的Prompting方法(其实也不是最早的)。这么做的依据则是考虑到训练数据集里有大量的Prompt结构的语料,可以使模型学到遇到类似的提示语后需要生成什么。

一些细节
-
训练数据:为了支持多任务的Zero-Shot,需要模型尽可能看更多,尽可能丰富的数据,数据收集的目标也是如此。要点如下:
-
开源Common Crawl,全网网页数据,数据集量大,且足够丰富,但存在质量问题,故而没有直接使用;
-
自建了WebText数据集,网页数据,主打一个干净高质量:只保留被人过滤过的网页,但人过滤成本很高,这里的方法是只要Reddit平台(类似国内的贴吧,社交分享平台)中被用户分享的站外链接,同时要求帖子至少3个karma(类似点赞?)。可以认为被分享的往往是人们感兴趣的、有用的或者有意思的内容。
-
WebText最终包括4500w链接,后处理过程:1、提取网页内容后;2、保留2017年以后的内容;3、去重;4、启发式的清理,得到800w+的文档,约40GB;4、剔除维基百科文档,避免与下游测试数据重叠(因为很多测试任务包括了维基百科数据,话说其他数据没有重叠吗?)。
-
-
模型:沿用GPT结构,但在模型特征输入编码、权重初始化、词典大小、输入长度、batch size等方面做了一些调整,主要是升级。
结论与讨论
-
主要结论:
-
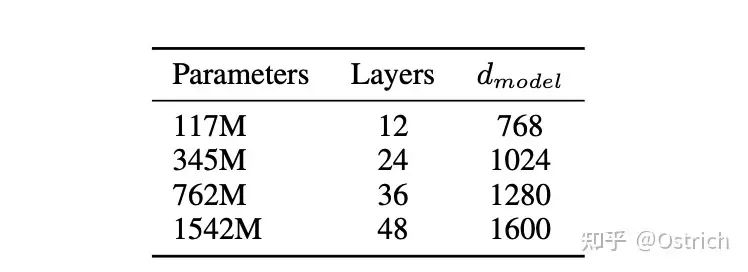
文章尝试了四种大小的模型,其中117M对应了Bert-base(和GPT-1),345M对应和Bert-large参数量,最大的模型1542M(15亿参数)。
-
-
-
模型的选择使用WebText的5%作为验证数据,实验发现所有大小的模型仍然是欠拟合状态,随着训练时间的增加,在验证集上的效果仍然可以继续提升。
-
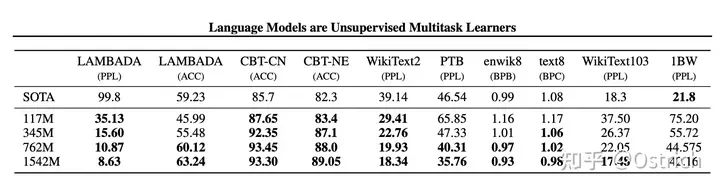
当然,在大多数Zero-Shot任务集合上也如愿取得了当时最好的结果:
-
-
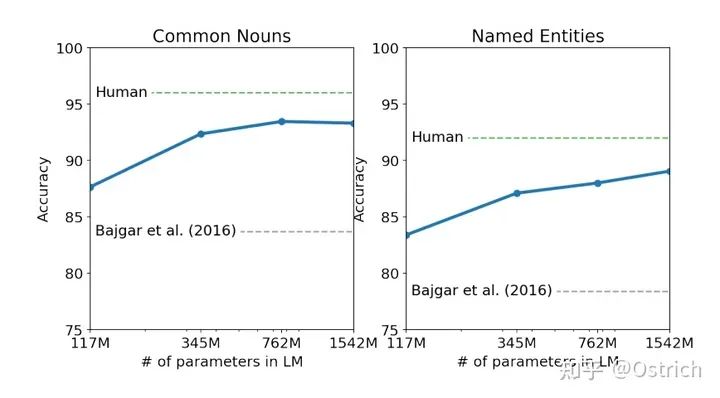
次要结论:在多数任务上,模型容量和核心指标的关系,可以发现随着模型容量的增加,效果不断变强。15亿参数看上去没有达到瓶颈,也就是说继续提升模型容量,效果能到什么程度极具想象力。(也就有了后续GPT-3的大力出奇迹)
-
Children’s Book Test任务:
-
-
-
Winograd Schema Challenge任务:
-
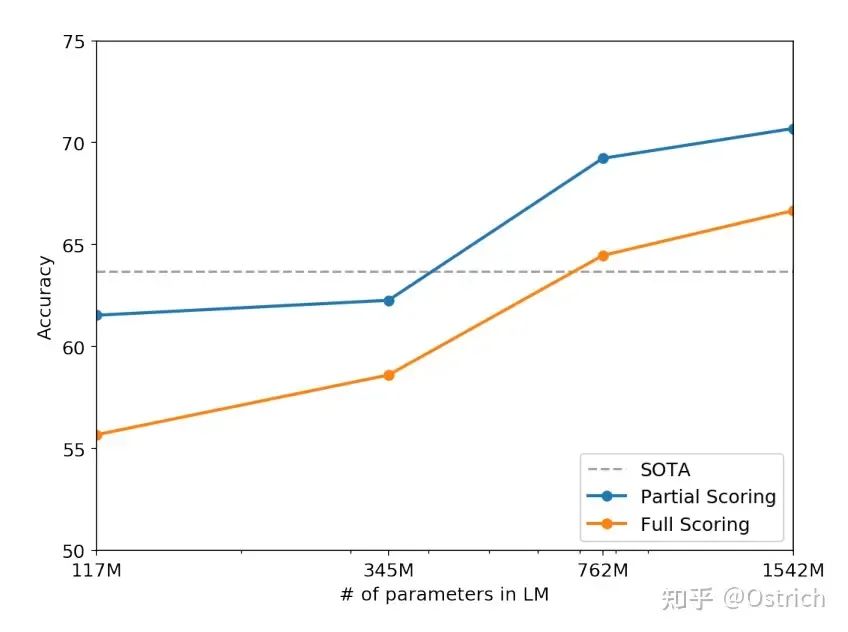
-
-
其他Zero-Shot任务
-
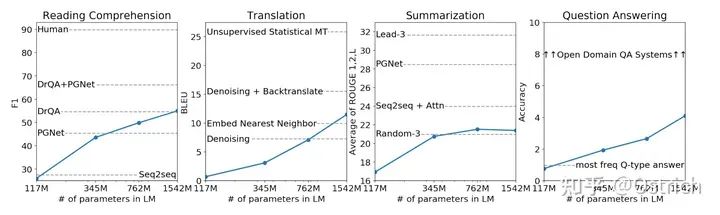
-
-
语言模型预训练集和验证集的效果(perplexity困惑度越小越好)
-
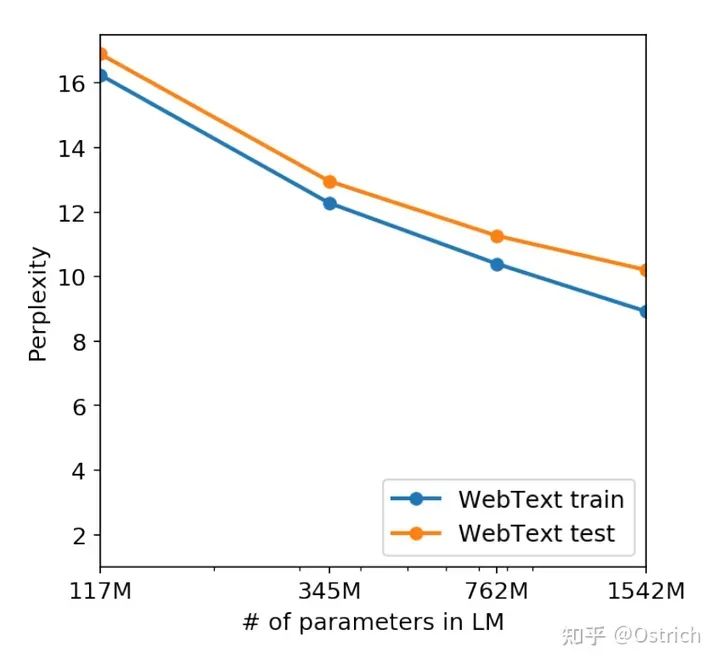
GPT-3
论文链接:《Language Models are Few-Shot Learners》
动机
BERT出来之后,虽然预训练+微调架构取得了惊人的效果(GPT系列短期比不了了),但这种微调有很多限制:
-
微调需要更多的领域数据,标注成本高,一些特殊任务更是难上加难(如纠错、写作、问答等)。
-
微调在小数据量下表现好,很可能只是过拟合。很多任务说是超过人类,实际上是夸大了实际表现(模型并不是根据知识和推理去做任务,并不智能)。
-
以人类的学习习惯对比,在人类有了足够的知识后(预训练),并不需要再看大量的监督数据才能做任务(对应微调),而只需要看少量样例即可。
文章认为,虽然微调现在效果确实打不过,但追求不微调仍然是值得的。方法嘛,延续GPT-2最后的结论,更大的模型、更多的数据、prompt更多的信息(In-Context learning)。
方案简述
主要与GPT-2相比:
-
沿用GPT-2的模型和训练方法,将模型大小升级到175B(1750亿的参数量 vs 15亿),这个175B的模型叫GPT-3;
-
不同于BERT/GPT-1模型使用下游任务微调进行效果验证,也不同于GPT-2仅仅使用Zero-Shot进行验证,GPT-3主要验证其In-Context learning的能力(可能认为是不微调,不梯度更新的方式,看通过prompt和几个例子作为输入,来完成具体任务的能力)。
-
GPT-3也不是不能微调,以后会做一些工作来看看微调的表现(这里说的也就是后面的Codex、InstructGPT和ChatGPT等工作了)。
一些细节
-
模型训练方式:前面提到了,相对GPT-2没有创新,就是更大模型、更多更丰富的数据、更长的训练时间,不止于Zero-Shot,还做One-Shot和Few-Shot任务(这里的x-Shot是不微调模型的,也就是所谓的In-Context learning,而在预训练阶段没有特殊操作),如图。
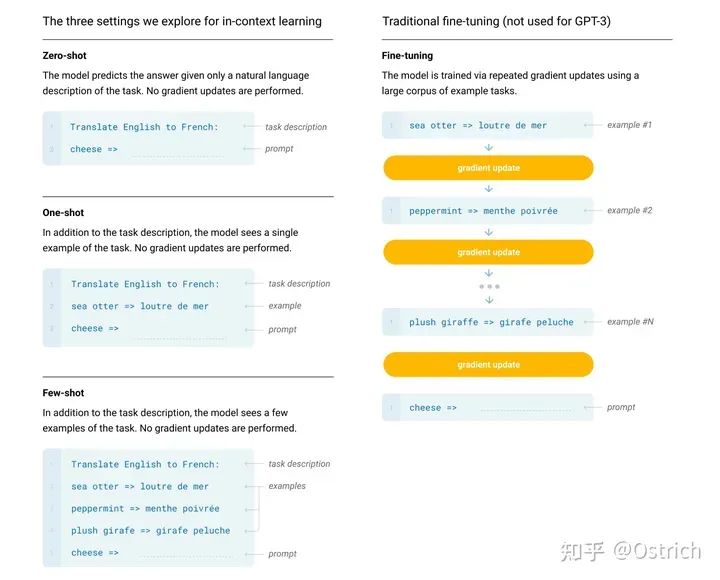
-
