

高性能计算关键组件核心知识
描述
高性能计算(缩写 HPC) 指通常使用很多处理器(作为单个机器的一部分)或者某一集群中组织的几台计算机(作为单个计 算资源操作)的计算系统和环境。有许多类型的 HPC 系统,其范围从标准计算机的大型集群,到高度专用的硬件。
本文参考自“高性能计算知识汇总”及“OpenMP编译原理及实现”,高性能计算应用特征剖析、超级计算机研究报告、深度报告:GPU研究框架、《高性能计算和超算专题》。
大多数基于集群的 HPC 系统使用高性能网络互连,比如那些来自 InfiniBand 或 Myrinet 的网络互连。基本的网络拓扑和组织可以使用一个简单的总线拓扑,在性能很高的环境中,网状网络系统在主机之间提供较短的潜伏期,所以可改善总体网络性能和传输速率。
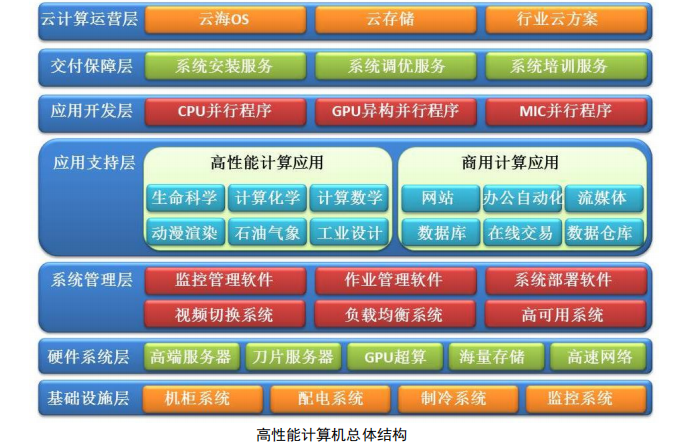
高性能计算硬件结构和总体结构
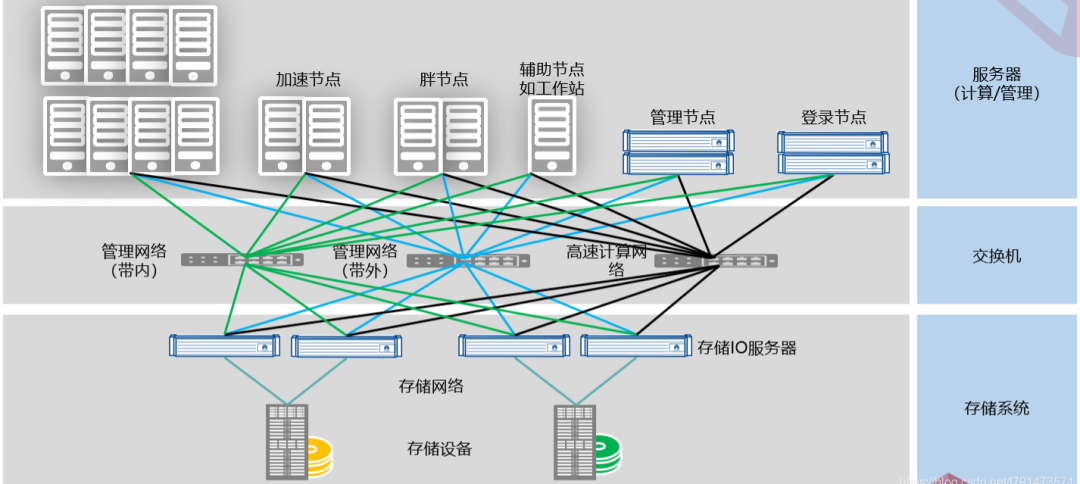
高性能计算拓扑结构,从硬件结构上,高性能计算系统包含计算节点、IO节点、登录节点、管理节点、高速网络、存储系统等组成。
高性能计算集群性能指标
FLOPS 是指每秒浮点运算次数,Flops 用作计算机计算能力的评价系数。根据硬件配置和参数可以计算出高性能计算集群的理论性能。
1) CPU 理论性能计算方法(以 Intel CPU 为例)
单精度:主频*(向量位宽/32)*2 双精度:主频*(向量位宽/64)*2 2 代表乘积指令
2) GPU 理论性能计算方法(以 NVIDIA GPU 为例)
单精度:指令吞吐率*运算单元数量*频率
3) MIC 理论性能计算方法(以 Intel MIC 为例)
单精度:主频*(向量位宽/32)*2 双精度:主频*(向量位宽/64)*2 2 代表乘积指令 通过利用测试程序对系统进行整体计算能力进行评价。
Linapck 测试:采用主元高斯消去法求解双精度稠密线性代数方程组,结果按每秒浮点运算次数(flops)表示。
HPL:针对大规模并行计算系统的测试,其名称为 HighPerformanceLinpack(HPL),是第一个标准的公开版本并行 Linpack 测试软件包。用于 TOP500 与国内 TOP100 排名依据。
同构计算节点
同构计算节点是指集群中每个计算节点完全有 CPU 计算资源组成,目前,在一个计算节点上可以支持单路、双路、四路、八路等 CPU 计算节点。
