

什么是贝叶斯定理 实例详解贝叶斯推理的原理
电子说
描述
实例详解贝叶斯推理的原理
贝叶斯推理是一种精确的数据预测方式。在数据没有期望的那么多,但却想毫无遗漏地,全面地获取预测信息时非常有用。 提及贝叶斯推理时,人们时常会带着一种敬仰的心情。其实并非想象中那么富有魔力,或是神秘。尽管贝叶斯推理背后的数学越来越缜密和复杂,但其背后概念还是非常容易理解。简言之,贝叶斯推理有助于大家得到更有力的结论,将其置于已知的答案中。 贝叶斯推理理念源自托马斯贝叶斯。三百年前,他是一位从不循规蹈矩的教会长老院牧师。贝叶斯写过两本书,一本关于神学,一本关于概率。他的工作就包括今天著名的贝叶斯定理雏形,自此以后应用于推理问题,以及有根据猜测(educated guessing)术语中。贝叶斯理念如此流行,得益于一位名叫理查·布莱斯牧师的大力推崇。此人意识到这份定理的重要性后,将其优化完善并发表。因此,此定理变得更加准确。也因此,历史上将贝叶斯定理称之为 Bayes-Price法则。 译者注:educated guessing 基于(或根据)经验(或专业知识、手头资料、事实等)所作的估计(或预测、猜测、意见等)
影院中的贝叶斯推理
试想一下,你前往影院观影,前面观影的小伙伴门票掉了,此时你想引起他们的注意。此图是他们的背影图。你无法分辨他们的性别,仅仅知道他们留了长头发。那你是说,女士打扰一下,还是说,先生打扰一下。考虑到你对男人和女人发型的认知,或许你会认为这位是位女士。(本例很简单,只存在两种发长和性别) 现在将上面的情形稍加变化,此人正在排队准备进入男士休息室。依靠这个额外的信息,或许你会认为这位是位男士。此例采用常识和背景知识即可完成判断,无需思考。而贝叶斯推理是此方式的数学实现形式,得益于此,我们可以做出更加精确的预测。 我们为电影院遇到的困境加上数字。首先假定影院中男女各占一半,100个人中,50个男人,50个女人。女人中,一半为长发,余下的25人为短发。而男人中,48位为短发,两位为长发。存在25个长发女人和2位长发男人,由此推断,门票持有者为女士的可能性很大。 100个在男士休息室外排队,其中98名男士,2位女士为陪同。长发女人和短发女人依旧对半分,但此处仅仅各占一种。而男士长发和短发的比例依旧保持不变,按照98位男士算,此刻短发男士有94人,长发为4人。考虑到有一位长发女士和四位长发男士,此刻最有可能的是持票者为男士。