

AI算力发展如何解决内存墙和功耗墙问题
人工智能
描述
目前 AI 大模型的算力水平显著供不应求。以 Open AI 的算力基础设施为例,芯片层面 GPGPU 的需求最为直接受益,其次是 CPU、AI 推理芯片、FPGA 等。AI 服务器市场的扩容,同步带动高速网卡、HBM、DRAM、NAND、PCB 等需求提升。同时,围绕解决大算力场景下 GPU“功耗墙、内存墙”问题的相关技术不断升级,如存算一体、硅光/CPO 产业化进程有望提速。
1.“内存墙”、“功耗墙”等掣肘 AI 的算力发展
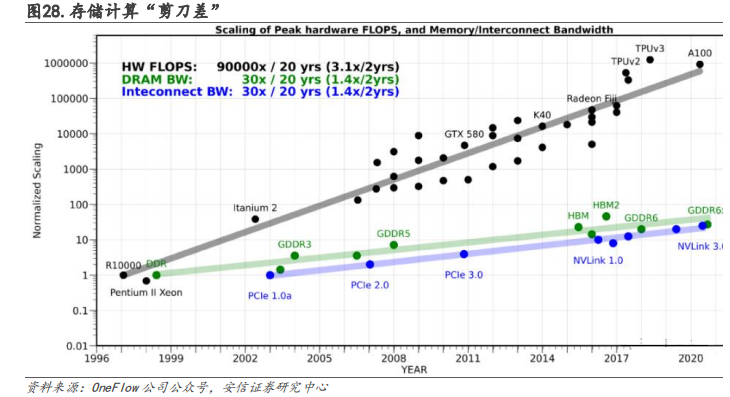
“存”“算”性能失配,内存墙导致访存时延高,效率低。内存墙,指内存的容量或传输带宽有限而严重限制 CPU 性能发挥的现象。内存的性能指标主要有“带宽”(Bandwidth)和“等待时间”(Latency)。近 20 年间,运算设备的算力提高了 90000 倍,提升非常快。虽然存储器从 DDR 发展到 GDDR6x,能够用于显卡、游戏终端和高性能运算,接口标准也从 PCIe1.0a 升级到 NVLink3.0,但是通讯带宽的增长只有 30 倍,和算力相比提高幅度非常缓慢。
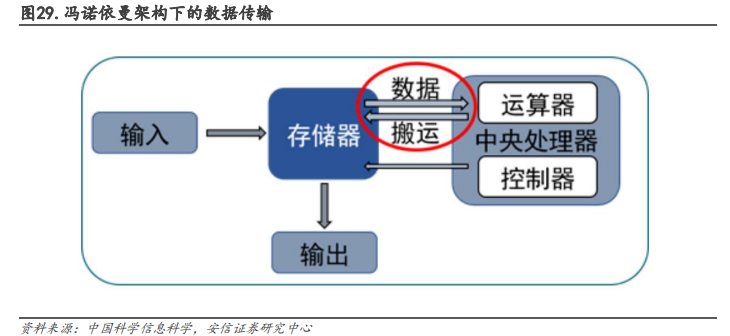
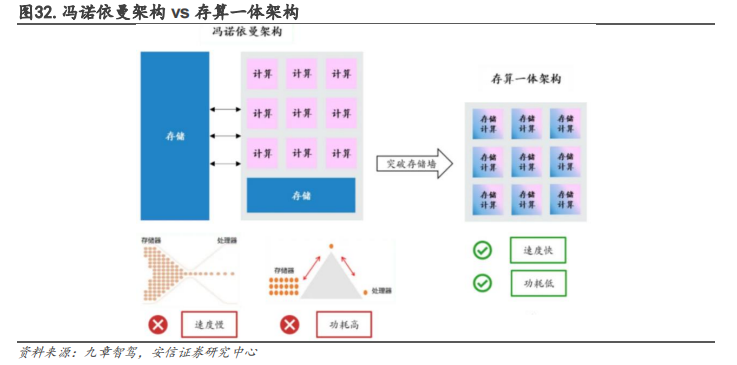
冯诺依曼架构下,数据传输导致严重的功耗损失。冯·诺依曼架构要求数据在存储器单元和处理单元之间不断地“读写”,这样数据在两者之间来回传输就会消耗很多的传输功耗。根据英特尔的研究表明,当半导体工艺达到 7nm 时,数据搬运功耗高达 35pJ/bit,占总功耗的63.7%。数据传输造成的功耗损失越来越严重,限制了芯片发展的速度和效率,形成了“功耗墙”问题。
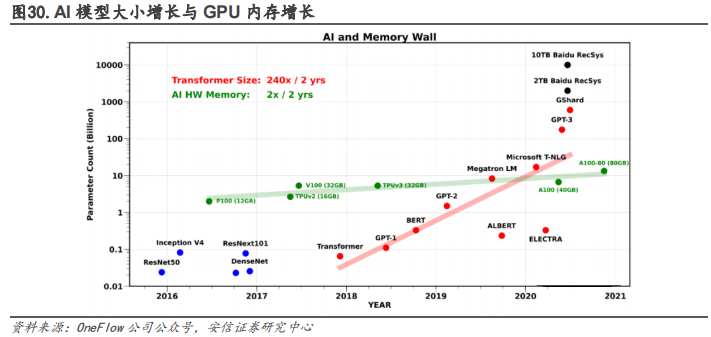
AI 模型参数量极速扩大,GPU 内存增长速度捉襟见肘。在 GPT-2 之前的模型时代,GPU 内存还能满足 AI 大模型的需求。近年来,随着 Transformer 模型的大规模发展和应用,模型大小每两年平均增长了 240 倍。GPT-3 等大模型的参数增长已经超过了 GPU 内存的增长。传统的设计趋势已经不适应当前的需求,芯片内部、芯片之间或 AI 加速器之间的通信成为了 AI训练的瓶颈。AI 训练不可避免地遇到了“内存墙”问题。
