

DPU 究竟有什么作用呢?
电子说
描述
这场革命始于SmartNIC,而DPU则是它的2.0版本。
“随着DPU 越来越多地出现在大众视野中,期待未来可以看到加密/解密、防火墙、数据包检查、路由、存储网络等功能由 DPU 处理,”Turner 预测。
SmartNIC——初代DPU
GPU的蓬勃发展源于x86 系列处理器的局限性,x86 处理器更适合处理通用型任务,但对于特定工作来说它们要比专用芯片慢得多。GPU最开始被用在游戏机中,后来被发现还很适合用于AI系统。
与 GPU 一样,SmartNIC最开始只是被用来从 CPU 中卸载一些网络功能,实现网络加速。现在已经被开发出了很多新的使用场景。
但 SmartNIC 并不是一个统一的、一刀切的类别。Delloro Group 的分析师 Baron Fung 解释说,随着网络变得更快,SmartNIC 需要承载更多的用户流量。网络供应商创建了一种使用专门的 ASIC 来卸载网络功能的“性能”网卡。但SmartNIC 有所不同。
SmartNIC 在性能网卡上又增加了另一层性能。SmartNIC 是完全可编程设备,具有自己的处理器、操作系统、集成内存和网络结构。它就像服务器中的服务器,从主机 CPU 提供不同范围的卸载服务。
目前大多数智能设备都是AWS、微软、阿里等云厂商专有的,他们在自己的数据中心构建自己的 SmartNIC,但随着越来越多创新产品和软件开发框架的发布,其他市场也逐渐开始采用SmartNIC 。
有预测显示,SmartNIC 在未来几年将以每年 3% 的速度增长,但在整个市场来看仍只是占据一小部分,因为SmartNIC 价格昂贵,目前SmartNIC 的价格是标准网卡的三到五倍。这就需要证明高成本的合理性。
在一般网络应用中,SmartNIC 可以提高网络效率,同时因为智能设备可以通过软件进行优化,采用SmartNIC 还能够延长基础设施的使用寿命,这实现了一种相对平衡。
随着SmartNIC 的发展,市场上又出现了它的进阶版——DPU。不同的厂商给它定义了不同的名称和功能,比如英特尔的叫IPU,阿里云的叫CIPU。
DPU的到来
DPU一词最早由Juniper创始人Pradeep Sindhu创建的硅谷创业公司Fungible提出。
“你可以使用通用 x86 定义一个非常简单的服务器来进行通用处理,然后放入一个 DPU 来为你完成所有其余的存储工作”,Fungible 首席执行官 Eric Hayes表示。
数据无处不在,每个人都在收集和存储数据。真正的问题在于如何处理所有这些数据?
CPU 和 GPU 的设计初衷并不是为了完成移动和处理数据的任务,所以它们处理这类任务的效率非常低。
Hayes 认为 SmartNIC 与DPU 之间存在明显的区别:“DPU 是为数据处理而设计的,它的出现就是为了处理 x86 和 GPU 无法高效处理的数据。”
根据 Hayes 的说法,早期的 SmartNIC “只是 Arm 或 x86 CPU、FPGA 和硬连线、可配置管道的不同组合。他们只能用有限的性能来换取灵活性。”
相比之下,DPU 架构实现了灵活性和性能兼具。
那么DPU 究竟有什么作用呢?
加速网络
首先是加速网络。DPU 能够让网络处理速度更快。由于软件定义网络 (SDN) 的出现,网络越来越多地以软件形式实现。SDN网络通过在软件中处理它们的功能使系统更加灵活,但是该软件在通用处理器上运行时效率极低。
SmartNIC 采取了一些措施来改进 SDN 功能,但还没有达到 DPU 的性能水平。除了SDN,DPU还将在更智能的网络生态系统中发挥重要作用,例如5G OpenRAN。
重写存储
DPU可以为以数据为中心的时代重建存储,通过创建TCP/IP上运行的内存访问协议,并将其卸载,从而创建“内联计算存储”。
NVMe(non-volatile memory express) 是一种用于访问闪存的接口,通常由 PCI express 总线连接。通过 TCP/IP 运行 NVMe,并将整个堆栈放在 DPU 上,将整个内存访问从CPU上卸载,这意味着闪存不再需要直接连接到CPU。
通过 TCP 执行 NVMe 的目的是能够从服务器中取出所有闪存,可以使用通用 x86 定义一个非常简单的服务器来进行通用处理,然后放入一个 DPU 来完成所有其余的存储工作。
就 CPU 而言,DPU 看起来像一个存储设备,卸载了通常必须在通用处理器上运行的所有驱动程序。
加速 GPU
一个基本的 x86 处理器可以管理很多 GPU,但这其中也存在一个瓶颈,因为数据必须从 GPU、PCI 接口传输到 CPU。
将通信任务交给 DPU 可以减少对 GPU-PCI 接口的依赖。在多用户环境中,这比将一组GPU专用于特定的x86处理器更高效,价格也便宜得多。
DPU 的最后一个作用是安全性。DPU有加速加密和解密的能力。
DPU需要标准化吗?