这是贝叶斯推理原理的具体案例。事先知晓一个重要的信息线索,门票持有者在男士休息室外排队,可以帮助我们做出更好的预测。 为了清晰地阐述贝叶斯推理,需要花些时间清晰地定义我们的理念。不幸的是,这需要用到数学知识。除非不得已,我尽量避免此过程太过深奥,紧随我查看更多的小节,必定会从中受益。为了大家能够建立一个基础,我们需要快速地提及四个概念:概率、条件概率、联合概率以及边际概率。
概率
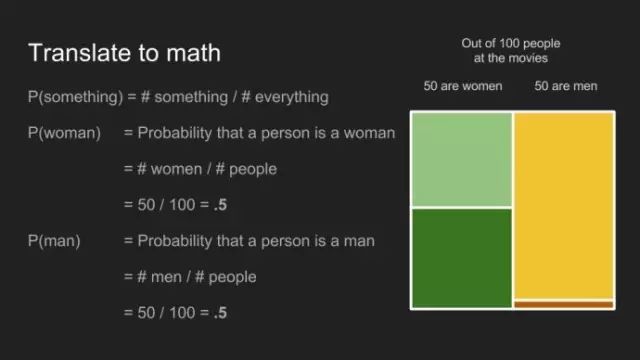
一件事发生的概率,等于该事件发生的数目除以所有事件发生的数目。观影者为一个女士的概率为50位女士除以100位观影者,即0.5 或50%。换作男士亦如此。

而在男士休息室排列此种情形下,女士概率降至0.02,男士的概率为0.98。 条件概率

条件概率回答了这样的问题,倘若我知道此人是位女士,其为长发的概率是多少?条件概率的计算方式和直接得到的概率一样,但它们更像所有例子中满足某个特定条件的子集。本例中,此人为女士,拥有长发的人士的条件概率,P(long hair | woman)为拥有长发的女士数目,除以女士的总数,其结果为0.5。无论我们是否考虑男士休息室外排队,或整个影院。
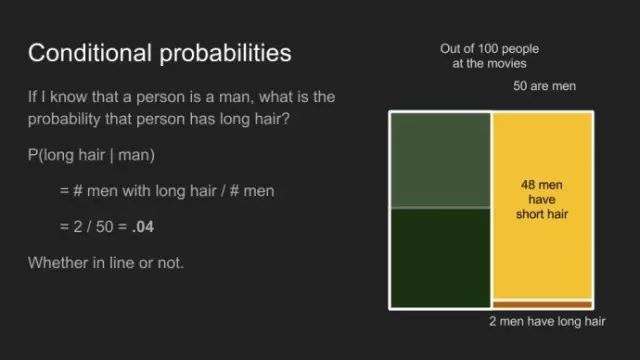
同样的道理,此人为男士,拥有长发的条件概率,P(long hair | man)为0.4,不管其是否在队列中。 很重要的一点,条件概率P(A | B)并不等同于P(B | A)。比如P(cute | puppy)不同于P(puppy | cute)。倘若我抱着的是小狗,可爱的概率是很高的。倘若我抱着一个可爱的东西,成为小狗的概率中等偏下。它有可能是小猫、小兔子、刺猬,甚至一个小人。
联合概率

联合概率适合回答这样的问题,此人为一个短发女人的概率为多少?找出答案需要两步。首先,我们先看概率是女人的概率,P(woman)。接着,我们给出头发短人士的概率,考虑到此人为女士,P(short hair | woman)。通过乘法,进行联合,给出联合概率,P(woman with short hair) = P(woman) * P(short hair | woman)。利用此方法,我们便可计算出我们已知的概率,所有观影中P(woman with long hair)为0.25,而在男士休息室队列中的P(woman with long hair)为0.1。不同是因为两个案例中的P(woman)不同。

