

后ChatGPT时代NLP的下一个方向:增强式大规模语言模型
描述
引言
目前,大规模语言模型(LLM)在自然语言处理领域表现出了惊人的性能,能够完成前所未有的任务,为更多的人机交互形式打开了大门,ChatGPT是一个最好的例子。然而,LLM在大规模推广中受到了一些限制,其中一些限制源于其单参数模型和有限的上下文(N个token)等基本缺陷。随着硬件和软件技术的不断发展,LLM需要更长的上下文来展现其更强大的能力,但在实践中,大多数LLM仍然只能使用较小的上下文尺寸。为了解决这些问题,出现了增强语言模型(ALM),它是一种利用外部信息来增强语言模型的方法。ALM包括推理、工具和行为三个方面,通过这些方面的增强,语言模型可以调用其他工具来解决更加复杂的任务,并对虚拟或真实世界产生影响并观察结果。本文介绍2种最近出现的增强式语言模型去完成各种模态的交互式任务:1)VisualChatGPT;2)Toolformer。
文章概览
文章概览
Visual-ChatGPT

微软最近的一个开源项目:Visual ChatGPT,让用户能够用交互的形式与大规模语言模型完成图片操作的任务。以此为 ChatGPT 提供了新的玩法。
论文:https://arxiv.org/abs/2303.04671
论文细节
介绍
Visual ChatGPT 是一种智能交互系统,它将不同的视觉基础模型与 ChatGPT 相结合,使得用户可以通过发送语言和图像与 AI 系统进行交互。与传统的 ChatGPT 仅支持文字交互不同,Visual ChatGPT 可以支持文字+图片的交互方式。除了可以进行简单的对话外,Visual ChatGPT 还可以接收复杂的视觉问题或视觉编辑指令,并要求多个 AI 模型之间进行协作和多步骤操作。用户还可以给出反馈,并要求修改结果,从而实现更加智能化、人性化的交互体验。简而言之,Visual ChatGPT 使用户可以以一种更加丰富、直观和自然的方式与 AI 系统进行交互。
用户可以发送以下几种指令进行交互:
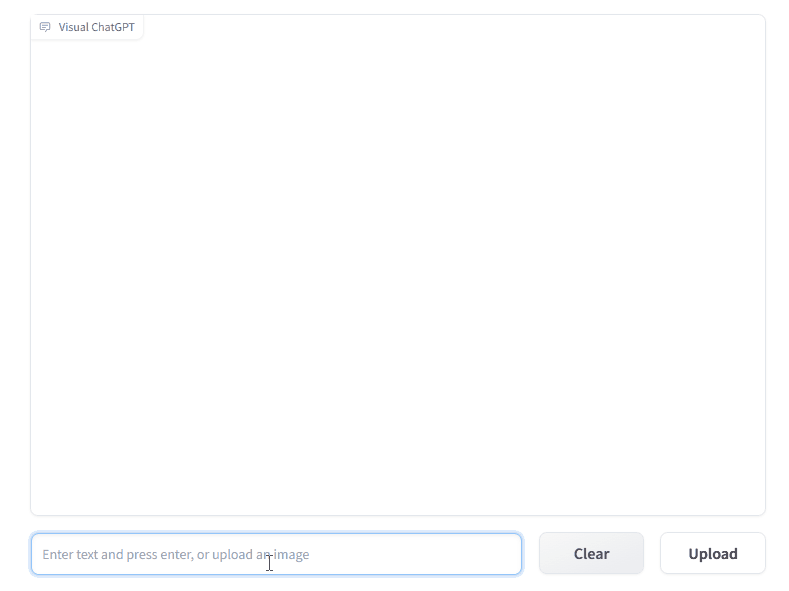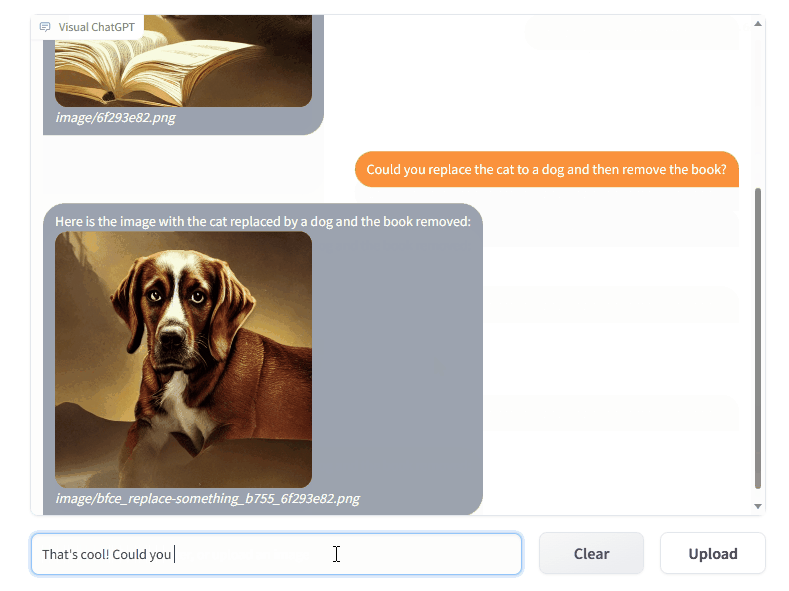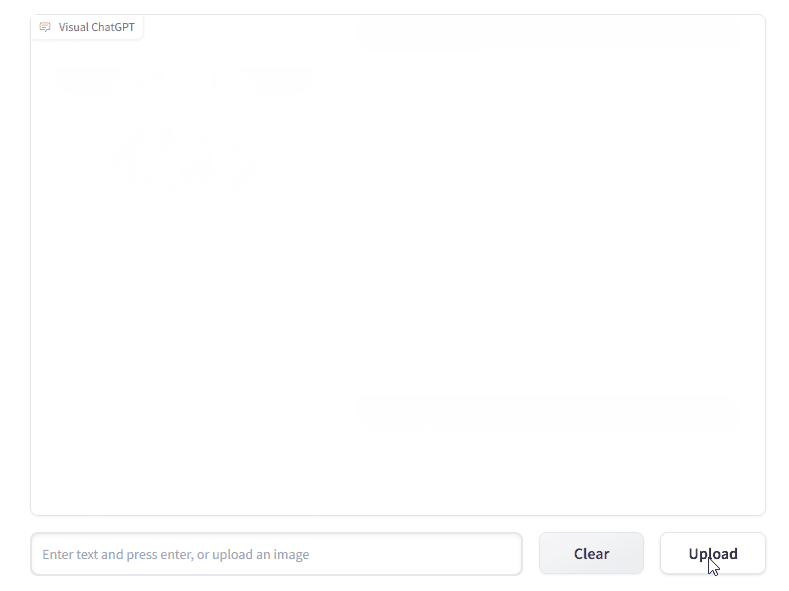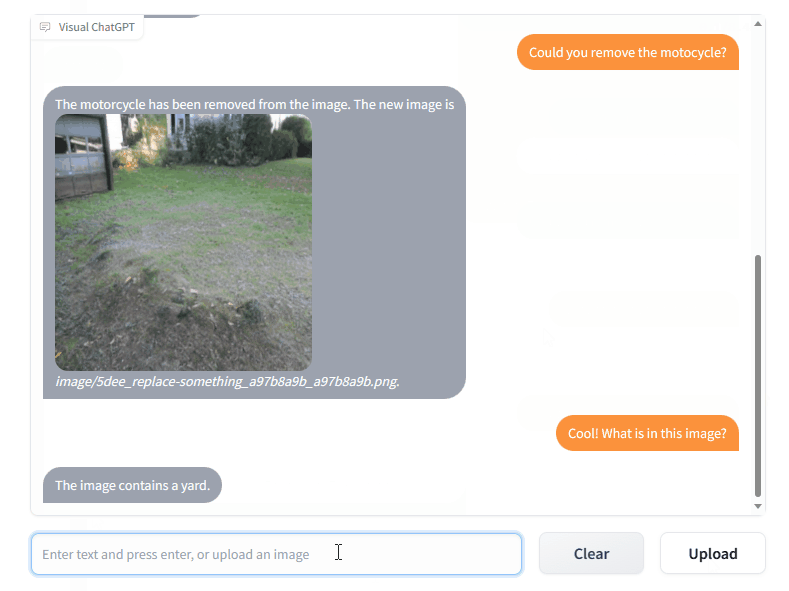
发送和接收不仅是语言而且是图像
