

基于Alpaca派生的多轮对话数据集
人工智能
描述
斯坦福大学的Alpaca项目为大模型的Instruction Tuning 提供了单轮的指令数据。然而,ChatGPT最显著的特点是其多轮对话能力,允许用户提出跟进问题或纠正模型回答中的错误。为了训练大模型响应多轮指令的能力,ChatAlpaca是一个面向大模型的多轮对话指令数据集。ChatAlpaca利用ChatGPT在Alpaca数据集的基础上模拟用户生成跟进问题,从而将单轮指令扩展为多轮对话。
ChatAlpaca数据集
目前,ChatAlpaca数据集包含10,000个对话组,共计95,558条对话语句。每个对话组的第一轮对话是来自Alpaca数据集的指令:用户输入指令,ChatGPT给出回答。随后,用户根据回答内容展开追问,将对话进行下去。以下是ChatAlpaca数据集的一个例子:

数据集构建过程
ChatAlpaca数据集使用Alpaca数据作为第一轮对话,通过扩展跟进问题来构建每一轮对话。每一轮对话的构建包括两个阶段:用户问题生成和回复生成。
用户问题生成:
ChatAlpaca使用ChatGPT(GPT-3.5-turbo)生成用户问题,模型的输入包括一个提示语(prompt)和当前对话的历史记录。提示语要求ChatGPT模拟用户生成问题,用户问题可以是进一步提问,或者在ChatGPT答案错误时给出提示。
例如,根据以下聊天历史记录:
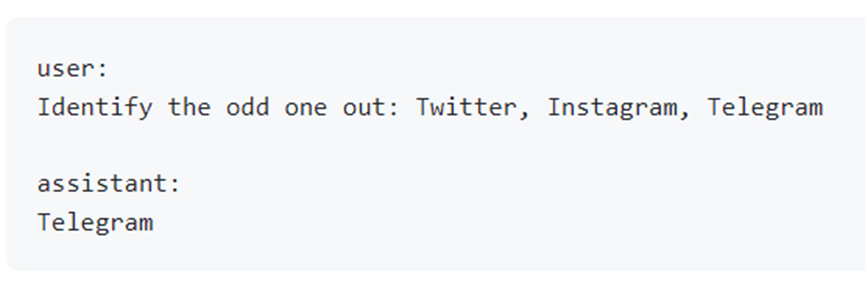
ChatGPT生成的用户问题为

ChatAlpaca还使用关键词过滤了不符合用户身份的问题,例如“As an AI language model, I'm here to assistyou.”、“Do you have any questions that I can help youwith?”等。
回复生成:
ChatAlpaca使用上一步生成的用户问题作为下一轮对话的开始,与对话历史记录拼接,让ChatGPT生成新的回复。在上面的例子中,ChatGPT根据以下输入生成回复:

然后将这一轮ChatGPT的回复添加到对话历史记录中。
重复上述过程,直到对话达到预定的轮数(ChatAlpaca设定为最多5轮),或用户问题中包含“GoodBye”。
目前已经发布了包含10,000个对话组的ChatAlpaca数据集,接下来将发布包含20,000个对话组的数据和由机器翻译生成的中文对话数据。此外,还将发布使用ChatAlpaca数据集训练的LLaMA-LoRA模型和LLaMA微调模型。
编辑:黄飞
- 相关推荐
- 热点推荐
- ChatGPT
-
米尔RK3576部署端侧多模态多轮对话,6TOPS算力驱动30亿参数LLM2025-09-05 12628
-
浅析多继承派生类中的虚基类2021-09-30 1714
-
派生单稳电路2008-05-19 1043
-
领邦研发轮对自动检测机 可测量国内外各种火车轮对2012-08-31 1652
-
继承与派生_实验32016-01-14 369
-
基于分层编码的深度增强学习对话生成2017-11-25 771
-
DocumentAI的模型、任务和基准数据集2022-08-22 2706
-
一个真实闲聊多模态数据集TikTalk2023-02-09 3826
-
中文多模态对话数据集2023-02-22 2482
-
多模态上下文指令调优数据集MIMIC-IT2023-06-12 1766
-
BaiChuan13B多轮对话微调范例2023-08-24 2360
-
摩尔线程Round Attention优化AI对话2025-03-06 1265
-
AI玩具:以多轮对话、情感陪伴等为卖点,多款方案优化角逐2025-04-28 7029
-
3C认证派生是什么意思?2025-10-21 1889
全部0条评论

快来发表一下你的评论吧 !