相似的,观影者中P(man with long hair) 为0.02,而在男士休息室队列中概率为0.04。 和条件概率不同,联合概率和顺序无关,P(A and B)等同于P(B and A)。比如,同时拥有牛奶和油炸圈饼的概率,等同于拥有油炸圈饼和牛奶的概率。
边际概率
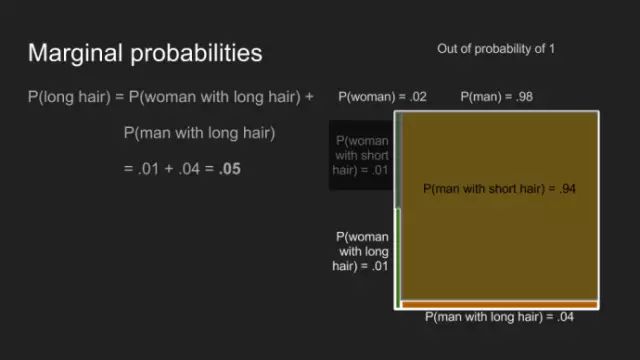
我们最后一个基础之旅为边际概率。特别适合回答这样的问题,拥有长发人士的概率?为计算出结果,我们须累加此事发生的所有概率——即男士留长发的概率加女士留长发的概率。加上这两个概率,即给出所有观影者P(long hair)的值0.27,而男休息室队列中的P(long hair)为0.05。
贝叶斯定理
现在到了我们真正关心的部分。我们想回答这样的问题,倘若我们知道拥有长发的人士,那他们是位女士或男士的概率为?这是一个条件概率,P(man | long hair),为我们已知晓的P(long hair | man)逆方式。因为条件概率不可逆,因此,我们对这个新条件概率知之甚少。 幸运的是托马斯观察到一些很酷炫的知识可以帮到我们。
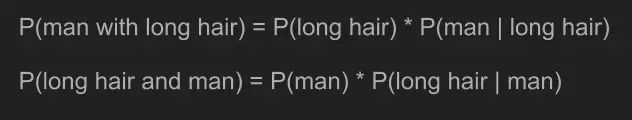
根据联合概率计算规则,我们给出方程P(man with long hair)和P(long hair and man)。因为联合概率可逆,因此这两个方程等价。
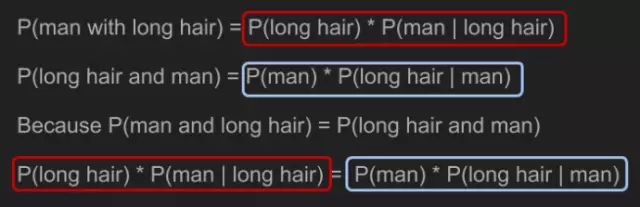
借助一点代数知识,我们就能解出P(man | long hair)。

表达式采用A和B,替换“man”和“long hair”,于是我们得到贝叶斯定理。

我们回到最初,借助贝叶斯定理,解决电影院门票困境。
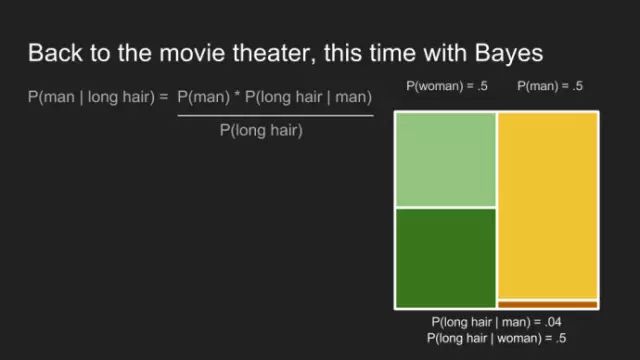
首先,需要计算边际概率P(long hair)。
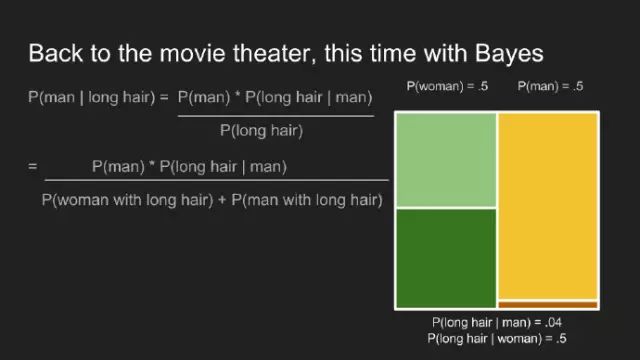
接着代入数据,计算出长发中是男士的概率。对于男士休息室队列中的观影者而言,P(man | long hair)微微0.8。这让我们更加确信一直觉,掉门票的可能是一男士。贝叶斯定理抓住了在此情形下的直觉。更重要的是,更重要的是吸纳了先验知识,男士休息室外队列中男士远多于女士。借用此先验知识,更新我们对一这情形的认识。