模型:沿用了GPT-2的结构,在模型初始化、归一化、Tokenization做了一些优化,另外也“抄”了一些类似Sparse Transformer的优点(总之是加了一些同期一些被验证有效的操作,或自己验证有效的小操作)。为了验证模型容量带来的效果,文章训练了多种大小的模型,最大的175B的叫GPT-3。为了训练大模型,还做了一些模型并行和提效的工作(其实这部分也比较重要,但是没有展开说)。模型大小参数,以及同期一些工作的训练资源开销对比如图:
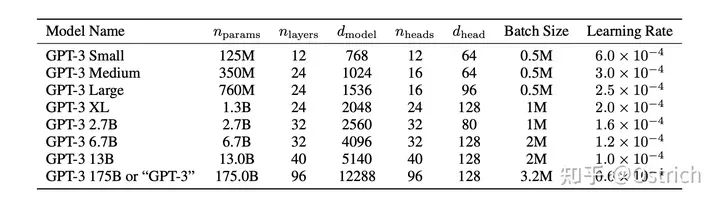
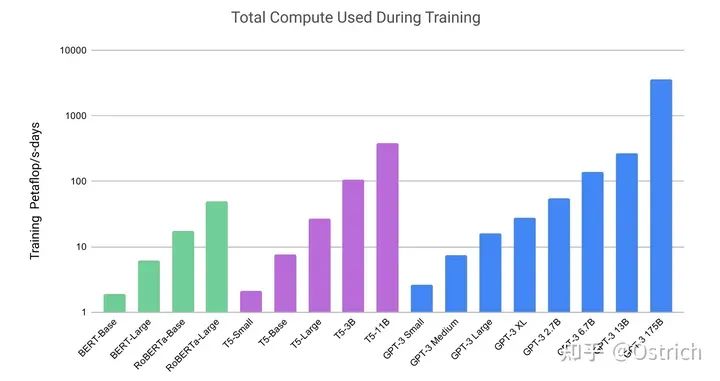
-
训练数据准备:
-
文章发现,模型增大之后,引入一些脏数据的负向影响没这么大了。因此,相比于GPT-2,GPT-3开始使用Common Crawl数据集了,但是做了一些清洗工作:1、保留与高质量数据集类似的内容(使用一些相似或判别的方法);2、去重;
-
最后把清洗后的Common Crawl数据和已有的高质量数据集合并在一起,得到训练数据集,并进行不同权重的采样使用:
-
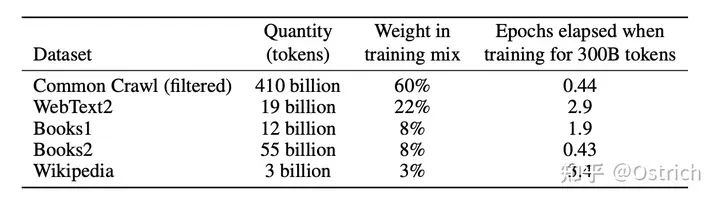
-
模型训练过程:
-
大模型可以使用更大的batch size,但是需要小一点的Learning rate;根据梯度的噪音尺度,动态调整batch size;为了防止大模型OOM,使用了全方位的模型并行,微软提供了硬件和软件的支持。
-
结论与讨论
-
主要结论:整体效果不错,在各种数据集上做了对比,NLU相关任务,GPT-3表现不错(个别数据集还超过了有监督微调的方式);在QA、翻译、推理等任务上还欠点火候,距离监督微调模型差距明显;生成任务基本可以做到人难分辨。如,几个主要的任务:
-
SuperGLUE:理解任务为主
-
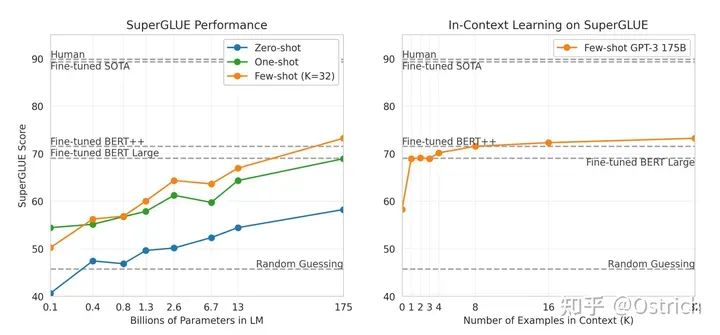
-
-
Winogrande:推理任务为主
-
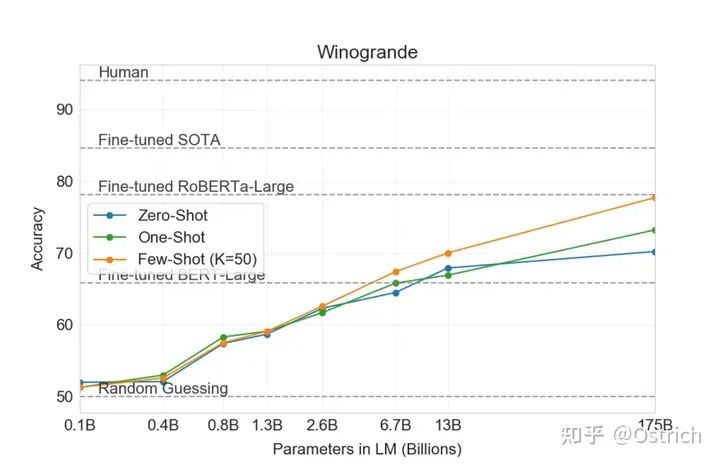
-
-
TriviaQA:阅读理解任务为主
-
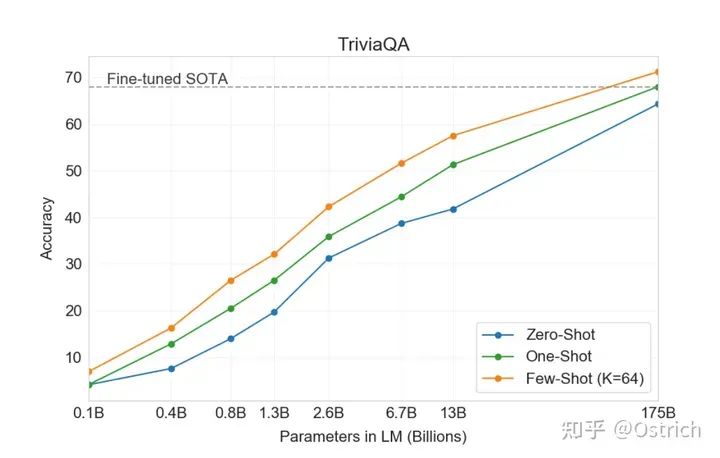
-
次要结论:
-
从主要结论曲线,可以明显发现,few-shot比zero-shot效果好,模型越大越好(废话),而且175B好像也没到极限,模型更大效果可能还会继续上升。
-
另一个数据显示,模型越大,loss下降空间越大,当前版本最大的模型,仍然没有收敛(黄色曲线);另一个不乐观的趋势是随着Loss的逐步降低,算力的ROI(投入产出比)也在逐渐降低。
-
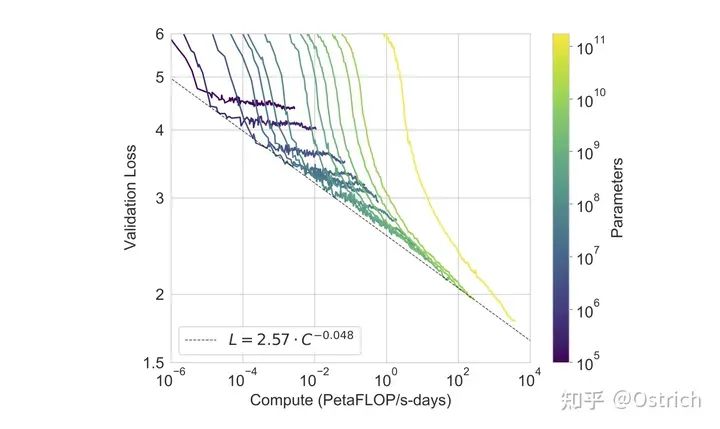
-
-
因为模型生成效果真假难辨,文章也着重讨论了模型的偏见、不道德以及不当用途的问题,因此也决定不开源(OpenAI走上CloseAI之路)!
-
Codex
论文链接:《Evaluating Large Language Models Trained on Code》
动机
GPT-3论文里提到,GPT可以微调但放在未来搞,Codex就是微调工作之一。任务是GPT模型在代码生成方向做微调的探索,算是一个应用方向的论文。
方案简述
具体地,Codex是利用代码注释生成代码。训练数据从github上获取,主要为python语言。为了验证模型效果,Codex做了一个新的数据集(164个原始代码问题,可以认为一些经典的leetcode题、面试题),通过单元测试的方式验证生成代码的正确性。
最终Codex可以取得28%的测试通过率(GPT-3只能解决0%);如果允许重复采样生成多个结果,选择100个,可以达到70%的通过率(想想自己能通过多少)。经过一些rerank策略,通过率直逼80%。
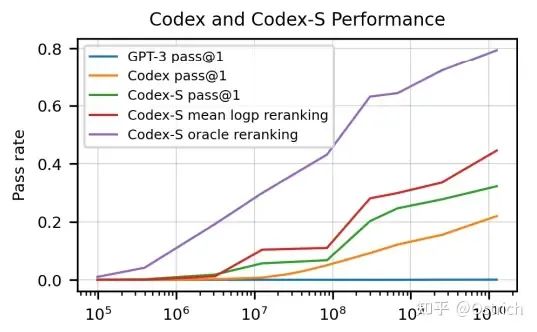
一些细节
-
验证集准备:因为之前没有现成的评测代码生成的验证集,文章自己设计了一个HumanEval。并使用pass@k作为评测指标(生成k个结果中有一个能通过就算通过,然后算通过率)。考虑生成代码的安全性不可控,需要使用一个sandbox环境运行(崩了也没事)。HumanEval的样例数据如下,包括代码注释和标准答案:
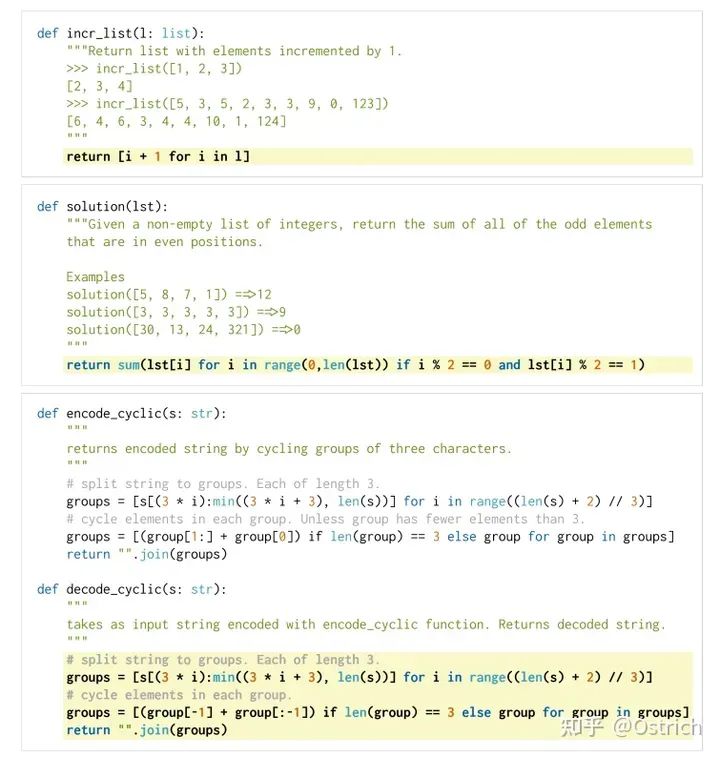
-
训练数据:截止到2020年5月,涉及540万的Github仓库,包括179GB的Python文件,文件大小小于1MB。做了一些过滤,主要过滤项是自动生成的代码、平均行长度大于100、最大行长度大于1000、包含一定比例数字等。最后数据集大小159GB。
-
模型:考虑生成任务,利用GPT系列的预训练模型应该会有好处,选择了13B的GPT模型作为主模型,进行微调。值得一提的是,利用预训练的GPT微调并不优于使用代码数据从头训练(应该是因为数据量已经足够大了),但是使用微调收敛更快。模型细节:
-