提供复杂的视觉问题或视觉编辑指令,需要多个 AI 模型之间的协作和多步骤操作
提供反馈并要求修改结果,并且它能够根据用户反馈修改结果
方法
文中作者让ChatGPT与其他视觉模型进行交互,下游模型称作VFM, 是 Visual Foundation Model(视觉基础模型)缩写,其中Stable Diffusion、ControlNet、BLIP 等图像处理类模型。作者还提出了提示管理器(Prompt Manger)作为 ChatGPT 和 VFM 之间的桥梁。提示管理器(Prompt Manger)明确告知 ChatGPT 每个 VFM 的功能并指定必要的输入输出格式; 它将各种类型的视觉信息(例如 png 图像、深度图像和遮罩矩阵)转换为语言格式以帮助 ChatGPT 理解。同时管理不同 VFM 的历史记录、优先级和冲突; 通过使用提示管理器,ChatGPT 可以有效地利用 VFM 并以迭代的方式接收他们的反馈,直到满足用户的要求或达到结束条件。
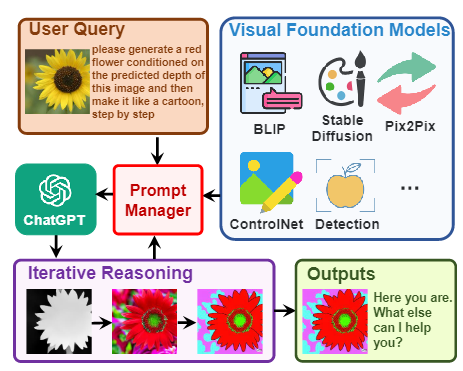
详细的整体结构如下:
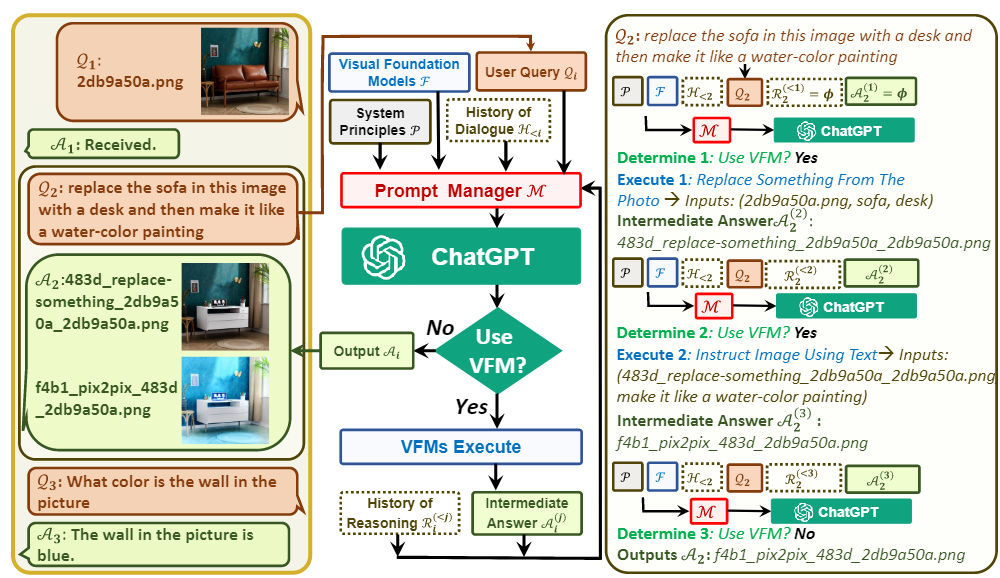
从左到右分为了三个部分,中间部分详细展示了模型接收到提问(Query)后,会判断是否需要使用 VFM 进行处理,如果需要则会调用下游的VFM相应的模型为这个指令进行回答。
Visual-ChatGPT特点
Visual ChatGPT 扩展了聊天机器人的输入和输出范围,超越了传统的基于文本的通信。它可以处理文本和图像信息,并根据用户需求生成各种格式的回复。
Visual ChatGPT 提高了聊天机器人的智能水平。传统的聊天机器人只能在单一领域或任务上表现出智能行为,而 Visual ChatGPT 可以在多个领域或任务上表现出智能行为,并且可以根据上下文切换不同模式。
Visual ChatGPT 增加了聊天机器人的趣味性和互动性。与传统的聊天机器人只能进行简单而枯燥的对话不同,Visual ChatGPT 可以进行富有创意和想象力的对话,并且可以根据用户喜好调整风格。
文章概览
Toolformer

论文地址:https://arxiv.org/pdf/2302.04761v1.pdf
论文细节
介绍