概率分布 诸如影院困境这样的例子,很好地解释了贝叶斯推理的由来,以及作用机制。然而,在数据科学应用领域,此推理常常用于数据解释。有了我们测出来的先验知识,借助小数据集便可得出更好的结论。在开始细说之前,请先允许我先介绍点别的。就是我们需要清楚一个概率分布。 此处可以这样考虑概率,一壶咖啡正好装满一个杯子。倘若用一个杯子来装没有问题,那不止一个杯子呢,你需考虑如何将这些咖啡分这些杯子中。当然你可以按照自己的意愿,只要将所有咖啡放入某个杯子中。而在电影院,一个杯子或许代表女士或者男士。

或者我们用四个杯子代表性别和发长的所有组合分布。这两个案例中,总咖啡数量累加起来为一杯。
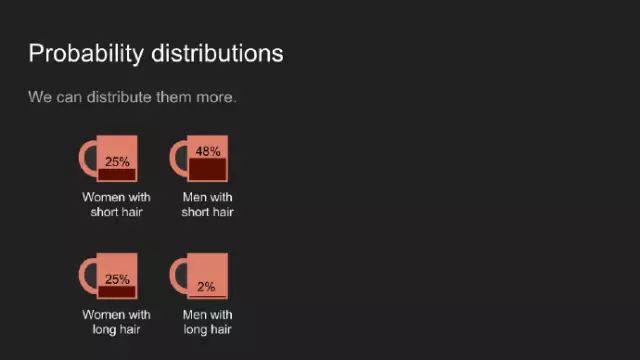
通常,我们将杯子挨个摆放,看其中的咖啡量就像一个柱状图。咖啡就像一种信仰,此概率分布用于显示我们相信某件事情的强烈程度。
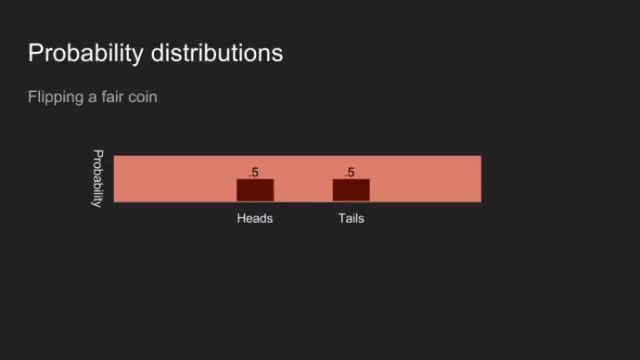
假设我投了一块硬币,然后盖住它,你会认为正面和反面朝上的几率是一样的。
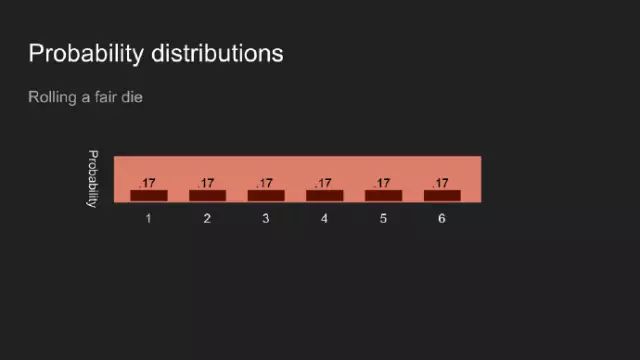
假设我投了一个骰子,然后盖住它,你会认为六个面中的每一个面朝上的几率是一样的。
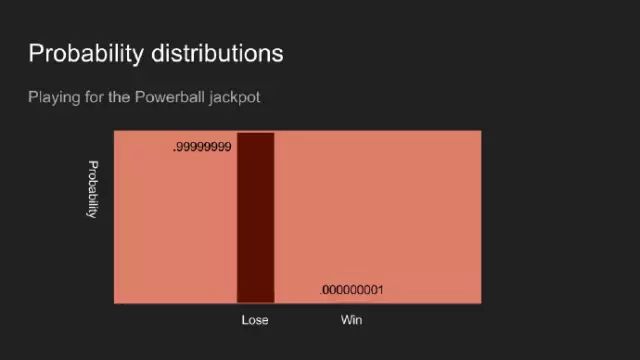
假设我买了一期强力球彩票,你会认为中奖的可能性微乎其微。投硬币、投骰子、强力球彩票的结果,都可以视为收集、测量数据的例子。
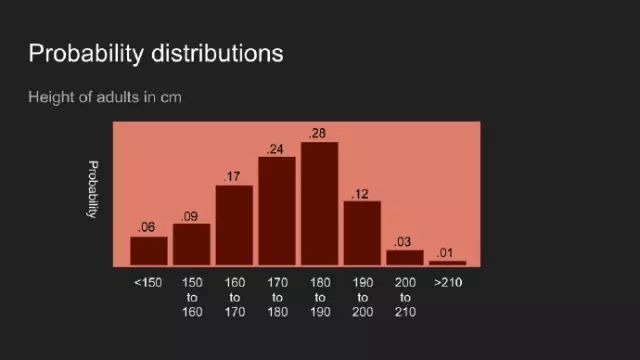
毫无意外,你也可以对其它数据持有某种看法。这里我们考虑美国成年人的身高,倘若我告诉你,我见过,并测量了某些人的身高,那你对他们身高的看法,或许如上图所示。此观点认为一个人的身高可能介于150和200cm之间,最有可能的是介于180和190cm之间。
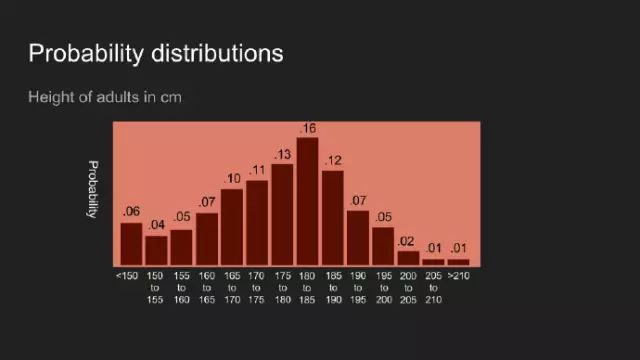
此分布可以分成更多的方格,视作将有限的咖啡放入更多的杯子,以期获得一组更加细颗粒度的观点。
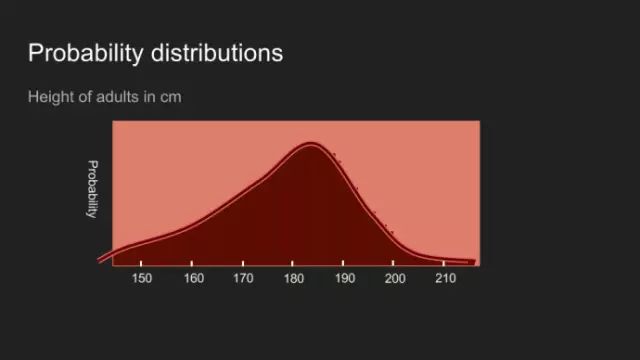
