

阅读开源项目源码的实用技巧(下)
电子说
描述
技巧二、多猜,多搜索,可以在底层库(标准库、网络框架等)打条件断点过筛选出关键流程 。
这句话其实是高效 debug 的关键。初看源码时「猜」是很重要且很有效的手段,结合 IDE 的搜索功能,能够帮我们快速定位关键代码。
为什么底层库适合打断点呢?因为出看大项目的代码很难搞清楚其中的细节,加上各种异步、多线程的操作,很容易把代码「跟丢」。如果把断点打在底层库的接口/方法上,就可以根据调用栈分析调用过程。
当然,底层库被调用的次数比较多,可能出现很多无关的调用,所以要结合条件断点来过滤掉无关的调用。
还是用 Pulsar 举例,我现在想探究 producer 发送消息的流程,那么 producer 和 broker 之间的网络通信过程就是一个重要的切入点。
首先发现 Pulsar 的网络协议使用的是 protobuf,而且注意到PulsarApi.proto这个文件中有一个BaseCommand定义:
message BaseCommand {
enum Type {
CONNECT = 2;
SUBSCRIBE = 4;
PRODUCER = 5;
SEND = 6;
SEND_RECEIPT= 7;
MESSAGE = 9;
ACK = 10;
PING = 18;
PONG = 19;
...
}
required Type type = 1;
optional CommandConnect connect = 2;
optional CommandConnected connected = 3;
...
}
又发现 Pulsar 底层靠 netty 框架实现网络通信,那么我们可以大胆猜测, 源码里肯定有一个大 switch 语句 ,来根据 command 里面的 type 分类处理对应的 command。
所以我们可以全局搜索一下case SEND_RECEIPT ,就找到了PulsarDecoder这个文件:
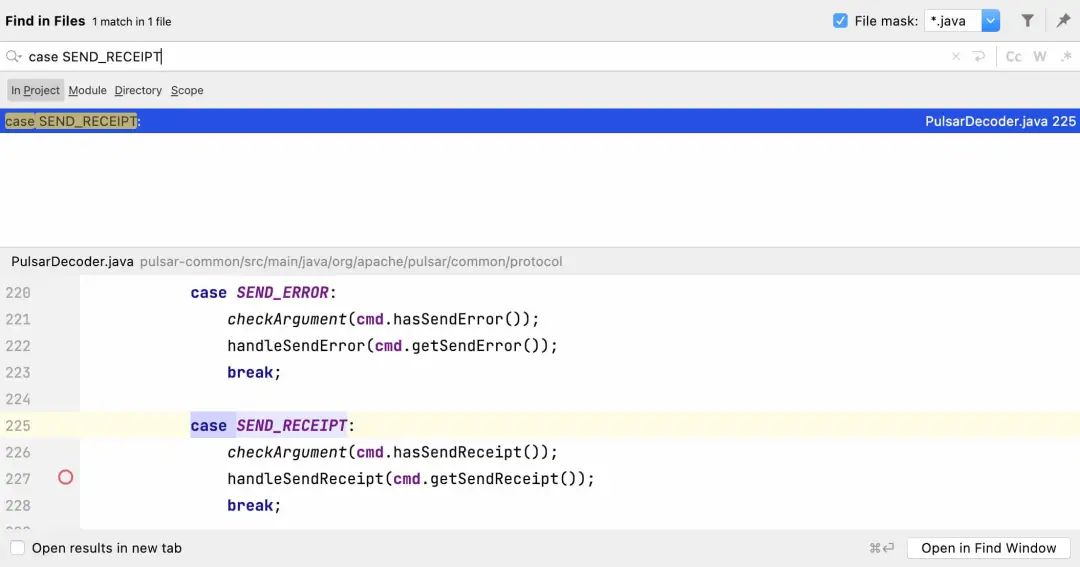
这里会根据不同的 command type 调用不同的 handle 函数,所以可以认为这里是 Pulsar 关键功能的入口。
而且注意这是 common 包,也就是说 client 和 broker 都会依赖这个包, 所以断点打在 switch 这里就可以看到 client 和 broker 的网络交互 ,每次跳转的 case 就是网络命令的交互顺序:

PS:因为 ping/pong 心跳消息在调试时很烦人,所以我们可以通过条件断点跳过心跳消息。另外,我们需要把 client 里面的各种 timeout 都调大一些,避免调试时出现超时的错误。
这样,启动我们的测试用例,仅仅通过这一个断点,就能搞明白 Pulsar 发消息的流程了:
当然,如果你想探究每一步具体做了什么,就跳进具体的 handle 函数里一步步调试即可。
技巧三、利用各种可视化工具 。
你比如,上面说的网络通信过程,我们知道了 produce 一条消息的流程,但每条 protobuf 数据包里面到底存了什么信息呢?