大型语言模型存在一些局限性,例如无法获取最新信息、可能会产生“信息幻觉”、难以理解低资源语言以及缺乏进行精确计算的数学技能等。为了解决这些问题,一种简单的方法是为模型提供外部工具,例如搜索引擎、计算器或日历。然而,现有方法通常需要大量的人工注释或将工具的使用限制在特定任务设置下,这使得语言模型与外部工具的结合使用难以推广。为了克服这种瓶颈,Meta AI 最近提出了一种名为 Toolformer 的新方法,该方法使得语言模型能够学会“使用”各种外部工具。
Toolformer满足了以下实际需求:
大型语言模型应该在自监督的方式下学习工具的使用,而不需要大量的人工注释。人工注释的成本很高,而且人类认为有用的东西可能与模型认为有用的东西不同。
语言模型需要更全面地使用不受特定任务约束的工具。Toolformer打破了大语言模型的瓶颈。接下来我们将详细介绍Toolformer的方法
方法
Toolformer基于带有in-context learning(ICL)的大型语言模型从头开始生成数据集。这种方法只需要提供少量人类使用API的样本,就可以让语言模型用潜在的API调用标注一个巨大的语言建模数据集。然后,使用自监督损失函数来确定哪些API调用实际上有助于模型预测未来的token,并根据对LM本身有用的API调用进行微调。由于Toolformer与所使用的数据集无关,因此可以将其用于与模型预训练完全相同的数据集,这确保了模型不会失去任何通用性和语言建模能力。具体来说,该研究旨在让语言模型具备一种能力——通过API调用使用各种工具。为了实现这个目标,每个API的输入和输出都可以表征为文本序列。这允许将API调用无缝插入到任何给定文本中,并使用特殊的token来标记每个此类调用的开始和结束。
该工作把每个API调用建模为一个元祖,如下所示:
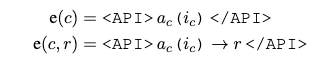
其中 是 API 的名称, 是相应的输入。给定一个API调用c和一个对应的结果r,上面的式子表示不带有结果的API调用,下面的式子表示带有API调用的结果的线性化序列。其中


给定一个只含有普通文本的数据集
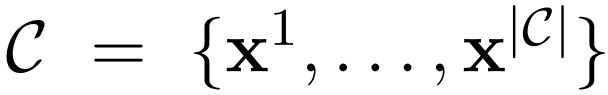
作者首先将这个数据集转换成一个增加了 API 调用表示的数据集 C*。这个操作分为三步如下图所示
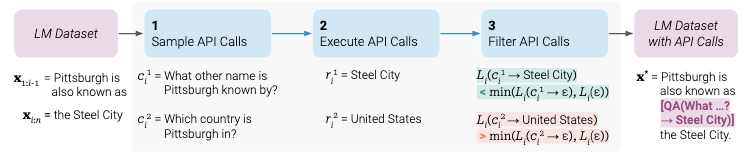
1)首先,该研究利用 LM 的 in-context learning 能力对大量潜在的 API 调用进行采样
2)然后执行这些 API 调用
3)再检查获得的响应是否有助于预测未来的 token,以用作筛选标准。