异构计算节点
异构计算技术从 80 年代中期产生,由于它能经济有效地获取高性能计算能力、可扩展性好、计算资源利用率高、发展潜力巨大,目前已成为并行/分布计算领域中的研究热点之一。异构计算的目的一般是加速和节能。目前,主流的异构计算有:CPU+GPU,CPU+MIC,CPU+FPGA
常见的并行文件系统
PVFS:Clemson 大学的并行虚拟文件系统(PVFS) 项目用来为运行 Linux 操作系统的 PC 群集创建一个开放源码的并行文件系统。PVFS 已被广泛地用作临时存储的高性能的大型文件系统和并行 I/O 研究的基础架构。作为一个并行文件系统,PVFS 将数据存储到多个群集节点的已有的文件系统中,多个客户端可以同时访问这些数据。
Lustre,一种平行分布式文件系统,通常用于大型计算机集群和超级电脑。Lustre 是源自 Linux 和 Cluster 的混成词。于 2003 年发布 Lustre 1.0。采用 GNU GPLv2 开源码授权。
集群管理系统的主要功能
目前,几大主流服务器厂商都提供了自己的集群管理系统,如浪潮的 Cluster Engine,曙光的 Gridview,HP 的 Serviceguard,IBM Platform Cluster Manager 等等。集群管理系统主要提供一项的功能:
1) 监控模块:监控集群中的节点、网络、文件、电源等资源的运行状态。动态信息、实况信息、历史信息、节点监控。可以监控整个集群的运行状态及各个参数。
2) 用户管理模块:管理系统的用户组以及用户,可以对用户组以及用户进行查看,添加,删除和编辑等操作。
3) 网络管理模块:系统中的网络的管理。
4) 文件管理:管理节点的文件,可以对文件进行上传、新建、打开、复制、粘贴、重命名、打包、删除和下载等操作。
5) 电源管理模块:系统的自动和关闭等。
6) 作业提交和管理模块:提交新作业,查看系统中的作业状态,并可以对作业进行执行和删除等操作。还可以查看作业的执行日志。
7) 友好的图形交互界面:现在的集群管理系统都提供了图形交互界面,可以更方便的使用和管理集群。
集群作业调度系统
关于目前主流的HPC作业调度系统有:LSF/Slurm/PBS/SGE,他们分别也都有一些衍生版本,所以,有人也将他们称为四大流派。
