

深度分析高通基于DSP的的AI加速硬件设计
处理器/DSP
描述
高通SoC的AI加速硬件都是基于DSP的,指令方面则是SIMD扩展。高通自2013年导入DSP加速,一直沿用至今,硬件架构变化不大,可以说是非常优秀的设计。从高通8150开始,一般高通SoC包含4个DSP,分别对应音频、传感器、Modem和计算,通常高通只把计算DSP即cDSP单独提及,一般说HEXAGON DSP指的就是cDSP。
DSP是通用的加速器,可以对应标量(Scalar)、向量(Vector)和张量(Tensor)。而我们所说的AI芯片一般只对应张量。标量运算一般对应的是CPU,通常是串行数据。向量和张量对应的并行数据计算,传统的CPU不太胜任。并行运算分指令并行、数据并行(SIMD)和线程并行(SIMT,即GPU)三大类。

图片来源:高通
高通在第六代Hexagon DSP中引入HVX概念,HVX是Hexagon Vector eXtensions的简称,HVX是DSP中一个可选的协处理器,它为标量DSP单元添加了128字节的矢量处理功能(在HVX编程的时候很多处理都要128对齐)。标量硬件线程通过访问HVX寄存器文件(也称为HVX上下文)来使用HVX协处理器。之后高通又引入HTA(Hexagon Tensor Accelerator),基本上只对应定点即整数运算,主要针对CNN模型。