

使用Google Colab快速体验ScaledYOLOv4
电子说
描述
「对象侦测」一直是计算机视觉的重点项目,已发展了二十多年,早期利用各种特征提取和比对来找出人们对影像中有兴趣的像素集合(对象),如VJ, HOG等。近几年来,大家则把重点放在了「深度学习」的模型上,从刚开始的二阶段侦测器(Two-stage Detector),如RCNN, SPPNet, Fast RCNN, Faster RCNN等,到目前最流行的一阶段侦测器(One-stageDetector),如SSD, RetinaNet, EfficientDet, YOLO等,其中又以YOLO(You OnlyLook Once)系列发展的最好,一路发展出YOLOv2, YOLOv3, YOLOv4, YOLOv5, 去年更有ScaledYOLOv4,YOLOX, YOLOR等技术推出,让大家有更快推论速度、更高推论精度、更弹性模型架构,让同一张影像中大小对象都能顺利被检出。
「ScaledYOLOv4」这个模型可依输入影像大小选择不同尺度架构,以往YOLOv4只分标准和tiny两种,而这里分为tiny, csp, large,而large又分p5, p6, p7,完整的架构可参考Fig. 1 & 2。至于模型的运作原理[7]写得颇清楚,这里就不多作说明。从Fig. 1就可明显看出其效能大幅优于YOLOv3, YOLOv4及EfficientDet。
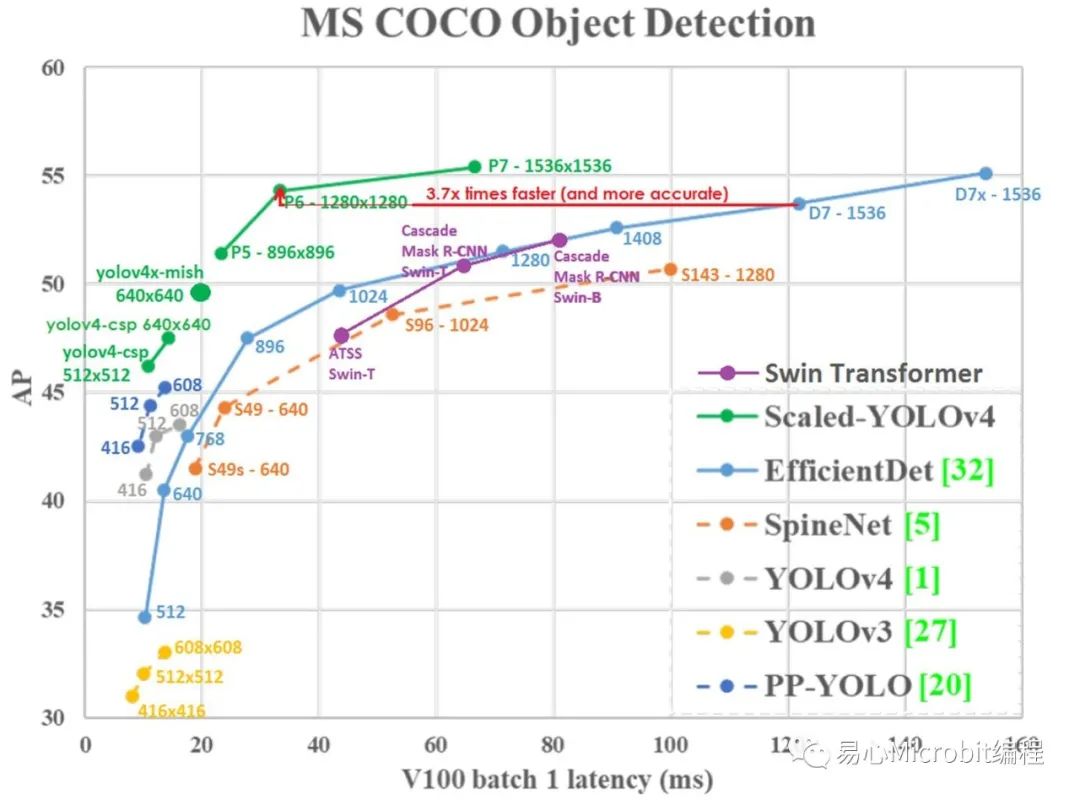
Fig. 1 ScaledYOLOv4和其它模型在COCO数据集推论效能比较表。
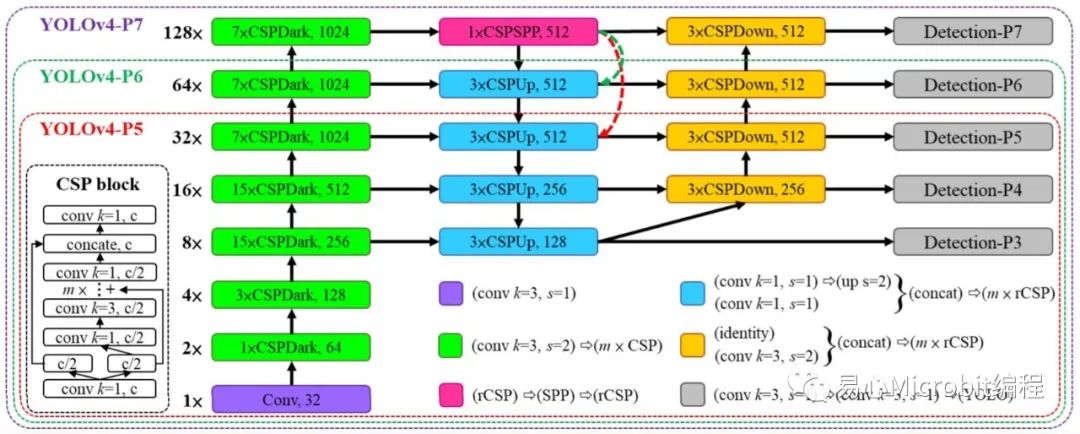
Fig. 2 ScaledYOLOv4模型架构(csp, p5,p6, p7)。
为了让大家快速上手,这里参考了王建尧博士释出的PyTorch源码,
https://github.com/WongKinYiu/ScaledYOLOv4
另外提供了一个完整的Google Colab范例,说明如何建立环境及运行COCO数据集预训练参数。而训练及推论自定义数据集就留待下回分解。完整范例请参考下列网址。
https://github.com/OmniXRI/Colab_ScaledYOLOv4
由于csp和large(p5)在模型定义的格式略有不同,前者为cfg,后者是采yaml,权重值亦有不同,前者为weight,后者为pt,所以这里有两个范例程序,分别对应csp和large两种格式,而large又以p5为例,若要执行p6, p7则自行修改内容即可。
scaled-yolov4-csp_coco_test.ipynb
scaled-yolov4-large_coco_test.ipynb
整个程序主要有八个动作,如下说明,这里以csp为例。
1. 检查GPU及CUDA版本
由于后面的程序需要用要Nvidia CUDA,所以要先检查。执行后若显示failed,则至左上角选单中「编辑」─「笔记本设定」下「硬件加速器」选择「GPU」,再重新运行一次即可。至于配置到那一种Nvidia GPU则无妨。
!nvidia-smi
2. 检查系统默认安装套件及版本