关于这个问题,社区有大佬写了一个 lua 脚本, 可以用 wireshark 解析 Pulsar 协议格式 ,具体说明在这里:
https://github.com/apache/pulsar/tree/master/wireshark
按照说明配置并启动 wireshark 之后,可以使用如下过滤命令过滤掉无关的数据包:
tcp.port eq 6650 and pulsar and protobuf.field.name ne "ping" and protobuf.field.name ne "pong"
接下来启动 standalone,通过 Java client 发送一条消息,就可以在 wireshark 抓到 10 个数据包,和刚才通过 debug 得到的流程是一样的:
同时,我们还可以查看每个包的具体数据,比如PARTITITONED_METADATA命令就是在查询 topic 对应的 partition 有多少,因为这里是个非分区的 topic,所以PARTITITONED_METADATA_RESPONSE返回了 0:
再比如LOOKUP命令用来查询 broker 的 URL,因为我们启动的 standalone 只有一个 broker,所以LOOKUP_RESPONSE返回的只有一个 URL:
在真实的使用场景中肯定有多个 broker,所以这个LOOKUP_RESPONSE应该会返回多个 broker URL。
最后看一下真正发送消息的SEND命令里面具体有什么数据:
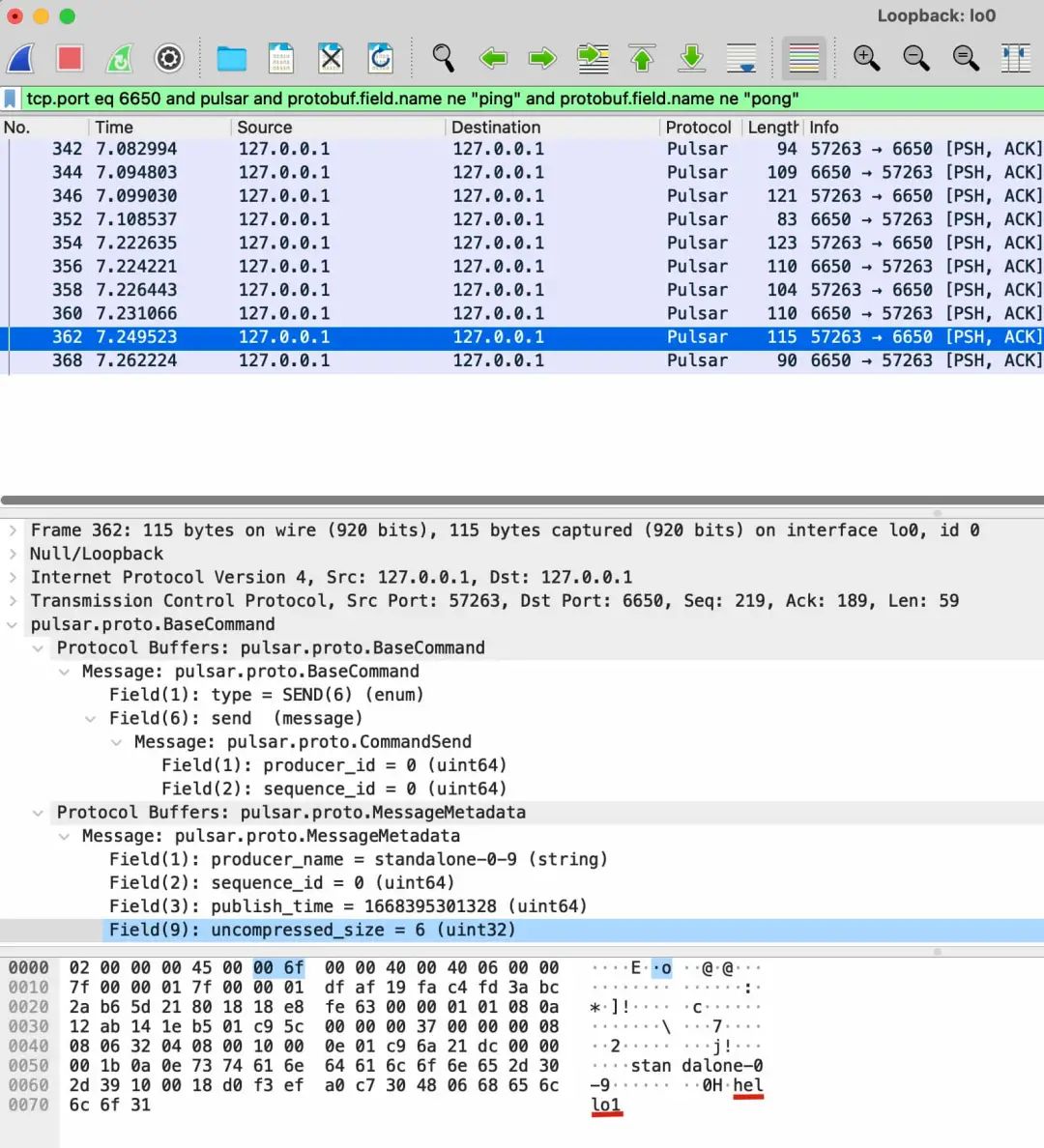
可以看到这里面有 producer_name, sequence_id 等数据,每条消息的 sequence_id 单调递增,用来防止由于网络重传导致的消息重复,和 tcp 里面的 seq 差不多的原理。
另外可以看到真正的消息数据放在数据包的最后,通过一个字段记录数据的长度。
具体的玩法可以有很多,我这里就不一一列举了,其实除了 wireshark 分析 Pulsar 的网络通信, 还可以使用 zookeeper 的可视化工具查看 Pulsar 的元数据 。
比如 prettyZoo 就是一款对 zookeeper 可视化的开源工具,那么我就可以在 Pulsar standalone 启动之后(会自动启动 zookeeper),让 prettyZoo 连接到 zookeeper 的端口,很直观地查看 zookeeper 里面的节点数据:
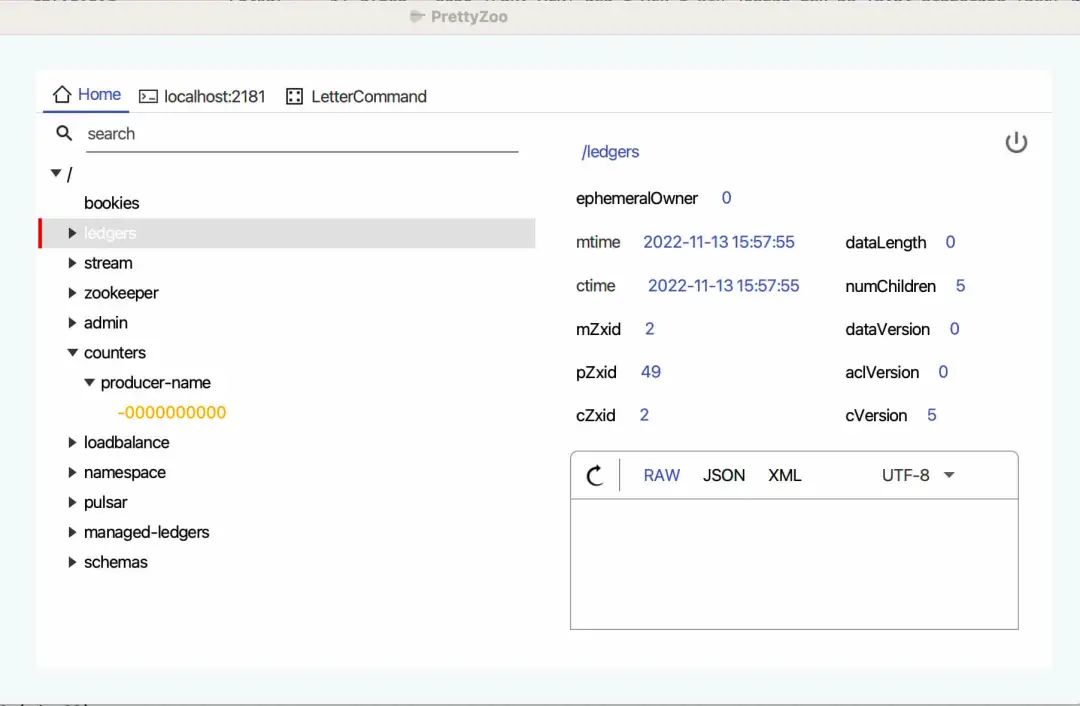
这里面很多数据可能不好理解,但我们手上有源码, 这些路径大概率是以字符串常量的形式表现的,那全局搜索就行了 。
比如这个producer-name的路径,我们搜一下就定位出来了:
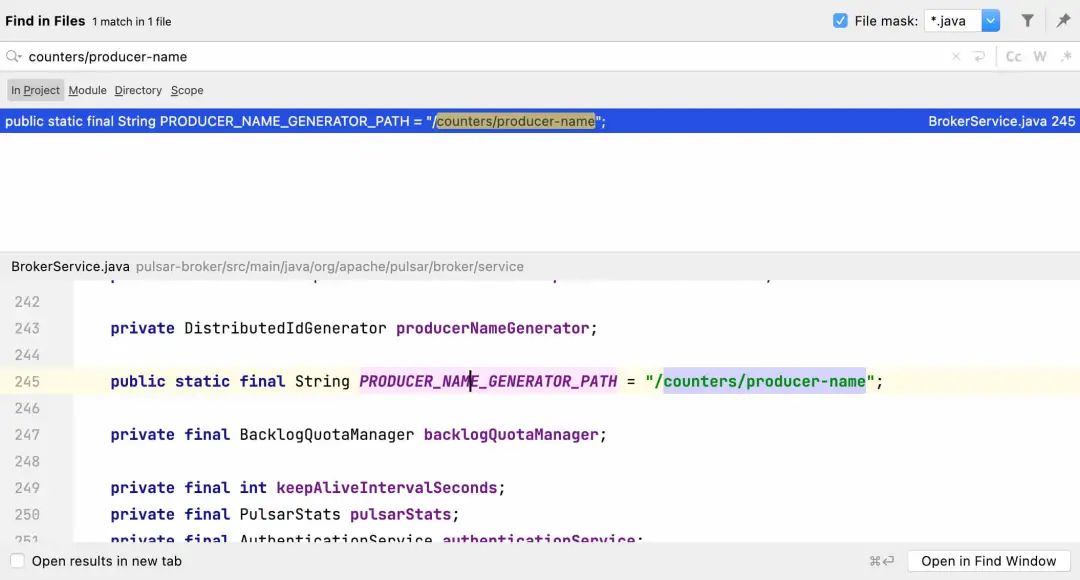
简单浏览一下源码,原来是借助 zookeeper 生成全局唯一的生产者名字。
最后
本文也够长了,主要介绍了一些阅读开源项目源码的实用技巧,总结来说就是: 善于找资源,善于用工具 。
