

SpringBoot多数据源及事务解决方案
电子说
描述
1. 背景
一个主库和N个应用库的数据源,并且会同时操作主库和应用库的数据,需要解决以下两个问题:
- 如何动态管理多个数据源以及切换?
- 如何保证多数据源场景下的数据一致性(事务)?
本文主要探讨这两个问题的解决方案,希望能对读者有一定的启发。
基于 Spring Boot + MyBatis Plus + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/ruoyi-vue-pro
- 视频教程:https://doc.iocoder.cn/video/
2. 数据源切换原理
通过扩展Spring提供的抽象类AbstractRoutingDataSource,可以实现切换数据源。其类结构如下图所示:
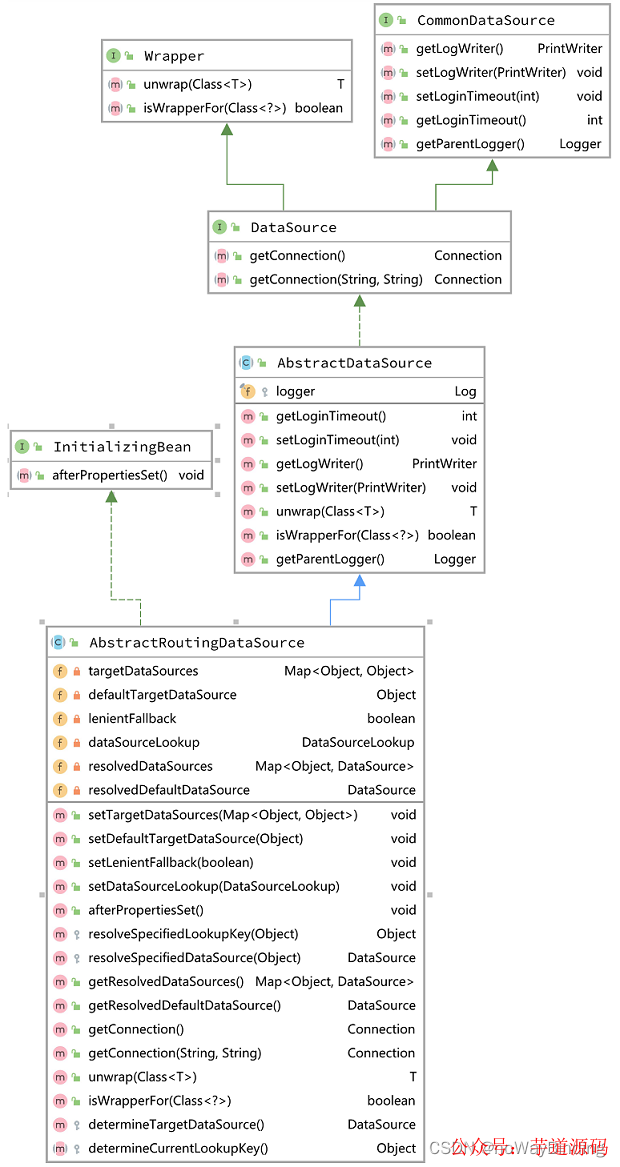
- targetDataSources&defaultTargetDataSource
项目上需要使用的所有数据源和默认数据源。
- resolvedDataSources&resolvedDefaultDataSource
当Spring容器创建AbstractRoutingDataSource对象时,通过调用afterPropertiesSet复制上述目标数据源。由此可见,一旦数据源实例对象创建完毕,业务无法再添加新的数据源。
- determineCurrentLookupKey
此方法为抽象方法,通过扩展这个方法来实现数据源的切换。目标数据源的结构为:Map其key为lookup key。
我们来看官方对这个方法的注释:

lookup key通常是绑定在线程上下文中,根据这个key去resolvedDataSources中取出DataSource。
根据目标数据源的管理方式不同,可以使用基于配置文件和数据库表两种方式。基于配置文件管理方案无法后续添加新的数据源,而基于数据库表方案管理,则更加灵活。
基于 Spring Cloud Alibaba + Gateway + Nacos + RocketMQ + Vue & Element 实现的后台管理系统 + 用户小程序,支持 RBAC 动态权限、多租户、数据权限、工作流、三方登录、支付、短信、商城等功能
- 项目地址:https://github.com/YunaiV/yudao-cloud
- 视频教程:https://doc.iocoder.cn/video/
3. 配置文件解决方案
根据上面的分析,我们可以按照下面的步骤去实现:
-
定义
DynamicDataSource类继承AbstractRoutingDataSource,重写determineCurrentLookupKey()方法。 -