建议版本如下所示,若大于下列版本而造成无法顺利运作则请自行降版后再执行后续工作。
Python3.7.12
opencv-contrib-python4.1.2.30
opencv-python4.1.2.30
tensorboard2.7.0
torch1.10.0+cu111
torchvision0.11.1+cu111
!python--version
!piplist
3. 安装 mish-cuda
这是ScaledYOLOv4必要组件,一定要安装,否则无法顺利运行,预设安装版本 0.0.3。
本范例无法于无Nvidia CUDA环境下运行。
!pipinstall git+https://github.com/JunnYu/mish-cuda.git
!piplist
4. 下载ScaledYOLOv4
依需求下载不同版本(csp, large)的PyTorch ScaledYOLOv4到 /content/ScaledYOLOv4 路径下。请注意这里 -byolov4-csp 为指定下载csp版本分支,若无-b参数则为large(default版本)。
!gitclone -b yolov4-csp https://github.com/WongKinYiu/ScaledYOLOv4
%cdScaledYOLOv4
!ls
5. 下载COCO预训练权重档
在 /content/ScaledYOLOv4下新增 /weights 路径,将Google共享文件COCO预训练权重值档案下载到该路径下。主要差别在--ld后面的路径,可自行更换。
yolov4-csp.weights: 1TdKvDQb2QpP4EhOIyks8kgT8dgI1iOWT
yolov4-p5.pt: 1aXZZE999sHMP1gev60XhNChtHPRMH3Fz
yolov4-p6.pt: 1aB7May8oPYzBqbgwYSZHuATPXyxh9xnf
yolov4-p7.pt: 18fGlzgEJTkUEiBG4hW00pyedJKNnYLP3
!mkdirweights
%cdweights
!gdown--id 1TdKvDQb2QpP4EhOIyks8kgT8dgI1iOWT
!ls
6. 下载测试影像
在 /data 路径下建立 /images 用于存放测试影像
随便从网络上下载一张影像并更名为 test01.jpg
%cd/content/ScaledYOLOv4/data
!mkdirimages
%cdimages
!wgethttps://raw.githubusercontent.com/WongKinYiu/PyTorch_YOLOv4/master/data/samples/bus.jpg
!mvbus.jpg test01.jpg
!ls
7. 进行推论
根据下列参数执行推论程序 detect.py
影像大小 640x640, (预设csp为640, p5为896, p6为1280, p7为1536)
置信度 0.3, (可自行调整)
推论装置(GPU) 0, (第一组GPU)
配置文件, (csp为yolov4-csp.cfg, large为yolov4-p5.yaml)
