

机器学习算法的分类
电子说
描述
一、监督学习根据有无标签分类
根据有无标签,监督学习可分类为:传统的监督学习(Traditional Supervised Learning)、非监督学习(Unsupervised Learning)、半监督学习(Semi-supervised Learning)。
(1)传统的监督学习
传统的监督学习的每个训练数据均具有标签(标签可被理解为每个训练数据的正确输出,计算机可通过其输出值与标签对比进行机器学习)。传统的监督学习包括:支持向量机(Support Vector Machine)、人工神经网络 (Neural Networks)、深度神经网络(Deep Neural Networks)。
(2)非监督学习
非监督学习的所有数据均没有标签。非监督学习假设同一类训练数据在空间中距离更近(个人理解:例如将若干含有两个变量的训练数据绘制于平面直角坐标系中,同一类训练数据在坐标系中的距离更近),计算机可根据样本空间信息,将空间距离更近的数据分为一类。非监督学习包括:聚类(Clustering)、EM算法(Expectation-Maximization Algorithm)、主成分分析(Principle Component Analysis)。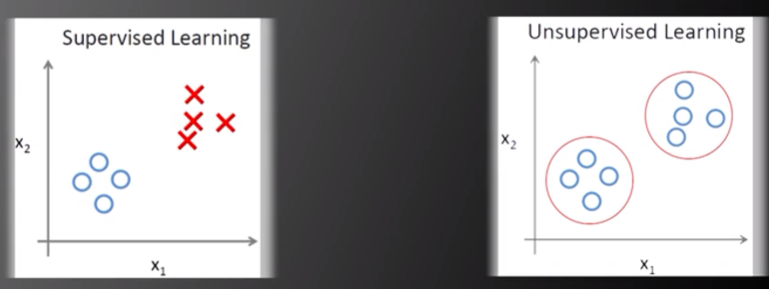
图片来源:中国慕课大学《机器学习概论》
(3)半监督学习
半监督学习中,一部分训练数据具有标签,一部分训练数据没有标签。因为随着互联网的普及,互联网中存在大量数据,将所有互联网数据进行标注的耗费较大,所以研究如何通过少量标注数据和大量未标注数据共同训练机器学习算法,即半监督学习成为机器学习的研究方向之一。
二、监督学习根据标签固有属性分类
根据标签固有属性,监督学习可被分为分类(Classification)和回归(Regression)。如果标签是离散的值,该种监督学习被称为分类;如果标签是连续的值,该种监督学习被称为回归。 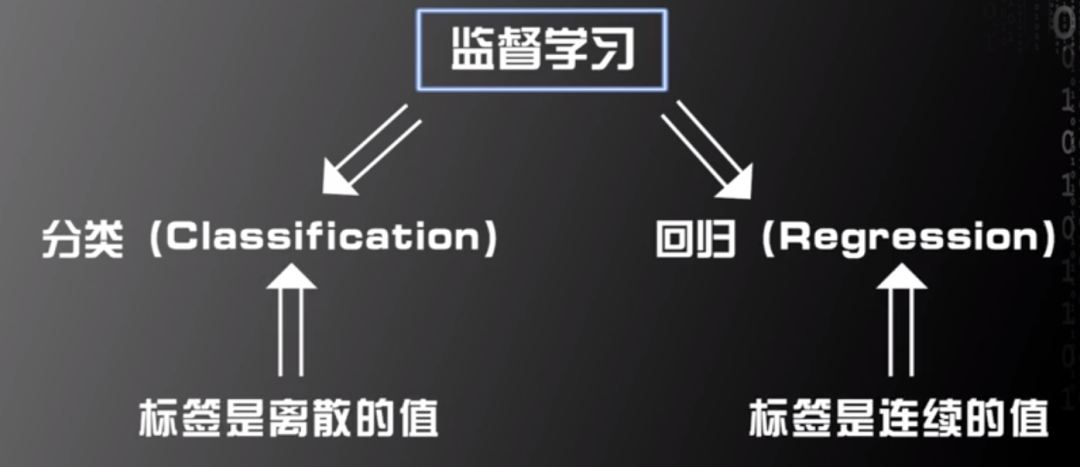
图片来源:中国慕课大学《机器学习概论》
