

Kubernetes Operator最佳实践介绍
描述
介绍
kubernetes operator是通过连接主API并watch时间的一组进程,一般会watch有限的资源类型。
当相关(所watch的)event触发的时候,operator做出响应并执行具体的动作。这可能仅限于与主 API 交互,但通常会涉及在其他一些系统上执行某些操作(可以是集群中或集群外资源)。

Operators是控制器的集合,并且每个控制器watch了指定的资源类型。当被watched的资源时间触发的时候,reconcile cycle(直译:调谐循环,下文均使用reconcile cycle)也将随之启动。
在执行reconcile cycle期间,控制器有责任检查当前状态是否与被watched资源描述的期望状态相匹配。有趣的是,根据设计,时间并不会传递到reconcile cycle中,这将会强制地让你去考虑实例的整个状态。这种方法被称为基于水平触发而不是基于边缘触发(level-based, as opposed to edge-based)。这源自于电子电路的设计,水平触发是接收event(例如中断)并对状态做出反应的理念,而基于边缘的触发是接收event并对状态变化做出反应的理念。
水平触发虽说效率较低,因为它强制重新评估完整的状态,而不是仅仅关注改变了什么,但在信号可能丢失或多次重复传输的复杂不可靠环境中,这种方式被认为是更适用的。
这种设计的选择会影响我们编写控制器代码的方式。
与此讨论相关的还有对 API 请求生命周期的理解。下图提供了一个高层次的总结:
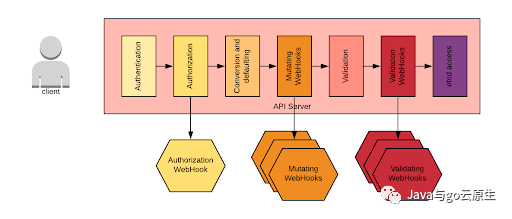
当向API服务器发送请求时,特别是对于创建和删除请求,它们会经历上图所示的阶段。需要注意的是,也可以指定webhook来执行请求的更改和验证。如果operator引入了CRD(custom resource definition),我们可能还必须定义这些webhook。一般来说,operator进程会开放一个端口来来实现webhook endpoint。
本文介绍了一系列在使用Operator SDK来设计和开发Operator时需要牢记的最佳实践。
如果你的operator引入了一个新的CRD,Operator SDK将会协助你来搭建。为确保您的 CRD 符合 Kubernetes 扩展 API 的最佳实践,请遵循这些约定。
文中所提到的所有的最佳实践都在operator-utils代码库中,并以可运行的例子体现。在你的operator项目中,也可以将operator-utils以library的方式导入,以此提供给你一些有用的工具。
最后,这组编写operator的最佳实践仅代表我的个人观点,不应被视为Red Hat的官方最佳实践。
创建 watches
正如我们所说,控制器watch着资源events。
watch是一种接收某种类型(核心类型或CRD)的机制。一般通过指定以下内容来创建watch机制:
想要watch的资源类型
handler。handler将被监视类型上的events映射到一个或多个调用协调周期的实例。监视类型和实例类型不必相同。
predicate。predicate是一组能够过滤我们感兴趣的events且可自定义的函数。
下图记录了以上提及的内容:
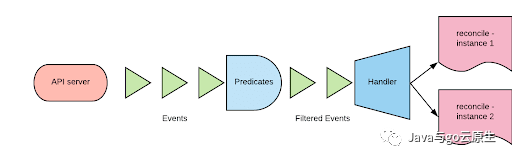
通常来说,同一类型(kind)开启多个watch是可行的,因为watch是多路复用的。
你也应该尽可能多地尝试过滤event。这边有个predicate例子,用来过滤secret资源上的event。这里你只对类型为TLS的secret资源event感兴趣:
isAnnotatedSecret := predicate.Funcs{
UpdateFunc: func(e event.UpdateEvent) bool {
oldSecret, ok := e.ObjectOld.(*corev1.Secret)
if !ok {
return false
}
newSecret, ok := e.ObjectNew.(*corev1.Secret)
if !ok {
return false
}
if newSecret.Type != util.TLSSecret {
return false
}
oldValue, _ := e.MetaOld.GetAnnotations()[certInfoAnnotation]
newValue, _ := e.MetaNew.GetAnnotations()[certInfoAnnotation]
old := oldValue == "true"
new := newValue == "true"
// if the content has changed we trigger if the annotation is there
