

详解域控制器的四大支柱
描述
域控制器的四大支柱分别是车载以太网、自适应Autosar、高性能处理器和集中式E/E架构。
车载以太网之物理层
车载以太网有两个核心,一个是车载以太网物理层,另一个是车载以太网协议栈。前者让车载以太网不同于传统PC以太网,具备较低的重量和成本、较好的EMI性能和简单布线。后者让车载以太网达到车规级的可确定性、高可靠性、低延迟和时钟一致。
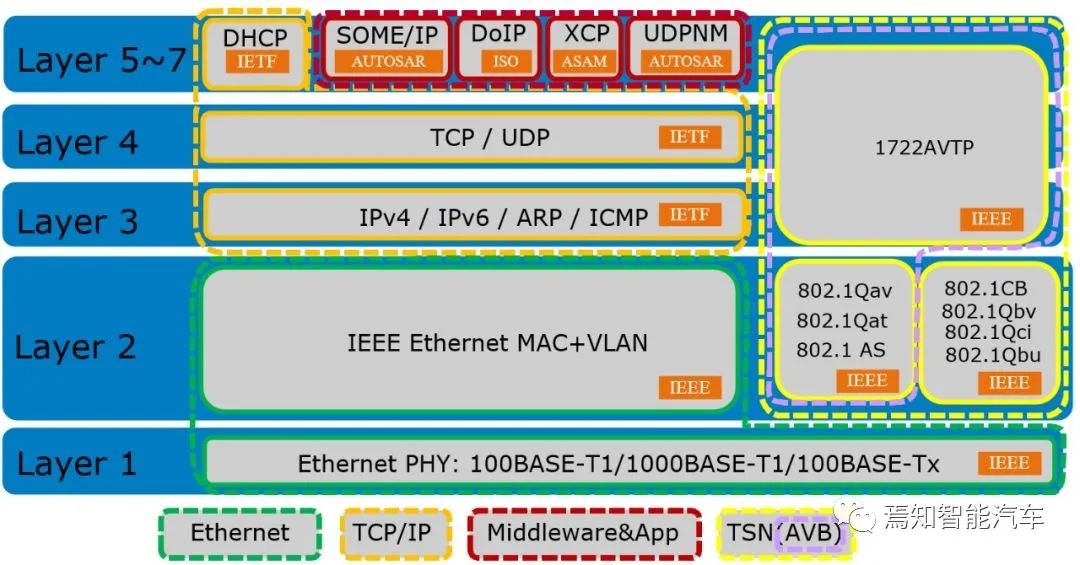
车载以太网OSI模型,资料来源:Marvell
车载以太网标准分两部分,一部分是最底层的PHY标准,另一部分是链路层标准。这两个标准都以IEEE的标准应用最广泛。
车载以太网PHY标准主要是制定单对双绞线标准,传统以太网与车载以太网最大不同是传统以太网需要2-4对线,车载以太网只需要一对,且是非屏蔽的,仅仅此一项,可以减少70-80%的连接器成本,可以减少30%的重量。这是车载以太网诞生的最主要原因。同时也是为了满足车内的EMC电磁干扰。
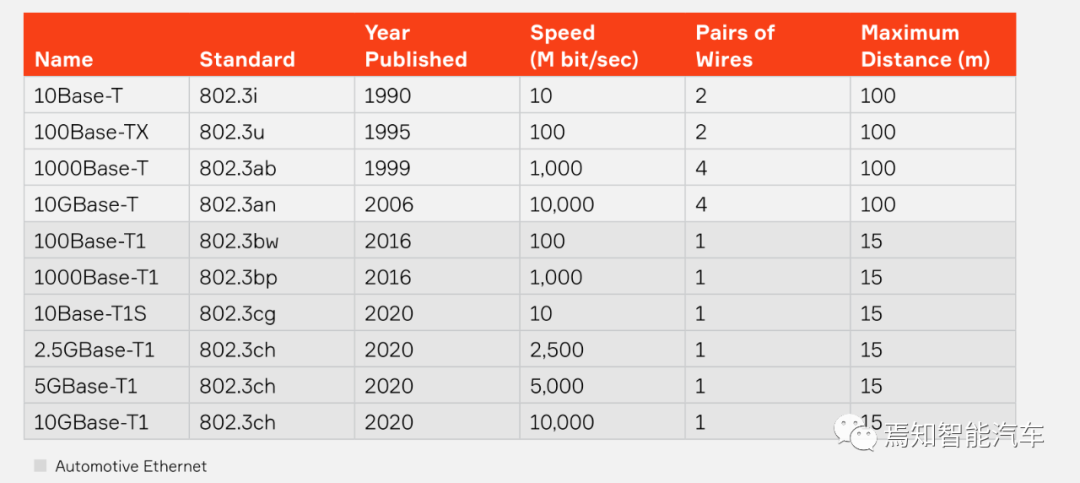
车载以太网PHY标准分布,资料来源:Marvell
车载以太网野心勃勃,10Base-T1S是试图取代传统的CAN网络的。10BASE-T1S即IEEE802.3cg也就是 OPEN Alliance 的TC14 ,100BASE-T1即IEEE802.3bw也就是OPEN Alliance TC1,100/1000BASE-T1 ECU测试标准即OPEN Alliance的TC8, 1000BASE-T1即IEEE802.3bp也就是OPEN Alliance 的TC12 ,2.5/5/10GBASE-T1即IEEE802.3ch也就是OPEN Alliance 的TC15标准。
车载以太网物理层IC,100Mbps的大约3-4美元,德州仪器、NXP传统汽车芯片大厂市场占有率高,传统网络芯片厂家博通也略强。1Gbps的大约15-20美元,Marvell在此领域实力超强,博通和Microchip也有一席之地。1Gbps以上基本只有Aquantia,Aquantia已经被Marvell以4.52亿美元收购。10Gbps有Aquantia的AQV107,大约40美元一片。
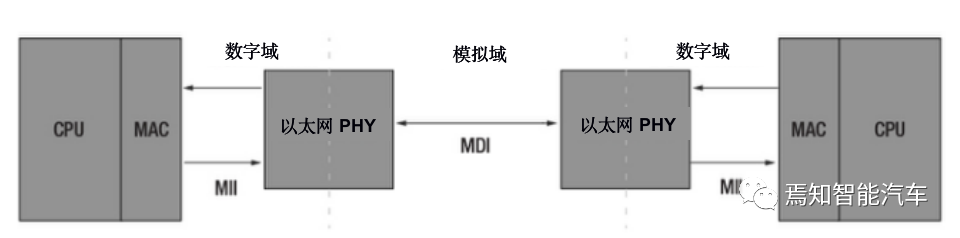
PHY在发送数据的时候,收到MAC过来的数据(对PHY来说,没有帧的概念,对它来说,都是数据而不管什么地址,数据还是CRC),每4bit就增加1bit的检错码,然后把并行数据转化为串行流数据,再按照物理层的编码规则(10Based-T的NRZ编码或100based-T的曼彻斯特编码)把数据编码,再变为模拟信号把数据送出去。网线上的到底是模拟信号还是数字信号呢?答案是模拟信号,因为它传出和接收是采用的模拟的技术。虽然它传送的信息是数字的,并不是传送的信号是数字的。
通常交换器IC和MCU会集成低端(如CAN网络)的物理层,高端(如以太、Flexray网络)物理层一般都是单独的芯片。
车载以太网协议栈标准集:TSN
以太网是由鲍勃梅特卡夫(Bob Metcalfe)于1973年提出的,以太网络使用CSMA/CD(载波监听多路访问及冲突检测)技术,目前通常使用双绞线(UTP线缆)进行组网。包括标准的以太网(10Mbit/s)、快速以太网(100Mbit/s)、千兆网(1Gbit/s)和10G(10Gbit/s)以太网。它们都符合IEEE802.3。(注:bps=bit/s) 。以太网中所有的传输都是串行传输,就是说在网卡的物理端口会在每一个单位时间内“写入”或是“读取”一个电位值(0或1)。那么这个单位时间对于1Gbps带宽来说就是1÷1000,000,000=1ns,每8个位(bit)相当于1个字节(Byte)。多个字节(Byte)可以组成一个数据帧。以太网传输数据是以帧为单位的。
以太网规定每一个数据帧的最小字节是64byte,最大字节是1518byte。实际上每个数据帧之间还会有一个12字节的间隔。由于带宽通常是由多个设备共享的,这也是以太网的优势所在。但是所有的发送端没有基于时间的流量控制,并且这些发送端永远是尽最大可能发送数据帧。这样来自不同设备的数据流就会在时间上产生重叠,即我们通常所说的冲突。因为所有数据流重叠/冲突的部分会遵循QoS优先机制进行转发,一部分的数据包肯定会被丢弃。在IT专业里有一个不成文的规定。
