

六自由度视觉定位
描述
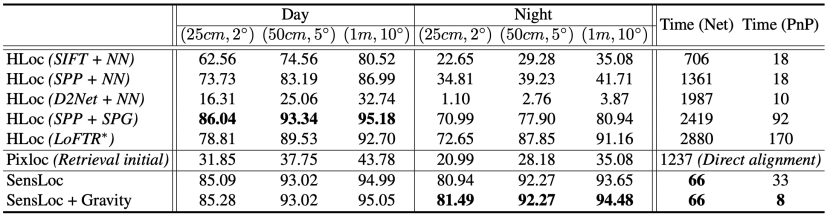
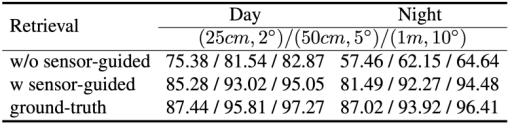
针对在时变的室外环境中难以视觉定位的问题,博士生颜深创新性地提出一种解决方案 SensLoc。SensLoc 利用移动设备内置的传感器数据,如 GPS、指南针和重力传感器,为视觉定位提供有效的初始位姿和约束条件,从而缩小图像检索和位姿估计的搜索空间。
此外,SensLoc 还设计了一个直接的 2D-3D 匹配网络,以高效地建立查询图像与三维场景之间的对应关系,避免了现有系统中需要多次进行 2D-2D 匹配的低效方案。为了验证 SensLoc 的有效性,论文还构建了一个新的数据集,该数据集包含了多种移动传感器数据和显著的场景外观变化,并开发了一个系统来获取查询图像的真实位姿。大量的实验表明 SensLoc 可以在时变的室外环境中实现准确、鲁棒且高效的视觉定位。
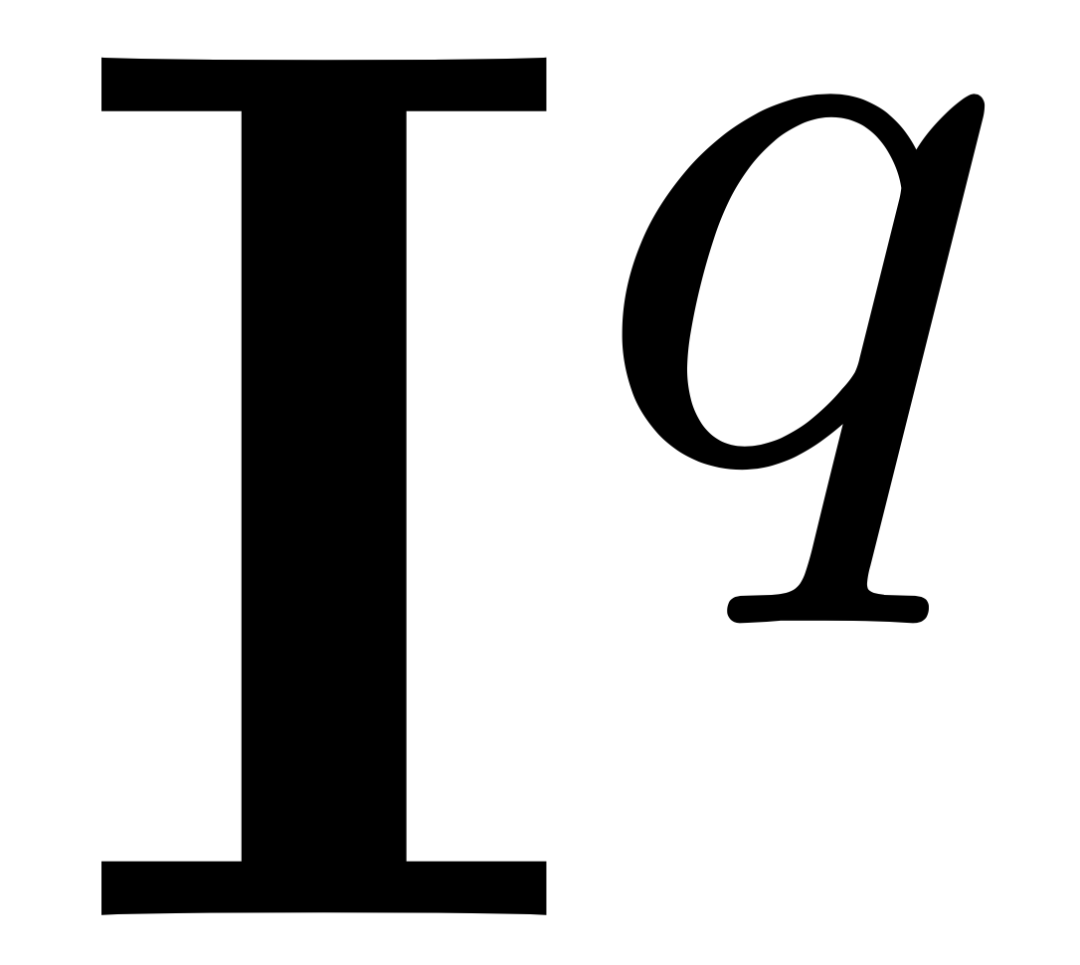 ,图像检索任务需要在参考图像集
,图像检索任务需要在参考图像集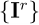 里找到与查询图有共视关系的图像子集:
里找到与查询图有共视关系的图像子集:
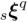 ,其位置分量来源于 GPS,旋转分量来自于重力计和指南针方向的集成。查询图像只需要在图像子集
,其位置分量来源于 GPS,旋转分量来自于重力计和指南针方向的集成。查询图像只需要在图像子集 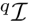 中检索共视邻居
中检索共视邻居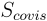
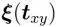 表示经纬度的 x-y 坐标,
表示经纬度的 x-y 坐标,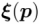 表示相机的主轴方向。
2 直接的 2D-3D 匹配
给定查询图
表示相机的主轴方向。
2 直接的 2D-3D 匹配
给定查询图 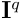 和共视邻居
和共视邻居 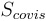 ,2D-3D 匹配任务需要建立 像素点与
,2D-3D 匹配任务需要建立 像素点与 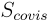 能观察到的局部点云
能观察到的局部点云 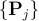 之间的 2D-3D 对应关系。
具体而言,首先使用多层级网络提取查询图
之间的 2D-3D 对应关系。
具体而言,首先使用多层级网络提取查询图 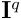 和参考图
和参考图 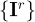 的粗(用