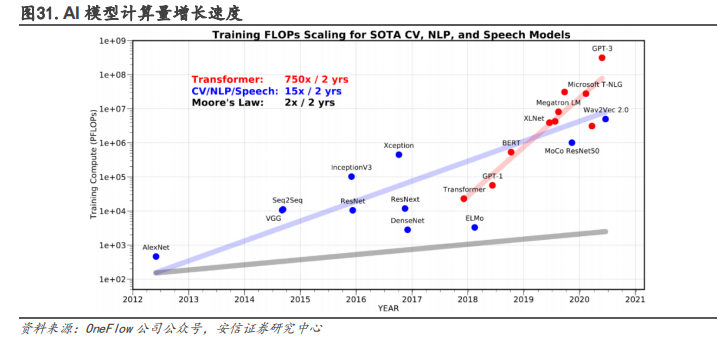
AI 模型运算量增长速度不断加快,推动硬件算力增长。预训练技术的进步导致了各领域模型计算量的快速增长,大约每两年就要增加 15 倍。而 Transformer 类模型的运算量更是每两年就要增加 750 倍。这种近乎指数的增长趋势促使 AI 硬件的研发方向发生变化,需要更高的峰值算力。
当前的研究为了实现更高的算力,甚至不惜简化或者优化其他部分组件,例如内存的分层架构,将 DRAM 容量用于需要高性能访问的热数据,将容量层用于处理需要大容量但性能要求不那么高的任务,以适应不同的数据类型、用例、技术需求和预算限制,适用于 AI、ML 和 HPC 等众多应用场景,能帮助企业以经济高效的方式满足内存需求。
2.“内存墙”、“功耗墙”等问题解决路径
2.2.1.存算一体技术:以 SRAM、RRAM 为主的新架构,大算力领域优势大存算一体在存储器中嵌入计算能力,以新的运算架构进行乘加运算。存算一体是一种以数据为中心的非冯诺依曼架构,它将存储功能和计算功能有机结合起来,直接在存储单元中处理数据。存算一体通过改造“读”电路的存内计算架构,可以直接从“读”电路中得到运算结果,并将结果“写”回存储器的目标地址,避免了在存储单元和计算单元之间频繁地转移数据。存算一体减少了不必要的数据搬移造成的开销,不仅大幅降低了功耗(降至 1/10~1/100),还可以利用存储单元进行逻辑计算提高算力,显著提升计算效率。它不仅适用于 AI 计算,也适用于感存算一体芯片和类脑芯片,是未来大数据计算芯片架构的主流方向。
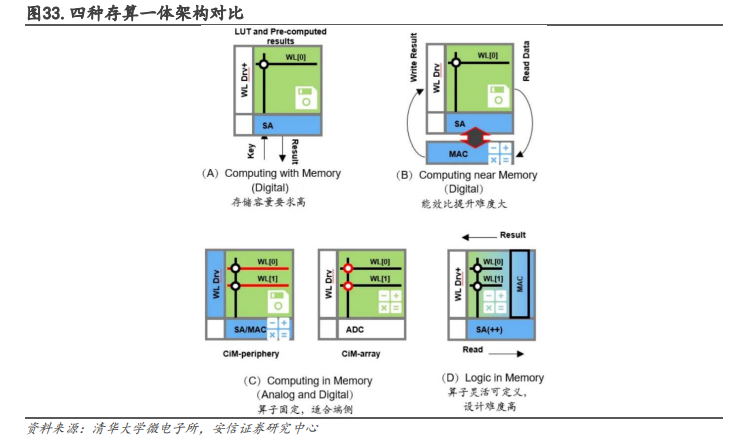
存算一体技术可分为查存计算、近存计算、存内计算和存内逻辑,提供多种方式解决内存墙问题。
查存计算:早期技术,在存储芯片内部查表来完成计算操作。