当某个交换机的带宽占用率超过40%时就必须得扩容,其目的就是通过提高网络带宽来避免拥堵的产生。
由于以太网的发明时间太早,并没有考虑实时信息的传输问题。尽管RTP(Realtime Transport Protocol)能在一定程度上保证实时数据的传输,但并不能为按顺序传送数据包提供可靠的传送机制。因此,想要对所有的数据包进行排序,就离不开对数据的缓冲(Buffer)。但一旦采用缓冲的机制就又会带来新的问题—极大的“延时”。换句话说,当数据包在以太网中传输的时候从不考虑延时、排序和可靠交付。传统以太网最大的缺点是不确定性或者说非实时性,由于Ethernet采用CSMA/CD方式,网络负荷较大时,网络传输的不确定性不能满足工业控制的实时要求,故传统以太网技术难以满足控制系统要求准确定时通信的实时性要求,一直被视为“非确定性”的网络。
尽管传统二层网络已经引入了优先级(Priority)机制,三层网络也已内置了服务质量(QoS)机制,仍然无法满足实时性数据的传输。此外,在传统以太网中,只有当现有的包都处理完后才会处理新到的包,即使是在Gbit/s的速率下也需要几百微秒的延迟,满足不了车内应用的需求。更何况目前是Mbit/s的速率,延迟最多可能达上百毫秒,这肯定是无法接受的。普通以太网采用的是事件触发传输模式,在该模式下端系统可以随时访问网络,对于端系统的服务也是先到先服务。事件触发模式的一个明显的缺点是当几个端系统需要在同一传输媒介上进行数据通讯时,所产生的传输时延和时间抖动会累积。
随着音视频娱乐大量进入汽车座舱,IEEE开始着手开发用于音视频传输的以太网,这就是EAVB。AVB——以太网音视频桥接技术(Ethernet Audio Video Bridging)是IEEE的802.1任务组于2005开始制定的一套基于新的以太网架构的用于实时音视频的传输协议集。
EAVB主要在针对多媒体数据,适用面太窄,2012年11月,EAVB工作小组改名TSN工作小组。TSN是一系列标准的集和。TSN的核心应用是异构性网络的实时、高可靠性,高时钟同步性数据交换。也就是说主要用于骨干传输网,而非节点。汽车、工业自动化是主要应用场合,这些场合至少有两种以上的传输总线,通常是CAN和以太网,汽车则还有MOST、Flexray、LIN、PSI5、CAN-FD等,这些是用户习惯、成本和研发成果复用性决定的,不可能改变。如果非异构性网络,TSN优势不明显。TSN也可用于5G,5G的前传Fronthaul采用的就是TSN 802.1CM标准。
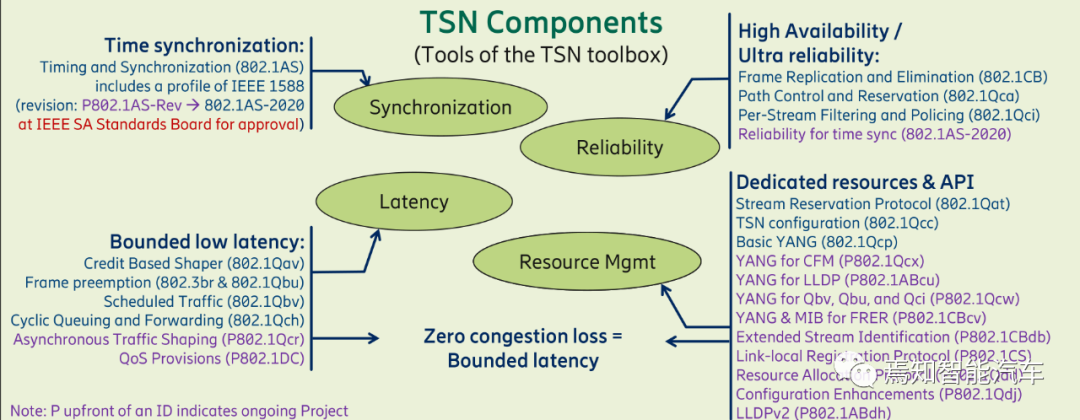
TSN标准包括时钟同步、超高可靠性、低延迟、资源管理四大类,紫色字体为尚未完成,截至2020年1月,2020年6月19日,802.1AS-2020版已经完成。
下面介绍TSN的关键标准
时间同步
所有通信问题均基于时钟,确保时钟同步精度是最为基础的问题,TSN工作组开发基于IEEE1588的时钟,并制定新的标准IEEE802.1AS-Rev。它用于实现高精度的时钟同步。对于TSN而言,其最为重要的不是“最快的传输”和“平均延时”,而是“最差状态下的延时”—这如同“木桶理论”,系统的能力取决于最短的那块板,即对于确定性网络而言,最差的延时才是系统的延时定义。
IEEE1588 协议,又称 PTP( precise time protocol,精确时间协议),可以达到亚微秒级别时间同步精度,于 2002 年发布 version 1,2008年发布 version 2。它的主要原理是通过一个同步信号周期性地对网络中所有节点的时钟进行校正同步,可以使基于以太网的分布式系统达到精确同步,IEEE 1588PTP时钟同步技术也可以应用于任何组播网络中。
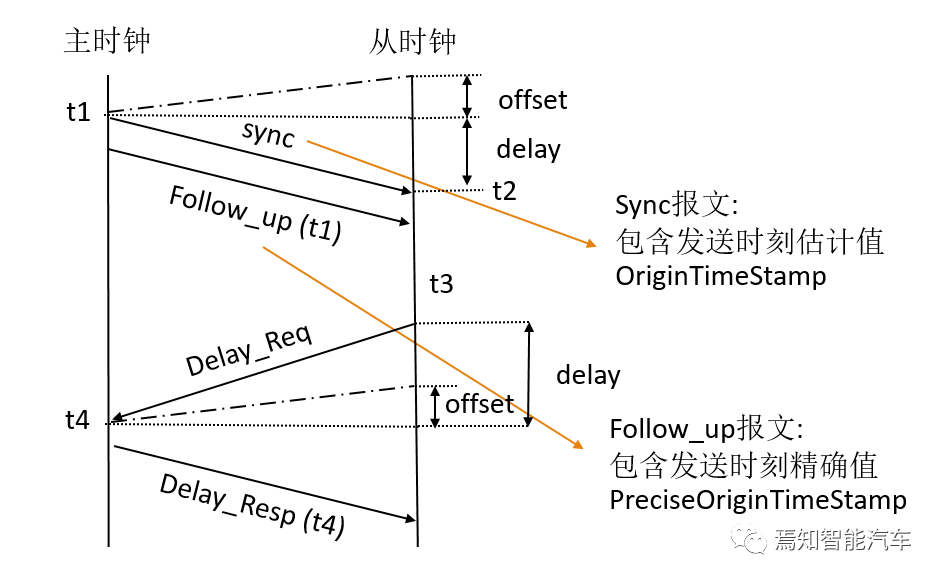
IEEE1588 协议的同步原理,所提出的 Delay Request-Response Mechanism(延时响应机制)如上图,IEEE1588 把所涉及到的报文分为 事件报文 和 通用报文,分类依据是:是否在收发报文时需要记录精确时间戳,根据上文中所描述的几种报文,可以进行如下分类:
事件报文(event message) < 收发时候需要记录精确时间戳 > :sync /Delay_Req/Pdelay_Req/Pdelay_Resp。