4) 筛选之后,该研究合并对不同工具的 API 调用,最终生成数据集 C*,并在此数据集上微调 LM 本身。
Toolformer结合了一系列的工具,包括一个计算器、一个Q/A系统、两个不同的搜索引擎、一个翻译系统和一个日历。Toolformer在各种下游任务中实现了大幅提高的零样本性能,通常与更大的模型竞争,而不牺牲其核心语言建模能力。
总结
本文介绍了两种增强式大语言模型(Visual-ChatGPT,Toolformer),使得大语言模型能够通过调用其他基础视觉模型,来通过交互让用户能够与大规模语言模型进行多模态任务的沟通;并且,通过构建API数据集的方式微调,让大规模语言模型学会利用调用API来执行各种任务。在当今火爆的大语言模型的浪潮下,增强式语言模型的范式为我们前往通用人工智能提供了有力的支持。
审核编辑 :李倩
-
ChatGPT爆火背后,NLP呈爆发式增长!2023-02-13 4337
-
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践2024-03-11 16144
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
【大规模语言模型:从理论到实践】- 每日进步一点点2024-05-31 2748
-
名单公布!【书籍评测活动NO.34】大语言模型应用指南:以ChatGPT为起点,从入门到精通的AI实践教程2024-06-03 50960
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2375
-
人类科技的下一个时代将是VR/AR的时代2019-08-30 1958
-
C 语言的下一个 ISO标准将会是 C2x ?2020-02-27 3823
-
下一个更智能的物联网时代:RFID的机会与挑战2021-05-08 3163
-
如何向大规模预训练语言模型中融入知识?2021-06-23 6325
-
NVIDIA NeMo最新语言模型服务帮助开发者定制大规模语言模型2022-09-22 1316
-
检索增强的语言模型方法的详细剖析2023-08-21 3359
-
人工智能nlp是什么方向2023-08-22 3473
-
大规模语言模型的基本概念、发展历程和构建流程2023-12-07 6729
-
llm模型和chatGPT的区别2024-07-09 2864
全部0条评论

快来发表一下你的评论吧 !
