

可视化CNN和特征图
电子说
1.4w人已加入
描述
作者:Ahzam Ejaz来源:DeepHub IMBA

 kernel/filter:kernel(也称为filter 或 weight )是一个可学习参数的小矩阵,用于从输入数据中提取特征。在下图中,输入图像的大小为(5,5),过滤器filter 的大小为(3,3),绿色为输入图像,黄色区域为该图像的过滤器。在输入图像上滑动滤波器,计算滤波器与输入图像的相应像素之间的点积。Padding是valid (也就是没有填充)。stride值为1。
kernel/filter:kernel(也称为filter 或 weight )是一个可学习参数的小矩阵,用于从输入数据中提取特征。在下图中,输入图像的大小为(5,5),过滤器filter 的大小为(3,3),绿色为输入图像,黄色区域为该图像的过滤器。在输入图像上滑动滤波器,计算滤波器与输入图像的相应像素之间的点积。Padding是valid (也就是没有填充)。stride值为1。
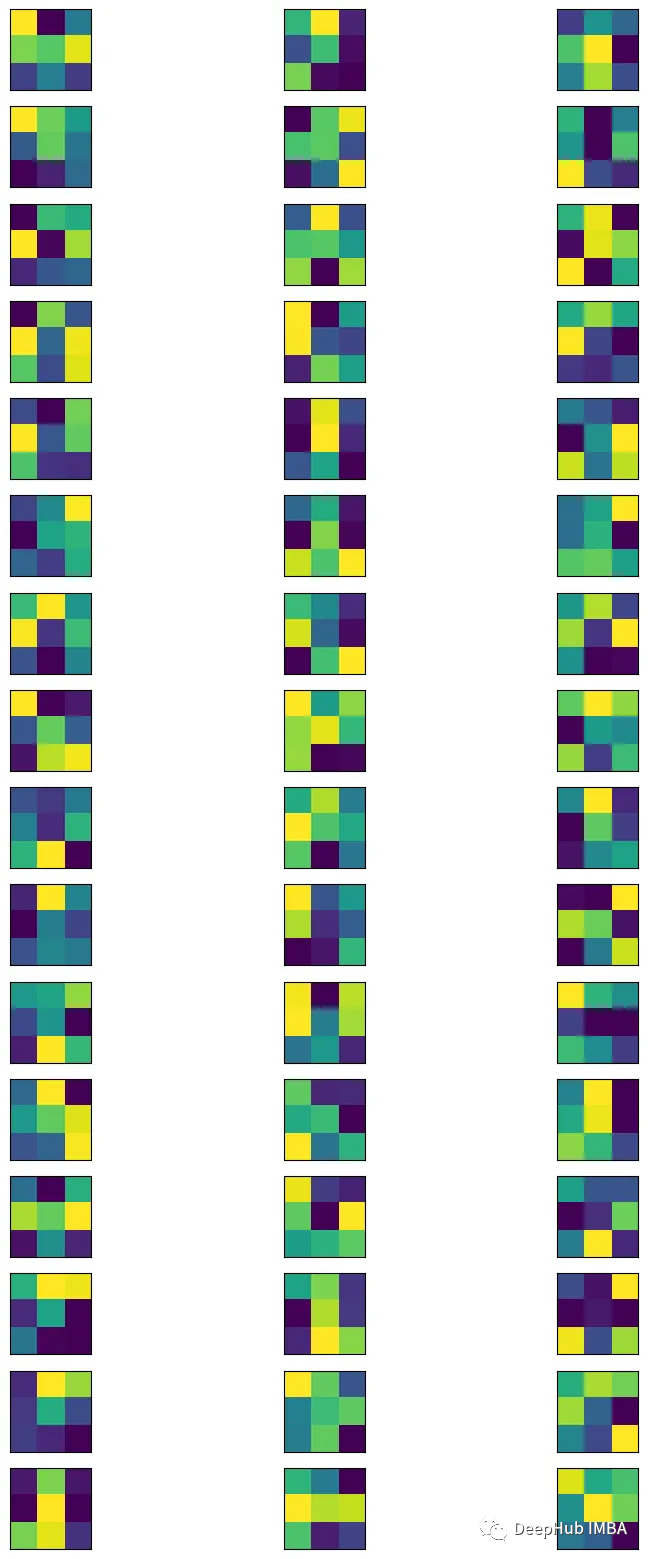 将图像输入到模型中得到特征图
将图像输入到模型中得到特征图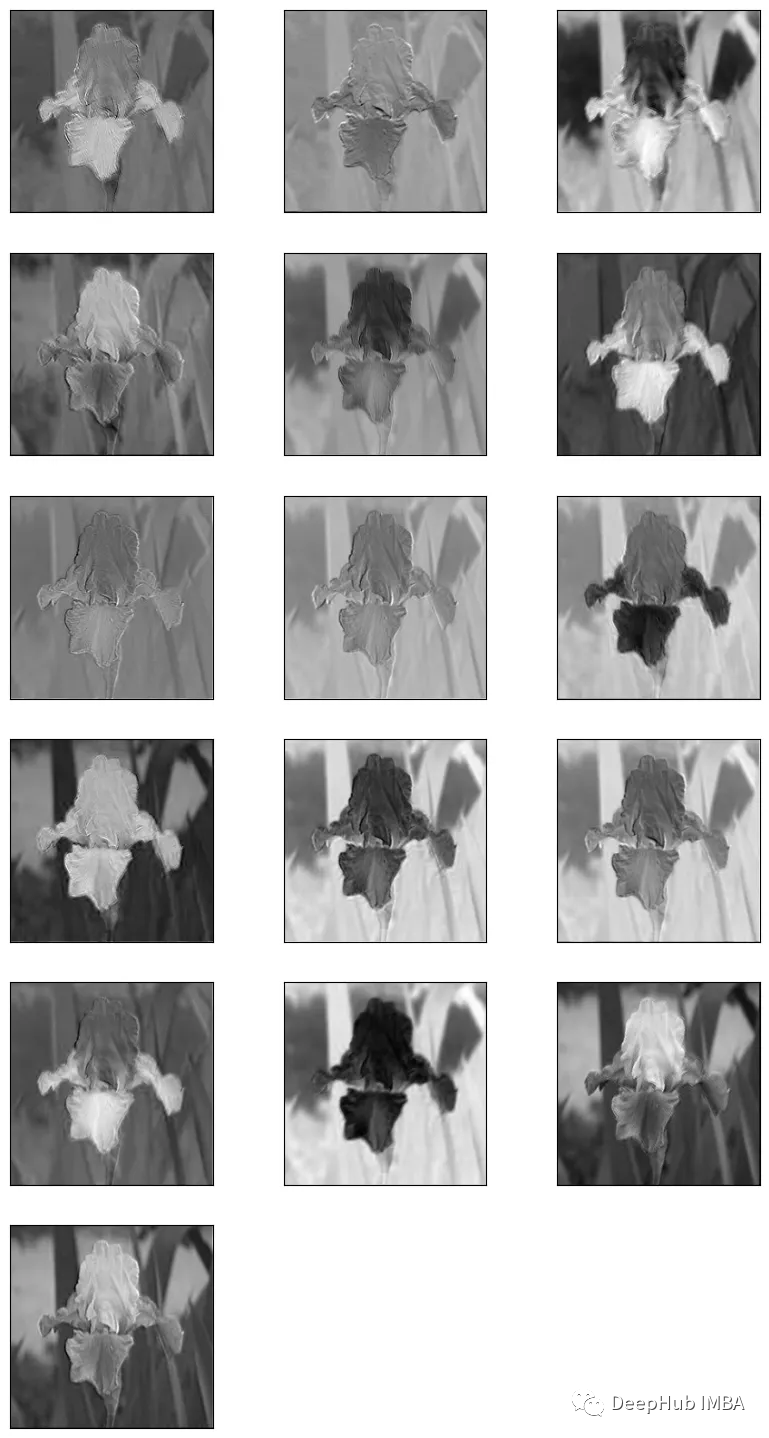