通用报文 (generalmessage)< 收发时候不需要几率精确时间戳 > :Announce/Follow_up/Delay_resp/Pdelay_Resp_Follow_Up/Magnament/Siganling。Pdelay_Req /Pdelay_Resp/Pdelay_Resp_Follow_Up通过peer延迟机制测量两个时钟端口之间的链接延时,链接延时被用来更正Sync和Follow_Up报文中的时间信息。
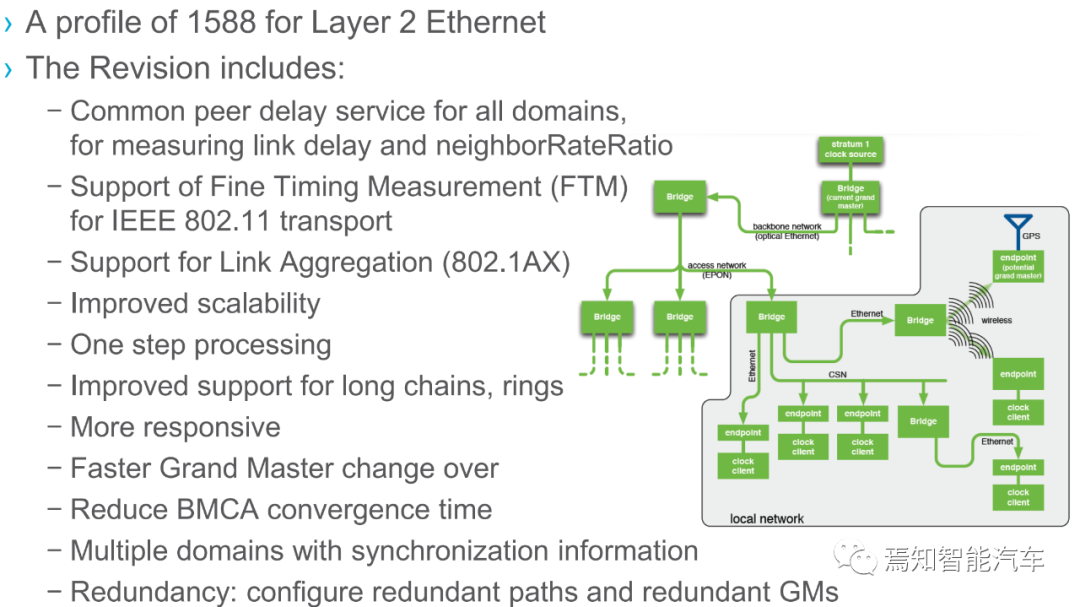
IEEE802.1AS-Rev是为以太网第二层所定义的1588规范加以扩展,它的扩展包括了所有域常用peer延迟服务,支持精细时间测量FTM,对链路聚合(802.1AX)的支持,改善的使用范围-包括1步时间戳标准化处理以及针对长链、环的支持,更好的响应能力,这包括了更快的主站交互、降低BMCA收敛时间。另外IEEE802.1AS-Rev支持了多域的同步信息传输以及冗余支持能力(可配置冗余路径和冗余主站)。对无线网络采用时间测量提供更好的支持。IEEE802.1AS-Rev的制定得到了AVNU联盟的大力支持,AVNU联盟由英特尔、思科和三星哈曼发起,是EAVB协议的主要提供者,AVNU联盟为IEEE802.1AS-Rev的实施提供协助,能够提供完整的协议栈和测试认证。
低延迟
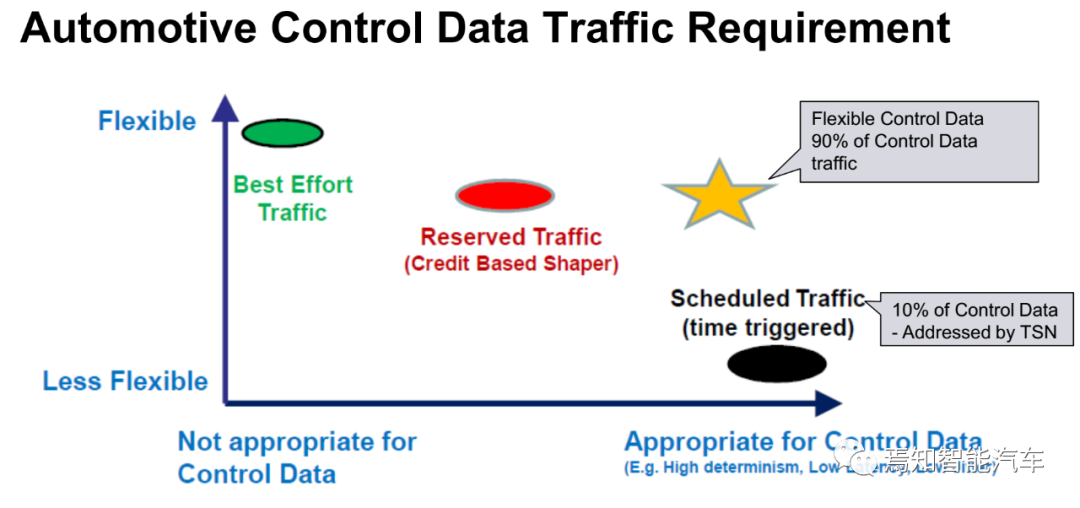
汽车控制数据可以分为三种,Scheduled Traffic、Reserved Traffic、Best-effort Traffic,Scheduled Traffic如底盘控制数据,没有任何的妥协余地,必须按照严格的时间要求送达,有些是只需要尽力而为的如娱乐系统数据,可以灵活掌握。汽车行业一般要求底盘系统延迟不超过5毫秒,最好是2.5毫秒或1毫秒,这也是车载以太网与通用以太网最大不同之处,要求低延迟。
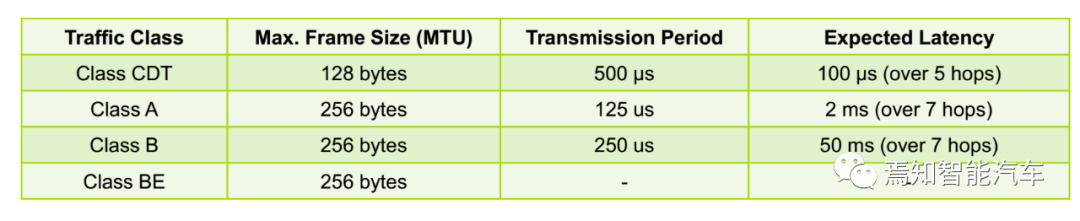
在TSN标准里,数据则被分为4级,最高的预计延迟时间仅为100微秒。
低延迟的核心标准是IEEE802.1Qbv时间感知队列。
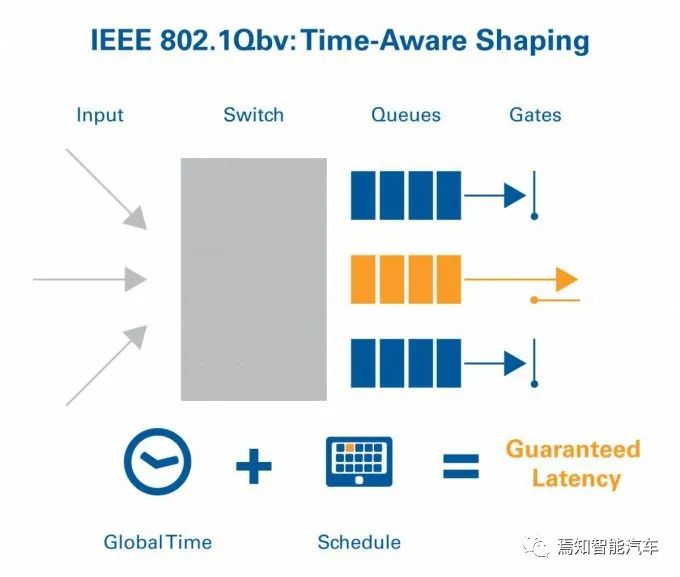
通过时间感知整形器(Time Aware Shaper)使TSN交换机能够来控制队列流量(queued traffic),以太网帧被标识并指派给基于优先级的VLAN Tag,每个队列在一个时间表中定义,然后这些数据队列报文的在预定时间窗口在出口执行传输。其它队列将被锁定在规定时间窗口里。因此消除了周期性数据被非周期性数据所影响的结果。这意味着每个交换机的延迟是确定的,可知的。而在TSN网络的数据报文延时被得到保障。TAS介绍了一个传输门概念,这个门有“开”、“关”两个状态。
传输的选择过程-仅选择那些数据队列的门是“开”状态的信息。而这些门的状态由网络时间进度表network schedule进行定义。对没有进入network schedule的队列流量关闭,这样就能保障那些对传输时间要求严格的队列的带宽和延迟时间。TAS保障时间要求严苛的队列免受其它网络信息的干扰,它未必带来最佳的带宽使用和最小通信延迟。当优先级非常高时,抢占机制可以被使用。
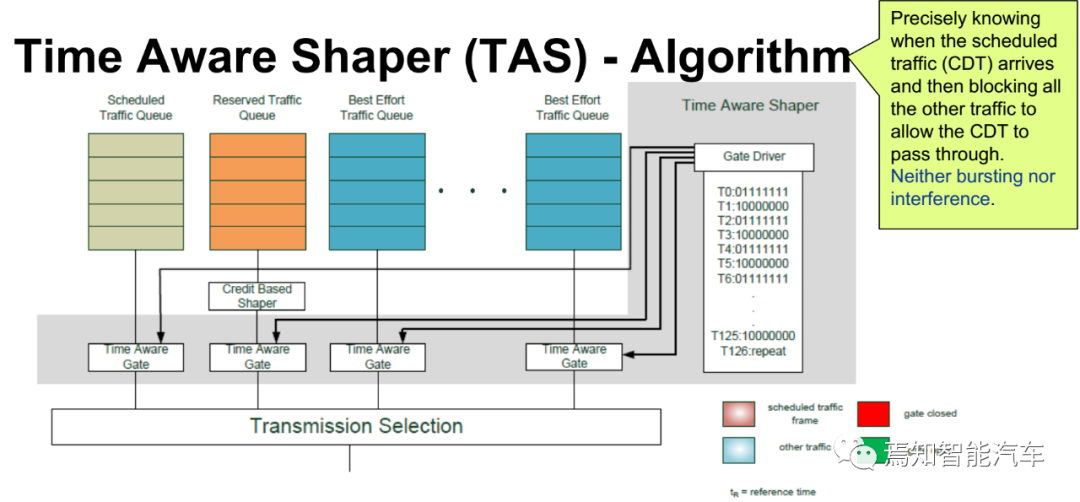
在网络进行配置时队列分为Scheduled Traffic、Reserved Traffic、Best-effort Traffic三种,对于Schedule而言则直接按照原定的时间规划通过,其它则按优先级,Best-effort通常排在最后。Qbv主要为那些时间严苛型应用而设计,其必须确保非常低的抖动和延时。Qbv确保了实时数据的传输,以及其它非实时数据的交换。
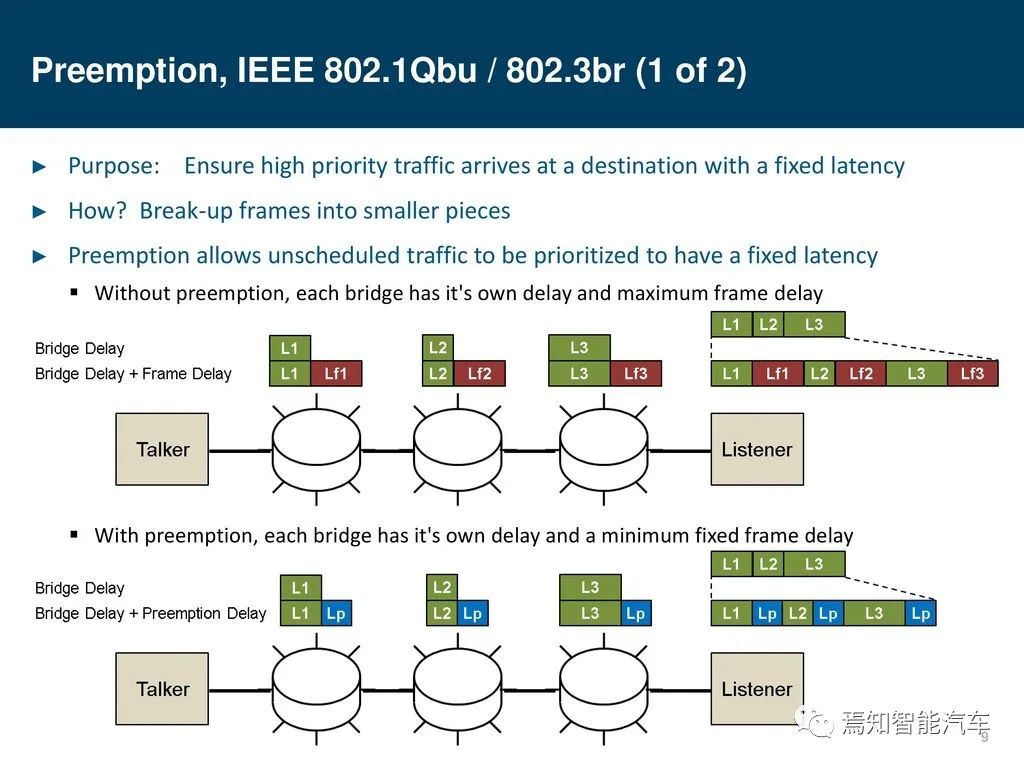
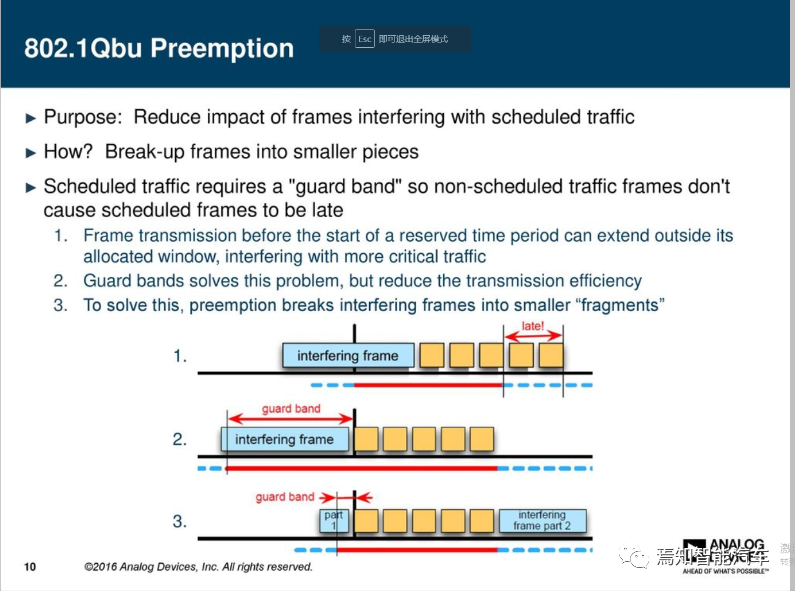
对于特别重要的数据,TSN规定了一个抢占机制,它由802.1Qbu/802.3br共同构成。对于IEEE802.1Qbu的抢占而言,正在进行的传输可以被中断,报文按等级可被分为可被抢占和抢占帧,抢占生成框架,最小以太网帧受到保护的,127字节的数据帧(或剩余帧)不能被抢占。IEEE802.1br定义了,设计了快速帧的MAC数据通道,可以抢占Preemptable MAC的数据传输。IEEE802.3br也同样可以与IEEE802.1Qbv配合进行增强型的数据转发。
高可靠性