之后高通继续改进HTA,改进为HTP (Hexagon Tensor Processor),所谓HTP就是加入了HMX即Hexagon Matrix eXtensions。仍然是基于标量DSP而加入的协处理器。
通常DSP都是哈佛架构,采用流水线操作,对数据的整齐度要求很高,不能有分支跳转或中断,DSP采用了哈佛结构,将存储器空间划分成两个,分别存储程序和数据。它们有两组总线连接到处理器核,允许同时对它们进行访问,每个存储器独立编址,独立访问。这种安排将处理器的数据吞吐率加倍,更重要的是同时为处理器核提供数据与指令。在这种布局下,DSP得以实现单周期的MAC乘积累加指令,而MAC就是AI运算的最底层。
DSP芯片广泛采用2-6级流水线以减少指令执行时间,从而增强了处理器的处理能力。这可使指令执行能完全重叠,每个指令周期内,不同的指令都处于激活状态。更像是脉动处理器,数据一次导入,流转周期很长,效率极高。
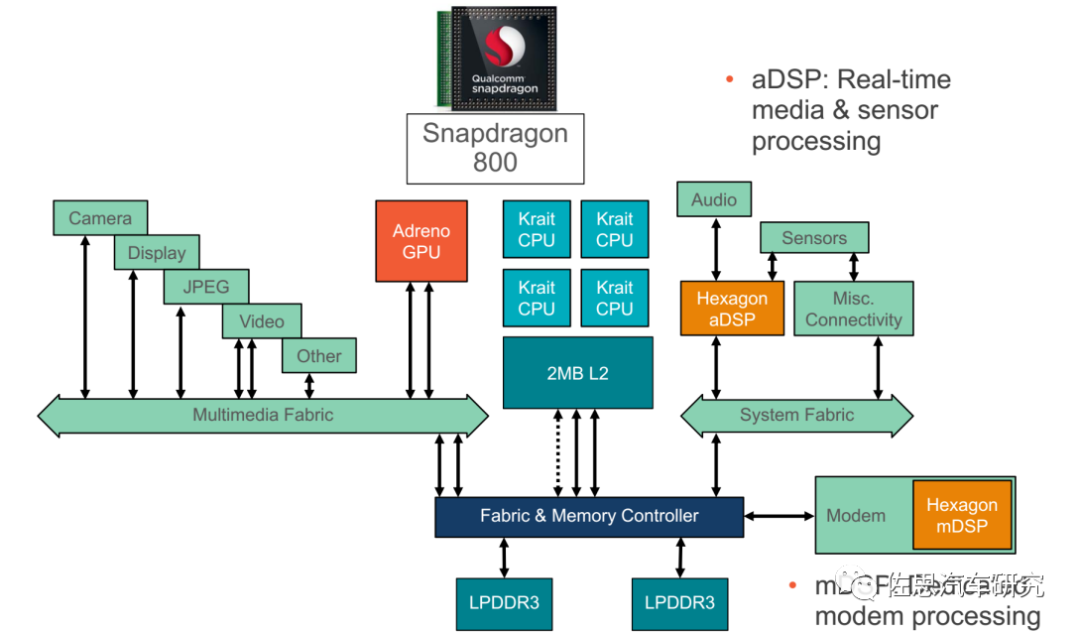
图片来源:高通
高通利用DSP加速早在2006年就开始了,不过早期都是针对modem或音频的,2013年以后增加了计算。
图片来源:高通
