

微软开源“傻瓜式”类ChatGPT模型训练工具
描述
在利用 OpenAI 的 GPT-4 为 Bing Chat、 Bing Image Creator、Microsoft 365 Copilot、Azure OpenAI Service 和 GitHub Copilot X 引入了类似 ChatGPT 的功能后。微软现又宣布推出 DeepSpeed-Chat,一种用于 RLHF 训练的低成本开源解决方案,基于微软开源的深度学习优化库 DeepSpeed;声称即使是使用单个 GPU,任何人也都可以创建高质量的 ChatGPT 式模型。
该公司表示,尽管开源社区付出了巨大的努力,但目前仍缺乏一个支持端到端的基于人工反馈机制的强化学习(RLHF)的规模化系统,这使得训练强大的类 ChatGPT 模型十分困难。ChatGPT 模型的训练是基于 InstructGPT 论文中的 RLHF 方式,与常见的大语言模型的预训练和微调截然不同,使得现有深度学习系统在训练类 ChatGPT 模型时存在种种局限。因此,为了让 ChatGPT 类型的模型更容易被普通数据科学家和研究者使用,并使 RLHF 训练真正普及到 AI 社区,他们发布了 DeepSpeed-Chat。
DeepSpeed-Chat 具有以下三大核心功能:
简化 ChatGPT 类型模型的训练和强化推理体验:只需一个脚本即可实现多个训练步骤,包括使用 Huggingface 预训练的模型、使用 DeepSpeed-RLHF 系统运行 InstructGPT 训练的所有三个步骤、甚至生成你自己的类 ChatGPT 模型。此外,还提供了一个易于使用的推理 API,用于用户在模型训练后测试对话式交互。
DeepSpeed-RLHF 模块:DeepSpeed-RLHF 复刻了 InstructGPT 论文中的训练模式,并确保包括 a) 监督微调(SFT),b) 奖励模型微调和 c) 基于人类反馈的强化学习(RLHF)在内的三个步骤与其一一对应。此外,还提供了数据抽象和混合功能,以支持用户使用多个不同来源的数据源进行训练。
DeepSpeed-RLHF 系统:其将 DeepSpeed 的训练(training engine)和推理能力(inference engine) 整合到一个统一的混合引擎(DeepSpeed Hybrid Engine or DeepSpeed-HE)中用于 RLHF 训练。DeepSpeed-HE 能够在 RLHF 中无缝地在推理和训练模式之间切换,使其能够利用来自 DeepSpeed-Inference 的各种优化,如张量并行计算和高性能 CUDA 算子进行语言生成,同时对训练部分还能从 ZeRO- 和 LoRA-based 内存优化策略中受益。DeepSpeed-HE 还能够自动在 RLHF 的不同阶段进行智能的内存管理和数据缓存。
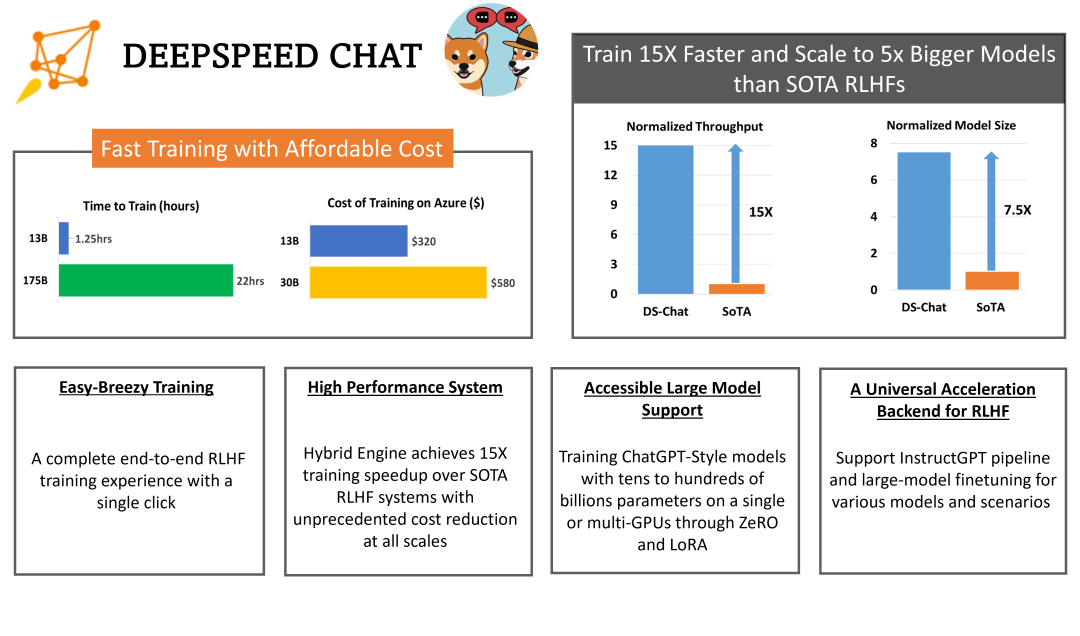
文档内容指出,DeepSpeed Chat 与其他先进方案相比的优势在于:效率和经济性方面比现有系统快 15 倍以上,在 Azure 云上只需 9 小时即可训练一个 OPT-13B 模型,只需 18 小时既可训练 OPT-30B 模型,分别花费不到 300 美元和 600 美元。
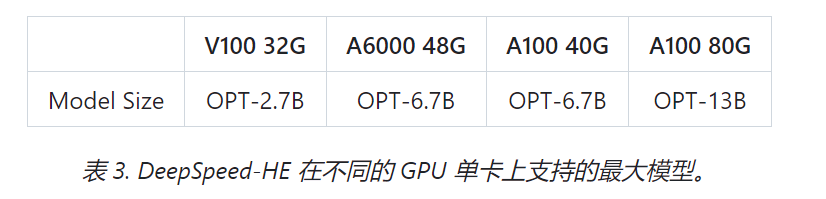
在速度和可扩展性方面,即使是 13B 的模型也可以在 1.25 小时内训练,庞大的 175B 模型可以在不到一天的时间内使用 64 个 GPU 集群进行训练。在 RLHF 的可访问性和普及化方面,则可以在单个 GPU 上训练超过 130 亿参数的模型。此外还支持在相同的硬件上分别运行 6.5B 和 50B 的模型,实现高达 7.5 倍的提升。