近存计算:早已成熟,计算操作由位于存储区域外部的独立计算芯片/模块完成。典型代表是 AMD 的 Zen 系列 CPU,以及封装 HBM 内存(包括三星的 HBM-PIM)与计算模组(裸Die)的芯片。
存内计算:计算操作由位于存储芯片/区域内部的独立计算单元完成,存储和计算可以是模拟或数字的。典型代表是 Mythic、千芯科技、闪亿、知存、九天睿芯等。
存内逻辑:通过在内部存储中添加计算逻辑,直接在内部存储执行数据计算。典型代表包括 TSMC(在 2021 ISSCC 发表论文)和千芯科技。
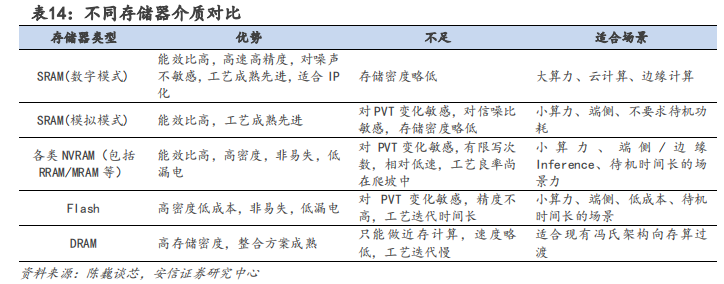
SRAM、RRAM 是存算一体介质的主流研究方向。存算一体的成熟存储器有几种,比如 NOR FLASH、SRAM、DRAM、RRAM、MRAM 等 NVRAM。
FLASH 是非易失性存储,成本低,可靠性高,但制程有瓶颈。
SRAM 速度快,能效比高,在存内逻辑技术发展后有高能效和高精度的特点。
DRAM 容量大,成本低,但速度慢,需要不断刷新电力。
新型存储器 PCAM、MRAM、RRAM 和 FRAM 也适用于存算一体。其中 RRAM 在神经网络计算中有优势,是下一代存算一体介质的主流方向之一。除了 SRAM 之外,RRAM 也是未来发展最快的新型存储器之一,它结构简单,速度高,但材料不稳定,工艺还需 2-5 年才能成熟。
存算一体有着广泛的应用场景,在不同大小设备上均有需求。
从技术领域来看,存算一体可以应用于:
(1)AI 和大数据计算:将 AI 计算中大量乘加计算的权重部分存在存储单元中,从而在读取的同时进行数据输入和计算处理,在存储阵列中完成卷积运算。
(2)感存算一体:集传感、储存和运算为一体构建感存算一体架构,在传感器自身包含的 AI存算一体芯片上运算,来实现零延时和超低功耗的智能视觉处理能力。
(3)类脑计算:使计算机像人脑一样将存储和计算合二为一,从而高速处理信息。存算一体天然是将存储和计算结合在一起的技术,是未来类脑计算的首选和产品快速落地的关键。
从应用场景来分,存算一体可以适用于各类人工智能场景和元宇宙计算,如可穿戴设备、移动终端、智能驾驶、数据中心等。