的粗(用 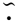 表示)、细(用
表示)、细(用  表示)粒度特征,然后将局部点云
表示)粒度特征,然后将局部点云 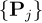 投影在参考特征图上并进行插值、平均,得到点云特征。
然后,使用带注意力机制的网络匹配查询图与局部点云的粗粒度特征,确定点云是否为查询图像所见,并初步确定它在图像上的位置。使用注意力机制变换后的粗粒度图像和点云特征分别为
投影在参考特征图上并进行插值、平均,得到点云特征。
然后,使用带注意力机制的网络匹配查询图与局部点云的粗粒度特征,确定点云是否为查询图像所见,并初步确定它在图像上的位置。使用注意力机制变换后的粗粒度图像和点云特征分别为 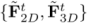 ,概率匹配矩阵
,概率匹配矩阵 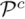 表示为
表示为
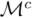 表示为
表示为
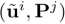 ,通过将点云的细粒度特征
,通过将点云的细粒度特征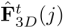 与在
与在 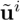 附近裁剪出细粒度窗口特征
附近裁剪出细粒度窗口特征 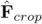 进行点乘,得到匹配概率并计算二维位置期望,获取查询图像的亚像素
进行点乘,得到匹配概率并计算二维位置期望,获取查询图像的亚像素 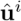 与局部点云 的精确对应关系。
3 基于重力方向的 PnP RANSAC
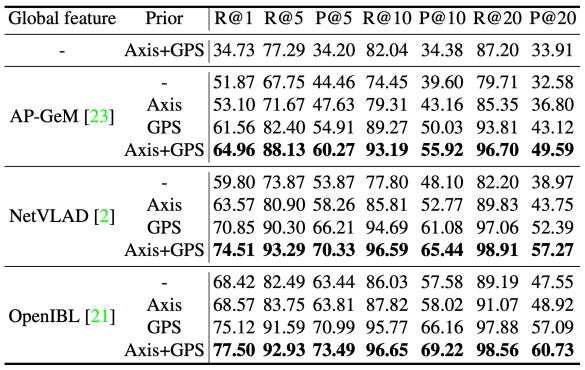
给定 2D-3D 的对应关系,之前的工作通常采用 PnP RANSAC 算法求解相机的六自由度位姿。论文在 PnP RANSAC 迭代中插入一个简单有效的验证模块,以保证重力方向的正确性。具体地,对于 RANSAC 迭代生成的位姿假设
与局部点云 的精确对应关系。
3 基于重力方向的 PnP RANSAC
给定 2D-3D 的对应关系,之前的工作通常采用 PnP RANSAC 算法求解相机的六自由度位姿。论文在 PnP RANSAC 迭代中插入一个简单有效的验证模块,以保证重力方向的正确性。具体地,对于 RANSAC 迭代生成的位姿假设 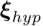 ,其与传感器位姿
,其与传感器位姿 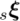 在重力方向
在重力方向 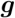 上差值为
上差值为
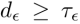 预先过滤掉大部分错误位姿,实现更高效、鲁棒的位姿解算。
