

多语言AI的现状
描述
-01-
作者介绍
Sebastian Ruder是Google的研究科学家,致力于研究代表性不足的语言的自然语言处理(NLP)。在此之前,他是DeepMind的研究科学家。他在Insight Research Centre for Data Analytics完成了自然语言处理和深度学习博士学位。在学习期间,他曾与微软,IBM的Extreme Blue,Google Summer of Code和SAP等公司合作。
-02-
译者说
据统计,世界上有超过7000种不同的语言,每种语言都承载着不同的文化。但是在历史的长河中,已经有很多语言已经消失或者濒临消失。笛卡尔曾经说过:“语言的分歧是人生最大的不幸之一”。长久以来,实现不同语言之间的互通,能够在经济活动、文化交流中消除语言造成的隔阂,是人类共同努力的方向。多语言的模型可以抵消现有的语言鸿沟,确保一些非主流语言的使用者不会落后。而当下的一些语言模型主要集中在英语和其他具有大量资源的语言上,对一些濒危语言或者代表性较差的语言的研究十分不足。无论是当下最流行的语言模型比如ChatGPT(目前我们已知它支持至少95种语言),还是Meta-AI最新开发的多语言模型NLLB-200(目前种类最多的多语言翻译模型,可以实现200+语言的互译),都无法实现世界上所有语言的互通,就更不用提在低资源语言上进行其他研究了。因此,开发适用于更多语言的模型十分重要。
原文链接:https://www.ruder.io/state-of-multilingual-ai/
-03-
译文大纲
多语言研究现状
近期进展
挑战与机遇
-04-
译文
多语言研究现状:全世界大约有7000种语言。大约400种语言的用户超过100万,大约200种语言的用户超过10万[1]。有研究人员[2]回顾了在ACL 2008上发表的论文,发现63%的论文都集中在英语上。对于最近的一项研究[3],同样回顾了ACL 2021的论文,发现近70%的论文仅在英语上进行评估。10年过去了,以英语为主流的现象似乎没有什么变化。 同样的,使用这些低资源语言的研究人员在ML和NLP社区中的代表性同样不足。例如,虽然我们可以观察到隶属于非洲大学的作者数量在顶级机器学习(ML)和NLP场所发表文章略有上升趋势,但与每年来自其他地区的数千名作者在这些场所发表文章相比,这种增长相形见绌。
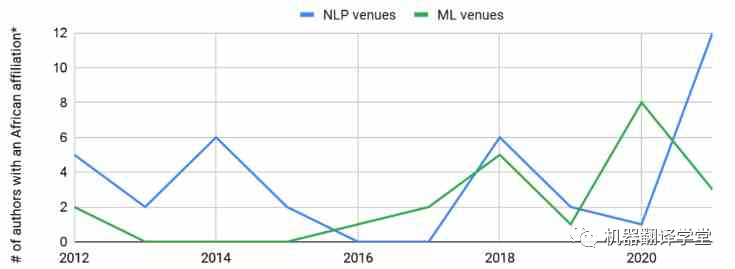