尽管近期关于对 ChatGPT 类大语言模型发展的反对和担忧之声不断,但微软似乎仍在全力推进其 AI 开发。对于微软的此次发布,前 Meta AI 专家 Elvis 也激动地表示,DeepSpeed Chat 提供了 Alpaca 和 Vicuna 等所缺少的、一个端到端的 RLHF 管道来训练类似 ChatGPT 的模型,解决的是成本和效率方面的挑战。这是 “微软令人印象深刻的开源努力。..。.. 是一件大事”。
审核编辑 :李倩
-
使用QUARTUS II做FPGA开发全流程,傻瓜式详细教程2012-03-08 56999
-
fpga资料傻瓜式教程2012-07-13 18083
-
Cadence画PCB傻瓜式教程2018-01-15 3397
-
ML之ECS:利用ECS的PAI进行傻瓜式操作机器学习的算法2018-12-20 3444
-
傻瓜式混合型功率放大器的原理是什么?2019-10-09 1743
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
傻瓜式混合型功率放大器电路及原理2009-11-17 3819
-
自制单片机开发板全过程(傻瓜式教程)2016-02-25 1659
-
斐讯无线路由器傻瓜式小白刷机教程2016-04-29 1680
-
【小知识】自制AT89S51单片机开发板全过程(傻瓜式教程)2021-11-13 1388
-
“傻瓜式”操作 高压旋喷灌浆记录仪2023-02-06 9504
-
类ChatGPT训练需高性能芯片大规模并联,高速接口IP迎红利时代2023-03-06 34231
-
【嵌入式AI简报20230414】黑芝麻智能7nm中央计算芯片正式发布、微软开源“傻瓜式”类ChatGPT模型训练工具2023-04-14 2655
-
重磅!微软开源Deep Speed Chat,人人拥有ChatGPT……2023-05-11 1365
-
llm模型和chatGPT的区别2024-07-09 2864
全部0条评论

快来发表一下你的评论吧 !