参数配置和GPT-3差不多;基于代码数据特点,做了特别的tokenizer,最终少了30%的token;sample数据时使用特别的停止符(' class'、' def'等),保证sample代码的完整性;
-
结论与讨论
-
主要结论:
-
不同的参数调整,和采样数量,显著影响生成代码的通过率。
-
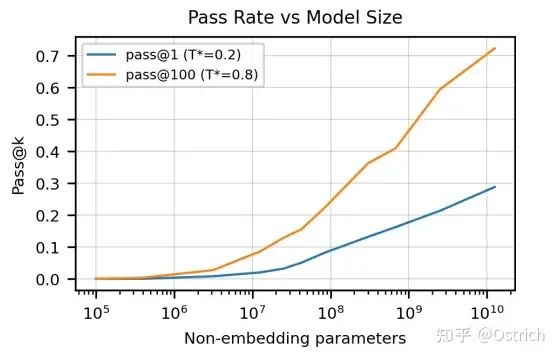
-
-
如果只选一个答案,使用一些模型输出指标,如最大mean log-probability,可以比随机选择效果更好;用借助先验知识的单元测试进行代码选择,可以取得理论上的最好效果(Oracle)。
-
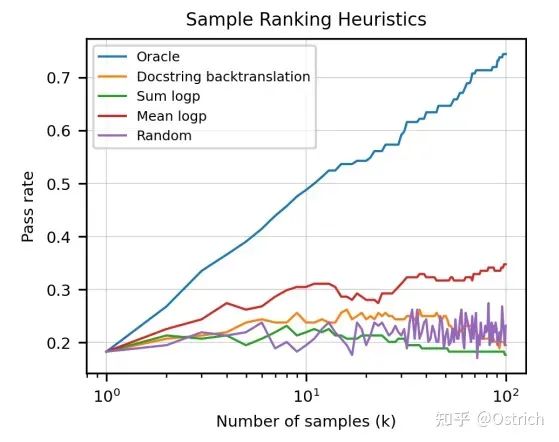
-
次要结论:因为效果还可以,趋势上看模型更大看上去效果还会提升,文章最后讨论了一下对于机器会写代码的担忧(自我优化最可怕);另外代码中也不出意外的有歧视、道德的偏见。(这个大概源自代码里也有人口吐芬芳,代码命名带Fxxk,有人的地方就有偏见)。
InstructGPT
论文链接:《Training language models to follow instructions with human feedback》
动机
GPT的另一种微调探索,使用用户指令和偏好答案来微调GPT模型,让模型生成的内容更符合用户的意图,更真实、更有用(Alignment,对齐过程)。这么做的出发点是面向一种经典的应用场景,用户给一条指令声明意图,期望模型生成有用、无害的内容,但使用大量网页数据训练的大语言模型GPT无法直接满足这种诉求,因此需要微调。
方案简述
指令微调的过程分为三步(RLHF,Reinforcement Learning from Human Feedback),如下图:
1、准备一批prompt(来源标注人员手写、OpenAI API请求);对于这批prompt,标注人员手写期望的答案,用这份prompt+answer数据微调GPT-3生成模型,这里叫做supervised policy;
2、使用微调后的模型,根据更多的prompt生成答案(一次prompt多次采样生成个答案),这时外包只要标注生成内容的相对顺序即可;用这份标注数据训练一个reward模型(RM模型),输入prompt和answer,模型输出一个打分(这里同样是使用GPT模型)。
3、采样更多的prompt,使用强化学习的方式,继续训练生成模型,强化学习的reward使用第2步的模型打分。
第2和3步是一个持续迭代的过程,即,第3步训练出的更好的生成模型(policy)可以用来收集更多具有相对顺序标签的数据,这些数据则用来训练新的RM模型(即步骤2),继而再训练新的生成模型(对应步骤3)。大多数的相对顺序标注数据来自于步骤1,一部分来自于步骤2和3的迭代。
此外这篇文章并不是第一个使用该方法的工作,前面还有一篇《Learning to summarize from human feedback》,使用类似三步方法做摘要任务。同样是OpenAI的工作,体现了工作的持续性,而非一蹴而就,灵感也不是说有就有。
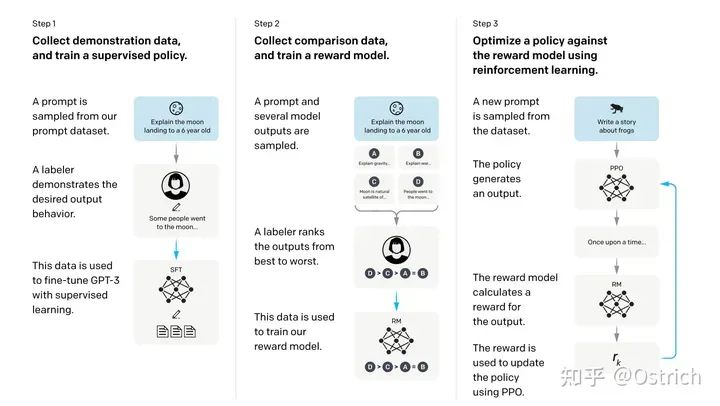
一些细节
-
数据收集过程
-
冷启动阶段:通过部分人工标注的prompt+answer数据,监督训练得到的早期版本InstructGPT;丰富阶段:部署试用版本在线服务,收集更多更丰富的真实用户prompt。本工作并未使用线上正式环境的服务用户数据,试用版本的数据将用于数据标注和模型训练,也提前告知了用户;
-
收集到的prompt根据最长公共前缀做了去重;
-
每个用户最多200条prompt,避免模型迎合个别用户偏好;训练集、验证集和测试集,不包括相同用户(强调用户维度的泛化能力);
-
过滤prompt中与个人身份相关的信息,同样是避免模型学到用户特征;
-
早期版本InstructGPT的训练数据是由外包手写的prompt和答案,冷启prompt包括3类:1、任意常见任务问题,追求任务的丰富性;2、同一类prompt写多个query和答案;3、模仿真实用户的prompt请求;
-
经过上面的操作,得到三类数据:1、SFT dataset,训练集13k prompts (来自于API和标注人员手写),用来训练SFT模型;2、RM数据集,训练集33k prompts (来自于API和标注人员手写),人工标注生成模型输出答案的排序,用来训练RM模型;3、PPO数据集,31k prompts(仅来自于API),不需要人工标注,用来做RLHF fine-tuning。
-
-
prompt特点:
-
真实用户的prompt指令类型分布和样例如图,96%的是英文,但结果发现对其他语言也有泛化能力。
-
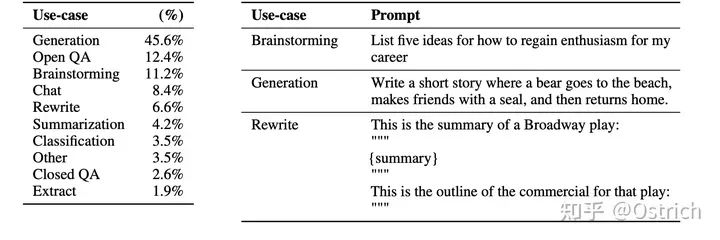
-
数据标注细节(也很关键,值得参考):
-
一个外包标注团队,由40个承包商组成,应该是为了提升标注多样性,防止模型对标注员风格敏感;