配置多个数据源注入
targetDataSources和defaultTargetDataSource,通过afterPropertiesSet()方法将数据源写入resolvedDataSources和resolvedDefaultDataSource。 -
调用
AbstractRoutingDataSource的getConnection()方法时,determineTargetDataSource()方法返回DataSource执行底层的getConnection()。
其流程如下图所示:
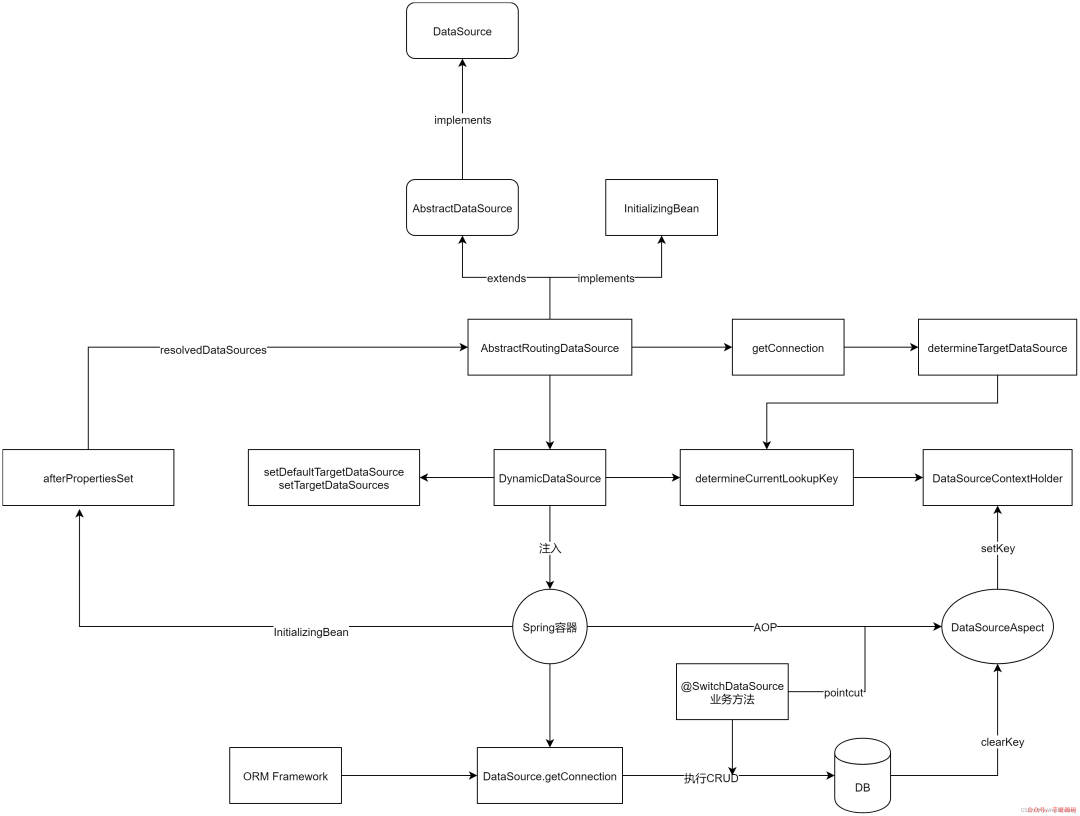
3.1 创建数据源
DynamicDataSource数据源的注入,目前业界主流实现步骤如下:
在配置文件中定义数据源
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driverClassName=com.mysql.jdbc.Driver
# 主数据源
spring.datasource.druid.master.url=jdbcUrl
spring.datasource.druid.master.username=***
spring.datasource.druid.master.password=***
# 其他数据源
spring.datasource.druid.second.url=jdbcUrl
spring.datasource.druid.second.username=***
spring.datasource.druid.second.password=***
在代码中配置Bean
@Configuration
public class DynamicDataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.master")
public DataSource firstDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.second")
public DataSource secondDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@Primary
public DynamicDataSource dataSource(DataSource firstDataSource, DataSource secondDataSource) {
Map targetDataSources = new HashMap<>(5);
targetDataSources.put(DataSourceNames.FIRST, firstDataSource);