最终虚拟的杯子数量将非常大,以至于这样的比喻变得不恰当。这样,分布变得连续。运用的数学方法可能有点变化,但底层的理念还是很有用。此图表明了你对某一事物认知的概率分布。 感谢你们这么有耐心!!有了对概率分布的介绍,我们便可采用贝叶斯定理进行数据解析了。为了说明这个,我以我家小狗称重为例。
兽医领域的贝叶斯推理
它叫雅各宾当政,每次我们去兽医诊所,它在秤上总是各种晃动,因此很难读取一个准确的数据。得到一个准确的体重数据很重要,这是因为,倘若它的体重有所上升,那么我们就得减少其食物的摄入量。它喜欢食物胜过它自己,所以说风险蛮大的。 最近一次,在它丧失耐心前,我们测了三次:13.9镑,17.5镑以及14.1镑。这是针对其所做的标准统计分析。计算这一组数字的均值,标准偏差,标准差,便可得到小狗当政的准确体重分布。
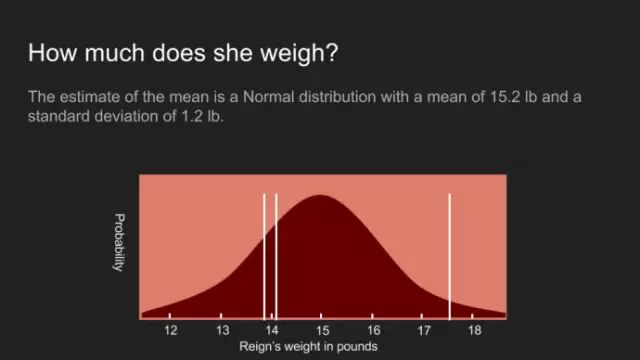
分布展示了我们认为的小狗体重,这是一个均值15.2镑,标准差1.2镑的正态分布。真实得测量如白线所示。不幸的是,这个曲线并非理想的宽度。尽管这个峰值为15.2镑,但概率分布显示,在13镑很容易就到达一个低值,在17镑到达一个高值。太过宽泛以致无法做出一个确信的决策。面对如此情形,通常的策略是返回并收集更多的数据,但在一些案例中此法操作性不强,或成本高昂。本例中,小狗当政的(Reign )耐心已经耗尽,这是我们仅有的测量数据。 此时我们需要贝叶斯定理,帮助我们处理小规模数据集。在使用定理前,我们有必要重新回顾一下这个方程,查看每个术语。

我们用“w” (weight)和 “m” (measurements)替换“A” and “B” ,以便更清晰地表示我们如何用此定理。四个术语分别代表此过程的不同部分。 先验概率,P(w),表示已有的事物认知。本例中,表示未称量时,我们认为的当政体重w。 似然值,P(m | w),表示针对某个具体体重w所测的值m。又叫似然数据。 后验概率,P(w | m),表示称量后,当政为某个体重w的概率。当然这是我们最感兴趣的。 译者注:后验概率,通常情况下,等于似然值乘以先验值。是我们对于世界的内在认知。 概率数据,P(m),表示某个数据点被测到的概率。本例中,我们假定它为一个常量,且测量本身没有偏向。 对于完美的不可知论者来说,也不是什么特别糟糕的事情,而且无需对结果做出什么假设。例如本例中,即便假定当Reign的体重为13镑、或1镑,或1000000 镑,让数据说话。我们先假定一个均一的先验概率,即对所有值而言,概率分布就一常量值。贝叶斯定理便可简化为P(w | m) = P(m | w)。