TSN中保证高可靠性主要依靠802.1CB标准。这也是无人驾驶必须用TSN的主要原因,也只有TSN能让整个系统达到功能安全的最高等级ASIL D级。同样,与自适应AUTOSAR的捆绑程度也比较高。
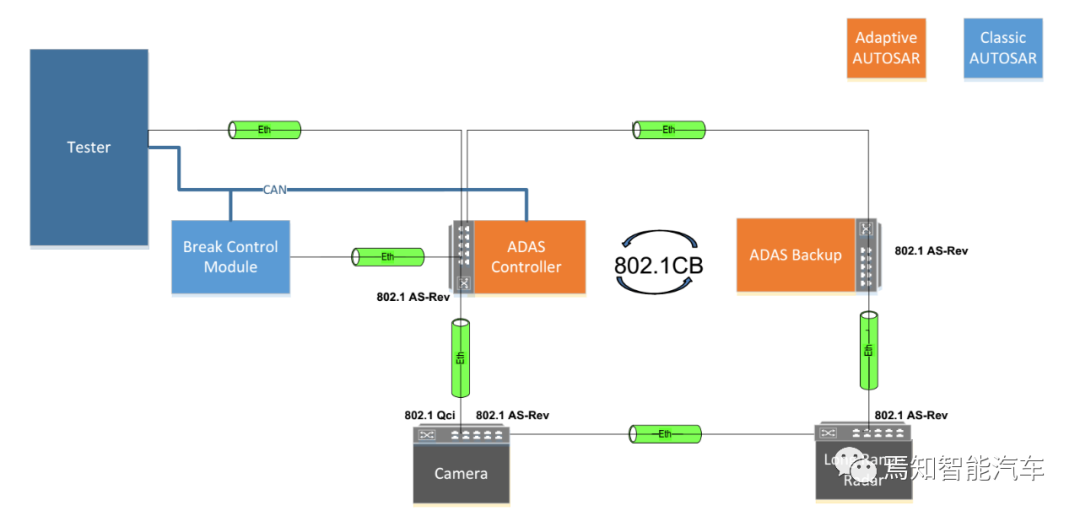
众所周知,L4级无人驾驶需要一个冗余处理器,但是主处理系统和冗余处理系统之间的通讯机制如何建立?这就是802.1CB的用武之地了。802.1CB是两套系统间的冗余,芯片之间的冗余还是多采用PCIE交换机的多主机fail-operational机制,两者有相似之处。
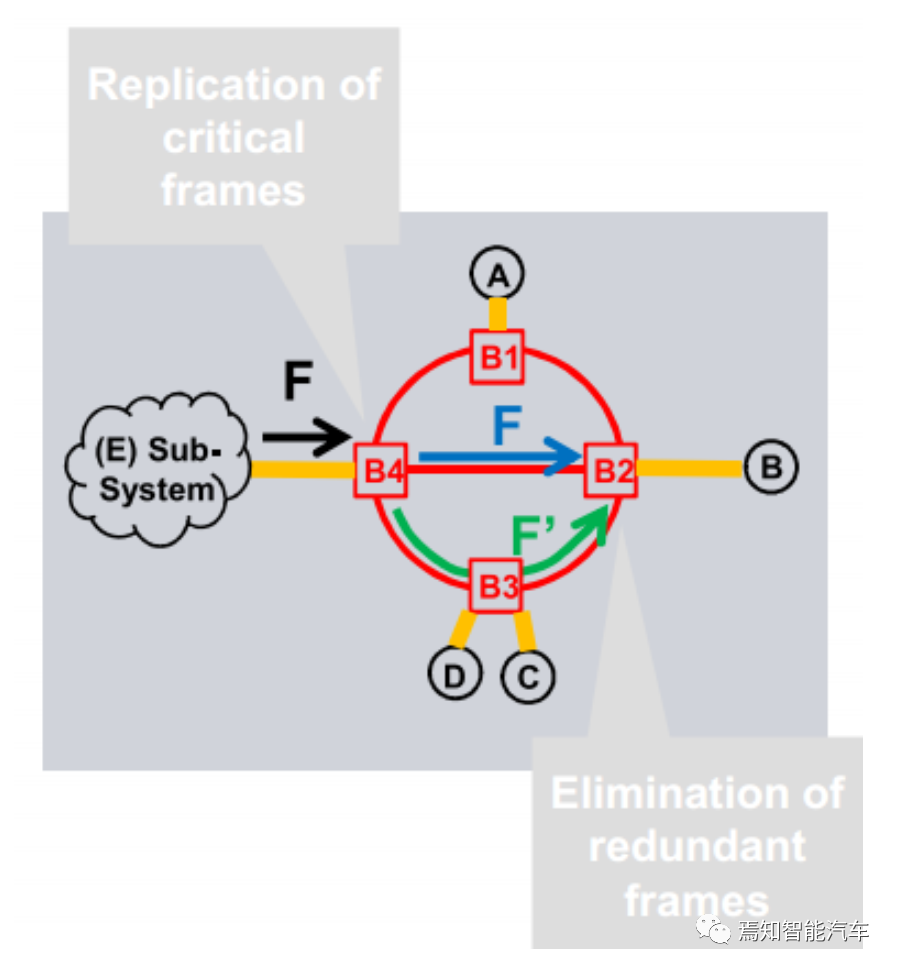
对于非常重要的数据,802.1CB会多发送一个数据备份,这个备份会沿着最远离主数据路径交集的路径传输。如果两个数据都接收到,在接收端把冗余帧消除,如果只接受到一帧数据,那么就进入后备模式。在ISO/IEC 62439-3中已经定义了PRP和HSR两种冗余,这种属于全局冗余,成本较高,802.1CB只针对关键帧做冗余,降低了成本。802.1CB标准的制定主要依靠思科和博通。

802.1CB也可以缩写为FRER。
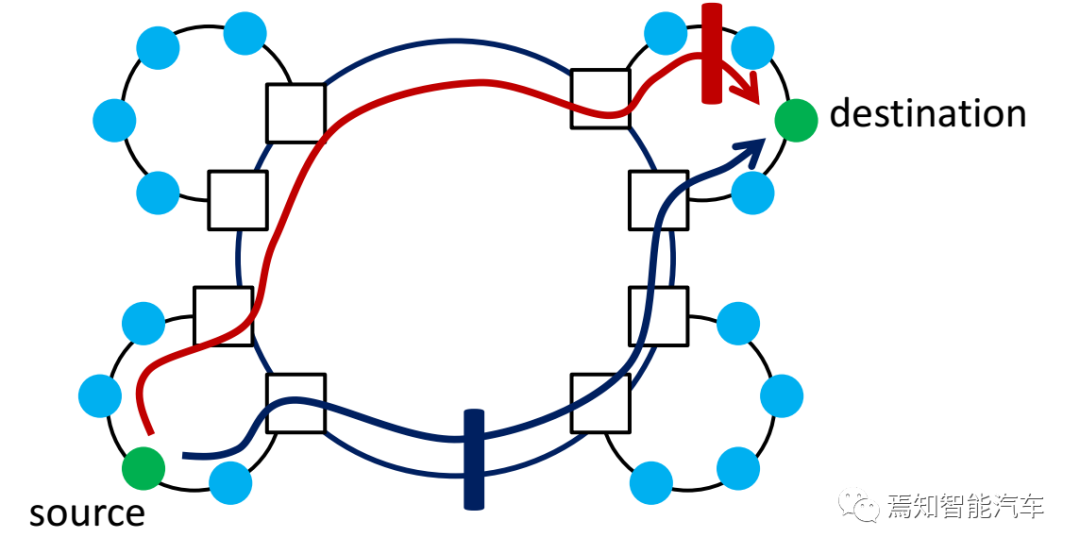
FRER不仅能提供双失效冗余,也可以提供多失效冗余。
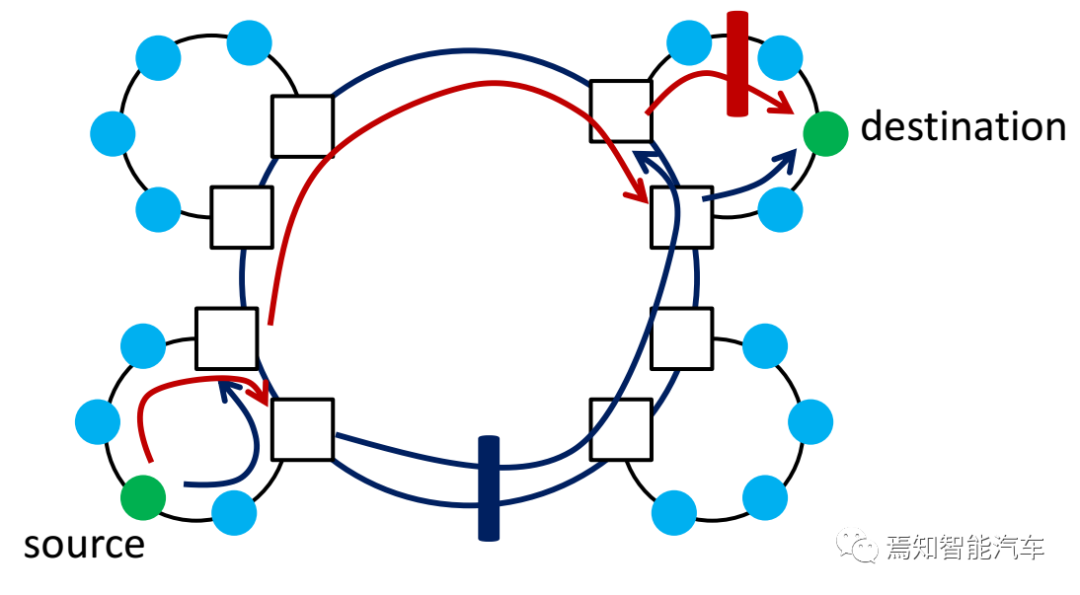
802.1CB也有简单的失效原因分析机制
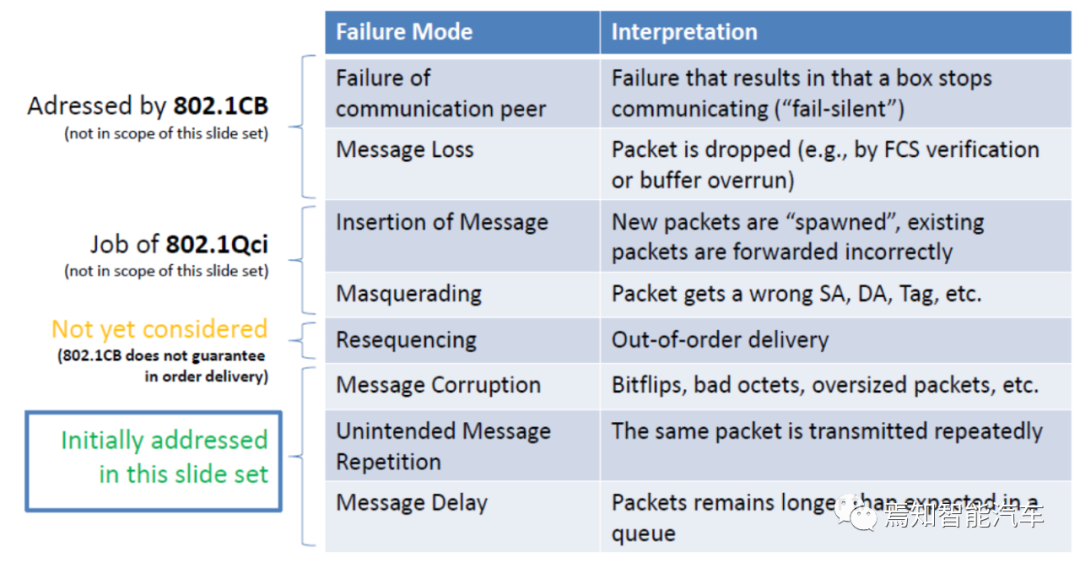
域控制器阶段,TSN的必要性还不是太突出,但是ADAS领域的域控制器,TSN或者说802.1CB的优势明显,未来进入到SOA架构阶段,即混合域和Zonal阶段,TSN交换机和物理层IC都是不可或缺的。一旦转进到SOA架构,TSN很快将取代EAVB成为主流。
自适应Autosar
AUTOSAR只是一个软件框架,不具备实操意义(务虚)。必须购购买第三方的软件系统或二次开发,全球主要有三家商业化的Autosar软件供应商,分别是Vector、EB和ETAS。EB属于德国大陆汽车软件子公司,独立性略差,硬件方方面与瑞萨和英飞凌捆绑稍明显,ETAS规模比较小,ETAS铺盖面最广,独立性最强,规模最大,因此Vector市市场占有率最高,大约有70%。
AUTOSAR结构比较臃肿,想定义一切,灵活性不高,新兴造车通通常不感兴趣。开发AUTOSAR和硬件也捆绑得有点紧,比如国内普华基础软件就跟意法半导体捆绑的紧。
国内有东软、恒润、普华和华为在做,需要芯片厂家配合提供MCAL抽象层,但芯片厂家地位超然,不屑于和小公司合作。普华汽车电子事业部国内唯一通过ASIPICE三级和ASIL D级认证的公司,隶属中中国电子科技集团,国企背景。主要客户包括一汽、东风、长安、奇瑞、江淮等国企。

即便是大公司如奔驰宝马也是购买Vector的Autosar工具MICROSAR。

奔驰的Vector Microsar
为什么要搞自适应Autosar,因为经典Autosar只能对应OSEK这样复杂程度很低的嵌入式操作系统,无法适应Linux这样的大型操作系统,而自动驾驶和部分智能驾驶操作系统都是Linux,因此催生了自适应Autosar。
Adaptive Autosar,自适应Autosar第一版诞生自2017年3月,目前已经有6版,最新版本是2019年11月。据说第一版的自适应Autosar的英文规格书用A4纸打印出来摞起来有7米高。
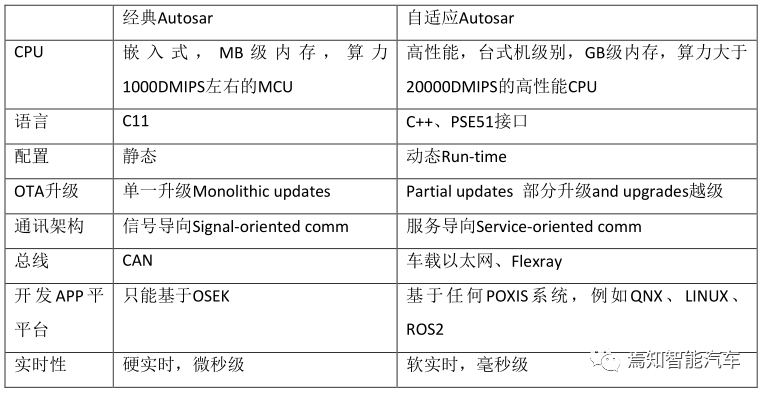
经典Autosar与自适应Autosar对比,目前Autosar有284个会员,9个核心会员,分别是宝马、奔驰、大陆汽车、福特、戴姆勒、PSA、通用汽车、丰田和大众。两个战略会员,电装和LG电子。55个高级会员,其中中国企业有长城、华为、百度、香港英恒。另外说一句,这4家企业是近两年才成为高级会员的,2017年高级会员没有中国企业。
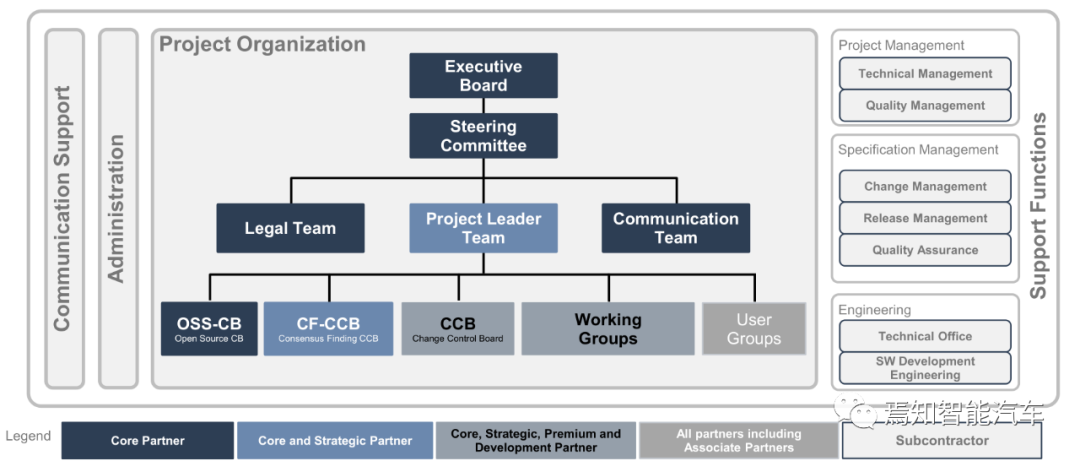
Autosar组织结构,主要工作由Working组完成。

Working组架构如上图。用户组下面再分三个小组,分别是中国组,负责演示开发和基础软件集成。北美组,负责一般性培训(OEM-Tier1 Workflows/ Security),安全和以太网。增强利用ImprovedExploitation组,负责命题(Thesis)优化。