targetDataSources.put(DataSourceNames.SECOND, secondDataSource);
return new DynamicDataSource(firstDataSource, targetDataSources);
}
}
3.2 AOP处理
通过DataSourceAspect切面技术来简化业务上的使用,只需要在业务方法添加@SwitchDataSource注解即可完成动态切换:
@Documented
@Retention(RetentionPolicy.RUNTIME)
@Target({ElementType.METHOD})
public @interface SwitchDataSource {
String value();
}
DataSourceAspect拦截业务方法,更新当前线程上下文DataSourceContextHolder中存储的key,即可实现数据源切换。
3.3 方案不足
基于AbstractRoutingDataSource的多数据源动态切换,有个明显的缺点,无法动态添加和删除数据源。在我们的产品中,不能把应用数据源写死在配置文件。接下来分享一下基于数据库表的实现方案。
4. 数据库表解决方案
我们需要实现可视化的数据源管理,并实时查看数据源的运行状态。所以我们不能把数据源全部配置在文件中,应该将数据源定义保存到数据库表。参考AbstractRoutingDataSource的设计思路,实现自定义数据源管理。
4.1 设计数据源表
主库的数据源信息仍然配置在项目配置文件中,应用库数据源配置参数,则设计对应的数据表。表结构如下所示:

这个表主要就是DataSource的相关配置参数,其相应的ORM操作代码在此不再赘述,主要是实现数据源的增删改查操作。
4.2 自定义数据源管理
4.2.1 定义管理接口
通过继承AbstractDataSource即可实现DynamicDataSource。为了方便对数据源进行操作,我们定义一个接口DataSourceManager,为业务提供操作数据源的统一接口。
public interface DataSourceManager {
void put(String var1, DataSource var2);
DataSource get(String var1);
Boolean hasDataSource(String var1);
void remove(String var1);
void closeDataSource(String var1);
Collection all() ;
}
该接口主要是对数据表中定义的数据源,提供基础管理功能。
4.2.2 自定义数据源
