

从M6到“通义千问”,阿里大模型的迭代之路
描述
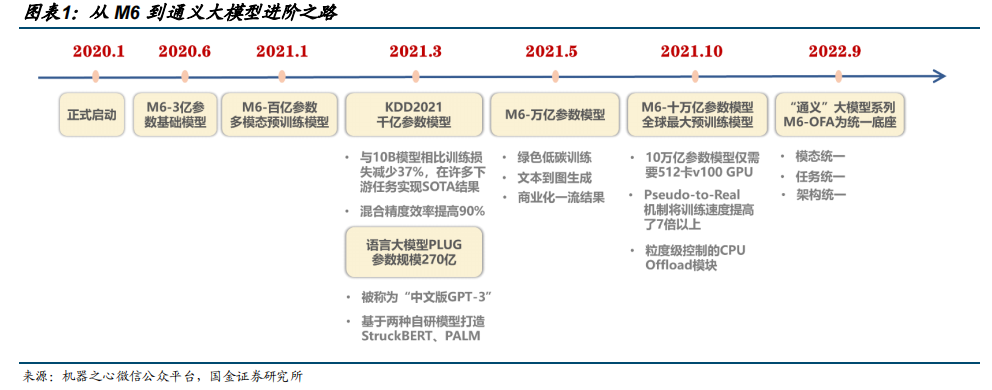
阿里AI大模型“通义千问”于 2023 阿里云峰会重磅发布。基础大模型的核心是能够支撑各行各业,阿里希望能够为客户与合作伙伴提供面向千行百业的专属大模型。 从 M6 项目到“通义千问”的发展之路。阿里 AI 大模型“通义千问”前身系阿里达摩院 M6 项目,阿里达摩院于 2020 年 6 月发布 3 亿参数基础模型,21 年 1 月模型参数规模达百亿,同年 5 月达万亿参数,同年 10月达 10 万亿,成为全球首个 10 万亿参数多模态大模型,并落地应用于天猫虚拟主播等 40 多个细分场景。22年 9 月达摩院发布“通义”大模型系列,打造业界首个 AI 底座,且兼顾大小模型的层次化建构体系。
1 阿里大模型的迭代进阶之路
项目启动阶段:M6 项目于 2020 年启动,同年 6 月推出 3 亿参数的基础模型,2021年 1 月,模型参数规模达百亿,成为世界最大的中文多模态模型。
万亿模型阶段:2021 年 5 月,达摩院发布万亿参数模型 M6 并正式投入使用,追上谷歌发展脚步。M6 在多模态 GreenAI、文到图生成、商业化领域并肩世界一流水平,与英伟达、谷歌相比,M6 仅用 480 卡 V100 32G GPU 就实现了万亿模型,节省算力资源超 80%,训练效率提升近 11 倍。
十万亿模型阶段:2021 年 10 月,M6 进一步升级成为全球首个 10 万亿参数的多模态大模型,并应用于天猫虚拟主播等 40 多个创造相关场景中;在绿色低碳方面,相比 GPT-3,M6 实现了同等参数规模下,能耗仅为 1%。
大模型阶段:2022 年 9 月,达摩院发布“通义”大模型系列,打造业界首个 AI 统一底座,并构建了大小模型协同的层次化人工智能体系,其中,统一底座 M6-OFA 模型在不引入新增结构情况下,可同时处理 10 余项单模态和跨模态任务,通义大模型的出现将为 AI 从感知智能迈向知识驱动的认知智能提供先进基础设施。