图1. 非洲NLP研究人员在顶级ML和NLP会议中的代表。*:不考虑在国外工作的非洲作家。数据基于:Marek Rei的ml_nlp_paper_data。NLP会议:ACL,CL,COLING,CoNLL,EACL,EMNLP,NAACL,TACL;ML会议:AAAI,ICLR,ICML,NeurIPS。
许多 ML 领域中当前最先进的模型主要基于两个要素:1) 大型的可扩展模型结构(通常基于 Transformer[4])和 2)迁移学习[5]。鉴于这些模型的一般性质,它们可以应用于各种类型的数据,包括图像[6],视频[7]和音频[8]。最近NLP中一些成功的模型如BERT[9],RoBERTa[10],BART[11],T5[12]和DeBERTa[13],它们使用了多种掩码语言建模(masked language modeling)方法的变体在数十亿个token的文本上进行了训练。在语音方面,wav2vec 2.0[14]也在大量未标记的语音上进行了预训练。
多语言模型: 在当下的深度学习领域中,许多较为先进的模型都在数十亿个token的文本上使用了多种掩码语言建模(masked language modeling)进行预训练。在NLP中,诸如mBERT,RemBERT[15],XLM-RoBERTa[16],mBART[17],mT5[18]和mDeBERTa[13]等模型,都使用了类似的方式进行训练:在大约100种语言的预料上,随机预测被mask的token。与单语模型相比,这些多语言模型需要更大的词汇表来表示多种语言中的token。同时,也有一些研究致力于学习更鲁棒的多语言表示,包括shared token[19],subword fertility[20]和词嵌入对齐[21]等方法。在语音中,XSLR[22]和 UniSpeech[23]等模型分别针对 53 种和 60 种语言的大量未标记数据进行了预训练。
多语言的诅咒: 为什么这些模型最多只能涵盖 200种语言?其中一个原因是“多语言的诅咒”[16]。与许多其他任务的训练过程相似,模型预训练数据的语言越多,可用于学习每种语言表示的模型容量就越少。增加模型的大小在一定程度上可以改善这一点,使得模型能够为每种语言提供更多容量[24]。