DynamicDataSource的实现如下图所示:
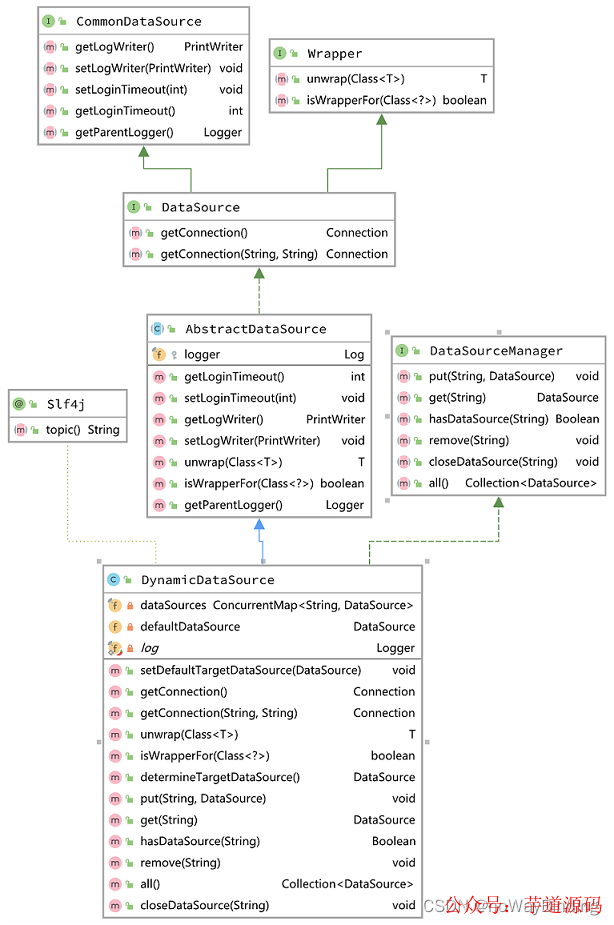
根据前面的分析,AbstractRoutingDataSource是在容器启动的时候,执行afterPropertiesSet注入数据源对象,完成之后无法对数据源进行修改。DynamicDataSource则实现DataSourceManager接口,可以将数据表中的数据源加载到dataSources。
4.2.3 切面处理
这一块的处理跟配置文件数据源方案处理方式相同,都是通过AOP技术切换lookup key。
public DataSource determineTargetDataSource() {
String lookupKey = DataSourceContextHolder.getKey();
DataSource dataSource = Optional.ofNullable(lookupKey)
.map(dataSources::get)
.orElse(defaultDataSource);
if (dataSource == null) {
throw new IllegalStateException("Cannot determine DataSource for lookup key [" + lookupKey + "]");
}
return dataSource;
}
4.2.4 管理数据源状态
在项目启动的时候,加载数据表中的所有数据源,并执行初始化。初始化操作主要是使用SpringBoot提供的DataSourceBuilder类,根据数据源表的定义创建DataSource。在项目运行过程中,可以使用定时任务对数据源进行保活,为了提升性能再添加一层缓存。
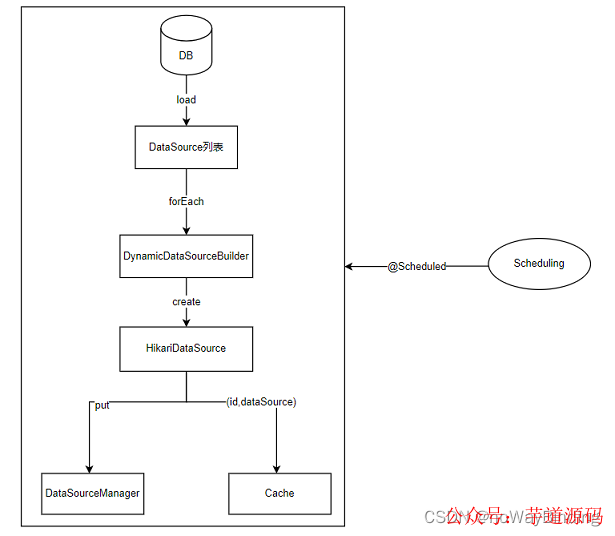
AbstractRoutingDataSource 只支持单库事务,切换数据源是在开启事务之前执行。 Spring使用 DataSourceTransactionManager进行事务管理。开启事务,会将数据源缓存到DataSourceTransactionObject对象中,后续的commit和 rollback事务操作实际上是使用的同一个数据源。
如何解决切库事务问题?借助Spring的声明式事务处理,我们可以在多次切库操作时强制开启新的事务:
@SwitchDataSource
@Transactional(rollbackFor = Exception.class, propagation = Propagation.REQUIRES_NEW)
这样的话,执行切库操作的时候强制启动新事务,便可实现多次切库而且事务能够生效。但是这种事务方式,存在数据一致性问题:
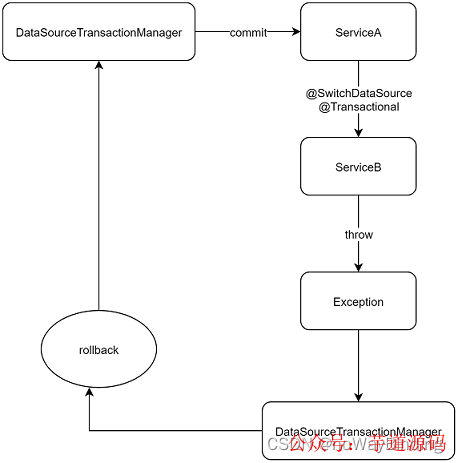
假若ServiceB正常执行提交事务,接着返回ServiceA执行并且发生异常。因为两次处理是不同的事务,ServiceA这个事务执行回滚,而ServiceA事务已经提交。这样的话,数据就不一致了。接下来,我们主要讨论如何解决多库的事务问题。
6. 多库事务处理
6.1 关于事务的理解
首先有必要理解事务的本质。
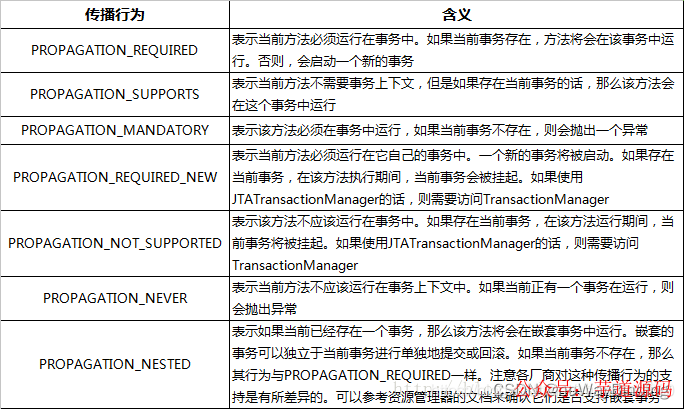
1.提到Spring事务,就离不开事务的四大特性和隔离级别、七大传播特性。
事务特性和离级别是属于数据库范畴。Spring事务的七大传播特性是什么呢?它是Spring在当前线程内,处理多个事务操作时的事务应用策略,数据库事务本身并不存在传播特性。
2.Spring事务的定义包括:begin、commit、rollback、close、suspend、resume等动作。
-
begin(事务开始): 可以认为存在于数据库的命令中,比如Mysql的
start transaction命令,但是在JDBC编程方式中不存在。 -
close(事务关闭): Spring事务的close()方法,是把
Connection对象归还给数据库连接池,与事务无关。 -
suspend(事务挂起): Spring中事务挂起的语义是:需要新事务时,将现有的
Connection保存起来(还有尚未提交的事务),然后创建新的Connection2,Connection2提交、回滚、关闭完毕后,再把Connection1取出来继续执行。 - resume(事务恢复): 嵌套事务执行完毕,返回上层事务重新绑定连接对象到事务管理器的过程。
实际上,只有commit、rollback、close是在JDBC真实存在的,而其他动作都是应用的语意,而非JDBC事务的真实命令。因此,事务真实存在的方法是:setAutoCommit()、commit()、rollback()。
close()语义为:
- 关闭一个数据库连接,这已经不再是事务的方法了。
使用DataSource并不会执行物理关闭,只是归还给连接池。
6.2 自定义管理事务
为了保证在多个数据源中事务的一致性,我们可以手动管理Connetion的事务提交和回滚。考虑到不同ORM框架的事务管理实现差异,要求实现自定义事务管理不影响框架层的事务。
这可以通过使用装饰器设计模式,对Connection进行包装重写commit和rolllback屏蔽其默认行为,这样就不会影响到原生Connection和ORM框架的默认事务行为。其整体思路如下图所示:
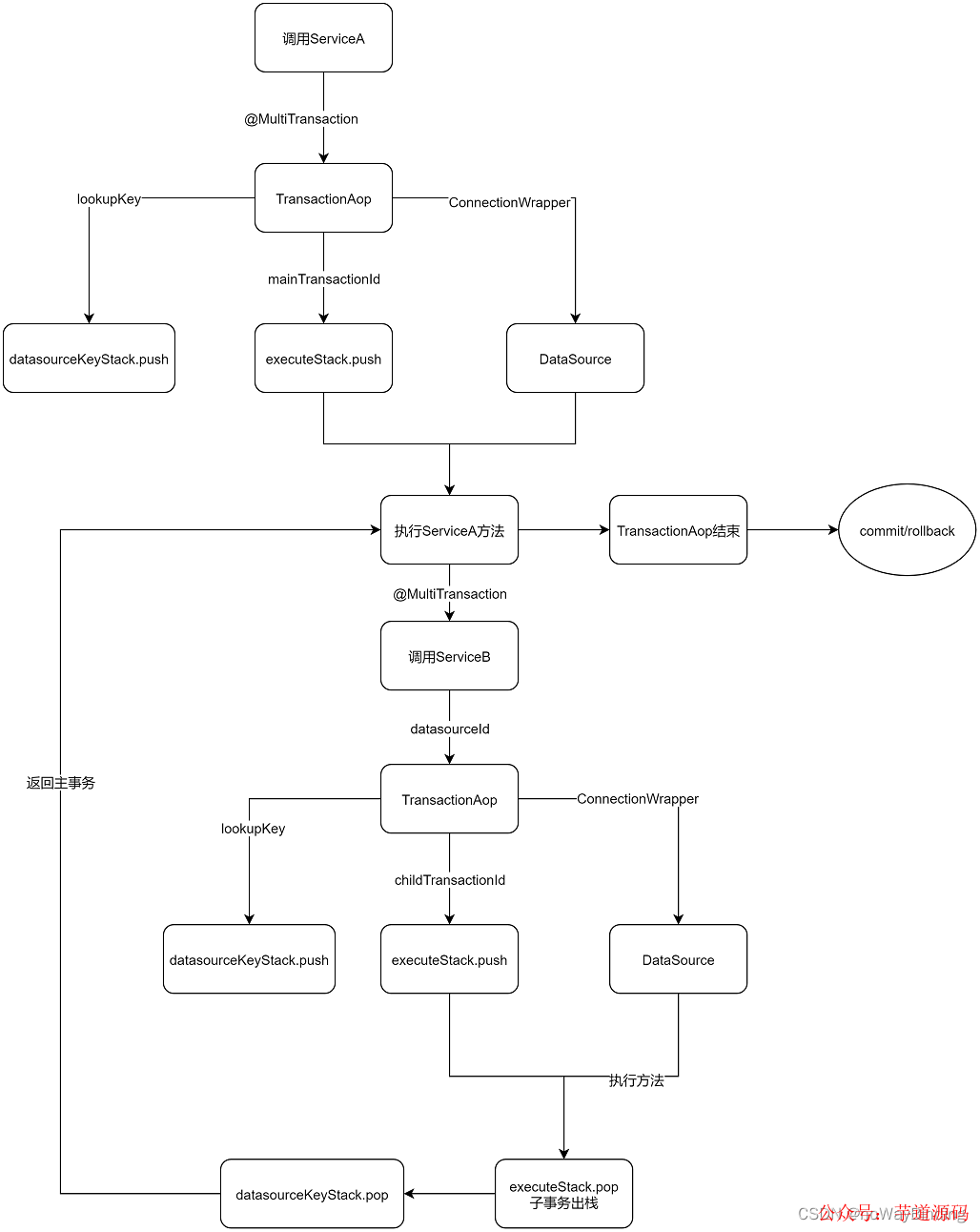