下表列出了目前主要使用的 HPC作业调度管理系统:PBS/Torque、Slurm、LSF、SGE 和 LoadLeveler使用的常用命令、环境变量和作业规范选项,这些作业调度管理器中的每一个都具有独特的功能,但最常用的功能在表中列出的所有这些环境中都可用。
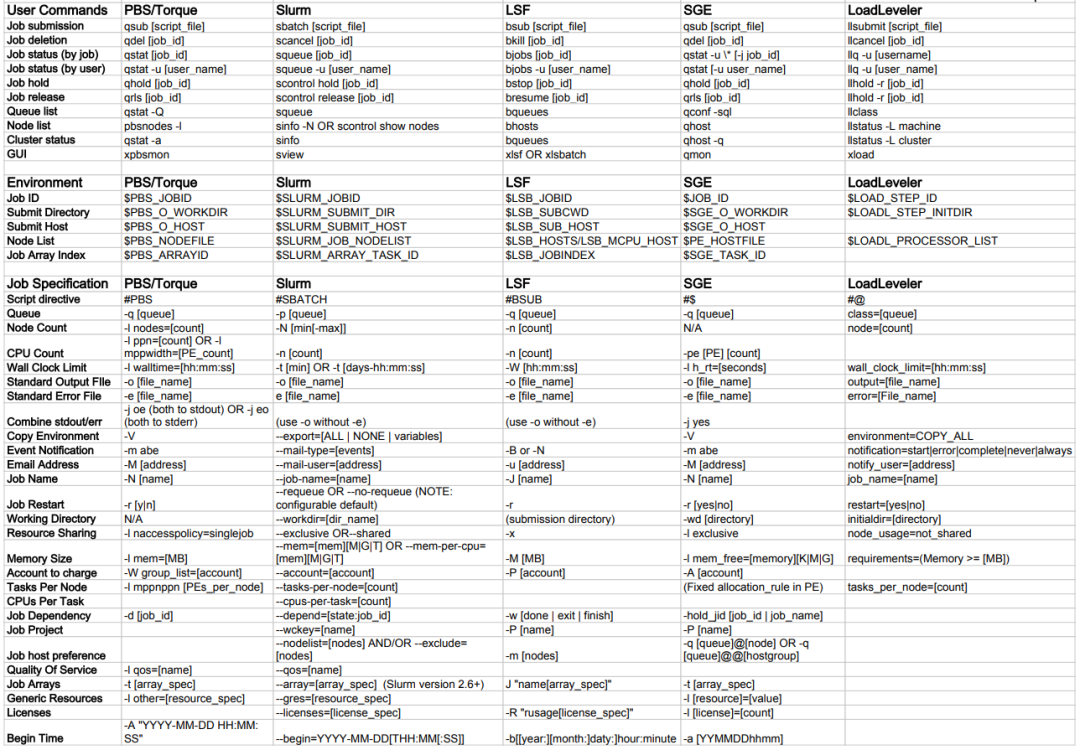
集群管理系统中最主要的模块为作业调度系统,目前,主流的作业调度系统都是基于PBS 的实现。PBS(Portable Batch System)最初由 NASA 的 Ames 研究中心开发,主要为了提供一个能满足异构计算网络需要的软件包,用于灵活的批处理,特别是满足高性能计算的需要,如集群系统、超级计算机和大规模并行系统。
PBS 的主要特点有:代码开放,免费获取;支持批处理、交互式作业和串行、多种并行作业,如 MPI、PVM、HPF、MPL;PBS 是功能最为齐全, 历史最悠久, 支持最广泛的本地集群调度器之一。
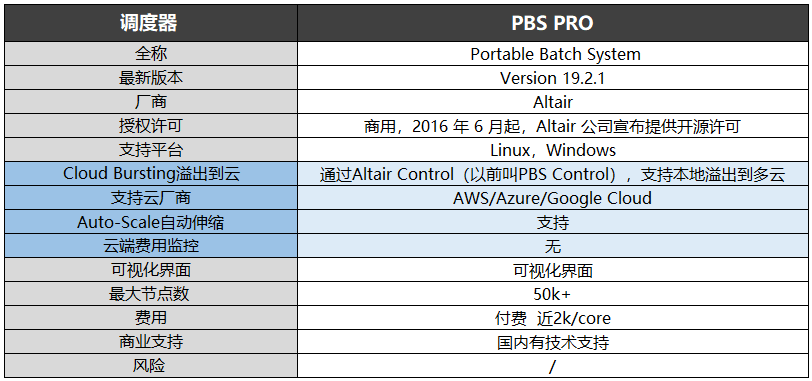
PBS 的目前包括 openPBS, PBS Pro 和 Torque三个主要分支. 其中 OpenPBS 是最早的 PBS 系统, 目前已经没有太多后续开发, PBS pro 是PBS 的商业版本, 功能最为丰富. Torque 是 Clustering 公司接过了 OpenPBS, 并给与后续支持的一个开源版本。PBS 主要有如下特征:
1) 易用性:为所有的资源提供统一的接口,易于配置以满足不同系统的需求, 灵活的作业调度器允许不同系统采用自己的调度策略。
2) 移植性:符合 POSIX 1003.2 标准,可以用于 shell 和批处理等各种环境。
3) 适配性:可以适配与各种管理策略,并提供可扩展的认证和安全模型。支 持广域网上的负载的动态分发和建立在多个物理位置不同的实体上的虚 拟组织。
4) 灵活性:支持交互和批处理作业。torque PBS 提供对批处理作业和分散的计算节点(Compute nodes)的控制。
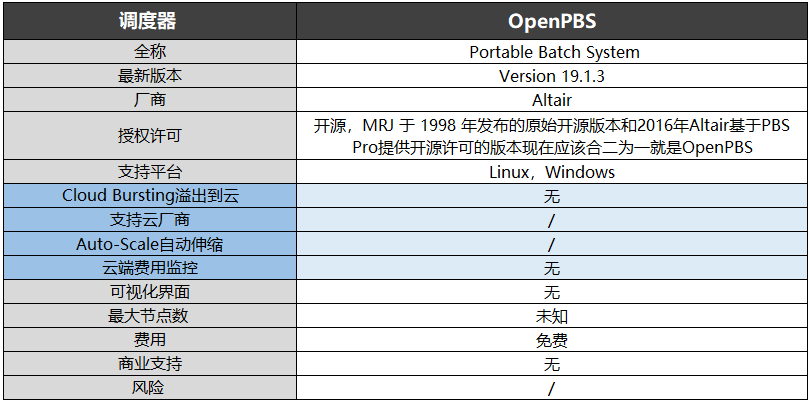
2016年Altair基于PBS Pro提供了开源许可版本,其与MRJ于1998年发布的原始开源版本两者合二为一大致就是现在的OpenPBS。与Pro版本比,多了很多限制,但都支持Linux和Windows。
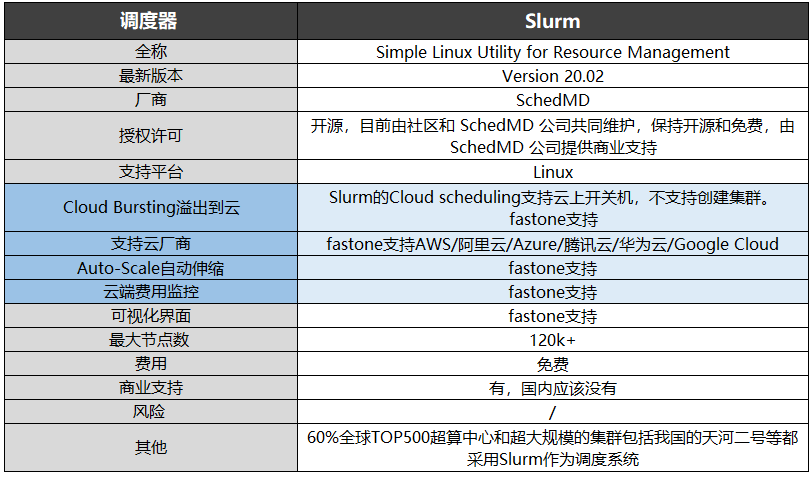
