

NeuralLift-360:将野外的2D照片提升为3D物体
描述
摘要
虚拟现实和增强现实(XR)带来了对3D内容生成的不断增长需求。然而,创建高质量的3D内容需要人类专家进行繁琐的工作。在本文中,我们研究了将单个图像提升为3D对象的具有挑战性的任务,并首次展示了能够生成与给定参考图像相对应的具有360°视图的可信3D对象。通过条件化参考图像,我们的模型可以满足从图像合成物体新视角的永恒好奇心。我们提出了NeuralLift-360,一种新颖框架,利用深度感知神经辐射场生成可信3D对象,并通过CLIP引导扩散先验学习概率驱动3D提升,并通过比例不变深度排名损失减轻深度误差。我们在真实和合成图像上进行了全面实验,在这些实验中,NeuralLift-360优于当前最先进方法。
主要贡献
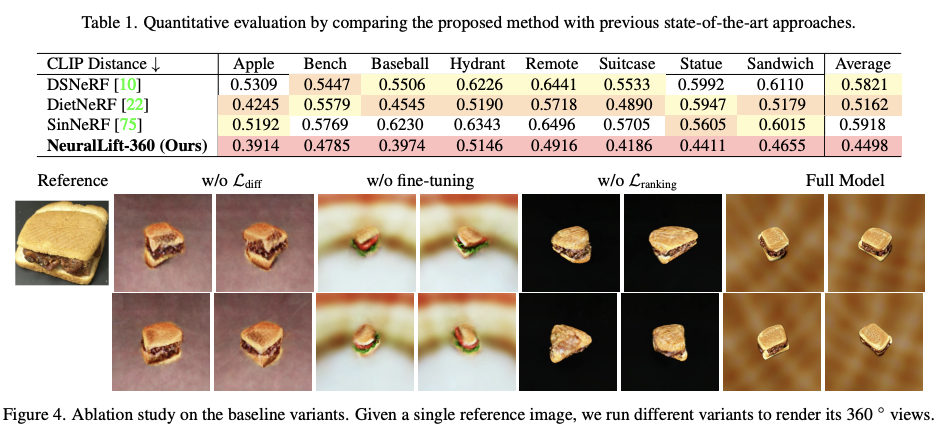
• 针对野外的单张图片,我们展示了将其提升到3D的有前景的结果。我们使用NeRF作为有效的场景表示,并整合来自扩散模型的先验知识。
• 我们提出了一种以CLIP为引导的采样策略,有效地将扩散模型的先验知识与参考图像结合起来。
• 当参考图像难以精确描述时,我们在保持其生成多样内容以指导NeRF训练的能力的同时,对单张图像进行扩散模型的微调。
• 我们引入了一种使用排名信息的尺度不变深度监督。这种设计减轻了对准确多视角一致深度估计的需求,并扩大了我们算法的应用范围。
主要方法
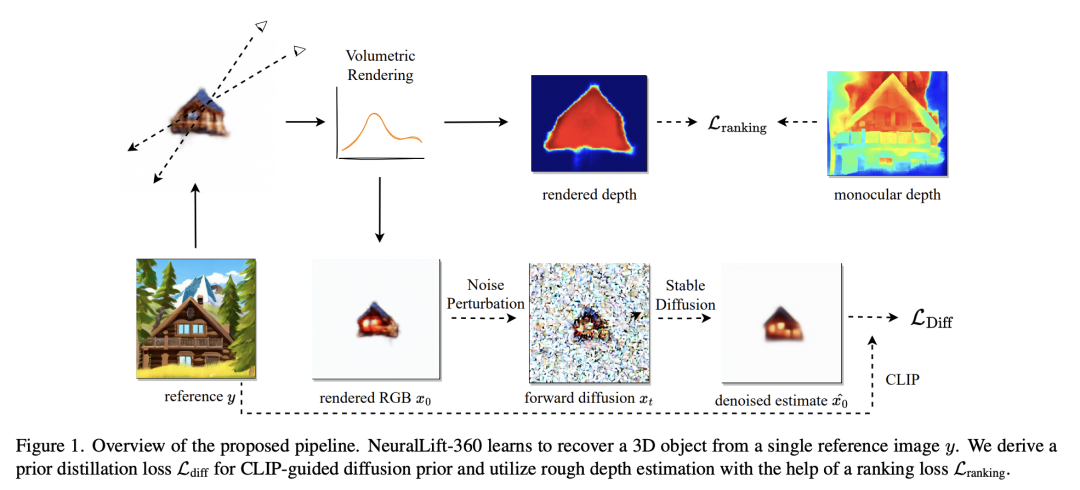
1.从单个2D图像中生成3D点云:首先,使用一个预训练的2D图像到3D点云模型来生成初始点云。然后,使用一个深度感知神经辐射场来对点云进行细化和修正。具体地,该神经辐射场将每个点的深度值作为输入,并输出一个向量场,该向量场将每个点移动到其正确的位置。
2.从3D点云中生成可渲染的3D网格:使用一个基于深度学习的方法来将点云转换为可渲染的3D网格。具体地,该方法使用一个编码器网络将3D点云编码为特征向量,并使用一个解码器网络将特征向量解码为可渲染的3D网格。
3.从可渲染的3D网格中生成360°视图:使用一个基于深度学习的方法来生成与给定参考图像相对应的具有360°视图的可信3D对象。具体地,该方法使用一个编码器网络将参考图像编码为特征向量,并使用一个解码器网络将特征向量解码为360°视图。
4.使用CLIP引导扩散先验学习概率驱动3D提升:使用一个基于扩散的方法来生成3D对象,并使用CLIP模型来指导扩散过程。具体地,该方法使用一个初始的3D对象,并通过多次迭代来扩散该对象。在每次迭代中,使用CLIP模型来计算当前3D对象与参考图像之间的相似度,并将相似度作为概率分布来指导扩散过程。
5.使用比例不变深度排名损失减轻深度误差:使用一个比例不变深度排名损失来训练模型,以减轻深度误差。具体地,该损失函数将每个像素的深度值与其在图像中的排名相关联,并使用比例不变的方式来计算损失。这种方法可以减轻深度误差,并提高模型的性能。
主要结果


审核编辑 :李倩
-
请问怎么才能将AD中的3D封装库转换为2D的封装库?2019-06-05 5125
-
为什么3D与2D模型不能相互转换?2019-09-20 2469
-
如何促使2D和3D视觉检测的性能成倍提升?2021-02-22 4284
-
视觉处理,2d照片转3d模型2023-05-21 23710
-
2D到3D视频自动转换系统2018-03-06 1843
-
适用于显示屏的2D多点触摸与3D手势模块2018-06-06 6469
-
如何把OpenGL中3D坐标转换成2D坐标2018-07-09 9477
-
3D 机器视觉为什么将逐步取代 2D 识别技术?2020-08-21 6114
-
阿里研发全新3D AI算法,2D图片搜出3D模型2020-12-04 4912
-
3d人脸识别和2d人脸识别的区别2022-02-05 54666
-
探讨一下2D和3D拓扑绝缘体2022-11-23 5225
-
将2D/3D图表和图形添加到WindowsForms应用程序中2023-06-15 9228
-
2D与3D视觉技术的比较2023-12-21 3427
-
一文了解3D视觉和2D视觉的区别2023-12-25 5780
-
2D、2.5D与3D封装技术的区别与应用解析2026-01-15 2005
全部0条评论

快来发表一下你的评论吧 !