这里并没有使用前面提到的@SwitchDataSource,这是因为我们在TransactionAop中已经执行了lookupKey的切换。
6.2.1 定义多事务注解
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface MultiTransaction {
String transactionManager() default "multiTransactionManager";
// 默认数据隔离级别,随数据库本身默认值
IsolationLevel isolationLevel() default IsolationLevel.DEFAULT;
// 默认为主库数据源
String datasourceId() default "default";
// 只读事务,若有更新操作会抛出异常
boolean readOnly() default false;
业务方法只需使用该注解即可开启事务,datasourceId指定事务用到的数据源,不指定默认为主库。
6.2.3 包装Connection
自定义事务我们使用包装过的Connection,屏蔽其中的commit&rollback方法。这样我们就可以在主事务里进行统一的事务提交和回滚操作。
public class ConnectionProxy implements Connection {
private final Connection connection;
public ConnectionProxy(Connection connection) {
this.connection = connection;
}
@Override
public void commit() throws SQLException {
// connection.commit();
}
public void realCommit() throws SQLException {
connection.commit();
}
@Override
public void close() throws SQLException {
//connection.close();
}
public void realClose() throws SQLException {
if (!connection.getAutoCommit()) {
connection.setAutoCommit(true);
}
connection.close();
}
@Override
public void rollback() throws SQLException {
if(!connection.isClosed())
connection.rollback();
}
...