-
对标注人员进行了测试(考试,性格测试),筛选目标是留下那些队不同群体敏感(宗教、性取向、种族等)、能识别潜在有害内容的标注人员;
-
要求标注人员能够准确判断用户意图,对于模糊意图进行跳过;考虑隐含意图,对于一些潜在、诱导性的脏话、偏见、虚假信息能够识别;
-
训练和验证阶段的意图对齐(alignment)有些许冲突:训练阶段强调生成内容的有用性(helpfulness),验证阶段则关注内容的真实性(truthfulness)和是否有害(harmlessness);
-
标注过程,算法开发和标注人员紧密沟通,为了做到这点,对外包标注人员做了一个入职流程(可能要交社保=_=);
-
为了测试模型对标注人员的泛化能力,留了一部分测试用的标注人员(held-out labelers,真工具人,严谨了),这些标注人员产出的数据不用于训练,而且这些人员没有经过性格测试;
-
尽管标注任务难度大,但标注人员的标注一致性还可以,训练标注人员标注一致性72.6 ± 1.5%,测试标注人员一致性77.3 ± 1.3%。
-
-
模型实现:同训练过程,包括三部分
-
Supervised fine-tuning (SFT):使用标注人员标注的数据,有监督的微调GPT模型,训了16个epoch, 学习率cosine decay。模型的选择使用验证集上的RM模型score(鸡生蛋蛋生鸡)。值得一提的是,这里SFT模型在验证集上1个epoch后就overfit了,但是继续更多的epoch有利于RM score和人的偏好。
-
Reward modeling (RM):
-
模型:同样是SFT GPT模型结构,不过是另外训练了一个6B的(175B不稳定,不适合下面的RL训练),输入是prompt和生成的内容,pooling后接一个全连接(也许有)输出一个scalar reward分。
-
Loss函数表示为:
-
-
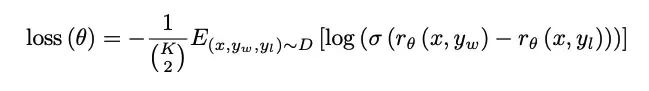
-
-
-
K为是一个prompt模型生成的答案数,标注人员对K个模型进行排序;K为4-9,标9个和4个成本差不多;
-
需要一个bias对reward进行归一,使其均值为0,方便下游RL使用(这里的bias可以是reword均值,也是RL的常规操作);
-
-
Reinforcement learning (RL),两个实验模型:
-
‘PPO’模型:直接使用经典的PPO算法,一种offline的RL算法,目标是最大化模型反馈的reward,同时兼顾online模型和offline模型的KL散度(这里offline模型是SFT模型,online模型是要优化的目标模型,online模型参数会定期同步到offline模型。如果不熟悉RL可以简单了解其目标即可);模型输出的reward,由RM打分得到;
-
‘PPO-ptx’模型:PPO+预训练目标(加这个目标,被验证可以兼顾公开NLP任务的效果),最终的优化目标,最大化:
-
-
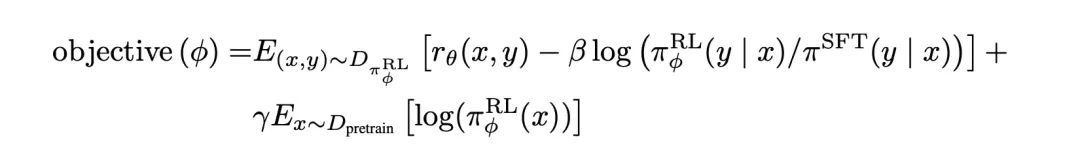
-
验证方法:评价模型两方面的能力,1、生成的答案人是不是喜欢;2、经典的NLP任务解决的怎么样。
-
在API请求的prompt验证效果:
-
真实分布下采样prompt做测试集;
-
175B的SFT GPT-3模型作为Baseline;
-
标注人员对各个模型生成的内容打出1-7分的喜欢/认可度;
-
认可度的依据是helpful、honest和harmless,每个维度又有很多细则。
-
-
在开源的NLP数据集,包括两类:
-
评测安全性、真实性、有害和偏见的数据集;
-
经典NLP任务数据集熵zero-shot的结果,如阅读理解、问答、摘要等。
-
-
结论与讨论
-
主要结论:
-
对于通过API获得的测试集prompt,RLHF显出好于baseline:
-
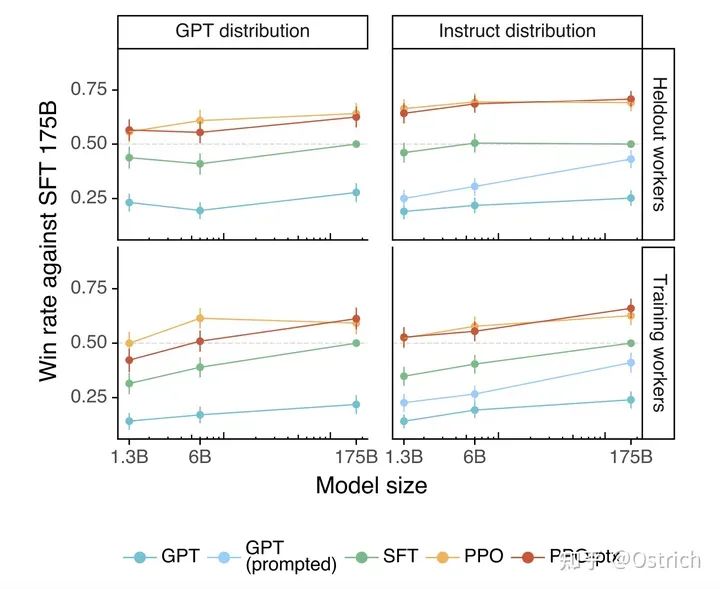
-
-
对比友商模型,也不错:
-
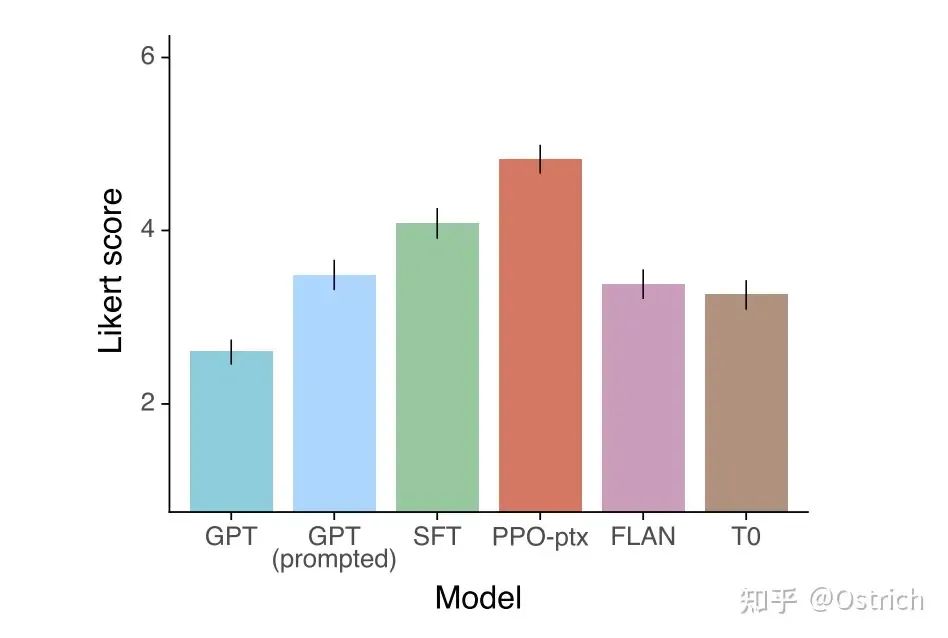
-
次要结论(InstructGPT生成内容的白话评价):
-
标注人员普遍认为InstructGPT生成的内容比GPT-3强很多;
-
InstructGPT模型生成的内容比GPT-3事实性更强(出现事实性错误比较少);
-
InstructGPT生成的内容在有害性优于GPT-3,但在偏见方面并没有强很多;
-
在RLHF微调过程中,由于“对齐税”的原因,在开源NLP任务表现变差了,但RLHF基础上增加语言模型的预训练目标,可以得到兼顾(PPO-ptx)。
-
InstructGPT模型在 “held-out”标注人员上也表现出了不错的泛化性;
-
公开NLP数据集任务上的表现,并不是InstructGPT追求的(ChatGPT才是);
-
InstructGPT模型在RLHF finetuning数据集分布外的prompt同样具有很好的泛化能力;