if !reflect.DeepEqual(newSecret.Data[util.Cert], oldSecret.Data[util.Cert]) ||
!reflect.DeepEqual(newSecret.Data[util.CA], oldSecret.Data[util.CA]) {
return new
}
// otherwise we trigger if the annotation has changed
return old != new
},
CreateFunc: func(e event.CreateEvent) bool {
secret, ok := e.Object.(*corev1.Secret)
if !ok {
return false
}
if secret.Type != util.TLSSecret {
return false
}
value, _ := e.Meta.GetAnnotations()[certInfoAnnotation]
return value == "true"
},
}
一个非常常见的模式是观察我们创建(和我们拥有)资源上的events,并且定期在拥有这些资源的CR上执行reconcile cycle。为此,你可以使用EnqueueRequestForOwner handler,按照如下方式完成:
err = c.Watch(&source.Kind{Type: &examplev1alpha1.MyControlledType{}}, &handler.EnqueueRequestForOwner{})
另一种不太常用的情况是将一个events传播到多个资源上。考虑一种情况,一个控制器注入了TLS secret的路由。同一个命名空间中的多个路由可以指向同一个secret。如果secret发生了改变,我们需要更新所有路由。因此,我们需要在secret类型上创建一种watch机制,处理程序如下所示:
type enqueueRequestForReferecingRoutes struct {
client.Client
}
// trigger a router reconcile event for those routes that reference this secret
func (e *enqueueRequestForReferecingRoutes) Create(evt event.CreateEvent, q workqueue.RateLimitingInterface) {
routes, _ := matchSecret(e.Client, types.NamespacedName{
Name: evt.Meta.GetName(),
Namespace: evt.Meta.GetNamespace(),
})
for _, route := range routes {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Namespace: route.GetNamespace(),
Name: route.GetName(),
}})
}
}
// Update implements EventHandler
// trigger a router reconcile event for those routes that reference this secret
func (e *enqueueRequestForReferecingRoutes) Update(evt event.UpdateEvent, q workqueue.RateLimitingInterface) {
routes, _ := matchSecret(e.Client, types.NamespacedName{
Name: evt.MetaNew.GetName(),
Namespace: evt.MetaNew.GetNamespace(),
})
for _, route := range routes {
q.Add(reconcile.Request{NamespacedName: types.NamespacedName{
Namespace: route.GetNamespace(),
Name: route.GetName(),
}})
}
}
资源 Reconciliation Cycle
reconcile cycle是在被watch的event传递后框架将控制权转交给我们地方。正如之前所解释的,在该reconcile cycle中我们没有获得相关时间类型的信息,是因为我们是基于水平触发的方式来工作。
下面是一个管理CRD控制器的常见reconcile cycle的模型。和其他任何一个模型一样,它不会反映任何特定用例,但我希望它将有助于解决你在编写operator时遇到的问题。