(1)针对端侧的可穿戴等小设备,对成本、功耗、时延难度很敏感。端侧竞品众多,应用场景碎片化,面临成本与功效的难题。存算一体技术在端侧的竞争力影响约占 30%。(例如 arm占 30%,降噪或 ISP 占 40%,AI 加速能力只占 30%)
(2)针对云计算和边缘计算的大算力设备,是存算一体芯片的优势领域。存算一体在大算力领域的竞争力影响约占 90%。
传统存储大厂纷纷入局,新兴公司不断涌现。
(1)国外方面,三星电子在多个技术路线进行尝试,发布新型 HBM-PIM(存内计算)芯片、全球首个基于 MRAM(磁性随机存储器)的存内计算研究等。台积电在 ISSCC 2021 上提出基于数字改良的 SRAM 设计存内计算方案。英特尔也早早提出近内存计算战略,将数据在存储层级向上移动,使其更接近处理单元进行计算。
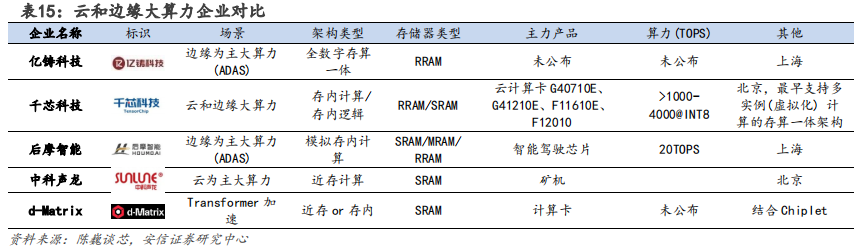
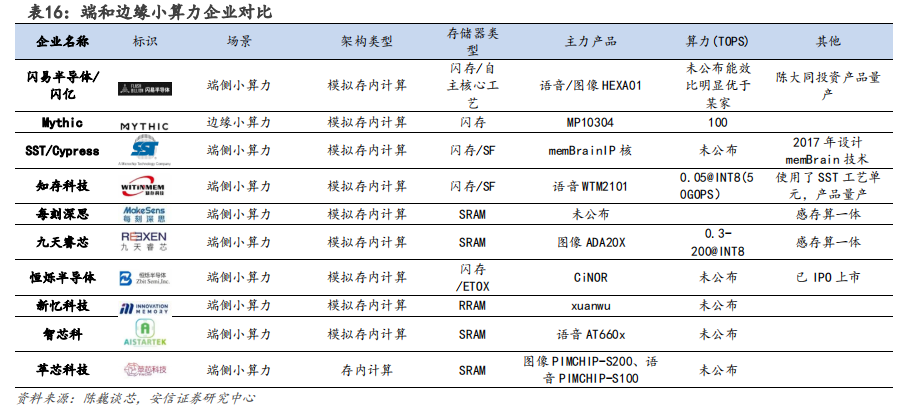
(2)国内方面,阿里达摩院成功研发全球首款基于 DRAM 的 3D 键合堆叠存算一体芯片,可突破冯·诺依曼架构的性能瓶颈。千芯科技是可重构存算一体 AI 芯片的领导者和先驱,核心产品包括高算力低功耗的存算一体 AI 芯片/IP 核(支持多领域多模态人工智能算法)。
编辑:黄飞
-
边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值2026-03-10 770
-
应对端侧AI算力、内存、功耗“三堵墙”困境,安谋科技Arm China “周易”X3给出技术锦囊2025-12-18 531
-
硅芯科技:AI算力突破,新型堆叠EDA工具持续进化2025-10-31 12912
-
大模型遭遇算力墙,探索超级应用的发展路径2025-02-10 1713
-
大算力时代, 如何打破内存墙2024-03-06 962
-
亿铸存算一体AI大算力芯片:存算一体架构2022-11-24 2772
-
ReRAM存算一体AI大算力芯片的独特优势2022-06-20 9477
-
有效解决内存墙问题 存算一体正处在快速发展阶段2021-10-26 6987
-
如何知道真正的CPU功耗 功率墙问题怎么解决2020-08-26 45155
全部0条评论

快来发表一下你的评论吧 !