-
InstructGPT生成的内容仍然会出现一些简单的错误;
-
ChatGPT
论文没有,官方博客:《https://openai.com/blog/chatgpt》
OpenAI没有开放ChatGPT的细节,只有两段大致方法描述,摘要一下包括:
-
和InstructGPT的方法大致相同,只是在数据收集上略有不同。ChatGPT使用的对话形式的数据,即多轮prompt和上下文,InstructGPT的数据集也转换成对话格式合并一起使用。
-
训练RM模型,使用多个模型生成的结果,随机选择模型生成的内容让标注人员根据内容质量排序,然后借助RM模型进行后续的PPO微调训练。同样,这也是一个反复迭代的过程。
更多的细节无了,不过从OpenAI友商Anthropic(创始人也来自OpenAI)的一篇论文能看到更多细节。以OpenAI工作的持续性看,从公司跳槽出去的人,应该也是延续了相关的工作。
读Anthropic之前,插一段OpenAI的系列工作总结,存个档。读了上面的论文,对于这张表的内容应该能够大致理解(参考):
| 能力 | 模型名 | 训练方法 | OpenAI API |
| Before GPT-3 | |||
| Pretrain + Fintune like Bert | GPT-1 | Language Modeling + Task Finetune | - |
| Generation+Zero-shot task | GPT-2 | Language Modeling | - |
| GPT-3 Series | |||
| Generation+World Knowledge+In-context Learning | GPT-3 Initial | Language Modeling | Davinci |
| +Follow Human Instruction+generalize to unseen task | Instruct-GPT initial | Instruction Tuning | Davinci-Instruct-Beta |
| +Code Understanding+Code Generation | Codex initial | Training on Code | Code-Cushman-001 |
| GPT-3.5 Series | |||
| ++Code Understandning++Code Generation++Complex Reasoning / Chain of Thought (why?)+long-term dependency (probably) | Current Codex Strongest model in GPT3.5 Series | Training on text + code Tuning on instructions | Code-Davinci-002 (currently free. current = Dec. 2022) |
| ++Follow Human Instruction--In-context learning--Reasoning++Zero-shot generation | Instruct-GPT supervisedTrade in-context learning for zero-shot generation | Supervised instruction tuning | Text-Davinci-002 |
| +Follow human value+More detailed generation+in-context learning+zero-shot generation | Instruct-GPT RLHF More aligned than 002, less performance loss | Instruction tuning w. RLHF | Text-Davinci-003 |
| ++Follow human value++More detailed generation++Reject questions beyond its knowledge (why?) ++Model dialog context --In-context learning | ChatGPT Trade in-context learning for dialog history modeling | Tuning on dialog w. RLHF | - |
可能确实如一些大佬所说,ChatGPT没有创新,只是一堆策略的叠加,凑出了一个强大的模型;也有人说ChatGPT更多的是工程和算法的结合。不管怎么样,方法是真work。
Anthropic的Claude
参考论文链接:《Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback》