卷积神经网络(cnn)是一种神经网络,通常用于图像分类、目标检测和其他计算机视觉任务。CNN的关键组件之一是特征图,它是通过对图像应用卷积滤波器生成的输入图像的表示。
理解卷积层
1、卷积操作卷积的概念是CNN操作的核心。卷积是一种数学运算,它把两个函数结合起来产生第三个函数。在cnn的上下文中,这两个函数是输入图像和滤波器,而得到的结果就是特征图。
2、卷积的层
卷积层包括在输入图像上滑动滤波器,并计算滤波器与输入图像的相应补丁之间的点积。然后将结果输出值存储在特征映射中的相应位置。通过应用多个过滤器,每个过滤器检测一个不同的特征,我们可以生成多个特征映射。
3、重要参数
Stride:Stride 是指卷积滤波器在卷积运算过程中在输入数据上移动的步长。
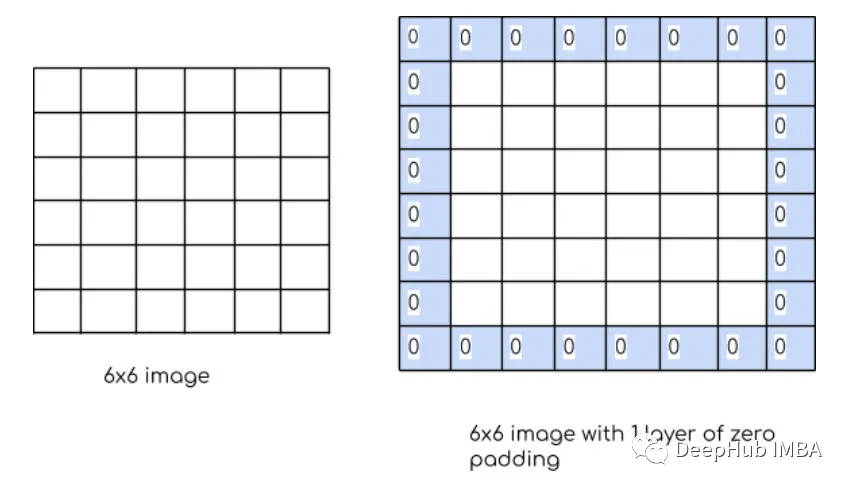
Padding:Padding是指在应用卷积操作之前在输入图像或特征映射的边界周围添加额外像素。Padding的目的是控制输出特征图的大小,保证滤波窗口能够覆盖输入图像或特征图的边缘。如果没有填充,过滤器窗口将无法覆盖输入数据的边缘,导致输出特征映射的大小减小和信息丢失。有两种类型的填充“valid”和“same”。