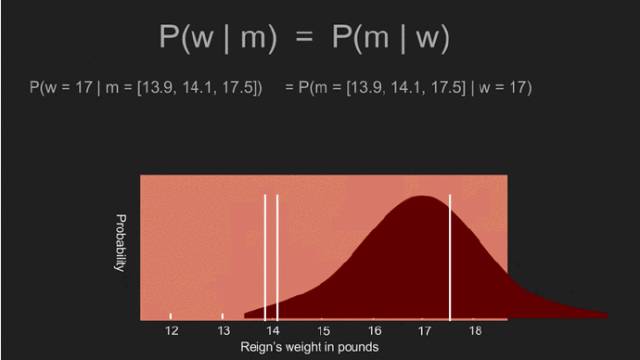
此刻,借助Reign的每个可能体重,我们计算出三个测量的似然值。比如,倘若当政的体重为1000镑,极端的测量值是不太可能的。然而,倘若当政的体重为14镑或16镑。我们可以遍历所有,利用Reign的每一个假设体重值,计算出测量的似然值。这便是P(m | w)。得益于这个均一的先验概率,它等同于后验概率分布 P(w | m)。 这并非偶然。通过均值、标准偏差、标准差得来的,很像答案。实际上,它们是一样的,采用一个均一的先验概率给出传统的统计估测结果。峰值所在的曲线位置,均值,15.2镑也叫体重的极大似然估计(MLE)。 即使采用了贝叶斯定理,但依旧离有用的估计很远。为此,我们需要非均一先验概率。先验分布表示未测量情形下对某事物的认知。均一的先验概率认为每个可能的结果都是均等的,通常都很罕见。在测量时,对某些量已有些认识。年龄总是大于零,温度总是大于-276摄氏度。成年人身高罕有超过8英尺的。某些时候,我们拥有额外的领域知识,一些值很有可能出现在其它值中。
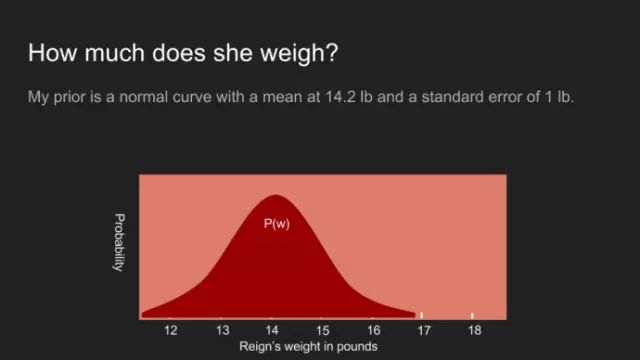
在Reign的案例中,我确实拥有其它的信息。我知道上次它在兽医诊所称到的体重是14.2镑。我还知道它并不是特别显胖或显瘦,即便我的胳膊对重量不是特别敏感。有鉴于此,它大概重14.2镑,相差一两镑上下。为此,我选用峰值为14.2镑。标准偏差为0.5镑的正态分布。
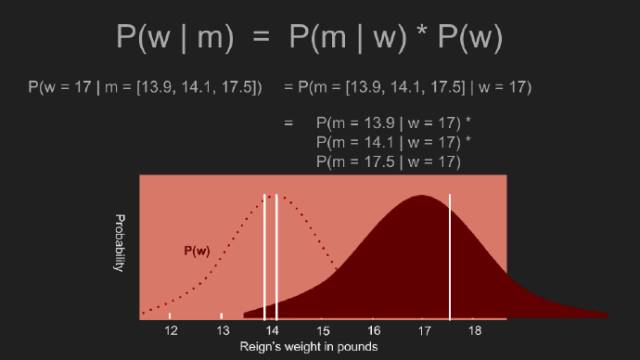
先验概率已经就绪,我们重复计算后验概率。为此,我们考虑某一概率,此时Reign体重为某一特定值,比如17镑。接着,17镑这一似然值乘以测量值为17这一条件概率。接着,对于其它可能的体重,我们重复这一过程。先验概率的作用是降低某些概率,扩大另一些概率。本例中,在区间13-15镑增加更多的测量值,以外的区间则减少更多的测量值。这与均一先验概率不同,给出一个恰当的概率,当政的真实体重为17镑。借助非均匀的先验概率,17镑掉入分布式的尾部。乘以此概率值使得体重为17镑的似然值变低。