高端DSP都采用VLIW(超长指令集),VLIW DSP在硬件上没有调度和冲突判决的机制,其性能的发挥完全依靠编译器的优化效果。VLIW架构中,指令级并行的发现与指令执行顺序的调度(硬件中最困难的部分)完全交由编译器完成。这样,硬件可以尽可能地保持简单。VLIW硬件不负责发现并发执行多个操作的工作。VLIW实现很长的指令,超长指令字已经对并发操作进行了编码,这通常是由编译器来完成的。与RISC或CISC的高度超标量实现相比,这种显式编码极大降低了硬件的复杂性。硬件简单化的好处就是只需要简单地增加计算单元就可提高算力,难题都交给了软件,这也是高通DSP生命力如此顽强的原因。
高通DSP的VLIW
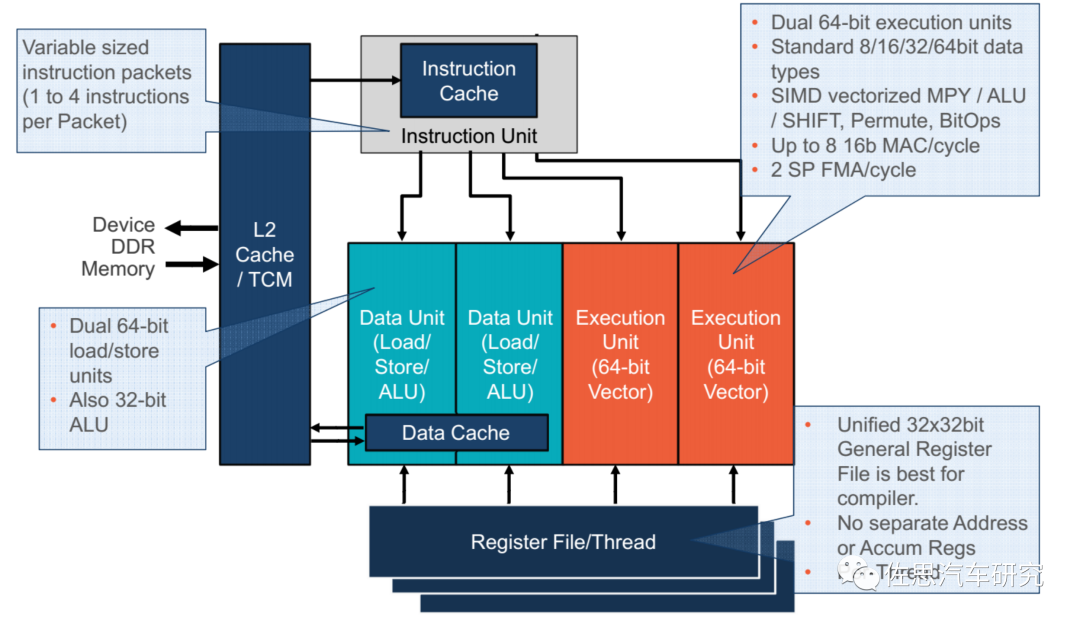
图片来源:高通
第一代带HVX的高通DSP硬件架构
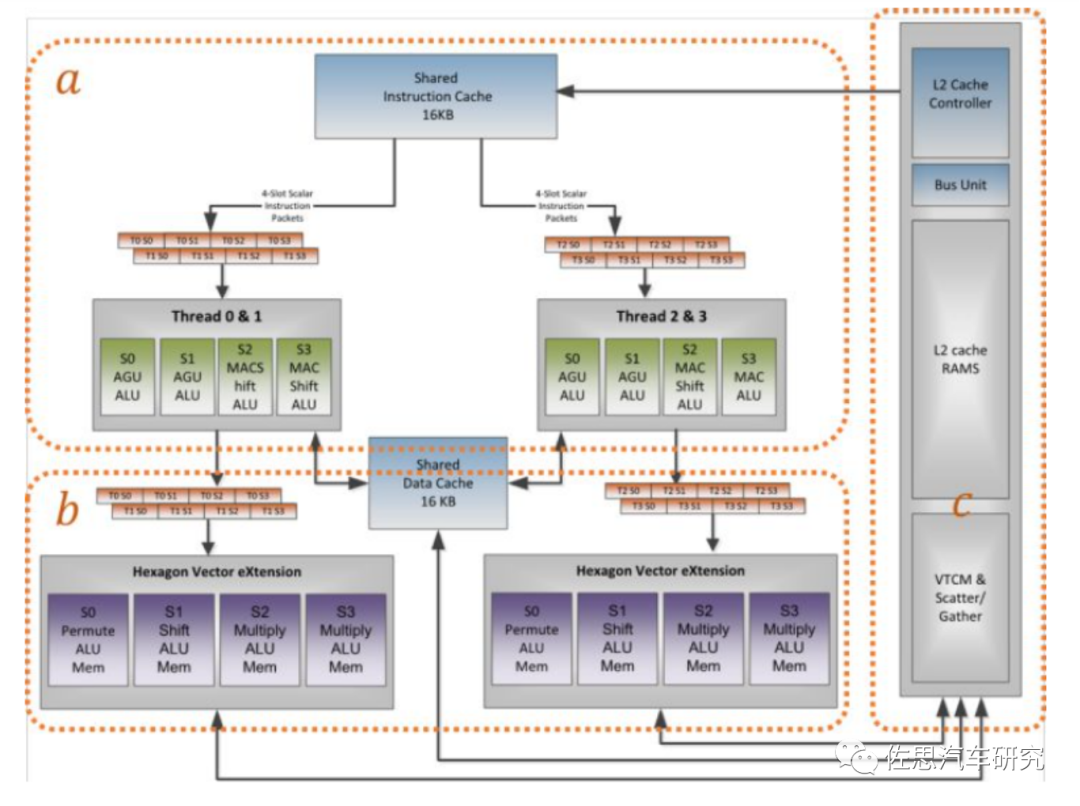
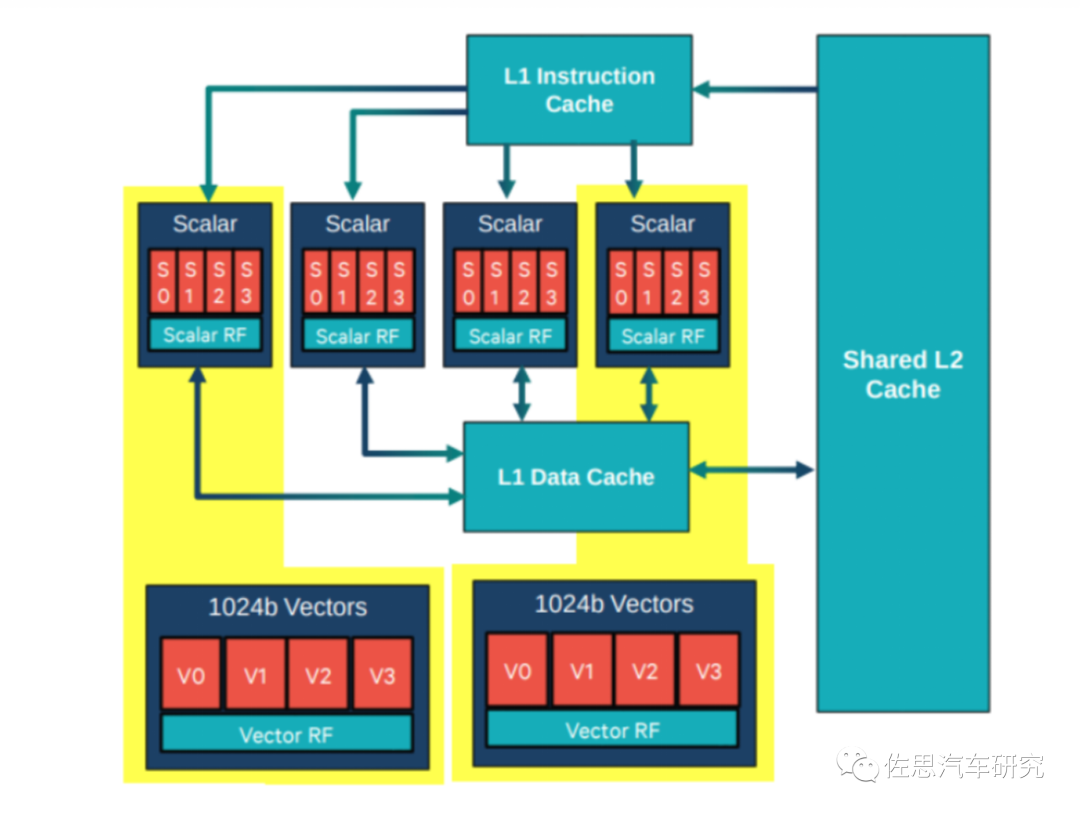
图片来源:高通
主处理器主要负责标量运算,有4个(目前新架构已调整至6个)硬件线程(每个拥有4路VLIW,共享L1/L2)。向量化运算由2个HVX context组成(目前新架构已调整至4个),分别会被多个标量线程控制。主处理器和HVX都是可以有多个软件线程,由QURT实时操作系统进行硬件线程选择及调度,开发者不可控。
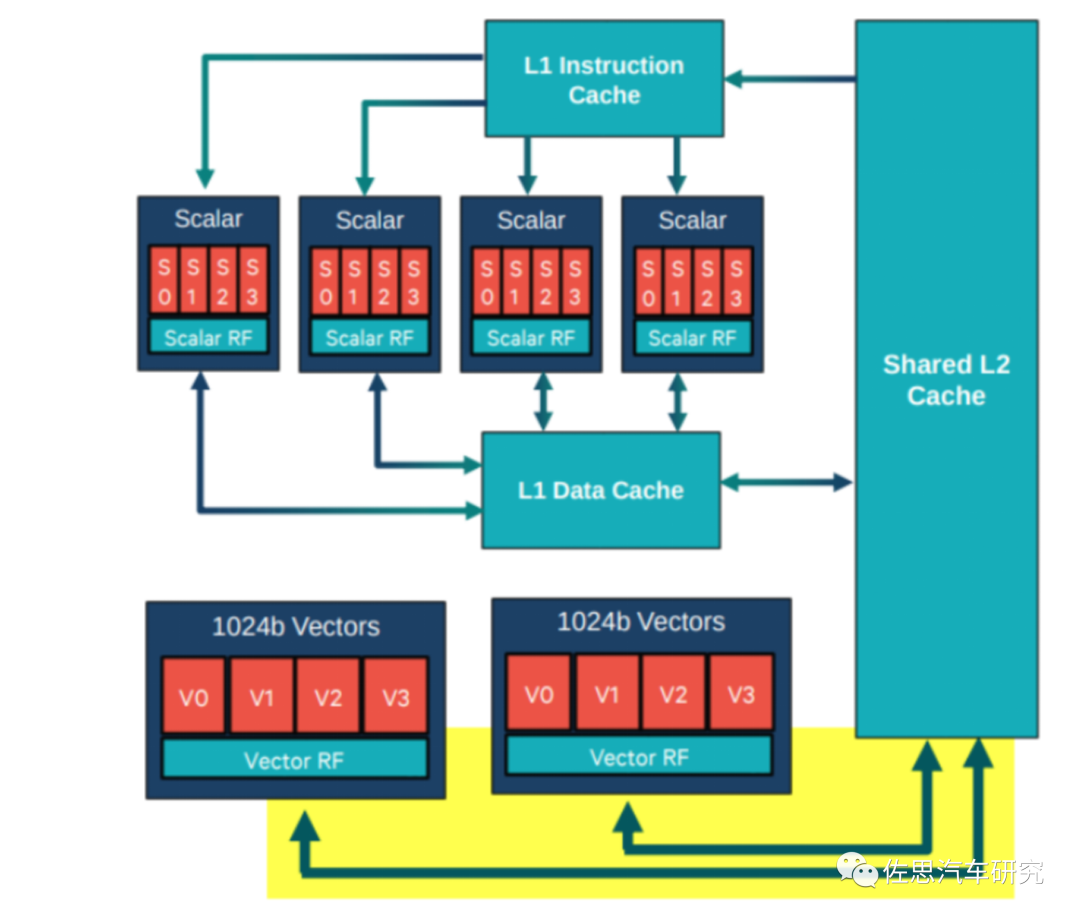
图片来源:高通
