

基于HMM的连续小词量语音识别系统
模拟技术
描述
嵌入式语音识别系统是应用各种先进的微处理器在板级或是芯片级用软件或硬件实现的语音识别。嵌入式技术与语音识别技术相结合,能使人们甩掉键盘,通过语音命令对智能化终端进行操作,人与智能化终端之间的这种自然快捷的交互方式有助于提高人机交互的效率,以适应嵌入式平台存储资源少,实时性要求高的特点,增强人对智能化设备的控制,同时,在语音识别技术发展过程中又以HMM的广泛应用为特点。文章对语音识别算法部分和硬件部分做了分析与改进,采用ARMS3C2410微处理器作为主控制模块,采用UDA1314TS音频处理芯片作为语音识别模块,利用HMM声学模型及Viterbi算法进行模式训练和识别,设计了一种连续的、小词量的语音识别系统。
1 Markov链及隐马尔可夫模型(HMM)
语音信号是一个可观察的序列,在足够小时间段上特性近似于稳定,但其总的过程可看作依次从相对稳定的某一特性过渡到另一特性,在整个分析区间内可将许多线性模型串接起来,这就是Markov链。Markov链是Markov随机过程的特殊情况,即Markov链式状态和时间参数都离散的Markov过程。
隐马尔可夫模型是对语音信号的时间序列结构建立统计模型,可将之看作一个数学上的双重随机过程:一个是用具有有限状态数的Mar-kov链来模拟语音信号统计特性变化的隐含的随机过程,另一个是与Mark-ov链的每一个状态相关联的观测序列的随机过程。前者通过后者表现出来,但前者的具体参数是不可测的。
一般来说,一个HMM是一个双重随机过程,由下述五个参数描述:

2 基于HMM的语音识别系统实现
人的言语过程实际上就是一个双重随机过程,语音信号本身是一个可观测的时变序列,是由大脑根据语法知识和言语需要(不可观测的状态)发出音素的参数流。HMM合理地模仿了这一过程,很好地描述了语音信号的整体非平稳性和局部平稳性,是较为理想的一种语音模型。从整段语音来看,人类语音是一个非平稳的随机过程,但是若把整段语音分割成若干短时语音信号,则可认为这些短时语音信号是平稳过程,就可以用线性手段对这些短时语音信号进行分析。若对这些语音信号建立隐马尔可夫模型,则可以辩识具有不同参数的短时平稳信号段,并可以跟踪它们之间的转化,从而解决了对语音的发音速率及声学变化建立模型的问题。
语音识别系统首先通过芯片内的A/D转换器将模拟语音信号转化为数字语音信号,然后对数字语音信号进行处理(信号加窗、过滤),得到干净的语音信号,再通过特征提取过程做出特征矢量,提取语音特征,最后由识别过程对说话人语音进行识别,得出识别结果。总体来说,整个识别过程分为语音信号的预处理、语音信号的特征提取、语音库的建立以及语音信号的识别等几个主要阶段,如图1所示。
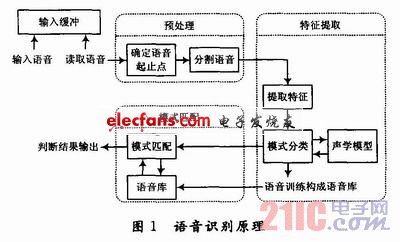
语音识别过程分为两个部分:一是HMM训练过程,得到HMM语音识别模型,即建立基本识别语音库;二是HMM识别过程,得到语音识别结果。
2.1 HMM训练
HMM算法是解决识别问题的一种常用方法。一个HMM模型中有N个状态,对于一个长度为T的观察序列,如果按照定义来计算,需要2TNT次运算,这种运算量是不能接受的,而HMM算法可以简化这个过程。



如果P(O/λZ)和

距离太大,则返回步骤(2),反复迭代运算,直到HMM模型参数不再发生明显的变化为止。
2.2 HMM模型识别
HMM模型的输出概率用Viterbi算法计算,因为概率值一般都远小于1,这里用取对数后的概率作为输出值:

以上式中δt(i)表示t时刻第i个状态的累积输出概率;φt(i)表示t时刻第i个状态的前续状态号;

为最优状态序列中t时刻所处的状态;P*为最终的输出概率。
3 实验结果
系统首先通过语音录入模块的麦克风将语音信号输入UDA1341 TS数字音频处理芯片,通过S3C2410向UDA1341数字音频处理芯片发送指令,数字音频处理芯片由内部A/D对语音信号进行采样,调用语音压缩算法对语音信号进行压缩,并调用语音识别函数API对输入语音进行基于模式匹配算法的语音识别,最终UDA1341数字音频处理芯片将识别结果通过I/O传送到ARM S3C2410,S3C2410接收到识别结果后,根据不同的识别结果再向UDA1341 TS发送不同指令,以此实现语音识别系统的功能。
系统采用三星的S3C2410作为嵌入式CPU,这是一款高性价比、低功耗、高性能、高集成度的CPU,基于ARM9核,主频为203 MHz,专为网络通信和手持设备而设计,能满足语音识别系统中的低成本、低功耗、高性能、小体积的要求。
实验采用10字中文数码,分别在室外环境和实验室环境下测试,结果如表1所示。

通过测试表明,在实验室环境下该系统在UDA1314TS DSP芯片上得到的结果比较令人满意,具有良好的鲁棒性,识别率达到实用要求,但在室外较高噪音条件下的识别率相对实验室环境下有一定差距,满足语音识别基本要求。
4 结论
本文系统采用隐马尔可夫模型的语音识别算法,能够对小词量、连续语音进行识别,识别率较高。ARMS3C2410微处理器和UDA1314TS音频处理芯片的结合应用,能使本语音识别系统具有较强的实时性。体积小,携带方便,使用灵活,可移植性强的特点使系统在进一步改进和发展后能够用于工业语音控制领域中,还可用于声控玩具、声控设备等人们的日常生活中。
-
基于OMAP5912的嵌入式非特定人连续语音识别系统2023-10-09 562
-
基于HMM的语音识别系统是怎么训练的2021-12-23 2509
-
怎样去搭建一个基于kaldi的在线语音识别系统2021-07-29 2219
-
基于DSP的汉字语音识别系统如何实现2021-03-12 3204
-
基于UniSpeech芯片和语音识别算法实现嵌入式语音识别系统的设计2020-10-04 5359
-
使用紧急呼叫和DSP的语音识别系统2019-11-04 2544
-
语音识别的现状如何?2019-10-08 3432
-
语音识别系统功能_语音识别系统的应用2019-10-01 6291
-
怎么设计基于嵌入式系统的语音口令识别系统?2019-09-03 3126
-
基于语音特征聚类的HMM语音识别系统研究姚敏锋2017-03-15 1037
-
一种基于DSP的汉字语音识别系统设计2014-12-16 3837
-
GMM-HMM语音识别原理详解2014-12-15 20351
-
基于LabVIEW的语音识别系统2013-05-16 5815
-
交互式语音识别系统研究2011-05-28 1617
全部0条评论

快来发表一下你的评论吧 !