ChatGPT出来不久,Anthropic很快推出了Claude,媒体口径下是ChatGPT最有力的竞争者。能这么快的跟进,大概率是同期工作(甚至更早,相关工作论文要早几个月)。Anthropic是OpenAI员工离职创业公司,据说是与OpenAI理念不一分道扬镳(也许是不开放、社会责任感?)。
一些内测结论:Claude相比ChatGPT更能避免潜在harmful的问题,在代码生成略为逊色,通用Prompt不分伯仲。从效果上,可能ChatGPT功能性更强,而Claude更为“无害”(或者说,对社会的潜在负面影响更小),这点从参考论文的标题也有所体现。
动机
引入偏好模型和RLHF(人类反馈强化学习)微调大语言模型(可能因为脱离OpenAI,不提GPT-3了),得到一个helpful和harmless的个人助理(类似ChatGPT);这种对齐(Alignment)微调,使预训练的语言模型在几乎所有的NLP任务中效果提升显著,并且可以完成特定的任务技能,如coding、摘要和翻译等。
方案简述
其实思路和InstructGPT差不多,三阶段的RLHF。不同点在于,1、进行了迭代式的在线模型训练:模型和RL策略每周使用新的人工反馈数据更新,不断迭代数据和模型;2、使用对话格式的数据数据;3、更为关注模型的helpful和harmless。
除了模型和策略设计之外,文章重点讨论了RLHF的稳定性问题;也对模型校准、目标冲突、OOD(out of distribution)识别等问题做了分析。
目标冲突是指helpful和harmless的目标冲突,因为如果模型对所有问题都回答“不知道”,虽然harmless,但是完全不helpful。
一些细节
-
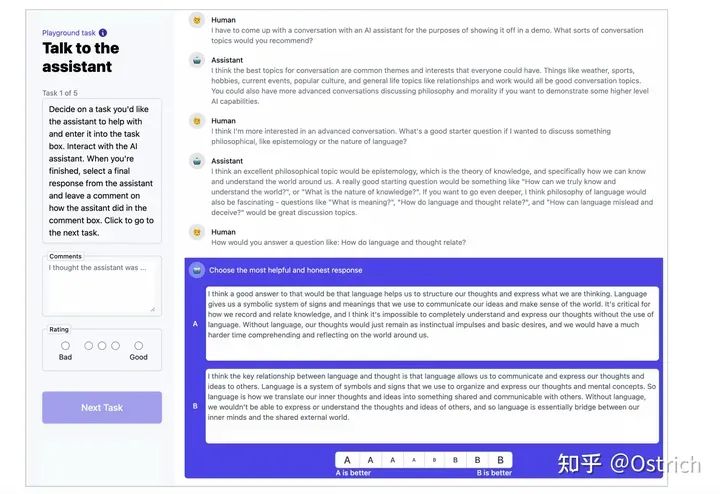
对话偏好数据集:
-
收集了一批helpfulness and harmlessness的对话数据集,数据的标注是标注人员和各种52B语言模型在对话标注页面交互完成。标注页面如图;
-
-
-
标注人员在交互页面与模型进行开放式对话,或者寻求帮助、或者提出指令、或者引导模型输出有害内容(比如如何成功抢劫)。对于模型输出的多个答案,标注人员需要在每轮对话标注出哪个更有用或哪个更有害;
-
收集了三份数据,一个来自于初始模型(SFT)、一个来自早期的偏好模型(RM)采样、最后一个来自人工反馈的在线强化学习模型(周更);
-
开源了三份数据:https://github.com/anthropics/hh-rlhf
-
-
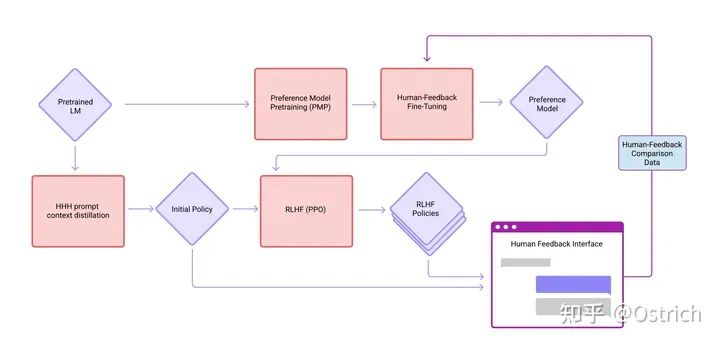
数据收集和模型训练流程(中间涉及的概念需要读往期论文,了解即可):
LLaMa与Alpaca
事情发展到现在,有一个小问题,就是模型越来越大,开源越来越少(其实开源了大多数人也玩不了)。首先GPT-3系列模型就很大了,训练和inference模型都需要大量的显卡;其次,GPT-3所用的数据也未公开,有算力复现也稍困难,需要自己去盘数据;在GPT-3之后的ChatGPT的闭源程度更甚,可能要进一步考虑商业利益。
在这样的背景下,前调模型提效以及开放的工作越来越多,近期比较有影响里的当属Meta AI的LLama和斯坦福基于LLama的Alpaca。前者类似GPT的大语言模型,后者类似ChatGPT。
LLama
论文:《LLaMA: Open and Efficient Foundation Language Models》
代码:https://github.com/facebookresearch/llama
动机
-
大语言模型相关的工作中,过去的普遍假设是模型越大效果越好。但近期有些工作表明,给定计算资源的前提下,最佳的效果不是由最大的模型实现,而是由更多的数据下相对小的模型实现。而后者对于inference或微调阶段更为友好,是更好的追求。
-
相应的,本文的工作是训练一批模型,实现了更好的效果,同时预测成本低。取得这种效果的一大手段,就是让模型看到了更多的token。训练得到的这些模型就是LLama。
方案简述
LLama的思想比较简单,在动机里已经大致包括。这项工作的其他特点可以简述为以下几点:
-
提供了7B~65B的模型,13B的模型效果可超GPT-3(175B),65B的模型效果直逼谷歌的PaLM(540B);
-
训练模型只用了开源数据集,trillions of token。
-
多项任务上SOTA,并且开源了所有模型权重。
一些细节
-
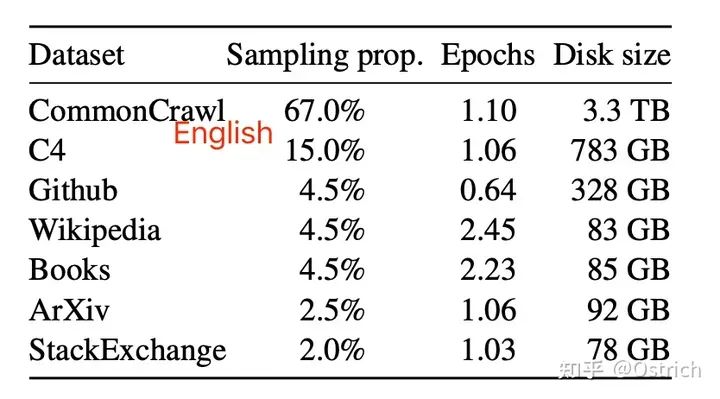
训练数据集(主要是英文,因此中文和中文微调效果堪忧)
-
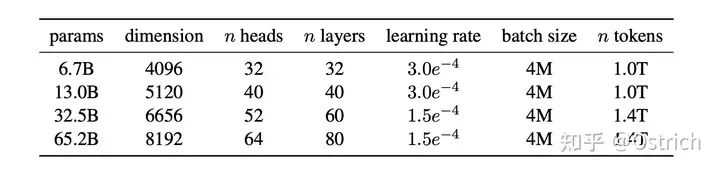
模型容量概况
-
模型结构:
和GPT一样,同样是Transformer Decoder架构,沿用了各种工作被验证有效的小优化(如:Pre-Normalization、SwiGLU激活函数、Rotary Embedding、AdamW优化器等)。同时也做了一些训练效率上的优化,包括模型实现上以及模型并行上的优化。