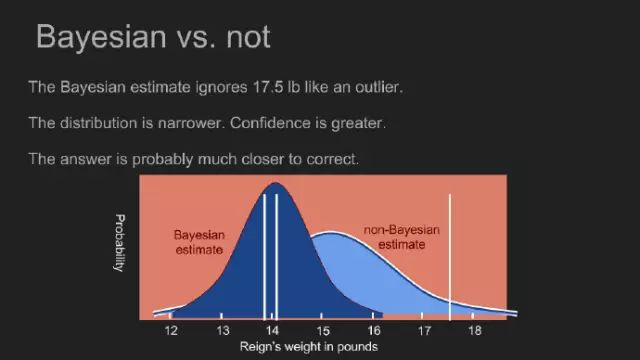
通过计算当政每一个可能的体重概率,我们得到一个新的后验概率。后验概率分布的峰值也叫最大后验概率(MAP),本例为14.1镑。这和均一先验概率有明显的不同。此峰值更窄,有助于我们做出一个更可信的估测。现在来看,小狗当政的体重变化不大,它的体型依旧如前。 通过吸收已有的测量认知,我们可以做出一个更加准确的估测,其可信度高于其他方法。这有助于我们更好地使用小量数据集。先验概率赋予17.5镑的测量值是一个比较低的概率。这几乎等同于反对此偏离正常值的测量值。不同于直觉和常识的异常检测方式,贝叶斯定理有助于我们采用数学的方式进行异常检测。 另外,假定术语P(m)是均一的,但恰巧我们知道称量存在某种程度的偏好,这将反映在P(m)中。若称量仅输出某些数字,或返回读数2.0,占整个时间的百分之10,或第三次尝试产生一个随机测量值,均需要手动修改P(m)以反映这一现象,以便后验概率更加准确。 规避贝叶斯陷阱 探究Reign的真实体重体现了贝叶斯的优势。但这也存在某些陷阱。通过一些假设我们改进了估测,而测量某些事物的目的就是为了了解它。倘若我们假定对某一答案有所了解,我们可能会删改此数据。马克·吐温对强先验的危害做了简明地阐述,“将你陷入困境的不是你所不知道的,而是你知道的那些看似正确的东西。” 假如采取强先验假设,当Reign的体重在13与15镑之间,再假如其真实体重为12.5镑,我们将无法探测到。先验认知认为此结果的概率为零,不论做多少次测量,低于13镑的测量值都认为无效。 幸运的是,有一种两面下注的办法,可以规避这种盲目地删除。针对对于每一个结果至少赋予一个小的概率,倘若借助物理领域的一些奇思妙想,当政确实能称到1000镑,那我们收集的测量值也能反映在后验概率中。这也是正态分布作为先验概率的原因之一。此分布集中了我们对一小撮结果的大多数认识,不管怎么延展,其尾部再长都不会为零。 在此,红桃皇后是一个很好的榜样: 爱丽丝笑道:“试了也没用,没人会相信那些不存在的事情。”
“我敢说你没有太多的练习”,女王回应道,“我年轻的时候,一天中的一个半小时都在闭上眼睛,深呼吸。为何,那是因为有时在早饭前,我已经意识到存在六种不可能了。”来自刘易斯·卡罗尔的《爱丽丝漫游奇境》
编辑:黄飞
全部0条评论

快来发表一下你的评论吧 !