模型权重文件, (csp为yolov4-csp.weights,large为yolov4-p5.pt)
来源影像(可指定单张影像、单个影片、档案夹等)
%cd/content/ScaledYOLOv4/
!pythondetect.py
--img640
--conf0.3
--device0
--cfgmodels/yolov4-csp.cfg
--weightsweights/yolov4-csp.weights
--sourcedata/images/test01.jpg
8. 显示推论结果
推论完成会将结果置于 /inference/output 路径下
使用OpenCV函数显示结果影像
importcv2
fromgoogle.colab.patches import cv2_imshow
img1 =cv2.imread('data/images/test01.jpg')
cv2_imshow(img1)
img2 =cv2.imread('inference/output/test01.jpg')
cv2_imshow(img2)

Fig. 3ScaledYOLOv4运行结果,左:csp,右:large(p5)。
从Fig. 3上可以看出,连右上角的遮挡的很严重的脚踏车都能侦测到。而左侧穿白外套男人领口的橘色部位在large(p5)被辨识为领带,人眼不仔细看还真的会误判,更何况模型。整体来说表现不错。
小结
这篇文章先帮大家暖暖身,如果你想辨识的内容在COCO数据集80类范围内的话,那就直接使用就可以,若需要自己训练自定义的数据集,就静待下回分解啰!
审核编辑 :李倩
-
使用google-translate和wwe合并后无法使用google-tts怎么解决?2024-06-28 742
-
在Google Colab笔记本电脑上导入OpenVINO™工具包2021中的 IEPlugin类出现报错,怎么解决?2025-03-05 418
-
Google Fast Pair服务简介2025-06-29 688
-
_53.【 Colab】搭建基于 Google Colab 的 HTTP 服务器充八万 2023-08-08
-
【转载】Google Glass应用开发探索2013-06-28 5125
-
浅析ADK Google fast pair功能2019-09-20 5796
-
Google Colab现在提供免费的T4 GPU2019-04-26 7730
-
Google“黑科技”,Pixel 4 或将实现指尖级的隔空操作2019-06-13 3133
-
Google推出了超级强大的在线编辑器Colaboratory2019-07-18 4293
-
怎样将Google日历附加到Google网站2019-11-25 2609
-
Google重磅发布开源库TFQ,快速建立量子机器学习模型2020-03-12 3447
-
如何在Colab中使用SQL2021-10-12 2540
-
谷歌Colab硬刚Github Copilot,编程效率要翻天2023-05-19 1578
-
PyTorch教程23.4之使用Google Colab2023-06-06 769
全部0条评论

快来发表一下你的评论吧 !
