

低延迟和低功耗图像预失真
描述
传统的平视显示器需要一个平坦的透明表面,图像投射到该表面上。如此平坦的表面只需要简单的梯形失真校正即可显示干净的图像。在较新的架构中,挡风玻璃本身将用作投影目标。
如果不进行校正,挡风玻璃上可能如下所示的干净投影图像:
对于挡风玻璃的三维表面,除了梯形失真或针垫校正之外,还需要更复杂的任意预变形。考虑到挡风玻璃的物理形状、投影仪的位置以及驾驶员可能的头部位置,这是必需的。
这种预失真需要对图像进行转换或扭曲,其中每个像素都被视为其所需位置。
Microchip与TES Electronic Solutions GmbH(TES)合作实施这种翘曲引擎。变形引擎基于以下简单概念:
对于每个输出像素,从查找表(LUT)读取所需源像素的亚像素精确位置,从源图像中读取该位置周围的所需源像素,并通过双线性滤波根据子像素位置对这些源像素进行加权来计算输出像素。
LUT由TES专有的自适应增量编码算法高度压缩,允许压缩系数从40到60倍,具体取决于子像素坐标的可配置最大误差值。

基于这种方法,可以实现任意形状的翘曲。翘曲引擎创建需要投影的三维图像的反曲率。
变形 IP 的通用设置如下:
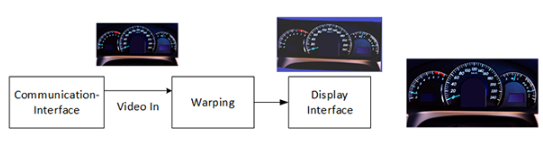
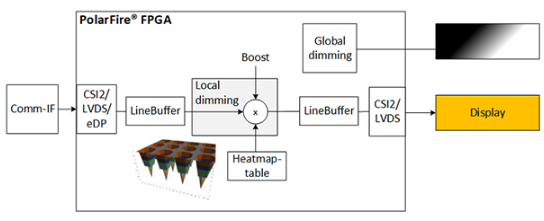
显示数据进入 PolarFire® FPGA,由翘曲引擎处理,然后传输到投影仪图像。局部调光可以作为翘曲过程的一部分进行;但是,这需要标准翘曲引擎的附加功能。
默认情况下,变形过程基于在 DDR 内存中临时存储传入的视频帧,并增加四个图像帧的延迟:
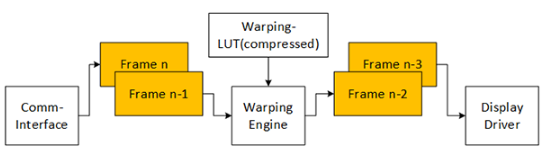
这种方法允许完全灵活地扭曲和旋转图像以及处理图像大小。
在外部 DDR 内存不可用或应避免的情况下,变形过程也可以适应在没有外部 DDR 内存的情况下工作,而只能在部分输入帧和流输出接口上工作:
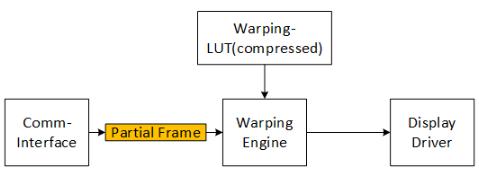
压缩的变形LUT存储在FPGA内部,输入的视频数据的几行缓冲在FPGA中。内部RAM要求取决于传入数据帧的宽度和需要存储的行数,后者取决于最大图像失真。
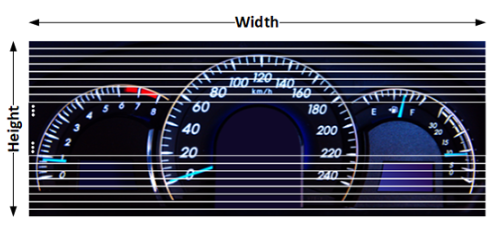
当内存中有足够的输入行时,可以开始处理输出像素。输出像素是根据存储的输入图像行中的可用数据创建的。

此方法在不使用外部 DDR 内存时优化最低延迟;但是,它降低了翘曲能力的灵活性。对于只需要少量翘曲的相对平坦的表面,可以通过减少内存需求来节省大量成本。一个积极的副作用是减少延迟。如果需要更大的图像失真,例如鱼眼镜头校正,该方法仍然适用,但节省的内存更少,延迟增加。
另一个好处是,移除DDR内存还可以消除内存引起的冻结帧的风险,这可能是系统中的安全问题。
局部调光是投影应用中经常需要的功能。局部调光抵消了由用于背光的LED矩阵的照明热图引起的图像梯度:
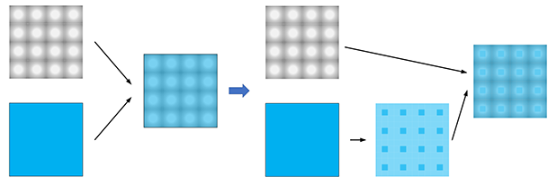
图像的像素在颜色和亮度上单独调整,以便背光矩阵的照明热图产生具有预期颜色和亮度的图像。
由于输出图像的每个像素都被扭曲引擎触摸,因此可以同时应用局部调光,而不会增加任何额外的延迟。局部调光到单个像素的粒度取决于可用于存储调光表的内存。
在只需要局部调光而不翘曲的情况下,也可以独立模式下使用按像素方法。对于此设置,只需要包含调光区域信息的热图表的内存。调光在流模式下实现,不存储完整的图像帧。在这种方法中,调光的延迟仅保持在两条图像线,并消除了外部存储器中图像冻结的风险。
基于FPGA的灵活性,可以支持不同的通信接口。这允许在客户可能拥有的多个平台上重复使用设计。在设计中使用FPGA时,中等复杂的FPGA足以运行翘曲引擎,因此可以使用非常节省空间的小型封装在PCB上进行简单且经济高效的布线。此外,在具有挑战性的热环境中使用FPGA可以毫不费力,因为Microchip的PolarFire FPGA是业界中档密度下功耗最低的器件。
审核编辑:郭婷
-
高性能低功耗的AD6641:数字预失真观测接收器的优选之选2026-03-31 373
-
ADAU1372低延迟低功耗编解码器:音频设计的理想之选2026-03-23 230
-
超低功耗、低失真全差分ADC驱动器ADA4940-1/ADA4940-2:高性能与低功耗的完美结合2026-01-12 671
-
ADA4940-1超低功耗、低失真ADC驱动器技术手册2025-03-14 2517
-
OPA1692低功耗、低噪声和低失真音频运算放大器数据表2024-06-14 646
-
LM6171高速、低功耗、低失真电压反馈放大器数据表2024-06-05 520
-
ADA4940-2超低功耗低失真ADC驱动器解读2023-01-13 1028
-
ADAU1372:四路ADC、双DAC、低延迟、低功耗编解码器2021-05-26 1232
-
DN148-低功耗、快速运算放大器具有低失真2021-05-25 937
-
数字预失真解决方案2021-04-22 871
-
具有低失真的低功耗快速运算放大器2019-08-23 1493
-
IDT推出业界最低功耗低失真多样化混频器2012-07-03 2761
-
可修正RF信号的RF预失真2011-08-02 4794
-
SFN5122F低功耗低延迟10G以太网卡2010-05-05 1912
全部0条评论

快来发表一下你的评论吧 !