预训练数据的缺乏: 除了模型容量,多语言模型的另一个限制因素是数据。网络上的数据偏向于西方国家使用的语言,对于那些低资源数据严重不足。这令人担忧,因为之前有研究表明,预训练数据量与某些任务的下游性能相关[25][26][27]。特别是,在预训练期间从未见过的语言通常会导致模型在实际应用中性能不佳[28][29]。
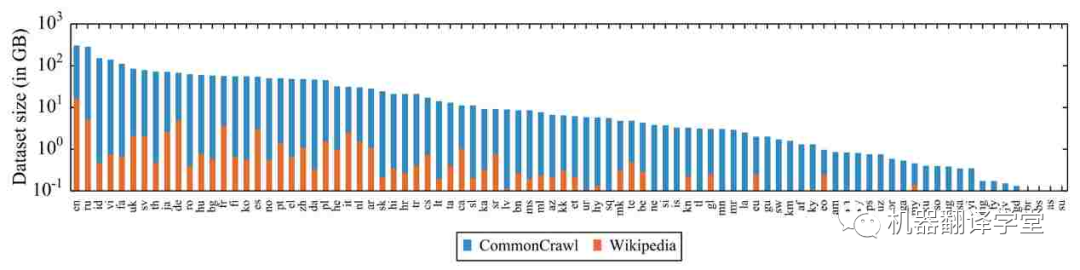
图2. 维基百科和 CommonCrawl[16] 中统计的 88 种语言和其对应的数据量(对数尺度)。
现有多语言资源的质量问题 :即使对于数据丰富的语言,过去的工作也表明,一些常用的多语言资源存在严重的质量问题。例如WikiAnn[30](基于维基百科的弱监督多语言命名实体识别数据集)中的实体跨度有很多是错误的[31]。同样,一些自动挖掘的资源和用于机器翻译的自动对齐语料库也是有问题的[32]。但是总的来说,在代表性不足的语言中,性能似乎主要受到数据数量而不是质量的限制[33]。
多语言评估 :我们可以在一些具有代表性的多语言评估指标(例如XTREME[25]和SuperGLUE[34])上查看最新模型的性能,从而更好地了解最新技术。该XTREME可以测试模型在9个任务和40种语言上的性能。从两年半前的第一个多语言预训练模型开始,多语言模型的性能稳步提高,并且正在慢慢接近基准测试上的人类水平。
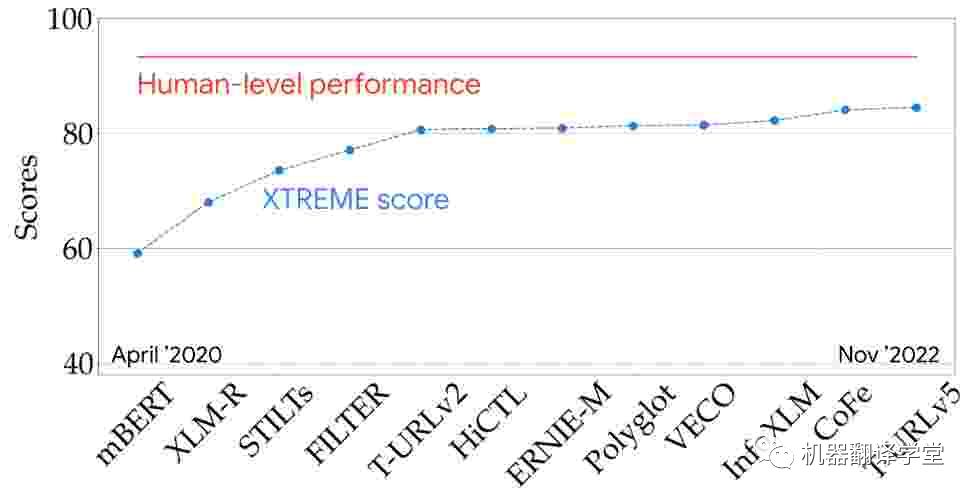
图3. 模型在 XTREME 排行榜上的表现(9 个任务和 40 种语言)
多语言模型和以英语为中心的模型 :观察最近 NLP 中的大型语言模型,我们根据预训练中的非英语数据的比例绘制了如下图片。基于这种特征,我们可以发现有两个不同的研究流派:1)直接使用多种语言数据进行训练的多语言模型和2)主要在英语数据上训练的以英语为中心的模型。
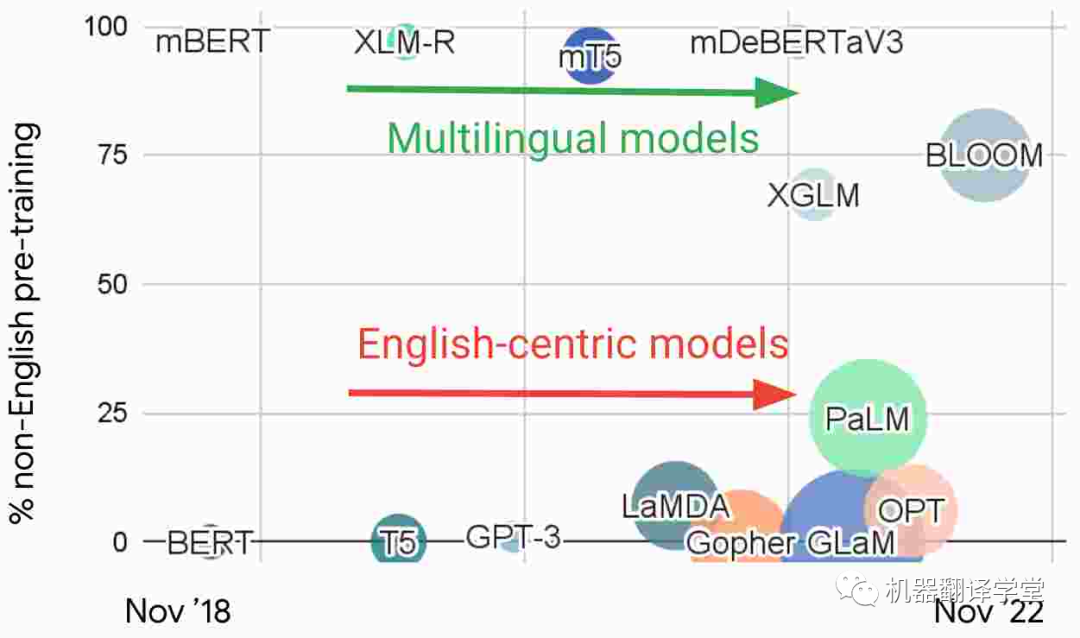
图4. 近期一些大语言模型中预训练数据中非英语数据的比例
以英语为中心的模型构成了NLP研究主流的基础,虽然这些模型越来越大,但它们并没有变得更加多语言。例如,GPT-3[35]和 PaLM[36]可以在具有大量数据的语言之间翻译文本。虽然它们已被证明能够执行多语言的few-shot学习[37][38][39],但当prompt或输入数据被翻译成英语时,模型表现最佳。在非英语语言对之间翻译或翻译成低资源的语言时,它们的表现也很差。虽然 PaLM 能够将非英语文本汇总为英语,但在生成其他语言的文本时却很困难。