数据集
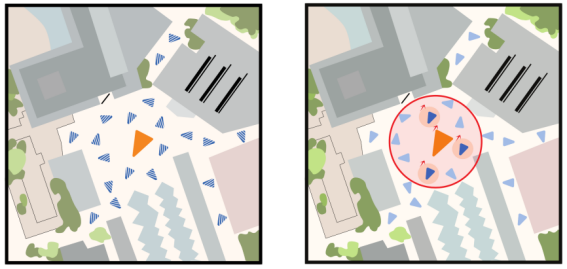
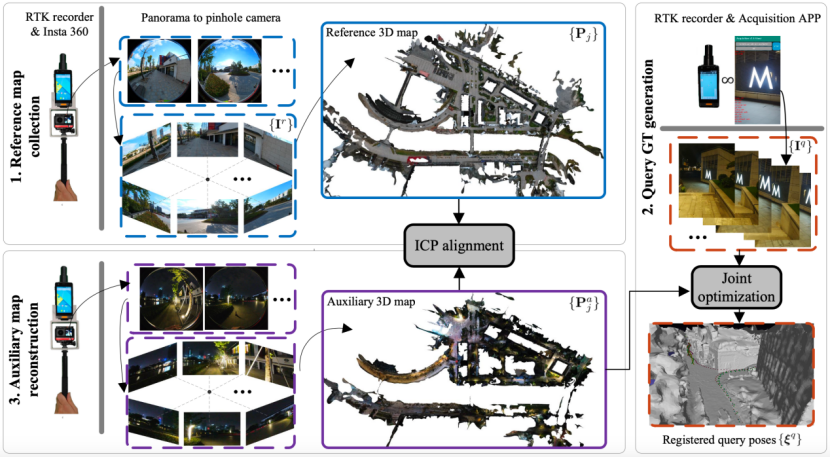
论文构建了一个新的数据集,用于验证所提方法的有效性。该数据集包括一个城市公园(约 31,250 平方米),包含植被、河流、建筑和人行道。作为一个公共区域,其不可避免地会经历各种场景的变化,例如不同光照、季节、天气,运动的行人、车辆,甚至新的基础设施建设。数据集的构建流程如下图所示。
预先过滤掉大部分错误位姿,实现更高效、鲁棒的位姿解算。
数据集
论文构建了一个新的数据集,用于验证所提方法的有效性。该数据集包括一个城市公园(约 31,250 平方米),包含植被、河流、建筑和人行道。作为一个公共区域,其不可避免地会经历各种场景的变化,例如不同光照、季节、天气,运动的行人、车辆,甚至新的基础设施建设。数据集的构建流程如下图所示。
 。相较于单目相机,全景相机具有更高的采集效率。将 7,958 张全景图像切分并转换为针孔模型后,该数据集包括 47,780 张参考图像。为了确定模型尺度并与地理坐标系保持一致,该研究预先在全景相机上绑定了一个 RTK 记录仪,以记录绝对地理坐标。
2 查询图像采集
在三维参考地图构建完成半年后,该研究在相同地址中行走,并开发了一款安卓应用程序 Acquisition Application(采集 APP),使用华为 P40 pro 和小米 Mix 3 手机拍摄视频以采集查询图像,并通过绑定 RTK 记录仪获取拍摄时的地理位置信息。该采集 APP 能够同时记录手机内置传感器的数据,包括 IMU、重力计、指南针、蓝牙、WiFi 和 GPS。拍摄视频与所有传感器均经过硬件同步和细致校准。由于论文关注于单图的视觉定位,因此视频序列会进行采样以生成不连续的单张图像。
3 三维辅助地图构建与伪位姿真值生成
由于查询图像与三维参考地图之间存在跨时节的变化,因此基于半年前构建的三维参考地图生成查询图像的伪位姿真值较为困难。论文提出在采集查询图像时,同时构建一个三维辅助地图
。相较于单目相机,全景相机具有更高的采集效率。将 7,958 张全景图像切分并转换为针孔模型后,该数据集包括 47,780 张参考图像。为了确定模型尺度并与地理坐标系保持一致,该研究预先在全景相机上绑定了一个 RTK 记录仪,以记录绝对地理坐标。
2 查询图像采集
在三维参考地图构建完成半年后,该研究在相同地址中行走,并开发了一款安卓应用程序 Acquisition Application(采集 APP),使用华为 P40 pro 和小米 Mix 3 手机拍摄视频以采集查询图像,并通过绑定 RTK 记录仪获取拍摄时的地理位置信息。该采集 APP 能够同时记录手机内置传感器的数据,包括 IMU、重力计、指南针、蓝牙、WiFi 和 GPS。拍摄视频与所有传感器均经过硬件同步和细致校准。由于论文关注于单图的视觉定位,因此视频序列会进行采样以生成不连续的单张图像。
3 三维辅助地图构建与伪位姿真值生成