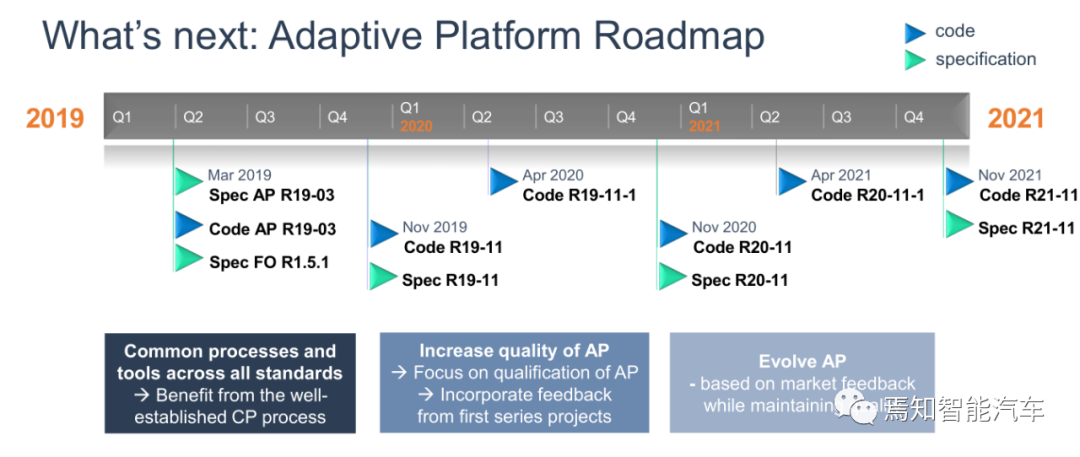
自适应Autosar路线图,版本是不能混用的,比如你买了R19-03的部分模块,剩下的模块想用R19-11版是不可能的。Adaptive AUTOSAR中,主要包含两种Application:
1)Application-Level的Application
2)Platform-Level的Application
Application-Level的Application会生成源代码和目标代码,这部分与 “用户”有关。Platform-Level的Application会生成目标代码,这部分与 "工具供应商" 有关。不是所有工具供应商都能提供完整的Platform-Level的Application,通常只能提供部分,某些领域,标准未确定,如V2X,工具供应商几乎完全无能为力。
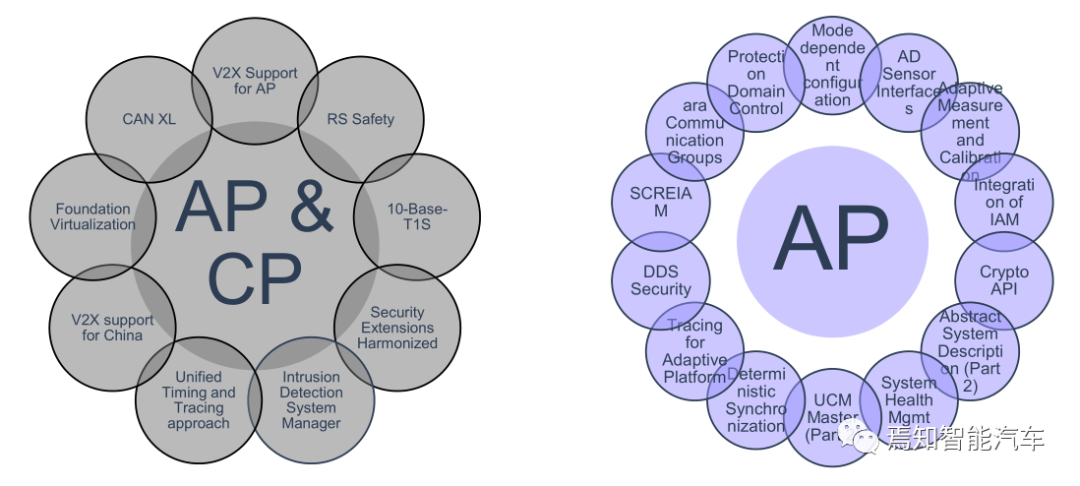
自适应Autosar与经典Autosar计划增加的特色有23个,例如针对中国特色的V2X。
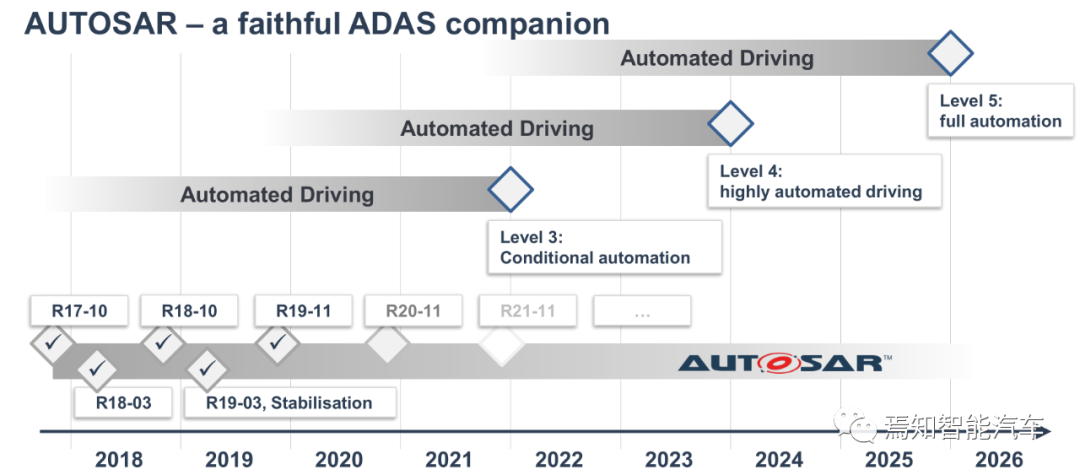
自适应Autosar是针对自动驾驶的,2021年11月版计划对应L3级自动驾驶,不过这个L3级换到中国或者马斯克口中,估计是L5了,目前一般推荐19-03版,比较稳定。

自适应Autosar典型应用场景如上图
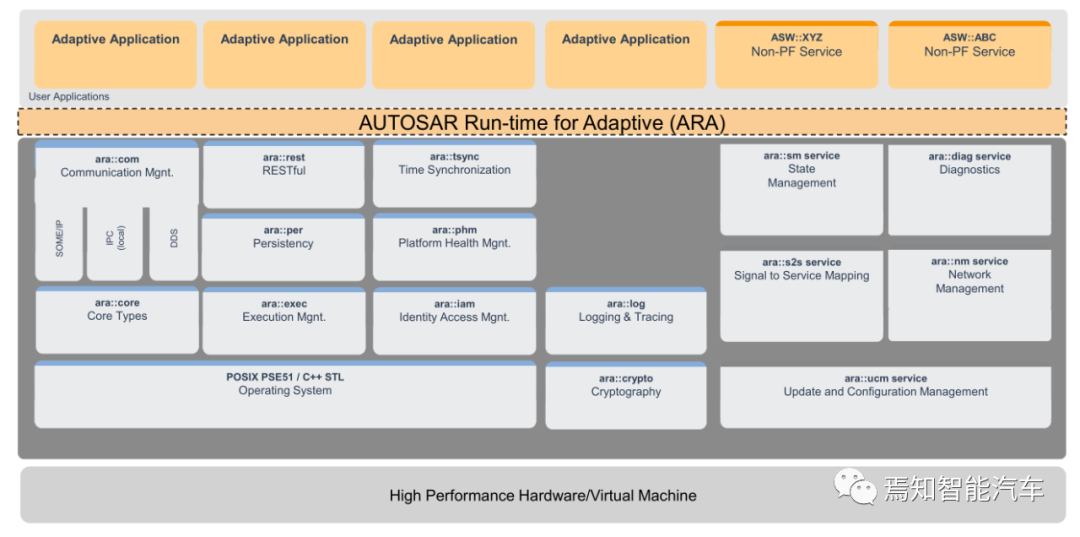
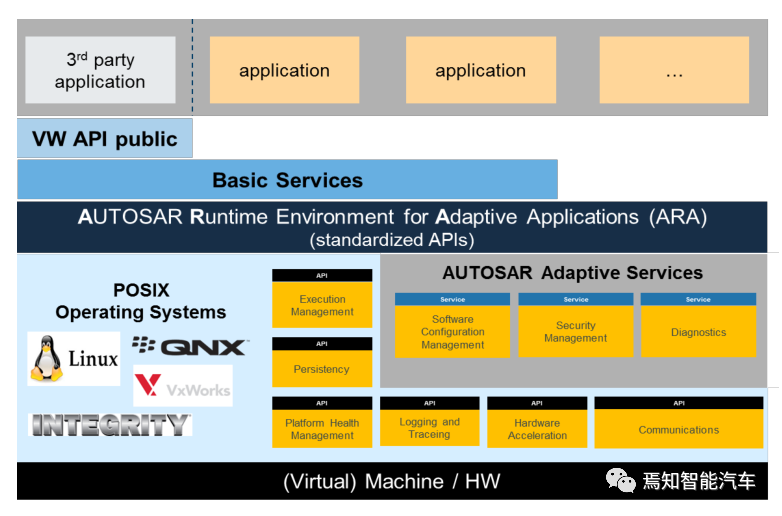
自适应Autosar的层架构如上图。基础服务层中,主要服务包括,通信服务(COM)、加密服务(crypto)、日志记录服务(Log)、诊断服务(Diag)、存储服务(Per)、状态管理(SM)、执行管理(Exec)、时间同步(Tsync)、升级配置管理(UCM)等。
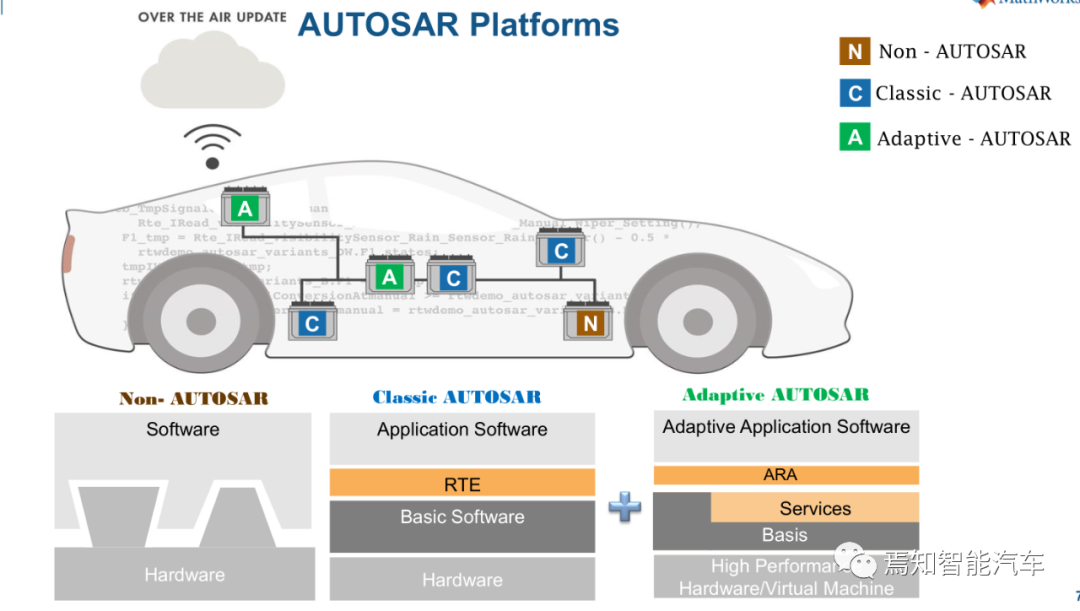
非Autosar、经典Autosar和自适应Autosar对比
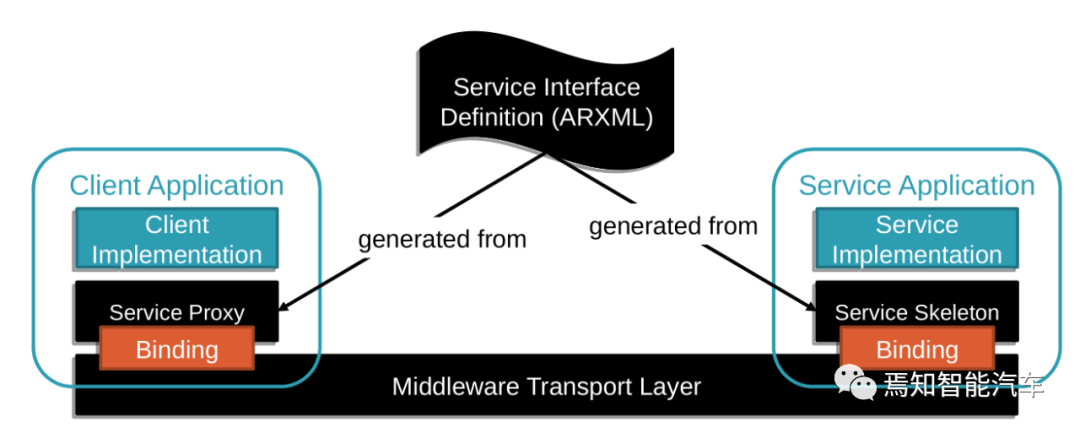
ARA的COM架构,还是Autosar定义的ARXML文件格式为核心
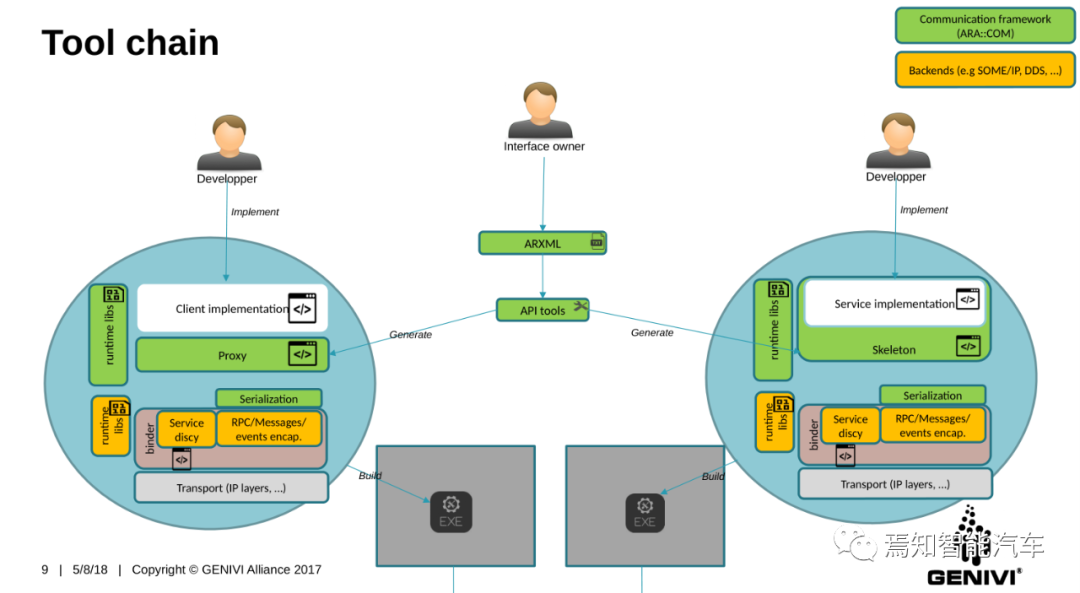
ARA工具链如上图
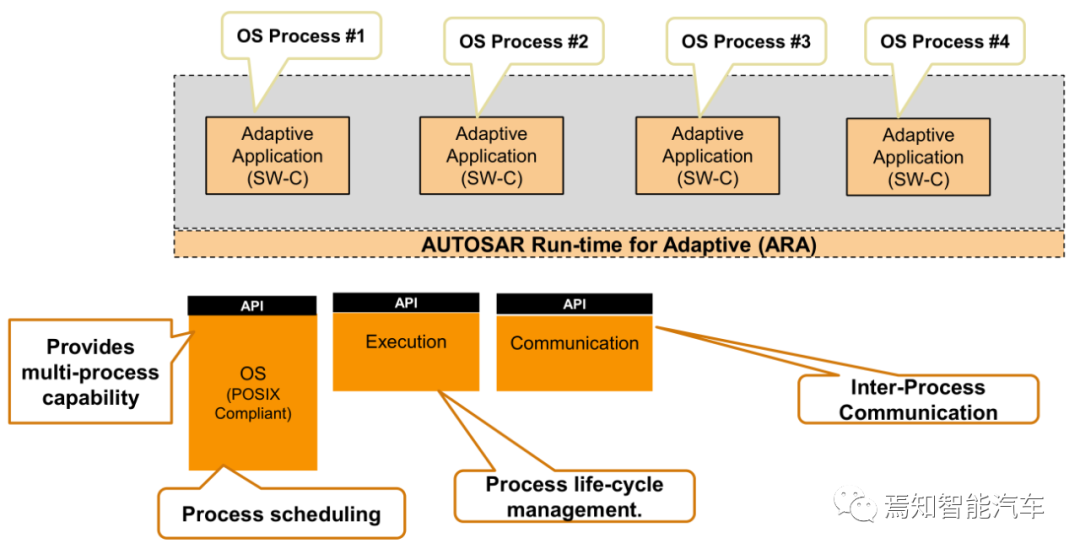
自适应Autosar关键点一:
Everything is a process .. as in “OS process”,一切都是一个进程,OS中的进程。
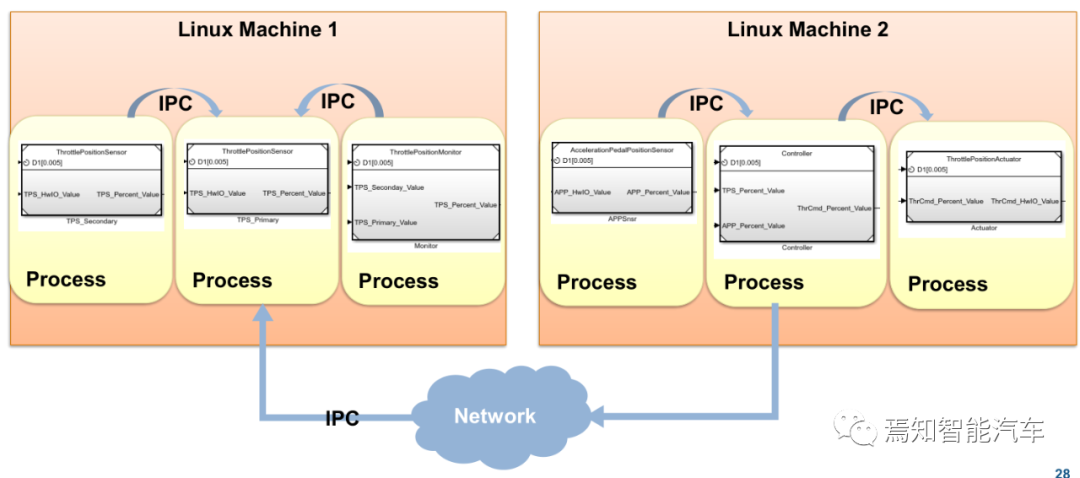
关键点二:面向服务的进程间通讯。
每个AA(自适应应用或者说APP)都作为一个独立的进程来实现,具有自己的逻辑内存空间和名称空间。一个AA可以包含多个进程,并且可以应用到一个AP(自适应平台)实例上,或者分布在多个AP实例上。从模块组织的角度来看,每个进程都是由操作系统在可执行文件中去实现的。可以从单个可执行文件实现多个进程。AA可以构成多个可执行文件。从操作系统的角度上看,一个AP模块只形成一组进程,每个进程包含一个或多个线程。这些进程通过IPC或任何其他可用的操作系统功能相互作用。但是,AA进程不能直接使用IPC,只能通过ARA(AUTOSAR Runtime for Adaptive applications) 的进行通信。
为了与AA交互,还需要使用IPC。要实现这一点,有两种可选设计。一种是“基于库”的设计,其中接口库由功能集群提供并链接到AA,直接调用IPC。另一种是“基于服务”的设计,流程使用通信管理功能,并有一个链接到AA的服务器代理库。代理库调用通信管理接口,该接口协调AA进程和服务器进程之间的IPC。实现定义决定了AA是只执行带有通信管理的IPC,还是通过代理库与服务器混合使用IPC。
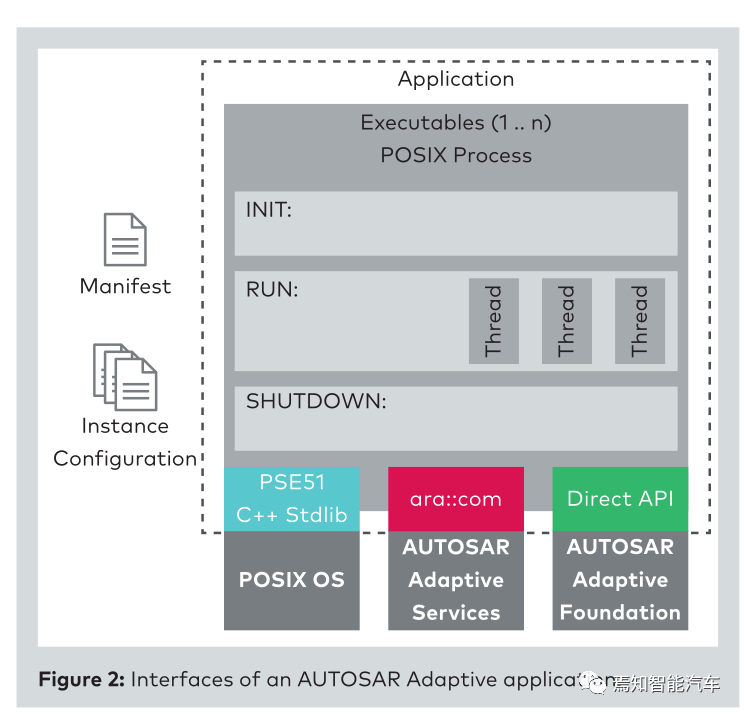
Application就是OS的一个一个进程,Autosar 采用一个Manifest用来配置管理这些进程信息,包含平台相关的信息,恢复操作以及与服务或库相关的依赖关系,Instance 配置文件主要包含静态的信息,这里会配合执行管理Exec、升级与配置管理UCM以及状态管理SM等来配合管理进程。自适应Autosar采用Proxy/Skeleton的通信架构,同时采用中间件SOME/IP