-
训练过程:7B和13B的模型在1T的token上进行训练;33B和65B的模型则在1.4T的token上进行了训练。
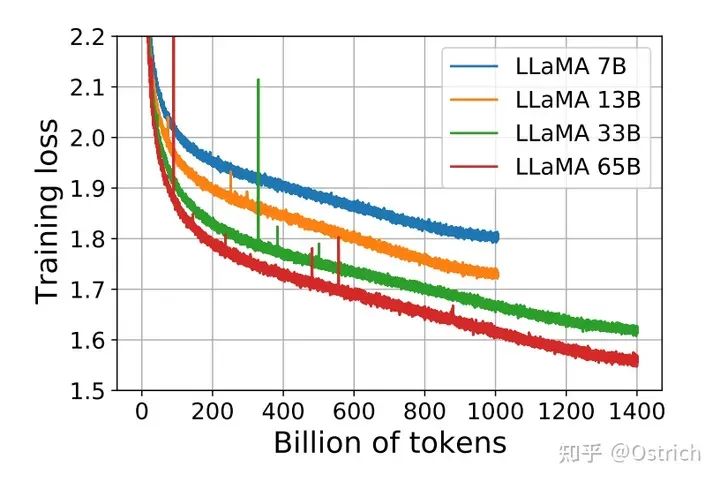
结论与讨论
-
LLama对标GPT,主要在Zero-Shot和Few-Shot任务上进行了验证;同时考虑指令微调是现在的流行应用之一,因此也在指令微调任务做了验证。
-
Zero-Shot
-
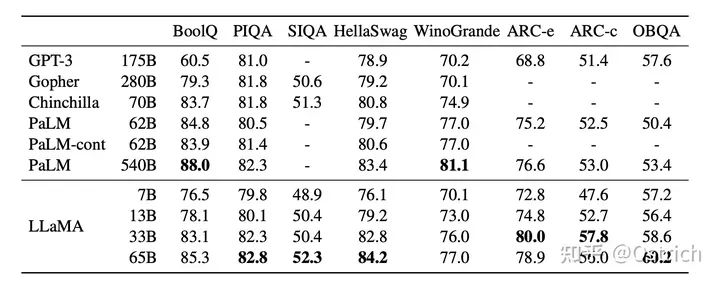
-
-
Few-Shot
-
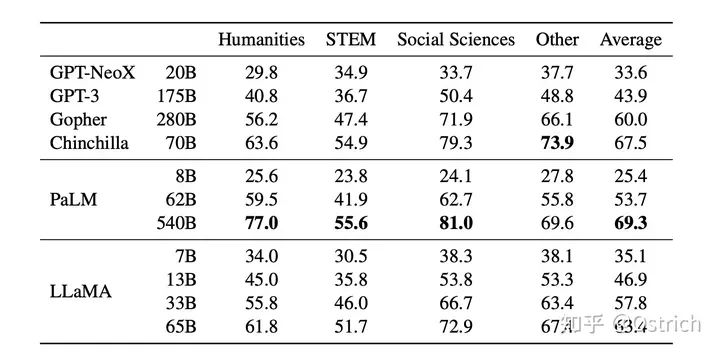
-
-
指令微调(主要和谷歌的Flan系列做对比):
-
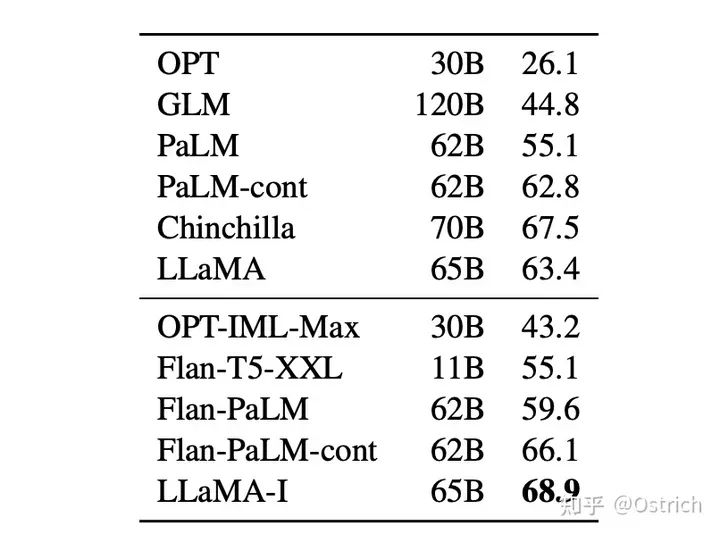
Alpaca
文章:https://crfm.stanford.edu/2023/03/13/alpaca.html
代码:https://github.com/tatsu-lab/stanford_alpaca
动机
前面可以看到,GPT-3.5、ChatGPT、Claude以及Bing Chat等指令微调模型被验证效果拔群,但仍存在生存内容虚假、带偏见和恶意等问题。为了加快这些问题的解决,需要学术届(穷老师、学生、公司)的加入一起研究,但是GPT-3.5这些模型大且闭源。
前阵子LLama发布,给了希望。所以基于LLama做指令微调得到了Alpaca模型,效果和GPT-3.5差不多,而且简单、复现成本低。
方案简述
-
穷人搞指令微调,需要两个前提:1、参数量小且效果好的预训练语言模型;2、高质量的指令训练数据。
-
这两个前提,现在看上去可以方便满足:1、LLama模型7B模型,可以接受;2、通过现有的强语言模型可以自动生产训练数据(准备prompt,调用GPT-3.5系列的OpenAI api)。
一些细节
-
训练方式:使用指令微调的方式,在LLama 7B模型上训练;训练数据规模为5.2万,来源是对OpenAI GPT-3.5 API的调用(花费500美元);微调过程在8张 80G A100s显卡训练3小时(使用云计算服务,花费100美元)。训练过程如图。
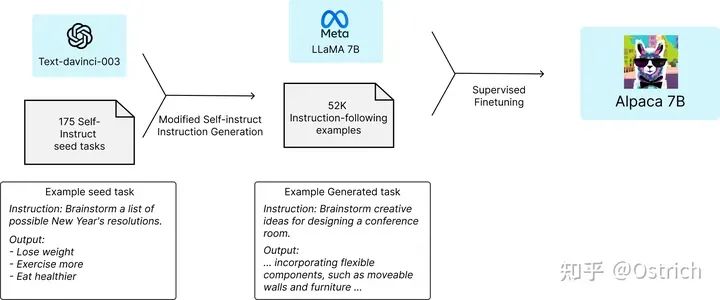
结论和讨论
目前开放了:测试Demo、训练数据集、训练数据的生成过程、训练代码;预训练的权重未来开放(可能考虑一些外因);
-
Demo: an interactive demo for everyone to try out Alpaca.
-
Data:52K demonstrationsused to fine-tune Alpaca.
-
Data generation process: the code forgenerating the data.
-
Training code: for fine-tuning the model using the Hugging Face API.
未来可能的方向(不包括优化推理能力,也许这些还是要留给有钱人):
-
模型验证:更加系统严格的对模型进行评估,会从HELM (Holistic Evaluation of Language Models) 开始,检验模型的生成和指令对其能力;
-
模型的安全性:更全面的评估模型的风险性;
-
理解模型(可解释):研究模型学到的是什么?基模型的选择有什么学问?增加模型参数带来的是什么?指令数据最关键的是什么?有没有其他的收集数据的方法?
GLM与ChatGLM
LLama虽好,但更多的是使用英文数据集,但在中文上表现不佳。同样指令微调后在中文场景下上限应该也比较低。因此在中文上,有必要有自己的一条研究方向,当前影响力比较高的开源版本属清华的GLM和ChatGLM。
GLM和ChatGLM相关的介绍比较多,下面摘抄部分内容对其进行简单了解。
GLM
论文:
-
《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》
-
《GLM-130B: AN OPEN BILINGUAL PRE-TRAINED MODEL》
方案简述
GLM-130B是在GPT-3之后,清华的大语言模型方向的尝试。不同于 BERT、GPT-3 以及 T5 的架构,GLM-130B是一个包含多目标函数的自回归预训练模型。
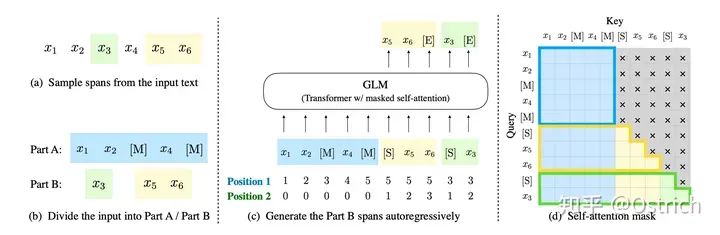
一些细节
GLM-130B在2022年8月开放,有一些独特的优势:
-
双语:同时支持中文和英文。
-
高精度(英文):在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
-
高精度(中文):在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