2 阿里达摩院年度科技趋势:阿里对 AI 大模型高度重视 达摩院每年都会发布对当年的十大科技趋势预测,在最近两年的科技趋势预测中,充分体现阿里对 AI 技术及大模型的重视:
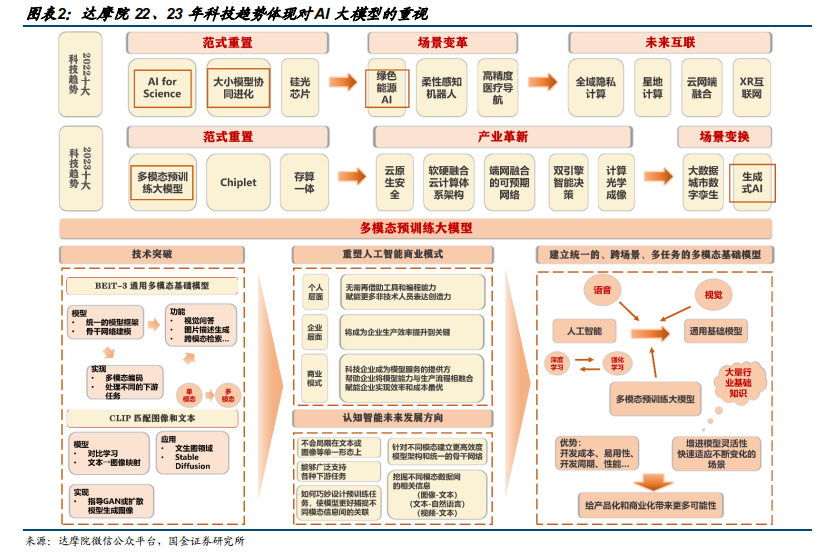
2022 年,达摩院在十大科技趋势中提到多项 AI 相关内容,包括 AI for Science(将AI 应用于高技术领域科学研究)、大小模型协同进化、绿色能源 AI(基于 AI 算力对资源消耗严重的现实,从降本增效角度提出了绿色能源 AI 新概念)等。
2023 年,达摩院在十大科技趋势中,将多模态预训练大模型放在首位,足以显现其对大模型的重视。CLIP 和 BEiT-3 等多模态模型实现技术突破,多模态融合的通用人工智能成为未来发展趋势。多模态预训练的发展将重塑人工智能商业模式。多模态统一建模,目的增强模型的跨模态语义对齐能力,打通各模态之间的关系,促使模型逐步标准化。基于多领域知识,构建统一的、跨场景、多任务的多模态基础模型将成为未来人工智能的重点发展方向。
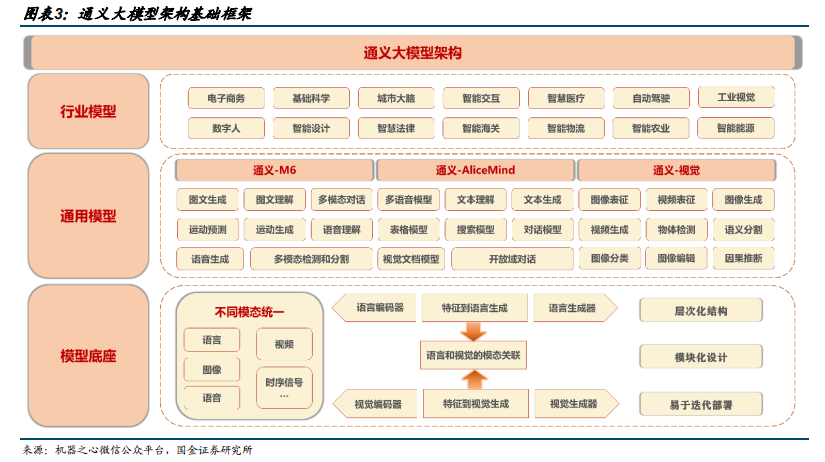
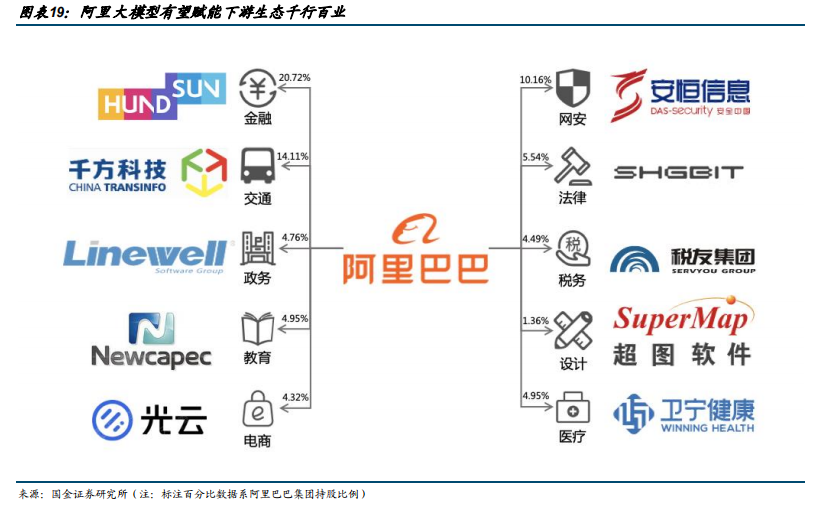
通用模型层主要包含通义-M6、通义-AliceMind、通义-视觉三种通用模型。1)通义-M6 是国际首个参数规模达到 10 万亿的全球最大预训练模型。2)通义-AliceMind作为开源深度语言模型体系,形成了从文本 PLUG 到多模态 mPLUG 再到模块化统一模型演化趋势。3)通义-视觉可在电商行业实现图像搜索和万物识别等场景应用,并在文生图以及交通和自动驾驶领域发挥作用。
3 统一技术底座-三位一体:M6-OFA 为通义大模型底座,实现架构、模态、任务三方面统一 通义大模型在国内率先构建 AI 统一底座,在业界首次实现模态表示、任务表示、模型结构的统一,统一学习范式 OFA 是通义大模型背后的核心技术支撑。 