目前明确使用自适应Autosar的量产车就是大众的MEB平台。
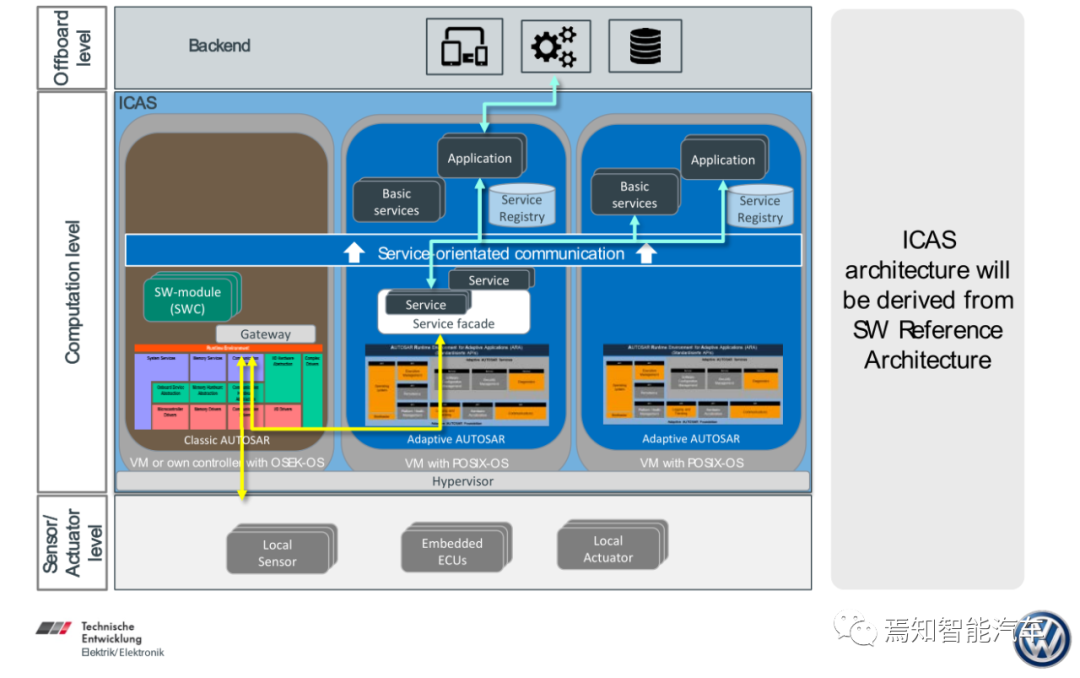
大众MEB的软件架构,POSIX可以是Linux、VxWorks、QNX、Integrity等。
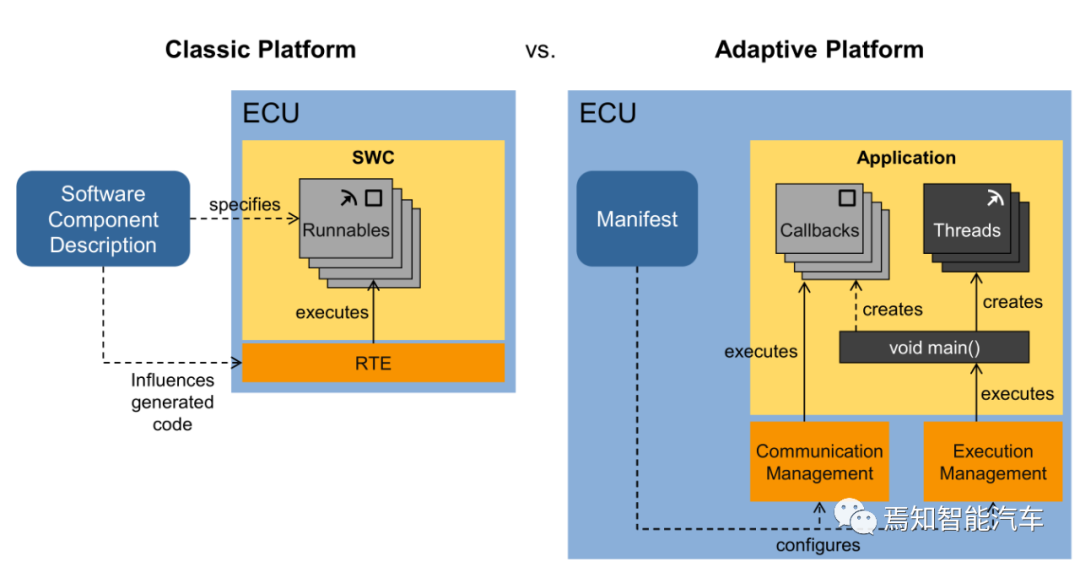
经典Autosar是将MCU硬件与软件层分离,提高软件复用率,减少工作量。自适应Autosar是将POSIX操作系统与上层API分离,让软件开发变成APP开发。一般情况下,POSIX系统的应用程序通过应用编程接口(API)而不是直接通过系统调用来编程(即并不需要和内核提供的系统调用来编程)。一个API定义了一组应用程序使用的编程接口。它们可以实现成调用一个系统,也可以通过调用多个系统来实现,而完全不使用任何系统调用也不存在问题。实际上,API可以在各种不同的操作系统上实现给应用程序提供完全相同的接口,而它们本身在这些系统上的实现却可能迥异。如下图,当应用程序调用printf()函数时,printf函数会调用C库中的printf,继而调用C库中的write,C库最后调用内核的write()。而经典Autosar的前身OSEK是不可能的。
从程序员的角度看,系统调用无关紧要,只需要跟API打交道。相反,内核只跟系统调用打交道,库函数及应用程序是怎么系统调用不是内核所关心的。
那个大众API就是大众所说的VW.OS。大众定义输入输出,第三方软件开发商基于这个定义开发APP。
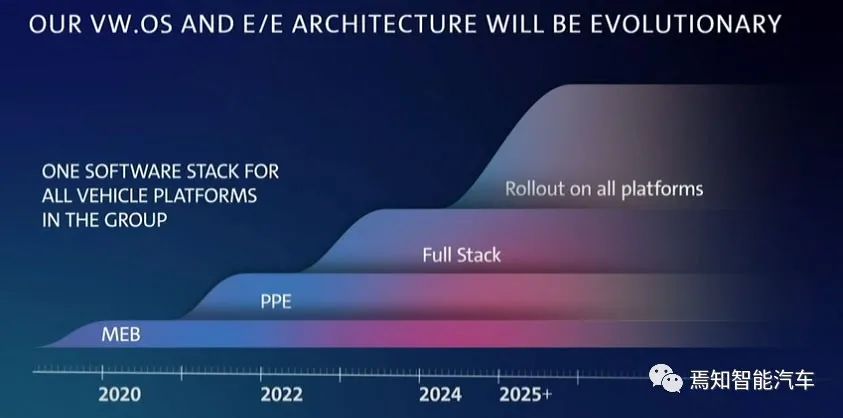
PPE是奥迪的下一代电动车平台,大众在2023年开始全部使用VW.OS。
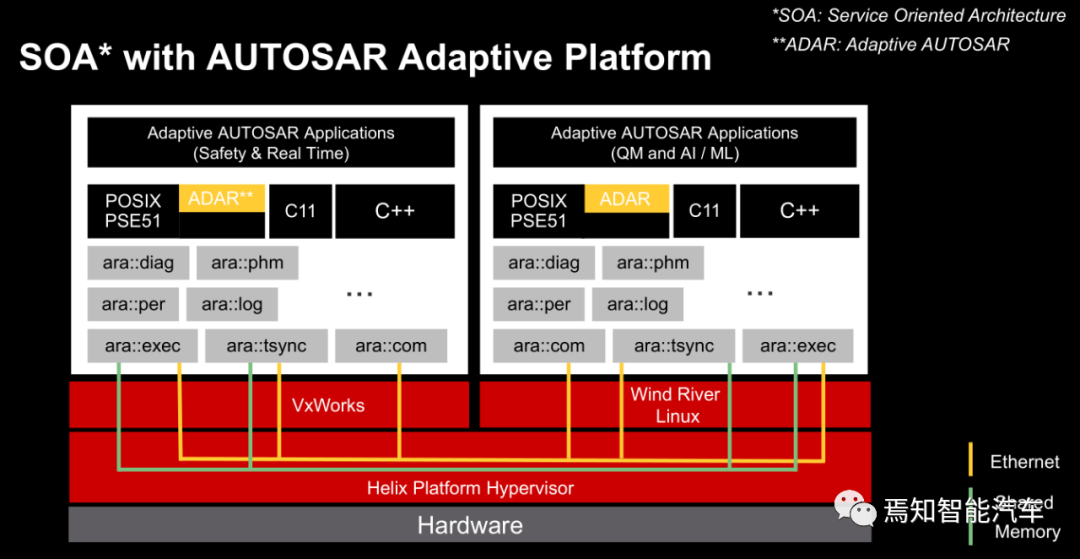
上图以WindRiver的操作系统为例,显示出Autosar的另一个优势,灵活架构。对于安全性和实时性要求高的领域采用VxWorks,对于要求不高也达不到高安全性的如深度学习(无功能安全要求)等采用Linux。在虚拟机上实现两个操作系统。顺便说一句Windriver是全球最大的商业RTOS供应商,最大的嵌入式商业Linux供应商。Windriver已经在2018年脱离英特尔独立。
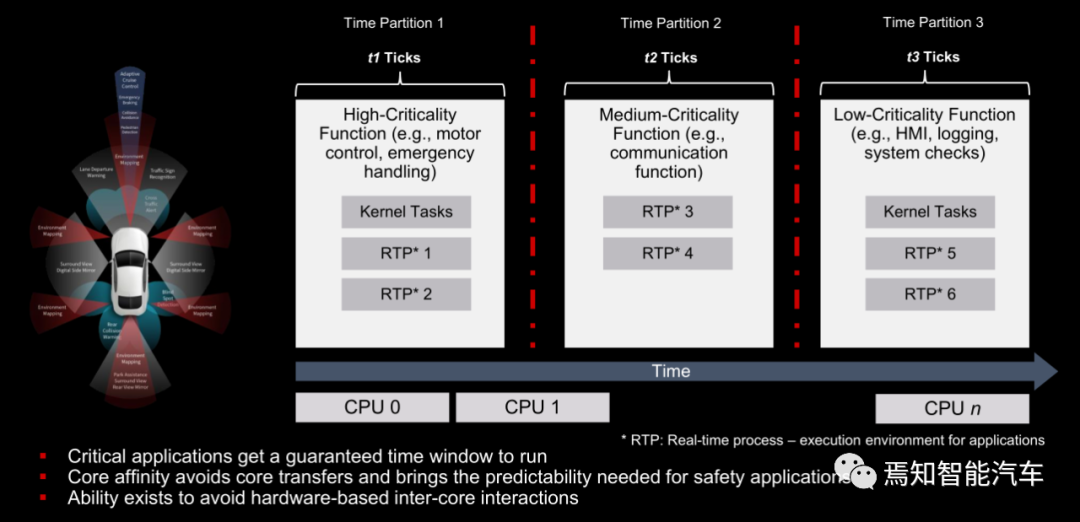
多种操作系统等于自适应Autosar可以构建时间分区架构。避免各个CPU核心之间的干扰。保证ADAS的安全性。
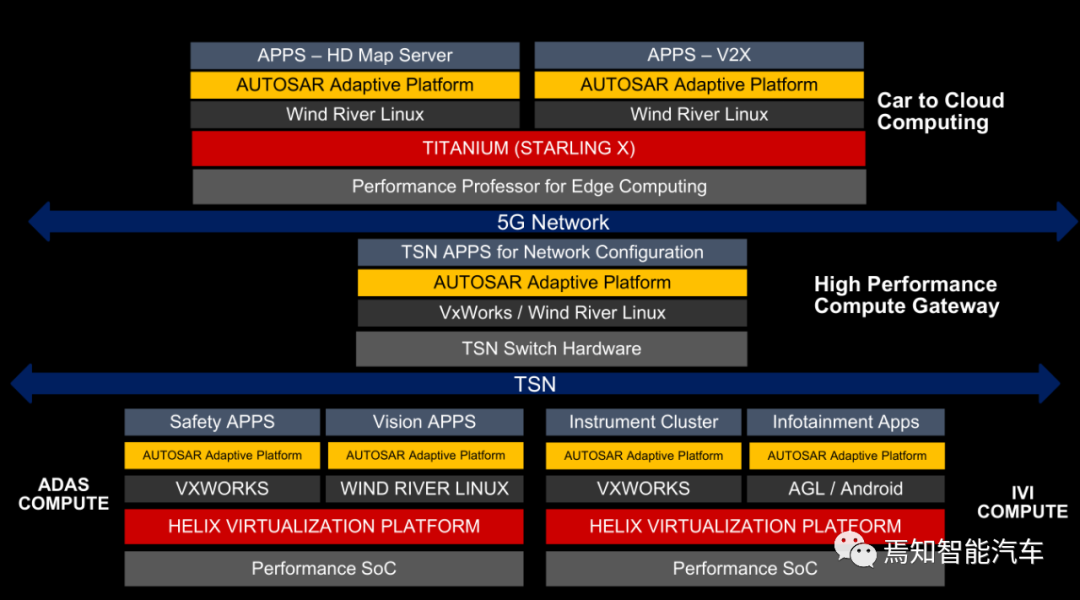
以Windriver产品为例L4级无人驾驶的自适应Autosar软件架构。对V2X 5G和高精度地图非常友好。
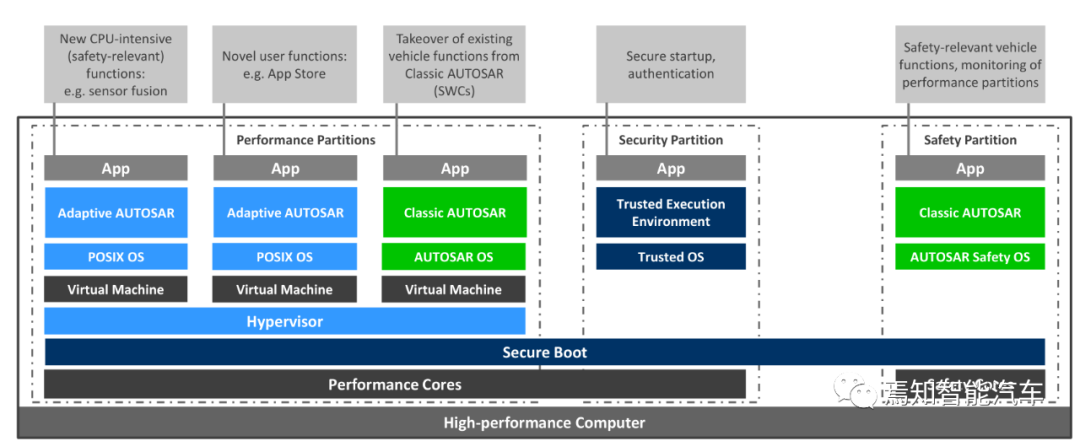
大陆汽车子公司Elektrobit的Corbos自适应Autosar架构
自适应Autosar将运行的硬件视为一台机器,实现一致的平台视图,而不考虑所使用的虚拟化技术。这台机器可能是一台真正的物理机器、一台完全虚拟化的机器、一个准虚拟化的操作系统、一个操作系统级的虚拟化容器或任何其他虚拟化环境。
在硬件上,可以有一台或多台机器,并且只有一个自适应Autosar服务在机器上运行。这种“硬件”上一般会有一个芯片,并承载着一台或多台机器。然而,如果自适应Autosar服务允许的话,多个芯片也可能形成一台机器。
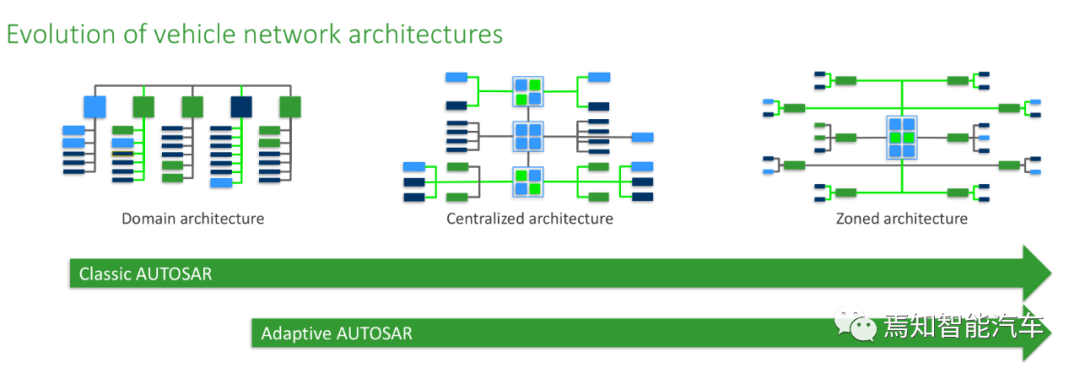
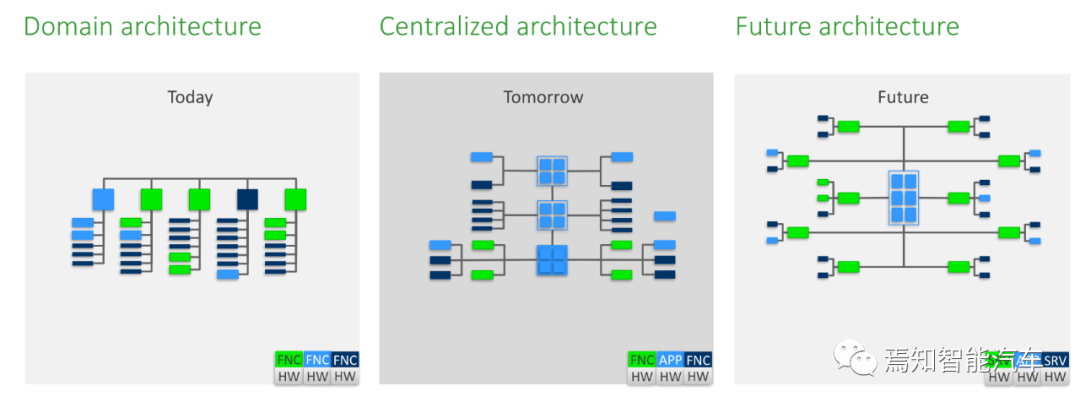
自适应Autosar也使得车内电子架构得以大幅度跃进,进入中央化和区域化时代
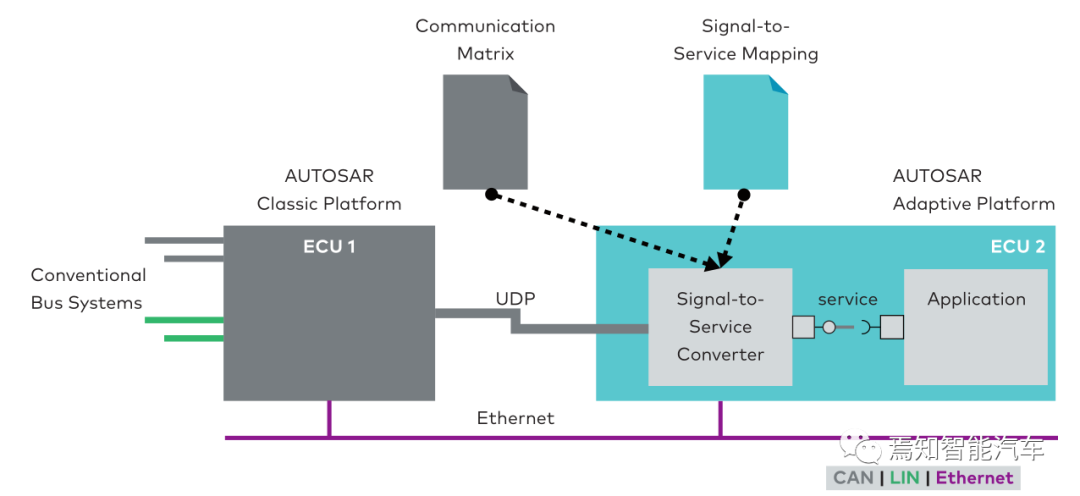
自适应Autosar平台与经典Autosar网关连接
自适应Autosar、车载TSN以太网、Zonal架构是三位一体的,也是未来汽车电子的核心。不过自适应Autosar目前对中小企业来说恐怕不合适,标准未完善,一次性投入过高,开发难度过高,开发周期长。
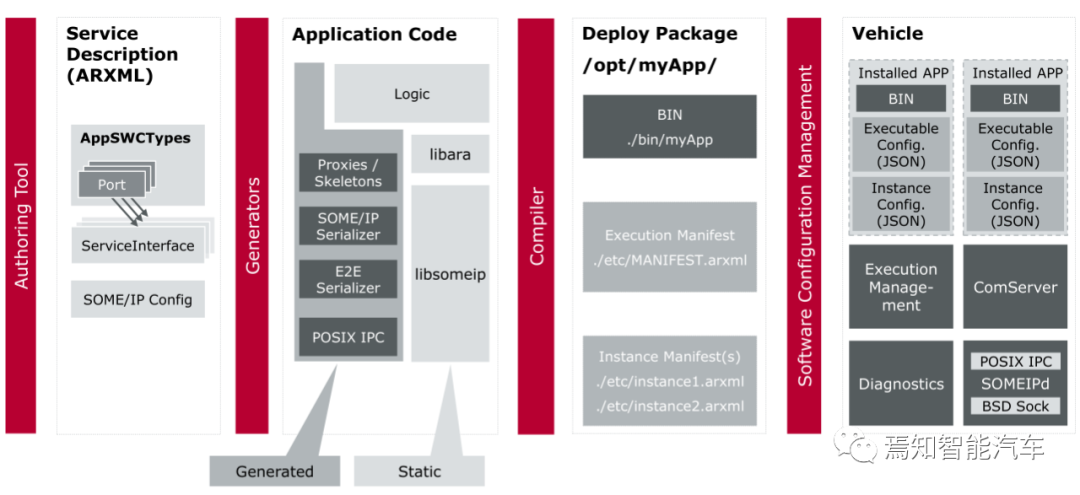
上图为Vector的自适应Autosar产品Adaptice MICROSAR 配置开发工具和工作流。
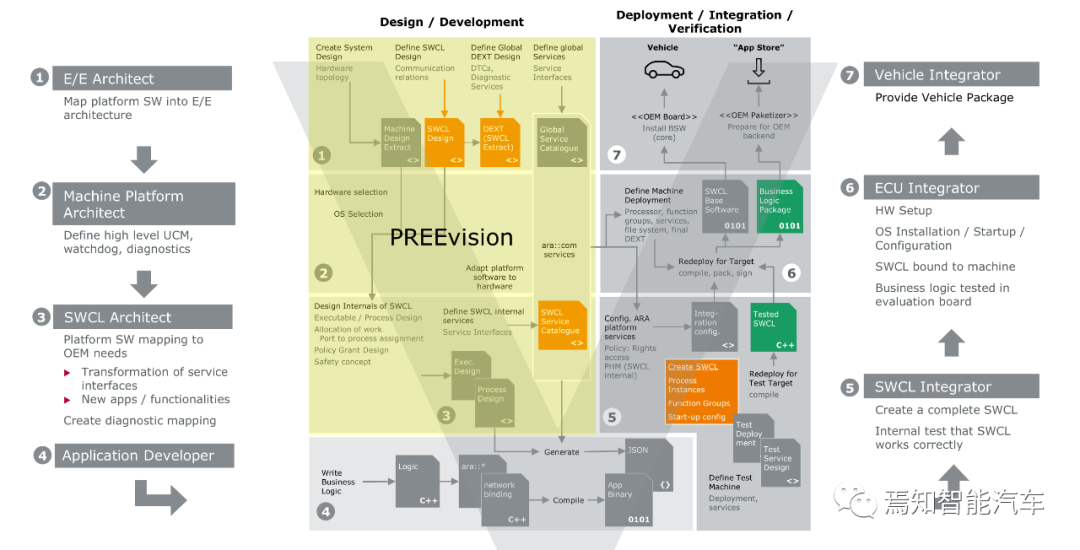