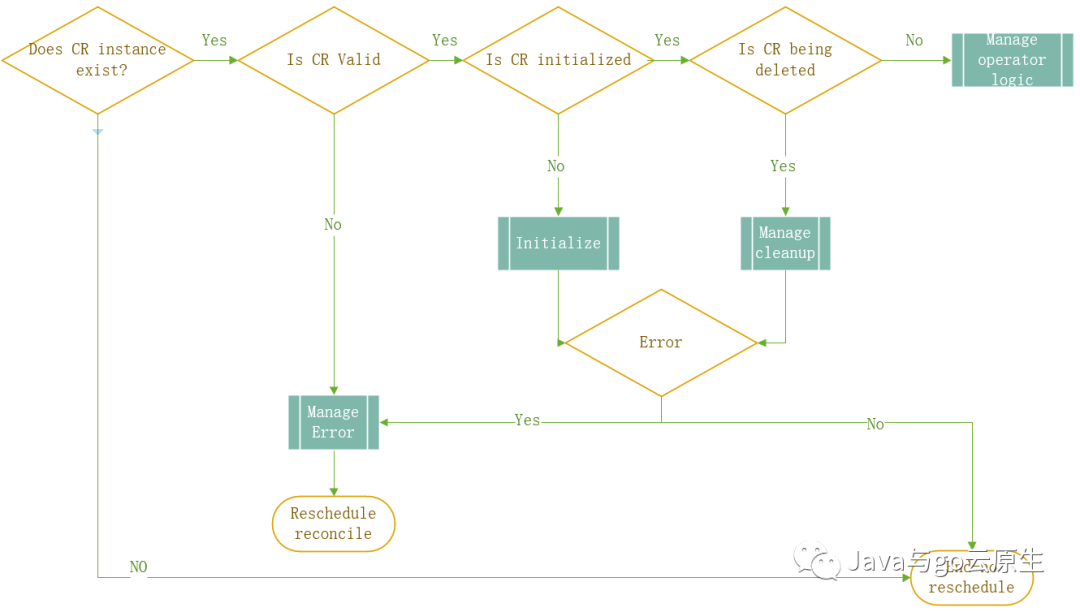
从图中我们可以看到,主要步骤是:
检索你感兴趣的CR实例
确认实例的有效性。我们不会在不合法实例上做任何事情。
初始化实例。如果实例的某些值没有被初始化,我们会在这一步进行处理。
判断实例的deletion状态。如果实例正在被删除,我们也需要做一些特殊的清理。
管理控制器的业务逻辑。如果以上步骤均通过,我们最终可以管理和执行该实例的reconcile逻辑。这个逻辑每个控制器都不尽相同。
在本节的剩余部分,你可以找到有关每个步骤的更深入的注意事项。
资源验证
这里存在两种类型的校验:语法校验和语义校验。
语法校验:通过定义OpenAPI规则来验证。
语义校验:可以通过创建 ValidatingAdmissionConfiguration 来完成。
注意:在控制器中不能校验CR合法性。一旦CR被APIServer接受了,它就会存在Etcd中。CR存在Etcd之后,管理该CR资源的控制器就无法拒绝它,如果这个CR是不合法的,控制器在尝试使用或处理它的时候将会发生错误。
推荐:但是由于我们不能保证ValidatingAdmissionConfiguration被创建或正常工作,我们还是应该在控制器内部去验证CR,如果CR不合法,应该避免创建无限错误循环。
语法校验
可以按照这个链接的描述添加OpenAPI验证规则
推荐:尽可能多地为你的自定义资源模型进行语法校验。你应该尽量使用语法校验,因为它相对简单,并且可以防止格式错误的 CR 存储在 etcd 中。
语义校验
语义校验是为了确保字段具有合理的值,从而使整个资源记录是有意义的。语义验证业务逻辑取决于 CR 所代表的概念,并且必须由operator的开发人员进行编码实现。
如果给定的CR需要语义校验,那么operator需要暴露一个webhook,作为operator deploymen的一部分,ValidatingAdmissionConfiguration也应该被创建。
以下是目前存在的局限性:
在OpenShift 3.11中,ValidatingAdmissionConfigurations还处于技术预览阶段(将从4.1开始支持)
Operator SDK不支持脚手架形式的webhook。可以使用kubebuilder来进行实现:
kubebuilder webhook --group crew --version v1 --kind FirstMate --type=mutating --operations=create,update
验证控制器中的资源
最好的方式是直接拒绝一个无效的CR,而不是接受并保存在Etcd中,然后对它进行错误条件处理。当然也有可能的情况是,ValidatingAdmissionConfiguration并没有被部署或者根本不可用。所以我认为在控制器代码中进行语义校验仍然是一个很好的做法。你应该做到的是,可以在ValidatingAdmissionConfiguration和控制器之间共享这部分结构化的代码。
控制器中调用验证方法的代码如下所示:
if ok, err := r.IsValid(instance); !ok {
return r.ManageError(instance, err)
}
请注意,如果验证失败,我们按照错误管理部分中的描述来管理这个错误。
IsValid函数如下:
func (r *ReconcileMyCRD) IsValid(obj metav1.Object) (bool, error) {
mycrd, ok := obj.(*examplev1alpha1.MyCRD)
// validation logic
}
资源初始化
Kubernetes的一个很好的惯例是用户只初始化他所需要的资源字段,其他的可以省略。以上是用户的视点,但从编码人员和调试者的角度来说,实际上最好将所有的字段都初始化。这允许在编码的时候不必总是去校验字段是否被定义了,并且可以轻松地排除错误情况。为了初始化资源,这里有两个选项:
在控制器中定义初始化方法
定义一个 MutatingAdmissionConfiguration(类似于ValidatingAdmissionConfiguration的程序)
建议:在控制器中定义一个初始化方法。代码应类似于此示例:
if ok := r.IsInitialized(instance); !ok {
err := r.GetClient().Update(context.TODO(), instance)
if err != nil {
log.Error(err, "unable to update instance", "instance", instance)
return r.ManageError(instance, err)
}
return reconcile.Result{}, nil