近期进展
原博客对于多语言领域的研究团体,领域会议等进行了介绍,由于篇幅原因,我们先略过这部分,只介绍在数据集和模型方面的进展,感兴趣的同学可以去原博客学习。
数据集 :在研究方面,在一些代表性比较低的语言上,出现了一系列新的数据集,它们包含了许多任务,包括文本分类[40],情感分析[41],ASR,命名实体识别[42],问答[43]和摘要[44]等等。

图5. MasakhaNER中非洲语言的命名实体注释。PER、LOC 和 DATE 实体分别为紫色、橙色和绿色(Adelani 等人,2021 年)[42]
模型 :在多语言领域开发的新模型特别关注代表性不足的语言。有专注于非洲语言的基于文本(text-based)的语言模型,如AfriBERTa[45],AfroXLM-R[46]和KinyaBERT[47],以及印度尼西亚语言的模型,如IndoBERT[48][49]和IndoGPT[50]。对于印度语言,有IndicBERT[51]和MuRIL[52],以及语音模型,如CLSRIL[53]和IndicWav2Vec[54]。其中许多模型是先在几种相关语言上进行训练,因此能够利用迁移学习,并且比较大的多语言模型更有效。论文[55]和[56]中论述了最近NLP和语音中的多语言模型的进展。
-03-
挑战与机遇
挑战1:有限的数据
可以说,多语言研究面临的最大挑战是世界上大多数语言可用的数据量有限。Joshi等人[57]根据其中可用的标记和未标记数据量将世界语言分为六个不同的类别。如下图所示,世界上 88% 的语言属于资源组 0,几乎没有可用的文本数据,而 5% 的语言属于资源组 1,可用的文本数据非常有限。
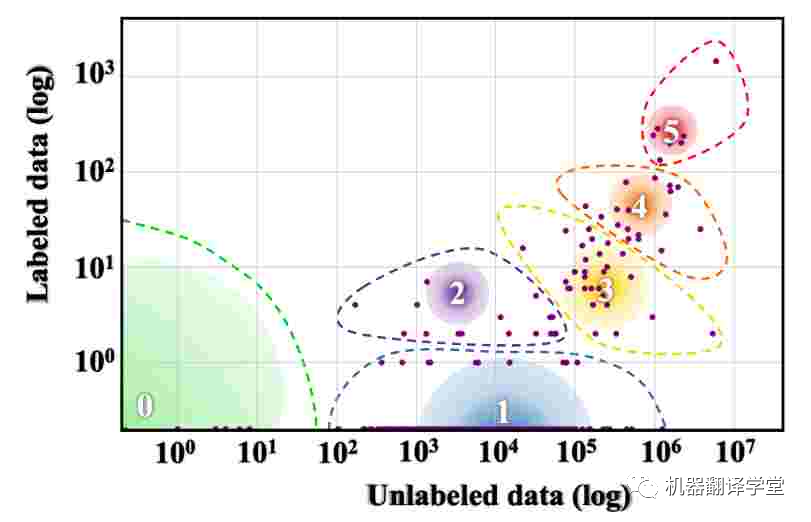
图6. 世界语言的资源分布。渐变圆圈的大小表示该类中的语言数。(Joshi 等人,2020 年)[57]。
机遇1:真实世界的数据
我们如何克服世界语言资源分布的巨大差异?创建新数据的成本很高,尤其是在标注很少的语言中。出于这个原因,许多现有的多语言数据集,如XNLI[58],XQuAD[59]和XCOPA[60]都是基于已创建的英语数据集的翻译。然而,这种基于翻译的数据是有问题的。一种语言的翻译文本可以被认为是该语言的一种“方言”,称为“translationese”,它不同于这种语言本身[61]。因此基于翻译的测试集可能会高估在类似数据上训练的模型的性能,而这些模型在真实场景中的表现可能不尽人意[62]。