上图为Vector推荐的自适应Autosar开发流程图,与经典Autosar不同,自适应Autosar要求最好和整车电子架构一起开发,因为自适应Auotsar是整车电子架构的核心底层。因此自适应Autosar常常与整车电子设计架构软件PREEvision捆绑。
PREEvision分4层
需求层(Requirements Layer):该层需要导入需求开发的输出物:需求说明书,作为工程设计的指导文件。需求层一般由三部分组成:Requirement、Customer Feature、FFN。
功能逻辑层:该层用于描述系统的逻辑功能关系,即系统功能的模块框架以及各模块之间的接口关系。主要包括两个层面的内容:系统逻辑架构层和软件架构层。前者关注系统功能实现的所有逻辑关系;后者关注系统实现过程中的软件相关的逻辑关系。内容包括逻辑传感器、功能块、逻辑执行器等功能模块,以及各功能模块之间的信息交互接口(Port)。当各模块之间的端口通过信息交互接口连接后,相应模块就能进行数据和控制信息的交换。在功能逻辑架构中,开发人员可以方便的查看各个功能模块之间的逻辑关系。
硬件架构层(Hardware Architecture Layer):该层主要包括网络层(Network Layer)、部件层(Components Layer)和线路原理层(Schematic/Circuit Layer)。网络层主要描述各个部件之间的逻辑链接方式,如总线系统、传统连接、电源供应和地线连接等(还会在线路原理层进行进一步细化);部件层描述每个部件内部构成及其对外接口的详细信息;线路原理层描述网络层中逻辑连接的具体实现情况,如:具体导线、线缆连接方式、保险继电器盒内部结构等。
E/E架构
先进E/E架构实际就是车载以太网和自适应Autosar的具体应用。无论是软件定义汽车还是服务架构导向,其最核心的支柱也是车载以太网和自适应Autosar。
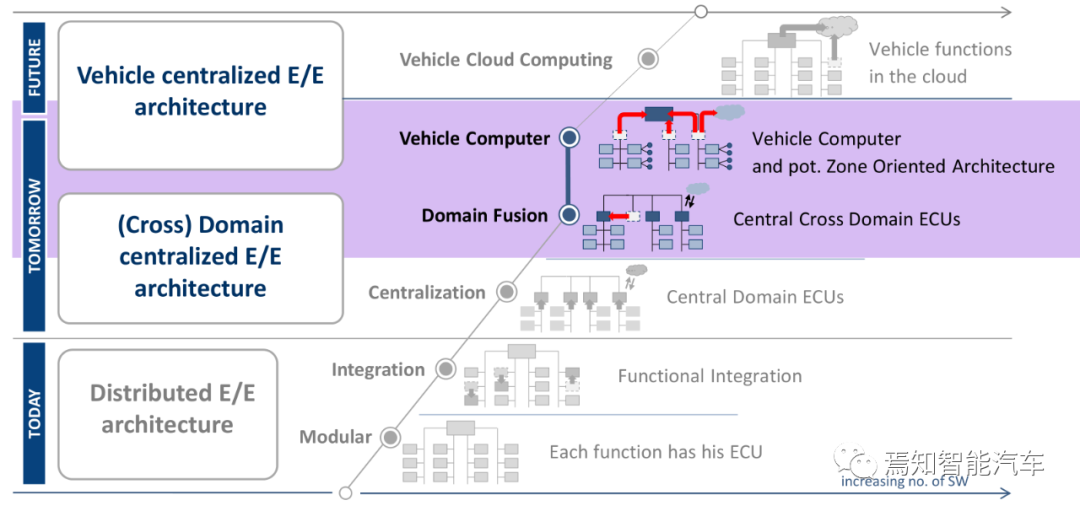
上图为汽车E/E架构演进路线图,资料来源:博世
Vehicle Computer阶段实际就是Zonal架构,Centralization中央化就是域控制器架构。这都离不开TSN。
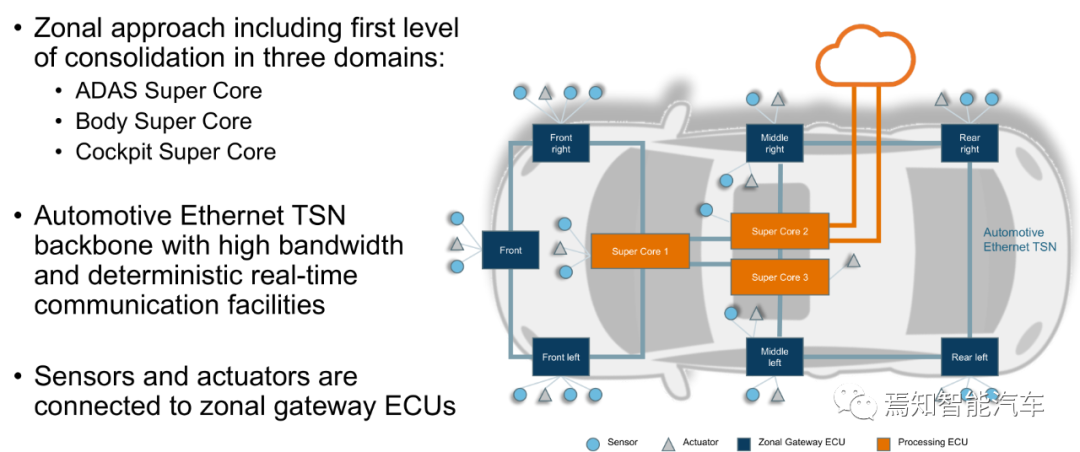
TSN为骨干网的Zonal架构
Zonal架构可算是SOA架构的典型代表,可以说SOA架构离不开TSN。ADAS/座舱/车身三个运算单元类似大众MEB里的ICAS。
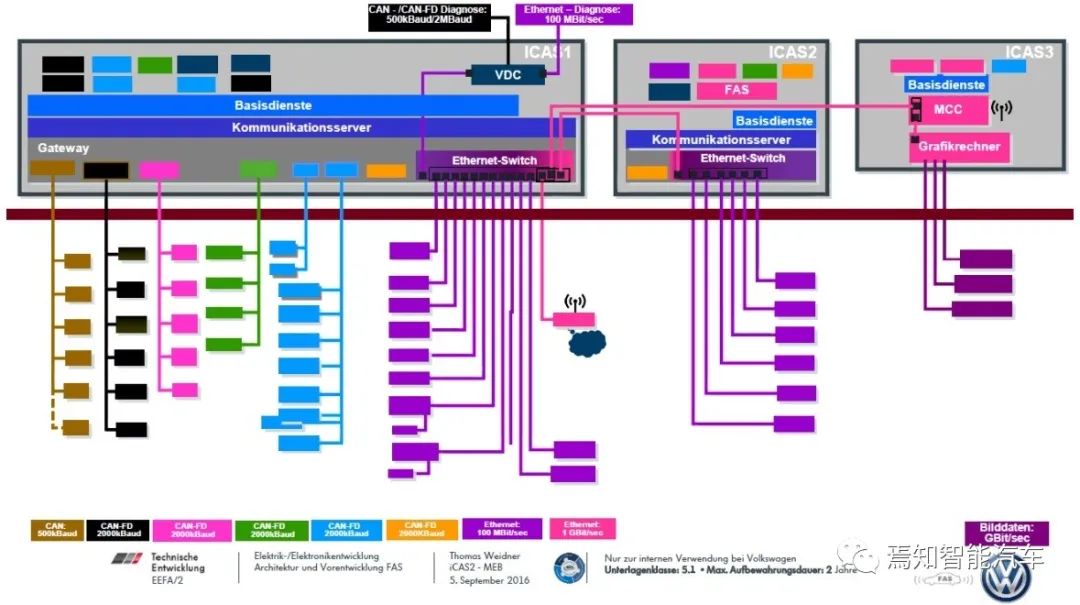
大众的MEB架构
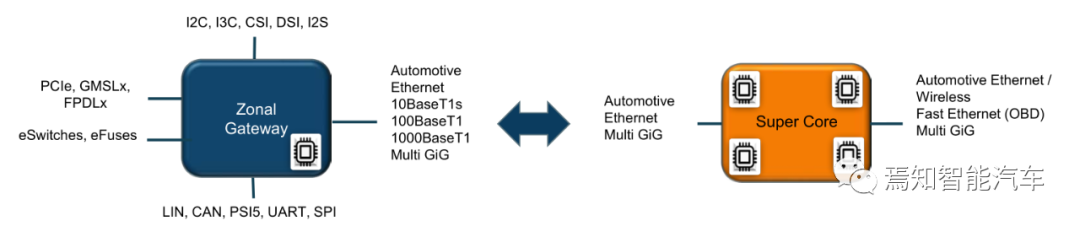
网关中最核心的则是对应TSN的交换机
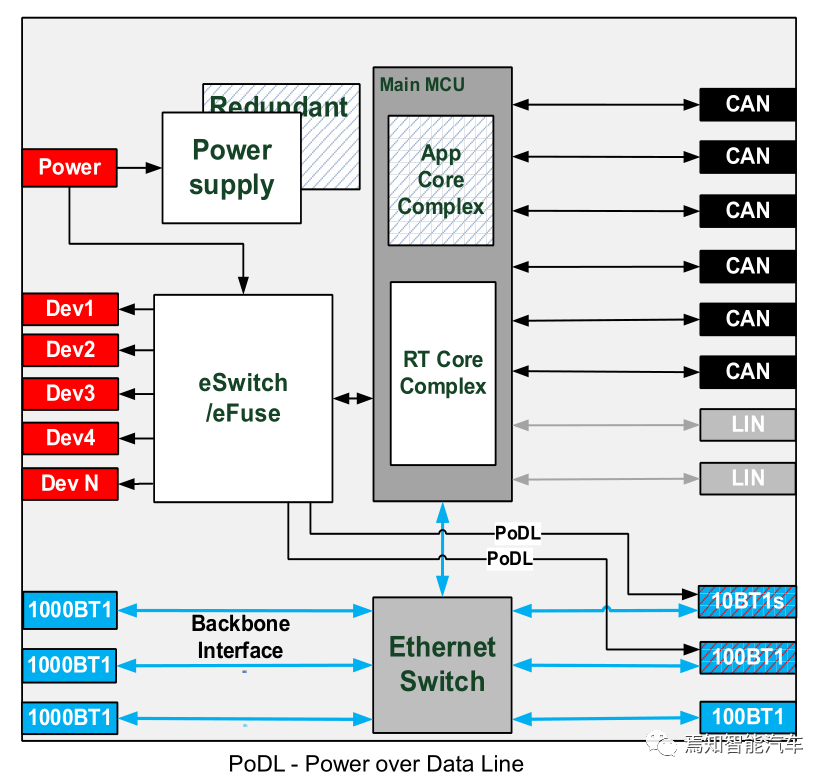
Zonal网关的内部框架图
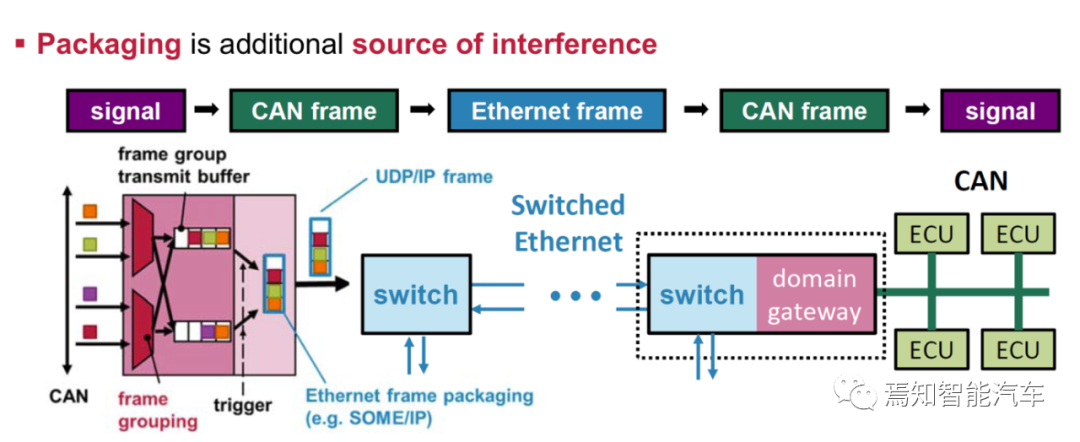
CAN到以太网,即SOME/IP-UDP-IP-MAC,或TCP-IP-MAC。这也意味着经典Autosar或自适应Autosar不可或缺。TSN、Autosar是SOA不可或缺的成分。
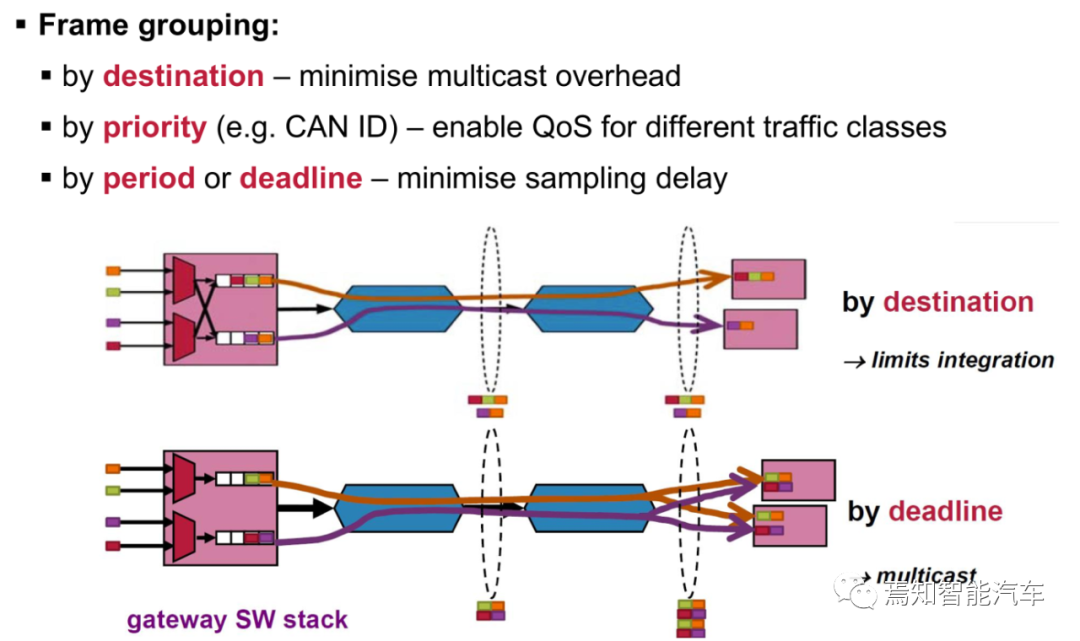
帧的分组,包括目的地,优先级,截至周期等
高性能处理器

上图为ARM在2017年投资者大会上发布的内容,ARM预计2020年顶级座舱的算力是50K DMIPS
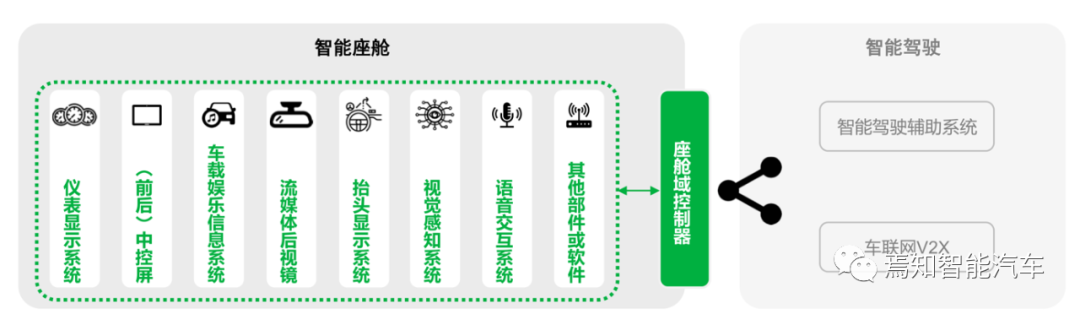
智能座舱典型功能,资料来源:IHS Markit
对于座舱来说,决定其功能和性能的关键是主SoC的算力,衡量CPU算力的单位主要是DMI。
PS,DMIPS是DhrystoneMillion Instructions Per Second的缩写,每秒处理的百万级的机器语言指令数。基本上SoC高于20000DMIPS才能流畅地运行智能座舱的主要功能(AR导航或云导航、360全景、播放流媒体、AR-HUD、多操作系统虚拟机等),GPU方面,只需要100GFLOPS的算力就可以支持3个720P屏幕,因此简单定义一下,CPU高于20000DMIPS,GPU高于100GFLOPS的SoC的座舱就是智能座舱。
程序编译和运行过程中,代码会经过编译器转化成机器可以理解的指令。CPU每个指令周期分为取指令、指令译码、指令执行三个过程,只有在指令执行时才真正有效,在取指令和指令译码时,CPU时间是白白浪费的,而同样的运算在不同架构不同指令集需要的指令数也不一样。