Slurm全称为Simple Linux Utility for Resource Management,前期主要由劳伦斯利弗莫尔国家实验室、SchedMD、Linux NetworX、Hewlett-Packard 和 Groupe Bull 负责开发,受到闭源软件Quadrics RMS的启发。 Slurm最新版本为22.05,目前由社区和SchedMD公司共同维护,保持开源和免费,由SchedMD公司提供商业支持,仅支持Linux系统,最大节点数量超过12万。 Slurm拥有容错率高、支持异构资源、高度可扩展等优点,每秒可提交超过1000个任务,且由于是开放框架,高度可配置,拥有超过100种插件,因此适用性相当强。
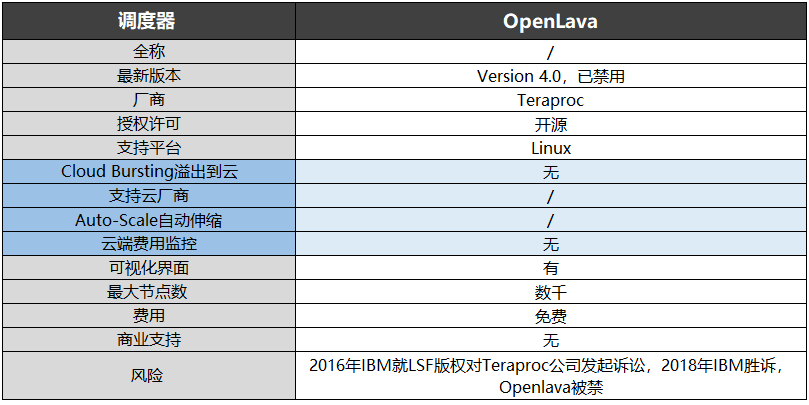
基于LSF(Load Sharing Facility)的调度器主要有Spectrum LSF、PlatformLSF、OpenLava三家。 早期的LSF是由Toronto大学开发的Utopia系统发展而来。
2007年,Platform Computing基于早期老版本的LSF开源了一个简化版Platform Lava。 这个开源项目2011年中止了,被OpenLava接手。2011年,Platform员工David Bigagli基于Platform Lava的派生代码创建了OpenLava 1.0。2014年,一些Platform的员工成立了Teraproc公司,为OpenLava提供开发和商业支持。2016年IBM就LSF版权对Teraproc公司发起诉讼,2018年IBM胜诉,OpenLava被禁用。
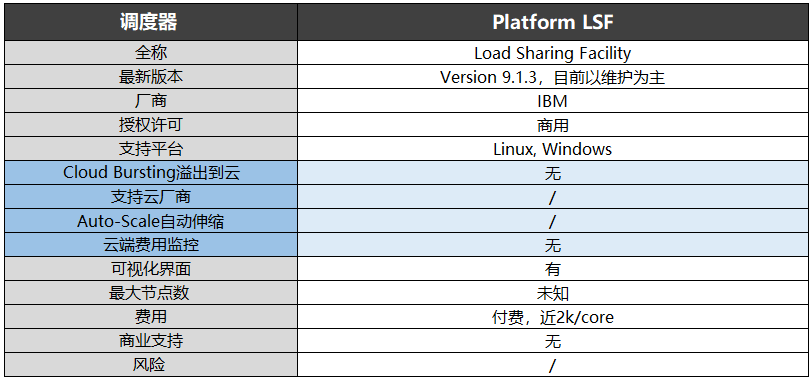
2011年,Platform Lava开源项目中止后。2012年1月,IBM收购了Platform Computing。Spectrum LSF就是IBM收购后推出的商用版本,目前更新到10.1.0,同时支持Linux和Windows,最大节点数超过6000,在国内提供商业支持。
Platform LSF是LSF的早期版本,与Spectrum LSF一样属于IBM,目前版本是9.1.3,目测已经停止更新以维护为主。
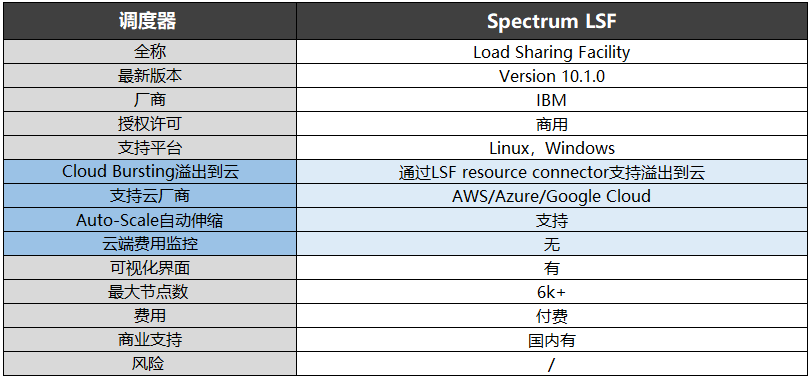