}
注意,如果IsInitialized方法的结果返回true,我们更新instance并return。这将会立即出发另一个reconcile cycle。第二次调用IsInitialized方法将会返回false,代码逻辑将会执行到下一部分。
资源 Finalization
如果资源不属于您的操作员控制的 CR,但在删除该 CR 时需要采取措施,您必须使用finalizer。
终结器提供了一种机制来通知 Kubernetes 控制平面,在执行标准 Kubernetes 垃圾收集逻辑之前需要执行一个操作。
资源可以有一个或多个finalizers。每一个控制器应该管理自己的finalizer并且忽略其他的。
这是管理finalizers的伪代码算法:
如果需要,在初始化方法中添加finalizer。
当资源被删除,检查此控制器拥有的finalizer是否存在。
清理成功,移除finalizer并更新CR
如果失败决定是重试还是放弃并可能留下垃圾(在某些情况下这是可以接受的)
如果不存在,直接return
如果存在,执行如下清理逻辑:
如果你的清理逻辑需要添加额外的资源,需要记住的是,无法在正在删除的命名空间中创建其他资源。删除命名空间将会触发finalizer并删除其下所有资源。
看如下的代码例子:
if util.IsBeingDeleted(instance) {
if !util.HasFinalizer(instance, controllerName) {
return reconcile.Result{}, nil
}
err := r.manageCleanUpLogic(instance)
if err != nil {
log.Error(err, "unable to delete instance", "instance", instance)
return r.ManageError(instance, err)
}
util.RemoveFinalizer(instance, controllerName)
err = r.GetClient().Update(context.TODO(), instance)
if err != nil {
log.Error(err, "unable to update instance", "instance", instance)
return r.ManageError(instance, err)
}
return reconcile.Result{}, nil
}
资源所有权
资源所有权是Kubernetes中的原生概念,它决定了资源如何被删除。默认情况下,当一个资源被删除的时候,它的子资源也也会被删除(你可以设置cascade=false来关闭这种行为)
这种行为有助于确保资源的正确垃圾收集,尤其是当资源控制多级层次结构中的其他资源时(deployment-> repilcaset->pod)
建议:如果你的控制器创建资源并且它的生命周期与其他资源(kubernetes核心资源或其他CR)有关联,那么您应该将此资源设置为其他资源的所有者,如下所示:
controllerutil.SetControllerReference(owner, obj, r.GetScheme())
有关所有权的其他规则如下:
父子资源必须位于同一命名空间中
命名空间资源可以拥有集群资源。但我们必须小心处理。一个对象可以有一个所有者列表。如果多个命名空间对象拥有相同的集群资源,则每个对象都应声明所有权,而不会覆盖其他对象的所有权
集群资源不能拥有命名空间资源
集群资源可以拥有另外一个集群资源
状态管理
Status是资源的一个标准部分。Status被用于报告资源的状态。在本文档中,我们将使用 status 报告最后一次执行协调循环的结果。你也可以在Status中添加更多的信息。
在正常情况下,如果我们每次执行reconcile cycle的时候都要更新资源,这将触发更新时间,进而导致无限触发reconcile cycle。
因此,正如上面描述的那样,我们应该把Status作为子资源。
使用这种方法,我们能够不增加ResourceGeneration元数据域的情况下更新资源的状态。使用如下命令更新状态:
err = r.Status().Update(context.Background(), instance)
现在我们需要为我们的watch机制写一个predicate(有关这些概念的更多详细信息,请参阅有关watches的部分)用来丢弃不增加ResourceGeneration的更新事件。可以使用GenerationChangePredicate来完成此功能。
如果你还记得的话,上文提到过,在使用finalizer的时候,应该在初始化的时候设置。如果finalizer是初始化的唯一项,由于它是元数据项的一部分,所以ResourceGeneration不会递增。为了说明该用例,以下是predicate的修改版本:
type resourceGenerationOrFinalizerChangedPredicate struct {
predicate.Funcs
}
// Update implements default UpdateEvent filter for validating resource version change
func (resourceGenerationOrFinalizerChangedPredicate) Update(e event.UpdateEvent) bool {
if e.MetaNew.GetGeneration() == e.MetaOld.GetGeneration() && reflect.DeepEqual(e.MetaNew.GetFinalizers(), e.MetaOld.GetFinalizers()) {
return false
}
return true
}
现在假设你的status如下所示:
type MyCRStatus struct {
// +kubebuilderEnum=Success,Failure
Status string `json:"status,omitempty"`
LastUpdate metav1.Time `json:"lastUpdate,omitempty"`
Reason string `json:"reason,omitempty"`
}
你可以写一个函数来管理并保证reconcile cycle成功执行:
func (r *ReconcilerBase) ManageSuccess(obj metav1.Object) (reconcile.Result, error) {
runtimeObj, ok := (obj).(runtime.Object)
if !ok {
log.Error(errors.New("not a runtime.Object"), "passed object was not a runtime.Object", "object", obj)
return reconcile.Result{}, nil
}
if reconcileStatusAware, updateStatus := (obj).(apis.ReconcileStatusAware); updateStatus {
status := apis.ReconcileStatus{
LastUpdate: metav1.Now(),
Reason: "",
Status: "Success",
}
reconcileStatusAware.SetReconcileStatus(status)
err := r.GetClient().Status().Update(context.Background(), runtimeObj)
if err != nil {
log.Error(err, "unable to update status")
return reconcile.Result{
RequeueAfter: time.Second,
Requeue: true,
}, nil
}
} else {
log.Info("object is not RecocileStatusAware, not setting status")
}
return reconcile.Result{}, nil
}
错误管理
如果控制器进入了一个错误条件,并且在reconcile方法中返回了一个错误。operator将会打印错误日志到标准输出,reconlie event将会立即再次调度(默认的调度器实际上应该检测是否一遍又一遍地出现相同的错误,并增加相应的调度时间,但在我的经验看来,这并没有发生)。如果错误一直存在,那么也将永远存在错误循环。而且,这个错误条件对用户来说是不可见的。
有两种方法可以通知用户发生了错误,它们可以同时使用:
在对象的status字段中返回错误
生成一个event描述错误
此外,如果你认为错误能够自解决,你应该在一段周期时间后重新调度reconcile cycle。通常来说,周期时间是呈指数增长的,因此在每次迭代中,reconcile event周期会越来越长(例如每次增长时间量的两倍)。
我们现在构建状态管理来处理错误条件:
func (r *ReconcilerBase) ManageError(obj metav1.Object, issue error) (reconcile.Result, error) {
runtimeObj, ok := (obj).(runtime.Object)
if !ok {
log.Error(errors.New("not a runtime.Object"), "passed object was not a runtime.Object", "object", obj)