西方概念的过度学习 :除了这些问题之外,翻译现有数据集会继承原始数据的偏差。特别是,翻译数据不同于不同语言用户自然创建的数据。由于现有的数据集大多是由西方国家的工作者或研究人员创建的,因此它们主要反映了以西方为中心的概念。例如,ImageNet[63]是ML中最具影响力的数据集之一,它基于英语WordNet。因此,它包含了一些过于针对英语、但是不存在于其他文化中的概念[64]。
实用数据 :因此,根据实际使用情况提供的信息来创建数据集是十分重要的。一方面,数据应反映讲该语言的人的背景比如文化背景、语言使用背景。一方面,它还减少了研究和实际场景之间的分布偏移,并使在学术数据集、或者在金融、法律等专业领域上开发的模型性能更好。
多模态数据 :世界上许多语言更常用而不是书面语言。我们可以通过关注来自多模态数据源(如无线电广播和在线视频)的信息以及组合来自多种模态的信息来克服对文本数据的依赖(和缺乏)。最近的语音和文本模型[65][66]在语音任务(如ASR,语音翻译和文本到语音)上有了很大的进步。但是它们在纯文本任务上的表现还是很差[67]。利用多模态数据以及研究不同语言的语言特征及其在文本和语音中的相互作用有很大的潜力[68]。
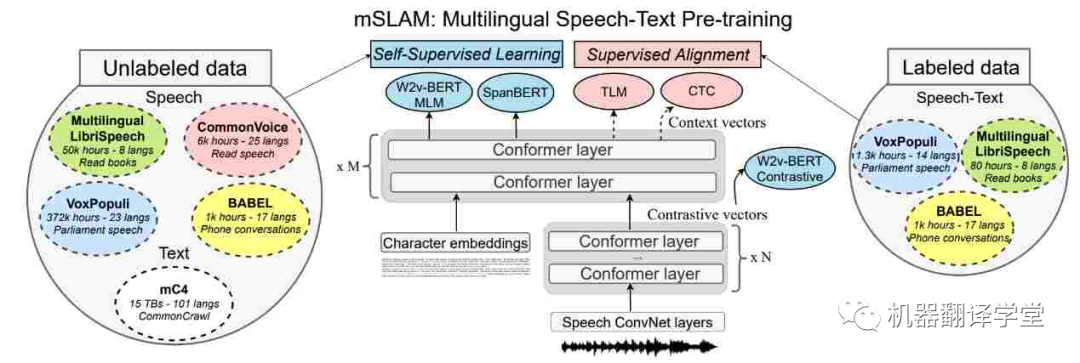
图7. mSLAM 中的多语言语音文本预训练模型,在未标记和标记的文本和语音数据集上联合预训练模型(Bapna 等人,2022 年)[67]。
最后,在为一些代表性不足的语言收集数据和开发模型时,人工智能面临的挑战包括数据管理、安全、隐私等等。为了应对这些挑战,需要回答以下问题:如何保证数据和技术的适当使用和所有权[69]?是否有适当的方法来检测和过滤有偏差的数据,并检测模型中的偏差?在数据收集和使用过程中如何保护隐私?如何使数据和技术开发参与[70]?
挑战2:有限的计算
代表性不足的语言的应用面临的限制不仅仅是数据的缺乏,还有计算资源的匮乏。例如,GPU服务器即使在许多国家的顶尖大学中也很稀缺[4],而在使用代表性不足的语言的国家,计算的成本更高[71]。
机遇2:高效性
为了更好地利用有限的计算,我们必须开发更有效的方法。有关高效Transformer架构和高效NLP方法的综述,请参阅[72]和[73]。由于预训练模型广泛可用,一个有前景的方向是通过参数高效方法优化这些模型,这已被证明比in-context learning更有效[74]。