在这三个调度器中,仅有Spectrum LSF支持Auto-Scale集群自动伸缩功能,同时该调度器还可通过LSF resourceconnector实现溢出到云,支持云厂商包括AWS、Azure、Google Cloud。
并行编程模型
消息传递接口(Message Passing Interface, MPI),MPI 是一种基于消息传递的并行编程技术。MPI 程序是基于消息传递的并行程序。消息传递指的是并行执行的各个进程具有自己独立的堆栈和代码段,作为互不相关的多个程序独立执行,进程之间的信息交互完全通过显示地调用通信函数来完成。
1) MPI 是一个库,而不是一门语言。
2) MPI 是一种标准或规范的代表,而不特指某一个对它的具体实现,迄今为止,所有的并行计算机制造商都提供对 MPI 的支持,可以在网上免费得到 MPI 在不同并行计算机上的实现,一个正确的 MPI 程序可以不加修改地在所有的并行机上运行。
3) MPI 是一种消息传递编程模型,并成为这种编程模型的代表。事实上,标准 MPI虽然很庞大,但是它的最终目的是服务于进程间通信这一目标。常见 MPI 类型有以下几类:
1) OpenMPI
OpenMPI 是一种高性能消息传递库,它是 MPI-2 标准的一个开源实现,由一些科研机构和企业一起开发和维护。因此,OpenMPI 能够从高性能社区中获得专业技术、工业技术和资源支持,来创建最好的 MPI 库。OpenMPI 提供给系统和软件供应商、程序开发者和研究人员很多便利。易于使用,并运行本身在各种各样的操作系统,网络互连,以及一批/调度系统。
下载地址:http://www.open-mpi.org/
2) Intel MPI
Intel MPI 是 Intel 编译器中支持的 MPI 版本。
3) MPICH
MPICH 是 MPI 标准的一种最重要的实现,可以免费从网上下载。MPICH 的开发与 MPI规范的制订是同步进行的,因此 MPICH 最能反映 MPI 的变化和发展。MPICH 的开发主要是由 Argonne National Laboratory 和 Mississippi State University 共同完成的,在这一过程中 IBM 也做出了自己的贡献,但是 MPI 规范的标准化工作是由 MPI 论坛完成的。MPICH 是 MPI 最流行的非专利实现,由 Argonne 国家实验室和密西西比州立大学联合开发,具有更好的可移植性。相关下载地址:http://www.mpich.org/