kernel/filter:kernel(也称为filter 或 weight )是一个可学习参数的小矩阵,用于从输入数据中提取特征。在下图中,输入图像的大小为(5,5),过滤器filter 的大小为(3,3),绿色为输入图像,黄色区域为该图像的过滤器。在输入图像上滑动滤波器,计算滤波器与输入图像的相应像素之间的点积。Padding是valid (也就是没有填充)。stride值为1。
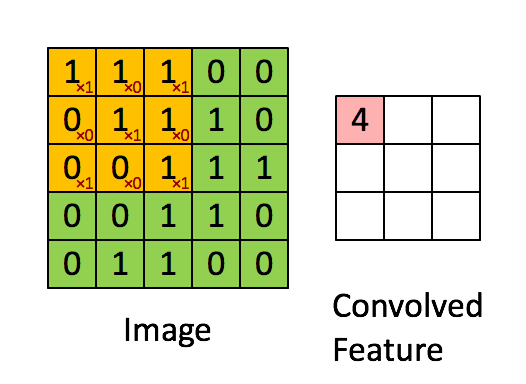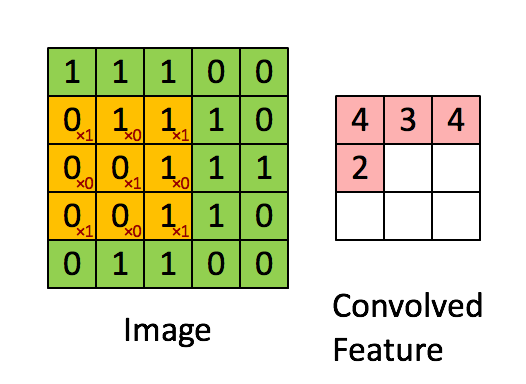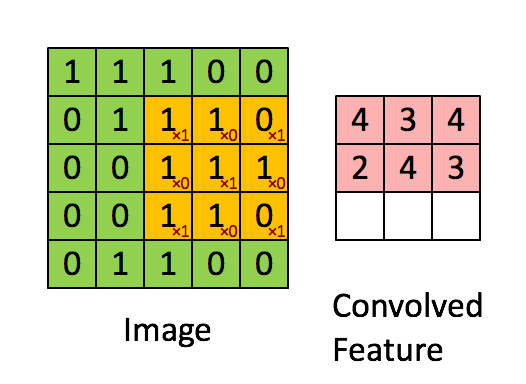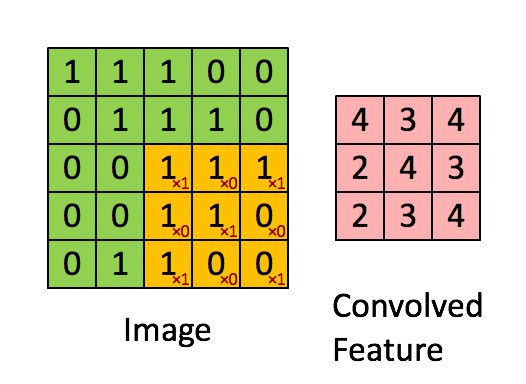
Output_Size = (Input_Size - Filter_Size + 2 * Padding) / Stride + 1
这个公式非常重要,因为在计算输出时肯定会用到,所以一定要记住来自一个卷积层的特征映射作为网络中下一层的输入数据。随着层数的增加,网络能够学习越来越复杂和抽象的特征。通过结合来自多层的特征,网络可以识别输入数据中的复杂模式,并做出准确的预测。特征图可视化