一种常见的方法是是使用adapter[75][76],这是插入预训练模型权重之间的小模块。这些参数高效的方法可以通过分配额外模型容量给特定的语言来提升多语言的能力。它们还能够让多语言预训练模型在预训练期间没见过的语言上有更好的表现[77][78]。
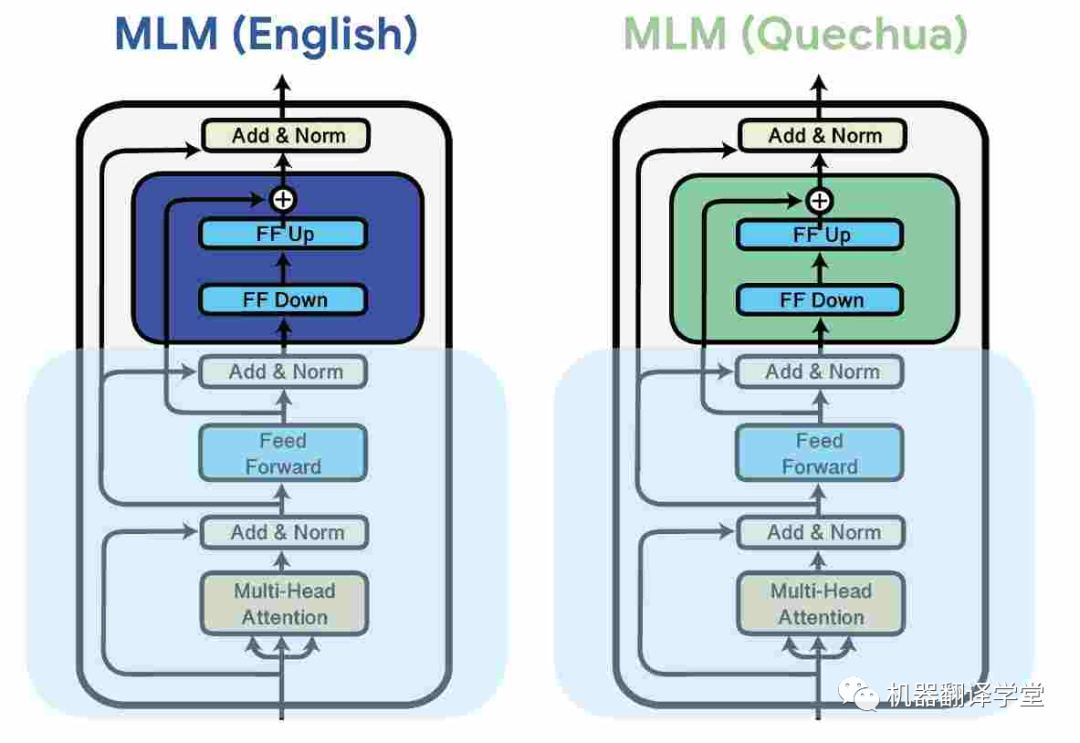
图8.通过对每种语言的数据进行掩码语言建模 (MLM) 学习针对特定于语言的adapter,同时冻结模型的其余参数(Pfeiffer 等人,2020 年)。[79]
与对模型进行微调[80]相比,adapter已被证明可以提高模型的鲁棒性[81][82],从而提高学习效率,并且优于其他参数高效方法[83][84]。
跨语言参数高效迁移学习不只有adapter,还可以采用其他形式[85],例如稀疏子网[86]。这些方法已被应用于各种领域,比如机器翻译[87][88]、ASR [89]和语音翻译[90]。
挑战3 语言类型特征
与现实世界的语言分布相比,现有数据集中的语言分布严重偏斜,并且具有可用数据的语言不能代表世界上大多数语言。代表性不足的语言具有许多西方语言中不存在的语言特征比如声调,它存在于大约80%的非洲语言中。在Yorùbá中,词汇音调区分了含义,例如,在以下单词中:igbá(“葫芦”,“篮子”),igba(“200”),ìgbà(“时间”),ìgbá(“花园鸡蛋”)和igbà(“绳子”)。在阿坎语气中,语法语气区分习惯动词和状态动词,例如Ama dá ha(“Ama睡在这里”)和Ama dàha(“Ama睡在这里”)。现有的NLP模型对于语言的音调研究还较少。
机遇3 特殊化处理
对于大多数代表性不足的语言,计算和数据是有限的。因此,将一定数量的先验知识纳入我们的语言模型以使它们对这些语言更有用是合理的。
比如说在tokenize的过程中,因为面对具有丰富的词汇形态或者有数据有限的语言,不够好的tokenize方法会导致分词结果较差。我们可以修改算法以首选多种语言共享的token[91],保留token的形态结构[92],或者使tokenize的算法面对错误的分割时更鲁棒[93]。
除此之外,许多代表性不足的语言属于类似语言的群体,即某一个语系。因此,专注于这些语系的模型可以更容易地共享跨语言的信息。模型可以从相关语言的迁移学习中得到有用的知识。