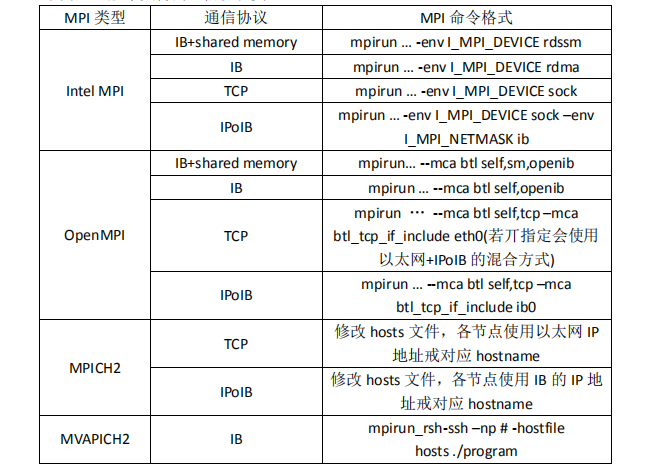
4) Mvapich
MVAPICH 是 VAPI 层上 InfiniBand 的 MPI 的缩写,它充当着连接消息传递接口(MPI 和被称作 VAPI 的 InfiniBand 软件接口间的桥梁,也是 MPI 标准的一种实现。InfiniBand 是“无限带宽”的缩写,这是一种新的支持高性能计算系统的网络架构。OSU(Ohio State University)超级计算机中心的科学家彼特于 2002 年开发出 MVAPICH 前,InfiniBand 和 MPI 是不兼容的。
同时,MVAPICH2/MVAPICH 也可以从 Open Fabrics Enterprise Distribution (OFED) 套件中获得。最新版本为 MVAPICH2 2.2b,下载地址:http://mvapich.cse.ohio-state.edu/
审核编辑 :李倩
-
鸿蒙原生页面高性能解决方案上线OpenHarmony社区 助力打造高性能原生应用2025-01-02 567
-
国产高性能ONFI IP解决方案全解析2026-01-13 848
-
高性能计算机的发展历史是怎样的?2019-09-10 4498
-
HPC高性能计算知识介绍2020-05-29 2834
-
高性能图像传感器参考设计的核心集成与协作解析2021-01-11 1675
-
高性能计算软件具有哪些缺陷?2021-08-30 1654
-
数据结构预算法核心知识点总结概述2021-12-21 1052
-
嵌入式开发中会用到哪些核心知识2021-12-24 1001
-
IIC的核心知识点汇总,绝对实用2022-01-24 1654
-
高性能选项和卓越性能基础知识总结2022-03-02 6845
-
计算机系统中的关键组件有哪些2024-07-15 4478
-
左蓝微电子高性能5G射频滤波器项目启动2024-09-26 1418
-
掌握EMC核心知识——7天倒计时!2024-12-11 1180
-
使用树莓派构建 Slurm 高性能计算集群:分步指南!2025-06-17 2095
-
AI算法核心知识清单(深度实战版3)2026-04-29 804
全部0条评论

快来发表一下你的评论吧 !