由于查询图像与三维参考地图之间存在跨时节的变化,因此基于半年前构建的三维参考地图生成查询图像的伪位姿真值较为困难。论文提出在采集查询图像时,同时构建一个三维辅助地图 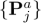 。三维辅助地图的构建方法与三维参考地图类似,同样使用全景相机和 RTK 记录仪进行采集,并采用 ICP 技术进行对齐。基于三维辅助地图生成查询图像的伪真值等同于基于三维参考地图生成的伪真值。论文设计了一套联合优化方法生成伪真值,优化项包括:1)图像自定位约束;2)序列图像的相对位姿约束;3)IMU 的运动约束;4)其他先验约束,如重力方向和 RTK 位置。
。三维辅助地图的构建方法与三维参考地图类似,同样使用全景相机和 RTK 记录仪进行采集,并采用 ICP 技术进行对齐。基于三维辅助地图生成查询图像的伪真值等同于基于三维参考地图生成的伪真值。论文设计了一套联合优化方法生成伪真值,优化项包括:1)图像自定位约束;2)序列图像的相对位姿约束;3)IMU 的运动约束;4)其他先验约束,如重力方向和 RTK 位置。

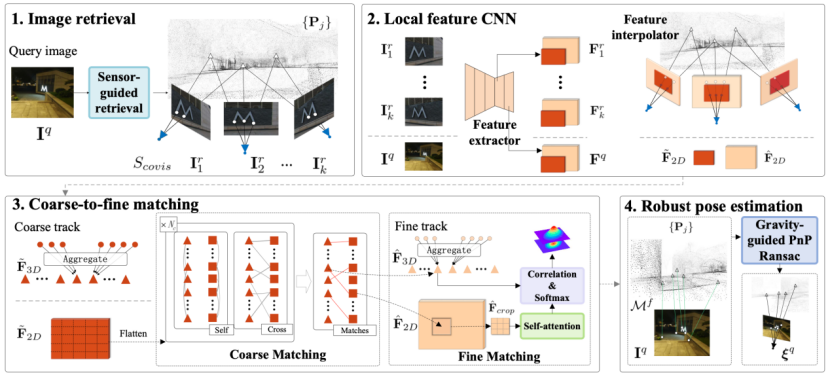
,图像检索任务需要在参考图像集里找到与查询图有共视关系的图像子集:
,其位置分量来源于 GPS,旋转分量来自于重力计和指南针方向的集成。查询图像只需要在图像子集 中检索共视邻居
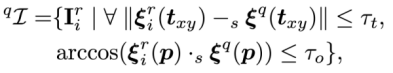
表示经纬度的 x-y 坐标,表示相机的主轴方向。
2 直接的 2D-3D 匹配
给定查询图 和共视邻居 ,2D-3D 匹配任务需要建立 像素点与 能观察到的局部点云 之间的 2D-3D 对应关系。
具体而言,首先使用多层级网络提取查询图 和参考图 的粗(用 表示)、细(用 表示)粒度特征,然后将局部点云 投影在参考特征图上并进行插值、平均,得到点云特征。
然后,使用带注意力机制的网络匹配查询图与局部点云的粗粒度特征,确定点云是否为查询图像所见,并初步确定它在图像上的位置。使用注意力机制变换后的粗粒度图像和点云特征分别为 ,概率匹配矩阵 表示为
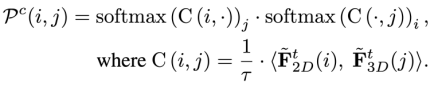
表示为
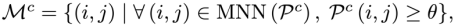
 为互最近邻,
为互最近邻,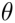 为预设阈值。
为预设阈值。
最后,对于每一个粗匹配对应的二维像素和三维点云
,通过将点云的细粒度特征与在 附近裁剪出细粒度窗口特征 进行点乘,得到匹配概率并计算二维位置期望,获取查询图像的亚像素 与局部点云 的精确对应关系。
3 基于重力方向的 PnP RANSAC
给定 2D-3D 的对应关系,之前的工作通常采用 PnP RANSAC 算法求解相机的六自由度位姿。论文在 PnP RANSAC 迭代中插入一个简单有效的验证模块,以保证重力方向的正确性。具体地,对于 RANSAC 迭代生成的位姿假设 ,其与传感器位姿 在重力方向 上差值为
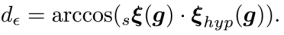
预先过滤掉大部分错误位姿,实现更高效、鲁棒的位姿解算。
数据集