目前DPU的采用尚处于起步阶段,每个DPU厂商都有自己的解决方案,标准化想要推进十分困难。
但如果DPU 要覆盖更多客户,就必须出现一个更加标准化的生态系统。
预计约有三分之一的 DPU 市场将集中在较小的提供商和私有数据中心中,这些小公司没有像云巨头厂商那样有大量的工程师,标准化有助于降低边际成本,创造规模效益,实现创新技术的价值变现。
Hello DPU,Goodbye CPU!
很多人都谈到了DPU的优势之一是降本增效,但是实际上并没有能够拿出有效的数据佐证这一观点。近日,英伟达使用其 BlueField-2 E 系列 DPU进行了一些测试,该 DPU 具有一对 100 Gb/sec 端口,并采用同样具有一对 100 Gb/sec 端口的常规 SmartNIC 作为对照组。
英伟达存储营销总监John Kim展示了将服务器上运行的hypervisor的Open vSwitch (OVS)卸载到BlueField-2 DPU的效果,以及将爱立信的用户平面功能(UPF)工作负载从5G基站中的服务器CPU卸载到机箱中运行的DPU的效果。在每一个案例中,英伟达都计算了在10,000台机器的集群中为这些负载卸载添加DPU的效果,并且只计算了在加州电价下节省的电力。在这两种情况下,英伟达计算服务器上有多少个内核在运行这两种工作负载,消耗了多少瓦,然后在DPU上运行它需要多少瓦,然后计算在三年内节省的电力和成本。
以下是 OVS 卸载的性能提升和节能数据:
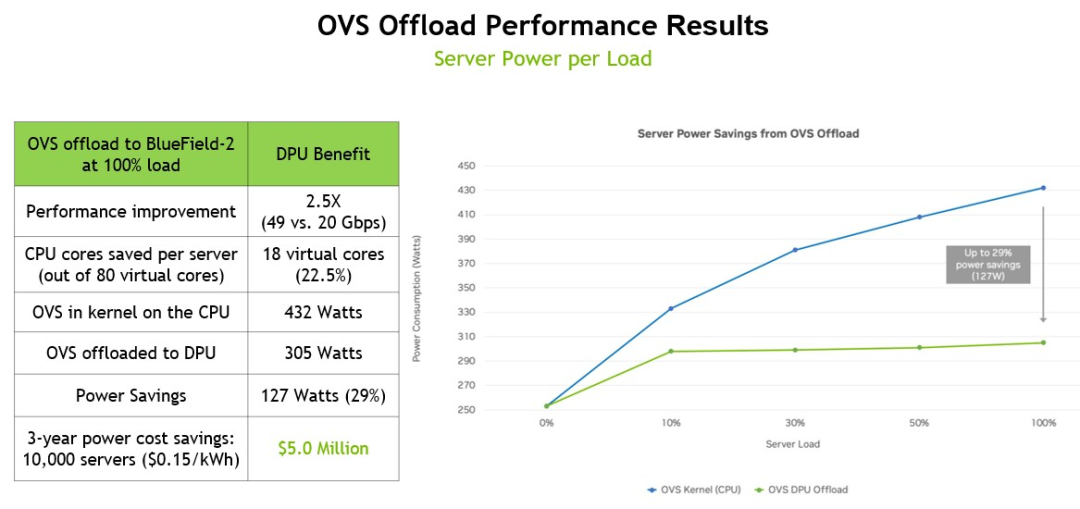
这个基准测试是在一台戴尔PowerEdge R740服务器上运行的,该服务器使用一对英特尔“Cascade Lake”至强SP-6248 Gold处理器,每个处理器有20个内核,运行在2.5 GHz,一个BlueField-2 DPU带有一对25 Gb/秒以太网端口。在服务器上运行OVS需要18个线程和9个内核(总共80个线程和40个内核),这占计算机固有计算能力的22.5%,也就是说理论上整个服务器150瓦CPU功率和实际432瓦CPU功率相同。通过将OVS工作负载转移到DPU, OVS在运行时只消耗305瓦,如果将节省的电能分散到10,000个节点上,那么三年节省的成本将达到500万美元。
重要的是,OVS 交换机的吞吐量从 20 Gb/秒提升到 49 Gb/秒,接近 DPU 上两个端口的峰值理论性能。
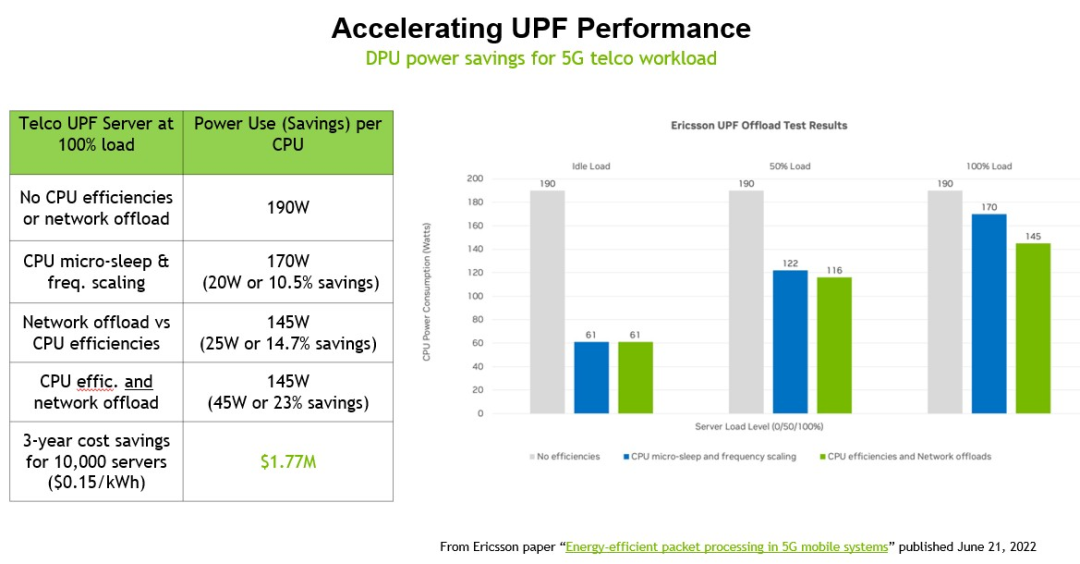