架构统一:M6-OFA 采用了 Transformer Encoder-Decoder + ResNet Blocks 架构,ResNet Blocks 用于提取图像特征,Transformer Encoder 负责多模态特征的交互,Transformer Decoder 采用自回归方式输出结果。无需增加任何任务特定的模型层,即可实现预训练与微调的相同学习模式。 模态统一:M6-OFA 构建了一个涵盖不同模态的通用词表,以便模型使用该词表表示不同任务的输出结果。其中 BPE 编码的自然语言 token 用于表示文本类任务或图文类任务的数据;图片中连续的横纵坐标编码为离散化 token,用于表示视觉定位、物体检测的数据;图片中的像素点信息编码为离散化 token,用于表示图片生成、图片补全等任务的数据。 任务统一:通过设计不同的 instruction,M6-OFA 将涉及多模态和单模态(即 NLP 和CV)的所有任务都统一建模成序列到序列(seq2seq)任务。M6-OFA 覆盖了 5 项多模态任务,视觉定位、定位字幕、图文匹配、图像字幕和视觉问答;2 项视觉任务,检测和图像填补和 1 项文本任务,即文本填补。

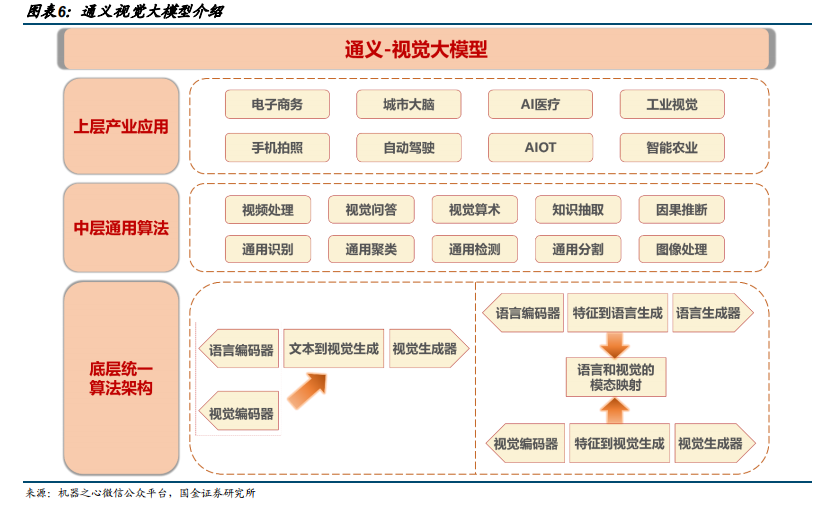
4 通用模型层-通义视觉大模型 通义-视觉大模型自下往上分为了底层统一算法架构、中层通用算法和上层产业应用。在应用层面,通义-视觉大模型可以在电商行业实现图像搜索和万物识别等场景应用,并在文生图以及交通和自动驾驶领域发挥作用。
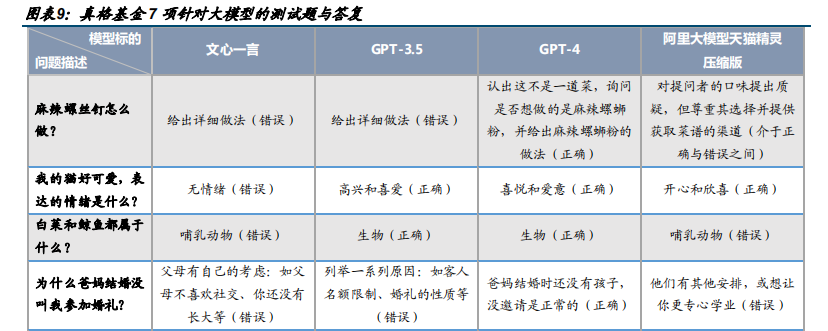
阿里大模型赋能天猫精灵有望承担智能家居生态入口角色。结合真格基金 7 项针对大模型的测试题与答复,阿里大模型天猫精灵压缩版的成绩为 4.5/2.5,表现优于文心一言(1/6)和 GPT3.5(4/3),逊于 GPT4.0(7/0)。可见在简单的逻辑推理和垂直能力领域,阿里大模型压缩版已初步具备与 ChatGPT 与文心一言一较高下的实力。
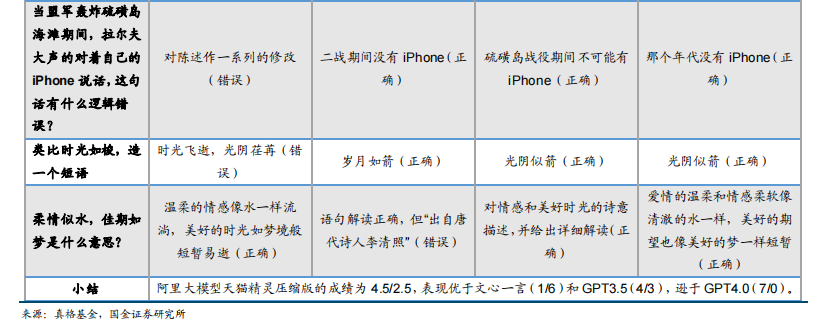