}
这里commit&close方法不执行操作,rollback执行的前提是连接执行close才生效。这样不管是使用哪个ORM框架,其自身事务管理都将失效。事务的控制就交由MultiTransaction控制了。
6.2.4 事务上下文管理
public class TransactionHolder {
// 是否开启了一个MultiTransaction
private boolean isOpen;
// 是否只读事务
private boolean readOnly;
// 事务隔离级别
private IsolationLevel isolationLevel;
// 维护当前线程事务ID和连接关系
private ConcurrentHashMap connectionMap;
// 事务执行栈
private Stack executeStack;
// 数据源切换栈
private Stack datasourceKeyStack;
// 主事务ID
private String mainTransactionId;
// 执行次数
private AtomicInteger transCount;
// 事务和数据源key关系
private ConcurrentHashMap executeIdDatasourceKeyMap;
}
每开启一个事物,生成一个事务ID并绑定一个ConnectionProxy。事务嵌套调用,保存事务ID和lookupKey至栈中,当内层事务执行完毕执行pop。这样的话,外层事务只需在栈中执行peek即可获取事务ID和lookupKey。
6.2.5 数据源兼容处理
为了不影响原生事务的使用,需要重写getConnection方法。当前线程没有启动自定义事务,则直接从数据源中返回连接。
@Override
public Connection getConnection() throws SQLException {
TransactionHolder transactionHolder = MultiTransactionManager.TRANSACTION_HOLDER_THREAD_LOCAL.get();
if (Objects.isNull(transactionHolder)) {
return determineTargetDataSource().getConnection();
}
ConnectionProxy ConnectionProxy = transactionHolder.getConnectionMap()
.get(transactionHolder.getExecuteStack().peek());
if (ConnectionProxy == null) {
// 没开跨库事务,直接返回
return determineTargetDataSource().getConnection();
} else {
transactionHolder.addCount();
// 开了跨库事务,从当前线程中拿包装过的Connection
return ConnectionProxy;
}
}
6.2.6 切面处理
切面处理的核心逻辑是:维护一个嵌套事务栈,当业务方法执行结束,或者发生异常时,判断当前栈顶事务ID是否为主事务ID。如果是的话这时候已经到了最外层事务,这时才执行提交和回滚。详细流程如下图所示:
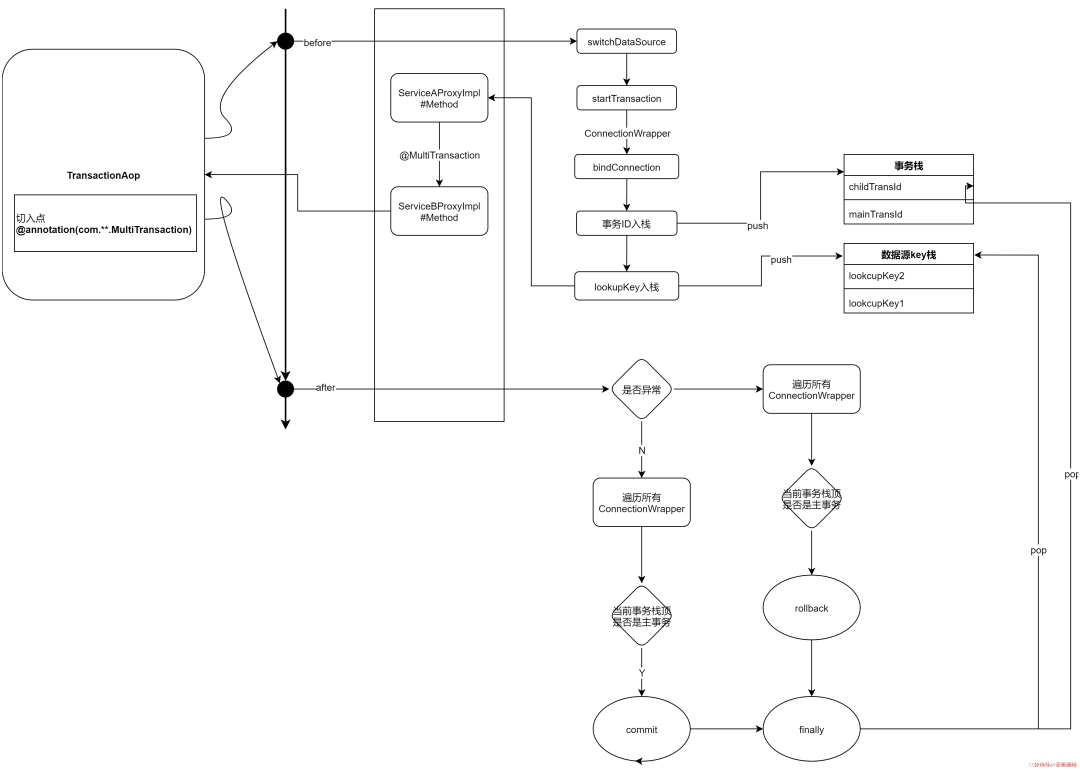
package com.github.mtxn.transaction.aop;
import com.github.mtxn.application.Application;
import com.github.mtxn.transaction.MultiTransactionManager;
import com.github.mtxn.transaction.annotation.MultiTransaction;
import com.github.mtxn.transaction.context.DataSourceContextHolder;
import com.github.mtxn.transaction.support.IsolationLevel;
import com.github.mtxn.transaction.support.TransactionHolder;
import com.github.mtxn.utils.ExceptionUtils;
import lombok.extern.slf4j.Slf4j;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
@Aspect
@Component
@Slf4j
@Order(99999)
public class MultiTransactionAop {
@Pointcut("@annotation(com.github.mtxn.transaction.annotation.MultiTransaction)")
public void pointcut() {
if (log.isDebugEnabled()) {