DPU 最关键的作用是在运行应用程序的服务器之间以及从服务器到访问应用程序和数据的客户端设备之间传输数据时对数据进行加密,因此英伟达创建了一个IPSec加密场景,用于加密应用程序的服务器端和客户端,以及将节省多少电力。

这组测试在配备一对英特尔“Ice Lake”至强 SP-830 处理器的服务器上运行,该处理器具有 40 个内核,每个内核以 2.3 GHzm 运行,带有一个 BlueField-2 卡,具有一对 100 GB/秒的以太网端口和 16 GB自带内存。在此设置中,服务器端 IPSec 加密和解密消耗 6 个物理内核(占内核的 7.5%),而客户端需要 20 个内核(占 25%)。抛开CPU 和运行 IPSec 的 DPU 之间是否存在性能差异,这个测试计算了将负载卸载到 DPU 所节省的电力,三年内通过 10,000 个节点可以节省 1420 万美元.

从这个比较中可以看出,为 10,000 个节点的每一个节点添加 BlueField-2 DPU 可以减少支持 IPSec 加密和解密工作负载所需的节点数量。根据英伟达的计算,服务器硬件的资本支出实际上降低了 2.4%,总体成本节省了 15%(这还没有考虑到性能差异、数据中心面积的节省以及管理的服务器的减少)。
就目前而言,为CPU减负是必然的。可以肯定地说,在未来的系统架构中,网络、存储访问、虚拟化工作负载和安全功能不会在 CPU 上完成。
DPU 将成为系统架构的中心,分配对计算和存储的访问权限,而CPU 则应该被称为具有庞大内存的串行处理单元。
-
共模电感选型依据究竟有哪些2024-05-06 555
-
PCBA打样加工究竟有哪些生产工序呢2023-09-28 1405
-
ICD与ICE之间究竟有什么区别和联系?2023-06-19 1296
-
户外电源究竟有什么功能与细节呢2021-12-30 2233
-
嵌入式系统究竟有何特点呢2021-12-22 1323
-
OpenPLC开源工业控制器究竟有何用处2021-09-02 8838
-
请问一下芯片制造究竟有多难?2021-06-18 3262
-
面向列的HBase存储结构究竟有什么样的不同之处呢?2021-06-16 1631
-
请问一下RFID与NFC究竟有什么关系?2021-06-15 2172
-
液晶PC与液晶电视究竟有什么区别?2021-06-07 2203
-
LED,LED背光,OLED三者之间究竟有怎样的区别和联系呢?2021-06-03 4150
-
物联网关键技术,RFID与NFC究竟有什么关系呢?2020-01-14 5320
-
都说IC设计高薪行业,薪水究竟有多高?大家来晒晒2011-12-19 18009
全部0条评论

快来发表一下你的评论吧 !