-
快速推理:首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
-
可复现性:所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
-
跨平台:支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
ChatGLM
文章:https://chatglm.cn/blog
代码:https://github.com/THUDM/ChatGLM-6B
方案简介
ChatGLM参考ChatGPT 的设计思路,在千亿基座模型 GLM-130B中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。
为与社区一起更好地推动大模型技术的发展,清华同时开源 ChatGLM-6B 模型。ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM(http://chatglm.cn)相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。
一些细节
ChatGLM-6B 有如下特点:
-
充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
-
优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
-
较低的部署门槛:FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
-
更长的序列长度:相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
-
人类意图对齐训练:使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。ChatGLM-6B 也有相当多已知的局限和不足:
-
模型容量较小:6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
-
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
-
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
-
英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
-
易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
小结
到这里还是低谷了工作量,写吐了,谷歌系列的几个工作,还是得单独一篇才能完结。与OpenAI的工作类似,谷歌同样产出了对标GPT-3和InstructGPT之类的模型,也包括了T5系列的Encoder-Decoder结构的大语言模型,而且并不是简单的Follow。
另一方面3、4月份,广大的开源工作者们也是百花齐放,在类ChatGPT的应用方向做出了很多探索工作,包括训练数据、模型、以及训练方法的探索与开源。在训练效率方向上,也出现了ChatGLM+Lora、LLama+Lora等进一步降低训练成本的工作。
这部分的内容也将在后面进行总结式的介绍和更新,也期待在这段时间里有更多优秀的工作诞生。对于文章中内容中的不正之处,也欢迎指正交流~。
审核编辑 :李倩
-
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程2024-06-03 50955
-
朋友们帮忙啊2011-03-31 1896
-
祝朋友们新年快乐2013-01-01 2541
-
fpga学习群,欢迎朋友们加入2013-06-08 2360
-
朋友们,我是新人请多多帮助2012-12-20 2196
-
加油了 电设的朋友们2013-09-02 1574
-
PCB技术交流群 262600057 pcb菜鸟们的天堂 做PCB的朋友们值...2014-06-22 3637
-
LabViEW宝典,需要的朋友们拿去~2014-08-06 10951
-
来哦来哦!!!电子设计大赛 请朋友们进来讨论2015-06-18 4445
-
实验室的朋友们看过2016-04-11 6579
-
如何在imx6上移植ubunt16.04系统,有移植过的朋友们吗?2022-11-30 535
-
PLC控制系统怎么提升运行速度?有啥好方法嘛?朋友们2023-01-17 13607
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
ChatGPT浪潮下,看中国大语言模型产业发展2023-06-01 1819
-
llm模型和chatGPT的区别2024-07-09 2864
全部0条评论

快来发表一下你的评论吧 !