这里我们使用TF作为框架进行演示
## Importing libraries
# Image processing library
import cv2
# Keras from tensorflow
import keras
# In Keras, the layers module provides a set of pre-built layer classes that can be used to construct neural networks.
from keras import layers
# For ploting graphs and images
import matplotlib.pyplot as plt
import numpy as np
使用OpenCV导入一张图像,并将其大小调整为224 x 224像素。
img_size = (224, 224)
file_name = "./data/archive/flowers/iris/10802001213_7687db7f0c_c.jpg"
img = cv2.imread(file_name) # reading the image
img = cv2.resize(img, img_size)
我们添加2个卷积层:
model = keras.Sequential()
filters = 16
model.add(layers.Conv2D(input_shape = (224, 224, 3),filters = filters, kernel_size= 3))
model.add(layers.Conv2D(filters = filters, kernel_size= 3))
从卷积层中获取过滤器。
bias = model.layers[0].get_weights()
min_filter = filters.min()
max_filter = filters.max()
filters = (filters - min_filter) / (max_filter - min_filter)p
可视化
= plt.figure(figsize= (10, 20))
= filters.shape[-1]
= filters.shape[0]
= 1
:
:
channels, index)
:, :, filter])
plt.xticks([])
plt.yticks([])
=1
plt.show()
将图像输入到模型中得到特征图
= (img - img.min()) / (img.max() - img.min())
= normalized_img.reshape(-1, 224, 224, 3)
= model.predict(normalized_img)
特征图需要进行归一化这样才可以在matplotlib中显示
feature_map = (feature_map - feature_map.min())/ (feature_map.max() - feature_map.min())
提取特征图并显示
total_imgs = feature_map.shape[0]
no_features = feature_map.shape[-1]
fig = plt.figure(figsize=(10, 50))
index = 1
for image_no in range(total_imgs):
for feature in range(no_features):
# plotting for 16 filters that produced 16 feature maps
plt.subplot(no_features, 3, index)
plt.imshow(feature_map[image_no, :, :, feature], cmap="gray")
plt.xticks([])
plt.yticks([])
index+=1
plt.show()
总结
通过可视化CNN不同层的特征图,可以更好地理解网络在处理图像时“看到”的是什么。例如,第一层可能会学习简单的特征,如边缘和角落,而后面的层可能会学习更抽象的特征,如特定物体的存在。通过查看特征图,我们还可以识别图像中对网络决策过程重要的区域。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- imagination
-
可视化MES系统软件2018-11-30 3455
-
利用Keras实现四种卷积神经网络(CNN)可视化2019-07-12 4016
-
如何把AD中非可视化区域物件移到可视化区域?2019-09-10 2527
-
基于STM的可视化门禁系统2020-03-07 3044
-
Python数据可视化2020-07-19 3414
-
TensorFlow TensorBoard可视化数据流图2020-07-22 2055
-
三维可视化的应用和优势2020-12-02 2808
-
常见的几种可视化介绍2021-07-12 2911
-
plotly可视化绘制嵌入式子图的方法2021-12-14 1574
-
Keras可视化神经网络架构的4种方法2022-11-02 3118
-
经验分享|BI数据可视化报表布局——容器2023-03-15 4487
-
电子家谱的元图可视化2017-11-28 1064
-
CNN的三种可视化方法介绍2020-12-29 3347
-
3种CNN的可视化方法2021-01-07 2660
-
可视化CNN和特征图2023-04-19 2098
全部0条评论

快来发表一下你的评论吧 !