不同的CPU指令集不同、硬件加速器不同、CPU架构不同,导致不能简单的用核心数和CPU主频来评估性能,所以出了一个跑分算法叫Dhrystone:程序用来测试CPU整数计算性能,其输出结果为每秒钟运行Dhrystone的次数,即每秒钟迭代主循环的次数。
Dhrystone所代表的处理器分数比MIPS(million instructionsper second 每秒钟执行的指令数)更有意义,因为在不同的指令系统中,比如RISC(Reduced Instruction Set Computer精简指令集计算机)系统和CISC(ComplexInstruction Set Computer复杂指令集计算机)系统,Dhrystone的得分更能表现其真正性能。由于在一个高级任务中,RISC可能需要更多的指令,但是其执行的时间可能会比在CISC中的一条指令还要快。由于Dhrystone仅将每秒钟程序执行次数作为指标,所以可以让不同的机器用其自身的方式去完成任务。另一项基于Dhrystone的分数为DMIPS(DhrystoneMIPS),其含义为每秒钟执行Dhrystone的次数除以1757(这一数值来自于VAX 11/780机器,此机器在名义上为1MIPS机器,它每秒运行Dhrystone次数为1757次)。
影响CPU算力最关键的参数是Decode Wide译码宽度,译码宽度可简单等同于每周期指令数量即IPC,即每个周期完成多少个指令。
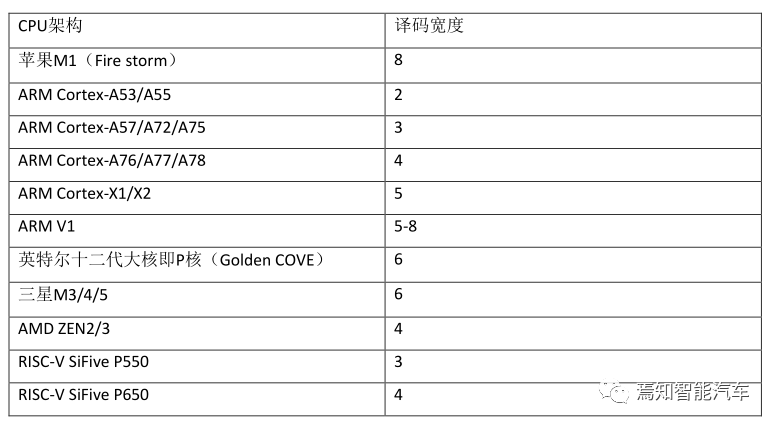
译码宽度的增加是非常困难的,不是想多少就多少的,简单来说每增加一位宽度,系统复杂度会提高15%左右,裸晶面积也就是成本会增加15-20%左右。如果简单地增加译码宽度,那么成本也会增加,厂家就缺乏更新的动力,所以ARM的做法是配合台积电和三星的先进工艺,利用晶体管密度的提高来减少裸晶面积降低成本,因此ARM的每一次译码宽度升级都需要先进制造工艺的配合,否则成本增加比较多。同时ARM也从商业角度考虑,每年小升级一次,年年都有提升空间。8位宽度是目前的极限,苹果一次到位使用8位宽度,缺点是必须使用台积电最先进的制造工艺,但苹果依然使用的是ARM的指令集。
此外,RISC和CISC还有区别,CISC增加宽度更难,但CISC的1位宽度基本可顶RISC的1.2-1.5位。英特尔是有实力压制苹果的,就是制造工艺不如台积电。CISC指令的长度不固定,RISC则是固定的。因为长度固定,可以分割为8个并行指令进入8个解码器,但CISC就不能,它不知道指令的长度。因此CISC的分支预测器比RISC要复杂很多,当然目前RISC也有长度可变的指令。遇到有些长指令,CISC可以一次完成,RISC因为长度固定,就像公交车站,一定要在某个站停留一下,肯定不如CISC快。也就是说,RISC一定要跟指令集,操作系统做优化,RISC是以软件为核心,针对某些特定软件做的硬件,而CISC相反,他以硬件为核心,针对所有类型的软件开发的。
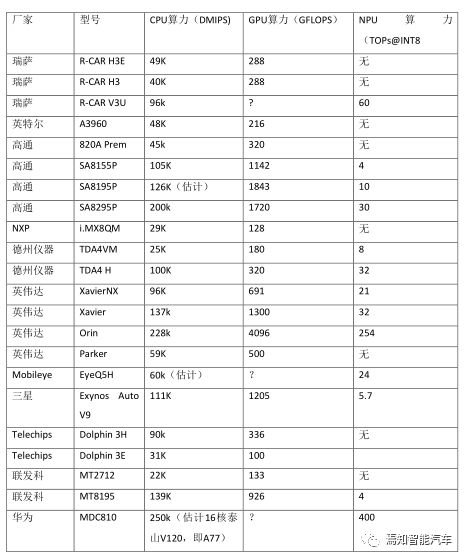
目前与未来常见座舱与智能驾驶SoC算力统计
审核编辑:刘清
-
关于域控制器的基础知识分享2024-01-24 2583
-
汽车五大域控制器有哪些?汽车域控制器和ecu的区别2023-11-23 11303
-
动力域控制器的功能和测试项目2023-10-23 4507
-
域控制器上AUTOSAR AP的优势和挑战2023-08-11 1055
-
域控制器是什么 域控制器介绍2023-07-25 6925
-
整车域控制器的经典五域详解2023-06-25 3109
-
什么是域控制器?OEM为什么要转向域控制器?2023-05-04 2115
-
什么是域控制器?域控制器市场概述2022-11-30 4083
-
NXP车身域和区域控制器介绍2022-11-15 1975
-
介绍汽车区域控制器的一些关键技术和MCU解决方案2022-10-26 3246
-
车身域控制器的原理是什么呢2022-02-14 2479
-
【HarmonyOS HiSpark AI Camera】域控制器预言开发2020-11-23 666
-
重置域控制器管理员密码的几个步骤分析2019-07-15 3545
-
基于Zigbee的路灯区域控制器设计2016-01-04 803
全部0条评论

快来发表一下你的评论吧 !