论文构建了一个新的数据集,用于验证所提方法的有效性。该数据集包括一个城市公园(约 31,250 平方米),包含植被、河流、建筑和人行道。作为一个公共区域,其不可避免地会经历各种场景的变化,例如不同光照、季节、天气,运动的行人、车辆,甚至新的基础设施建设。数据集的构建流程如下图所示。
。相较于单目相机,全景相机具有更高的采集效率。将 7,958 张全景图像切分并转换为针孔模型后,该数据集包括 47,780 张参考图像。为了确定模型尺度并与地理坐标系保持一致,该研究预先在全景相机上绑定了一个 RTK 记录仪,以记录绝对地理坐标。
2 查询图像采集
在三维参考地图构建完成半年后,该研究在相同地址中行走,并开发了一款安卓应用程序 Acquisition Application(采集 APP),使用华为 P40 pro 和小米 Mix 3 手机拍摄视频以采集查询图像,并通过绑定 RTK 记录仪获取拍摄时的地理位置信息。该采集 APP 能够同时记录手机内置传感器的数据,包括 IMU、重力计、指南针、蓝牙、WiFi 和 GPS。拍摄视频与所有传感器均经过硬件同步和细致校准。由于论文关注于单图的视觉定位,因此视频序列会进行采样以生成不连续的单张图像。
3 三维辅助地图构建与伪位姿真值生成
由于查询图像与三维参考地图之间存在跨时节的变化,因此基于半年前构建的三维参考地图生成查询图像的伪位姿真值较为困难。论文提出在采集查询图像时,同时构建一个三维辅助地图 。三维辅助地图的构建方法与三维参考地图类似,同样使用全景相机和 RTK 记录仪进行采集,并采用 ICP 技术进行对齐。基于三维辅助地图生成查询图像的伪真值等同于基于三维参考地图生成的伪真值。论文设计了一套联合优化方法生成伪真值,优化项包括:1)图像自定位约束;2)序列图像的相对位姿约束;3)IMU 的运动约束;4)其他先验约束,如重力方向和 RTK 位置。
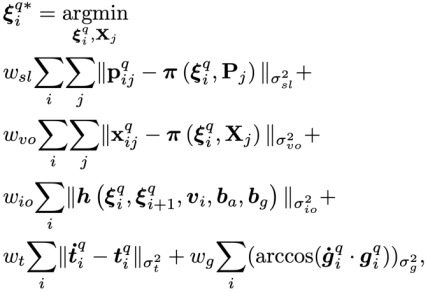
审核编辑 :李倩
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
基于FPGA EtherCAT的六自由度机器人视觉伺服控制设计2024-05-29 1045
-
基于FPGA的六自由度机器人视觉伺服控制方案设计2024-04-24 1560
-
基于Matlab的开源六自由度协作机器人实验平台2021-09-07 1622
-
ADIS16495:战术级六自由度惯性传感器数据表2021-05-25 1146
-
ADIS16385:六自由度惯性传感器报废数据表2021-05-24 868
-
ADIS16485:战术级六自由度惯性传感器数据表2021-05-23 963
-
ADIS16367:六自由度惯性传感器报废数据表2021-05-10 837
-
什么是六自由度压电纳米定位台,它的作用是什么2020-08-10 1872
-
六自由度液压运动平台的迭代学习控制卢颖2017-03-15 814
-
关于六个自由度座椅的控制2017-01-13 3764
-
超声波在六自由度测量定位系统中的应用2016-05-04 614
-
基于STM32、以太网、Labview的六自由度Stewart并联运动平台模型2014-04-16 6072
-
DSP在六自由度电磁跟踪系统中的应用2011-01-25 1823
全部0条评论

快来发表一下你的评论吧 !