虽然本文是以 Pulsar 为例,但这些技巧都是通用的,可以运用到任何比较成熟的开源项目上去。
如果你也有什么经验分享,可以留言告诉我,掌握技巧只是漫漫长路的第一步,让我们共同在开源社区里成长进步。
-
Matepad pro12.2 已上市半个月,但是还没有在开源网站看到该项目的开源信息,违背开源精神2024-08-27 341
-
关于Linux下的源代码阅读问题2017-11-21 2869
-
【HiSpark系列】润和 HiHope 社区 开源项目集合2020-10-22 1437
-
C语言开源项目2021-08-20 1151
-
下载编译源码的要点和搭建源码阅读环境的方法2022-01-10 1393
-
STM32项目开发中超级实用技巧分享2022-01-21 1349
-
分享一个超级实用的源码阅读小技巧2021-05-29 2831
-
优秀的 Verilog/FPGA开源项目介绍(一)2021-10-11 11623
-
模拟阅读器开源分享2022-11-14 833
-
矩阵显示器上的新闻阅读器开源项目2023-02-08 978
-
阅读开源项目源码的实用技巧(上)2023-04-12 2142
-
Java算法大全源码包开源源码2023-06-07 622
-
Haiku eInk阅读器开源分享2023-06-15 716
-
如何去阅读源码,我总结了18条心法2023-07-17 1508
-
浙大博导开源飞控planner源码2024-06-12 624
全部0条评论

快来发表一下你的评论吧 !
