

Lightelligence使用Cadence Xcelium多核加速DFT仿真
EDA/IC设计
描述
当今片上系统的设计复杂性日益增加,可能导致长达数小时、数天甚至数周的可测试性 (DFT) 仿真设计。由于这些往往发生在专用集成电路(ASIC)项目结束时,当工程变更单(ECO)强制重新运行这些长时间的DFT仿真时,它可能会影响流片计划数天和数周。这些 DFT 模拟具有很长的运行时间,因为它们通常具有高事件密度(每个模拟时间的事件数),并且传统事件模拟器会随着事件密度的增加而变慢。需要一种新的方法。
Lightelligence是一家专门从事人工智能和光学计算的科技公司。该公司专注于开发用于机器学习、计算机视觉和数据分析的新技术,利用光的独特特性为下一代创新提供动力。Lightelligence是全球唯一一家展示工作和完全集成的光学计算系统的公司。
Lightelligence旨在为各种应用提供高速,低功耗和节能的AI解决方案。Cadence的Xcelium多核GLS仿真以及其他Cadence产品和解决方案对Lightelligence构建其技术至关重要。Lightelligence团队与Cadence接洽,以加快超长的DFT模拟。长延迟模拟影响了他们的流片里程碑。本博客介绍了使用 Xcelium 的高效门级仿真方法如何帮助 Lightelligence 解决长延迟问题,缩短回归时间,从而提高性能。
低延迟和高延迟仿真都会影响流片里程碑
对于大容量、低延迟的模拟,执行时间从几秒钟到一小时不等。它的内存占用量相对较低(数亿到数百万个作业),回归运行时往往会在项目后期达到峰值。对于小容量、高延迟仿真,通常是门级仿真 (GLS)、标准延迟格式 (SDF) 和 DFT 仿真,执行需要数小时、数天或数周。它具有相对较高的内存占用和数十个作业。回归运行时间往往在项目后期达到峰值,大约在流片前后。Xcelium解决方案解决了这两种类型的仿真挑战。
解决传统仿真引擎中长延迟问题的 GLS 方法
多线程波形转储
在具有多个CPU的机器上运行的传统模拟器可以提高波形转储的性能。在多进程模式下,模拟器启动一个单独的可执行文件,用于执行一些波形转储处理。该进程在不同的 CPU 上并行运行,直到主进程退出,从而将性能提高 5% 到 2 倍,具体取决于探测的对象数。
保存/还原和检查点
从初始化状态保存/还原可减少运行时间。Xcelium 仿真器的保存和恢复功能通过减少重新运行多个长仿真常见的测试段所浪费的时间,极大地缩短了周转时间。在运行时环境中保存初始化状态并从初始化状态还原有助于减少系统的整体运行时间。它提供了仅初始化一次并从该点重新运行它的选项,以避免数小时的初始化。保存和还原有助于检查点长延迟运行,以减少调试周期时间,并以更高的吞吐量完成回归。
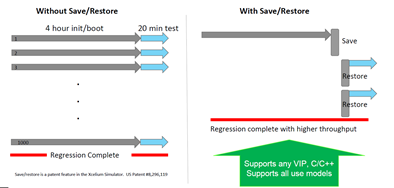
独特的仿真解决方案
Xcelium多核将仿真事件分布在多个核之间,从而实现更快的仿真。在单个实例上为高活动测试处理许多模拟事件。高活动仿真事件分布在众多服务器内核上,以加速设计。在低活动测试中,缓存中除一个内核外的所有内核都被阻塞,从而导致高缓存命中率,从而在更快的仿真中出现。
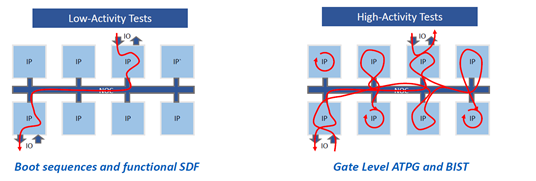
并行性和活动性
与一般假设不同,设计内部的并行性不是结构复制。Xcelium 多核并行性是关于语言并行性的,这存在于所有设计中。镉曲线测试活性。多核需要并行块才能激活。活动克服了管理核心之间通信的开销。随着活动的增加,间接成本会降低。
Xcelium多核在ATPG测试中实现了3倍的加速
Lightelligence团队在流片附近经历了为期5天的自动测试模式生成(ATPG)模拟。ATPG测试由Cadence Modus DFT软件解决方案生成。具有几乎相同脚本的 Xcelium 多核有助于在 ATPG 回归的平均测试中实现 3 倍的加速。
长延迟门级功能和DFT仿真发生在设计周期的后期,导致回归重新运行的更改会延迟流片。高效的门级仿真方法,包括保存/重启和 Xcelium 多核,可缩短回归时间。Lightelligence应用了Xcelium多核,对其DFT模拟设置进行了最小的更改,以实现高达3倍的加速。
审核编辑:郭婷
-
加速多物理场系统仿真布局,Cadence 的几大“法宝”2023-09-09 3198
-
如何理解Xcelium的多核仿真呢?2023-03-28 3048
-
CadenceTECHTALK:使用 Xcelium Logic Simulator 获得最优性能2023-01-11 1205
-
Cadence仿真步骤.zip2022-12-30 761
-
Cadence推出 Xcelium Apps应用程序系列产品2022-06-30 3926
-
Cadence发布Helium Virtual和Hybrid Studio平台,加速移动、汽车及超大规模系统开发2021-09-23 2324
-
如何使用DFT App进行硬件加速仿真设计2019-09-16 2827
-
寒武纪首款智能云端芯片应用Cadence Z1硬件仿真加速平台2018-05-08 11913
-
加速人工智能工作负载 百度投资初创公司Lightelligence2018-02-05 1093
-
Cadence发布业界首款已通过产品流片验证的Xcelium并行仿真平台2017-03-01 6445
-
cadence_specctraquest仿真教程2016-02-22 1087
-
Cadence 仿真流程2015-12-08 951
-
Cadence仿真流程2008-07-12 1625
全部0条评论

快来发表一下你的评论吧 !