过去的基于掩码的一些算法对于多语言的学习有一定的效果,比如whole word masking[94]和PMI-masking[95],但考虑到语言的一些特征(如丰富的词形结构或语气),融入这些特征的预训练目标可能会使得模型能够更高效地学习。比如在基尼亚卢旺达语的KinyaBERT模型[47]中,它调整了模型的结构以融合有关语言形态的信息,使得模型在低资源但是词形丰富的吉尼亚卢旺达语上有了更优秀的翻译结果。
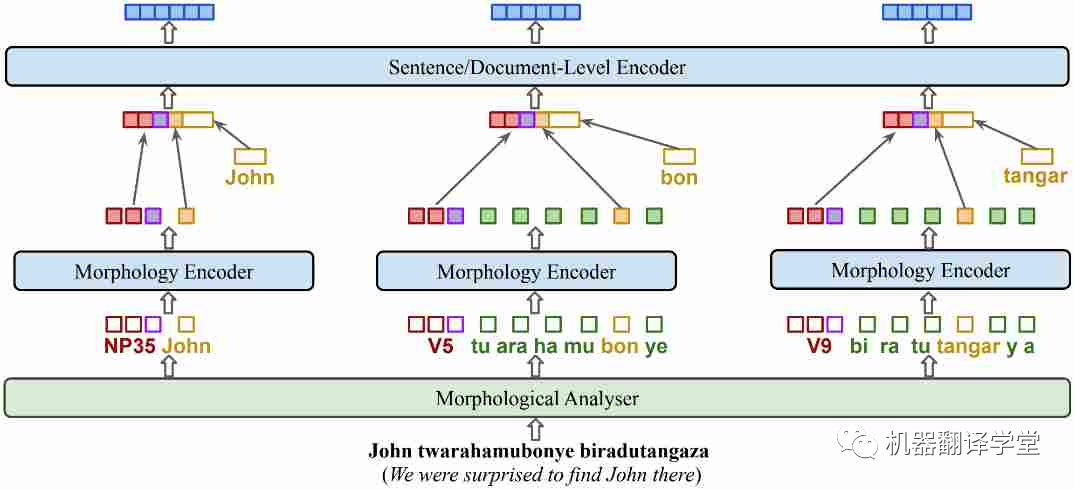
图9.KinyaBERT模型。添加了针对不同词形、单词内部结构的encoder,对 POS 标签、词干和词缀使用不同的嵌入
-05-
总结
虽然最近的多语言人工智能取得了巨大的进展,但仍有很多任务作要做。最重要的是,我们应该专注于创建反映语言用户真实世界情况的数据,并开发满足全球语言用户需求的语言技术。虽然人们越来越意识到这项工作很重要,但需要一个团体来为世界语言开发公平的语言技术。Masakhane(祖鲁语中的“让我们一起建设”)!
审核编辑 :李倩
-
多语言开发的流程详解2023-11-30 2159
-
这个多语言包 怎么搜不到2024-03-24 5942
-
串口屏能否支持全球多语言功能?2019-03-27 1910
-
HarmonyOS低代码开发-多语言支持及屏幕适配2023-05-23 3239
-
多语言综合信息服务系统研究与设计2009-04-01 509
-
华硕 M3A78-EH主板多语言版说明书2010-02-03 420
-
华硕 P5PL2 C主板多语言版说明书2010-02-04 450
-
SoC多语言协同验证平台技术研究2015-12-31 1072
-
Multilingual多语言预训练语言模型的套路2022-05-05 4338
-
蚂蚁集团开源高性能多语言序列化框架Fury解读2023-08-25 2505
-
基于LLaMA的多语言数学推理大模型2023-11-08 1184
-
如何在TSMaster面板和工具箱中实现多语言切换2023-11-11 2722
-
大语言模型(LLMs)如何处理多语言输入问题2024-03-07 1623
-
ChatGPT 的多语言支持特点2024-10-25 2610
-
京东多语言质量解决方案2026-01-13 1316
全部0条评论

快来发表一下你的评论吧 !