人脸识别属于监督学习中的分类。人脸识别的任务包括两个:其一是识别两张人脸图片是否为同一个人,开发人员可将两张人脸图片是同一个人的标签定义为1,将两张人脸图片不是同一个人的标签定义为0;其二是在多张人脸图片(也可以是多个人脸在一张图片中)识别某个人脸,开发人员可将每个人脸定义标签为一个数字,可根据数字1、2、3……N的顺序为每个人脸定义标签。以上人脸识别两个任务的标签均是离散的值。 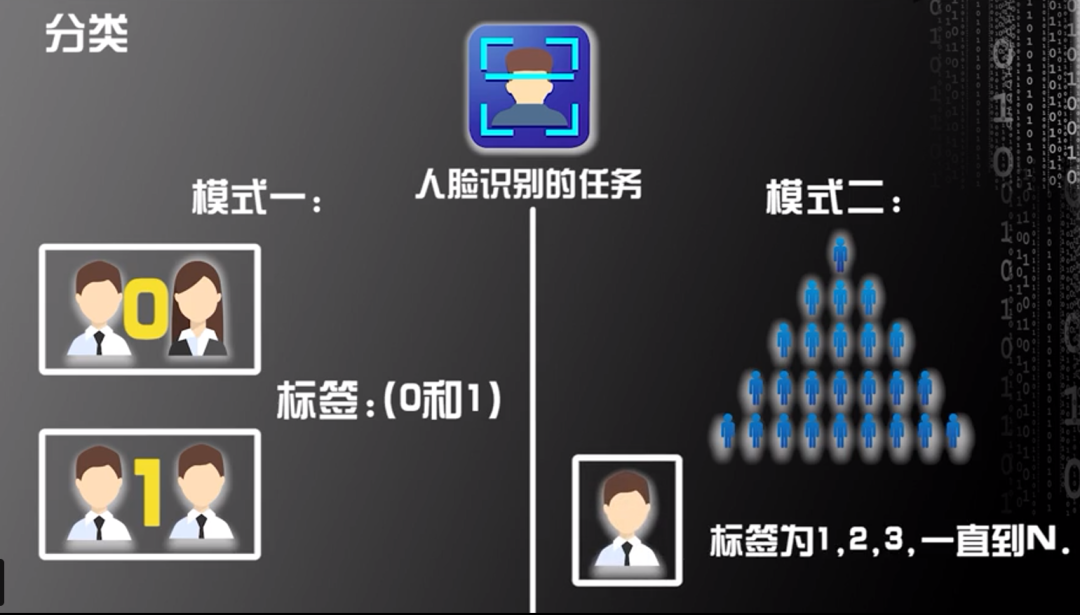
图片来源:中国慕课大学《机器学习概论》
预测股票价格、预测房价、预测温度、预测年龄等问题属于监督学习问题中的回归问题。一般,股票、房价、温度、年龄变化的数据(个人理解:此处的数据可被理解为标签)可被视为连续的值。
虽然监督学习可被分为分类和回归,但分类和回归的界限是模糊的,二者可以相互转换,这是由于连续数据和离散数据是可以相互转换的。例如:如果将房价值四舍五入,得出一组离散的数据(标签),那么预测房价问题可属于分类问题。因此,一个可以解决回归问题的机器学习算法经过较少的改造可解决分类问题,反之亦然。
审核编辑:刘清
-
机器学习算法汇总 机器学习算法分类 机器学习算法模型2023-08-17 2361
-
#硬声创作季 人工智能基础—机器学习入门完整版教程:7.机器学习算法分类介绍Mr_haohao 2022-09-21
-
机器学习的范围/算法/分类2021-01-21 4159
-
各类机器学习分类算法的优点与缺点分析2020-03-02 4407
-
详解机器学习分类算法KNN2019-10-31 7346
-
干货 | 这些机器学习算法,你了解几个?2019-09-22 3163
-
机器学习算法分类2018-01-05 3867
-
机器学习分类算法中必须要懂的四种算法2017-12-26 27075
-
机器学习所负责的任务的分类方法介绍2017-12-20 2875
-
Spark机器学习库的各种机器学习算法2017-09-28 1371
-
机器学习含义的图文解说2017-09-20 688
-
如何实现机器人的自我学习?2016-03-04 25649
全部0条评论

快来发表一下你的评论吧 !