return reconcile.Result{}, nil
}
var retryInterval time.Duration
r.GetRecorder().Event(runtimeObj, "Warning", "ProcessingError", issue.Error())
if reconcileStatusAware, updateStatus := (obj).(apis.ReconcileStatusAware); updateStatus {
lastUpdate := reconcileStatusAware.GetReconcileStatus().LastUpdate.Time
lastStatus := reconcileStatusAware.GetReconcileStatus().Status
status := apis.ReconcileStatus{
LastUpdate: metav1.Now(),
Reason: issue.Error(),
Status: "Failure",
}
reconcileStatusAware.SetReconcileStatus(status)
err := r.GetClient().Status().Update(context.Background(), runtimeObj)
if err != nil {
log.Error(err, "unable to update status")
return reconcile.Result{
RequeueAfter: time.Second,
Requeue: true,
}, nil
}
if lastUpdate.IsZero() || lastStatus == "Success" {
retryInterval = time.Second
} else {
retryInterval = status.LastUpdate.Sub(lastUpdate).Round(time.Second)
}
} else {
log.Info("object is not RecocileStatusAware, not setting status")
retryInterval = time.Second
}
return reconcile.Result{
RequeueAfter: time.Duration(math.Min(float64(retryInterval.Nanoseconds()*2), float64(time.Hour.Nanoseconds()*6))),
Requeue: true,
}, nil
}
注意,此函数会立即发送一个event,然后使用错误条件更新状态。最后,计算何时重新安排下一次reconcile。该算法尝试将每个循环的时间加倍,最多到六个小时为止。
六个小时是一个很好的上限时间,因为event大约持续6个小时,所以这应该确保始终有一个活动event描述当前的错误情况。
总结
本博客中介绍的实践涉及Kubernetes Operator时最常见的问题,且让你可以编写一个有信心投入生产环境的operator。当然很有可能,这仅仅是一个开始,我们很容易预见将会有更多的框架和工具的出现来帮助你编写operator。
审核编辑:刘清
-
leader选举在kubernetes controller中是如何实现的2022-07-21 2801
-
C编程最佳实践.doc2012-08-17 2912
-
Kubernetes Ingress 高可靠部署最佳实践2018-04-17 3070
-
Dockerfile的最佳实践2019-07-11 1573
-
Kubernetes Dashboard实践学习2020-04-10 1972
-
虚幻引擎的纹理最佳实践2023-08-28 750
-
华为云在Kubernetes大规模场景下的Service性能优化实践2019-06-21 1595
-
阿里巴巴 Kubernetes 应用管理实践中的经验与教训2019-11-14 552
-
教你们Kubernetes五层的安全的最佳实践2021-07-09 1986
-
最常用的11款Kubernetes工具2021-08-23 3098
-
Kubernetes是什么,一文了解Kubernetes2021-12-21 2178
-
如何从零开发Kubernetes Operator?2023-01-05 2400
-
Kubernetes上Java应用的最佳实践2023-03-14 1557
-
什么是Operator?Operator是如何工作的?如何构建Operator?2023-09-01 3284
-
生产环境中Kubernetes容器安全的最佳实践2025-07-14 1201
全部0条评论

快来发表一下你的评论吧 !