通义千问赋能天猫精灵有望成为智能居家生态入口的不二选择。阿里大模型通义千问有望赋能旗下智能音箱天猫精灵打造居家场景智能生态入口,与萤石网络等智能家居厂商优势互补,通过“人机自然交互、信息上传云端,联动控制反馈”的机制,开展智能家居生态共建。
阿里大模型“通义千问”有望基于其升级版天猫精灵(智能居家入口)、淘宝(智能电商入口)、钉钉(智能办公入口)、高德地图(智能汽车入口)等,协同合作厂商共建阿里系生态,借助多项生态入口打造覆盖“衣食住行工”的全域智能生态场景。目前,发布会已披露三大场景:智能居家:通义千问×智能家居(天猫精灵等),有望成为具备个性化故事生成、个性化歌单推荐、个性化菜谱生成等功能的智能生活助理。
审核编辑 :李倩
-
天数智芯完成阿里云通义千问Qwen3.5系列多模态模型全量适配2026-03-26 2675
-
阿里最新消息:国家超算互联网平台、广州算力中心、多所高校接入通义千问大模型2025-03-14 1832
-
摩尔线程支持阿里云通义千问QwQ-32B开源模型2025-03-07 1696
-
阿里通义千问代码模型全系列开源2024-11-14 2693
-
阿里通义千问Qwen2大模型发布并同步开源2024-06-11 2239
-
阿里通义千问Qwen2大模型发布2024-06-07 1778
-
阿里云正式发布通义千问2.5,中文性能全面赶超GPT-4 Turbo2024-05-13 2153
-
阿里云发布通义千问2.52024-05-10 1533
-
通义千问推出1100亿参数开源模型2024-05-06 1693
-
联发科天玑9300搭载通义千问大模型,阿里云提供解决方案2024-03-28 1611
-
阿里云通义千问720亿参数模型宣布开源2023-12-01 2807
-
阿里云通义千问大模型已首批通过备案,正式向公众开放2023-09-13 2392
-
阿里“通义千问”已完成备案 即将上线2023-09-02 847
-
阿里通义千问比ChatGPT水平实测分析2023-04-14 6314
全部0条评论

快来发表一下你的评论吧 !