log.debug("start in transaction pointcut...");
}
}
@Around("pointcut()")
public Object aroundTransaction(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
// 从切面中获取当前方法
Method method = signature.getMethod();
MultiTransaction multiTransaction = method.getAnnotation(MultiTransaction.class);
if (multiTransaction == null) {
return point.proceed();
}
IsolationLevel isolationLevel = multiTransaction.isolationLevel();
boolean readOnly = multiTransaction.readOnly();
String prevKey = DataSourceContextHolder.getKey();
MultiTransactionManager multiTransactionManager = Application.resolve(multiTransaction.transactionManager());
// 切数据源,如果失败使用默认库
if (multiTransactionManager.switchDataSource(point, signature, multiTransaction)) return point.proceed();
// 开启事务栈
TransactionHolder transactionHolder = multiTransactionManager.startTransaction(prevKey, isolationLevel, readOnly, multiTransactionManager);
Object proceed;
try {
proceed = point.proceed();
multiTransactionManager.commit();
} catch (Throwable ex) {
log.error("execute method:{}#{},err:", method.getDeclaringClass(), method.getName(), ex);
multiTransactionManager.rollback();
throw ExceptionUtils.api(ex, "系统异常:%s", ex.getMessage());
} finally {
// 当前事务结束出栈
String transId = multiTransactionManager.getTrans().getExecuteStack().pop();
transactionHolder.getDatasourceKeyStack().pop();
// 恢复上一层事务
DataSourceContextHolder.setKey(transactionHolder.getDatasourceKeyStack().peek());
// 最后回到主事务,关闭此次事务
multiTransactionManager.close(transId);
}
return proceed;
}
}
7.总结
本文主要介绍了多数据源管理的解决方案(应用层事务,而非XA二段提交保证),以及对多个库同时操作的事务管理。
需要注意的是,这种方式只适用于单体架构的应用。因为多个库的事务参与者都是运行在同一个JVM进行。如果是在微服务架构的应用中,则需要使用分布式事务管理(譬如:Seata)。
审核编辑 :李倩
- 相关推荐
- 热点推荐
- spring
- 数据源
- 微服务
- SpringBoot
-
Mybatis 拦截器实现单数据源内多数据库切换2024-12-12 1938
-
LabView动态创建数据源的方法2012-09-23 25180
-
ODBC数据源的建立2016-04-21 3972
-
SpringBoot中的Druid介绍2019-05-07 2937
-
SpringBoot项目多数据源配置数据库2020-06-05 1359
-
数据源配置工具2010-07-01 929
-
基于元组水平对数据源进行分层抽样2017-12-29 1133
-
基于LDA主题模型进行数据源选择方法2018-01-04 1253
-
Deep Web数据源选择和集成方法2018-02-09 1144
-
数据仓库入门之创建数据源2018-02-24 2921
-
Veritas收购Globanet,新功能将允许用户获得和使用更多数据源2020-11-12 2213
-
SpringBoot分布式事务的解决方案(JTA+Atomic+多数据源)2022-04-11 2822
-
多数据源数据转换和同步的ETL工具推荐2023-07-28 2057
-
weblogic修改数据源需要重启吗2023-12-05 2815
-
SpringBoot实现动态切换数据源2023-12-08 2013
全部0条评论

快来发表一下你的评论吧 !