高通带HVX的DSP的内存体系,L1只能由标量单元访问(Scalar是标量单元),L2是标量单元的第二级内存,也是HVX协处理器的第一级内存。向量单元支持各种加载/存储指令,包括对未对齐向量和每字节条件存储的支持。
HVX离不开SIMD扩展指令集,英特尔于1996年率先将多媒体SIMD扩展指令集引入通用处理器,在其奔腾处理器上集成了SIMD扩展部件MMX。
多媒体应用中通常存在大量同质、独立的访存和计算操作,且使用的数据类型一般都很窄(如图形系统使用8位表示三基色的每一种颜色,使用8位表示透明度;音频采样位宽通常为8位或16位)。SIMD扩展指令集具有独立的长位宽向量寄存器(64/128/256/512/1024......),允许将原来需要多次装载的连续内存地址数据一次性装载到向量寄存器中,并使用分裂模式将长的向量寄存器当作多个独立的窄位宽元素,通过一条SIMD扩展指令实现对SIMD向量寄存器中所有数据元素的并行处理。这种执行方式非常适合于处理计算密集、数据相关性少的音视频解码等多媒体程序。即把64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升了8倍。SIMD指令的初衷就是这样的。
SIMD扩展部件仅需要在原来标量部件的基础上复制几份同样的处理单元,不需要增加太多的额外硬件,就能对多媒体等特定应用带来显著的性能提升,且不增加通信以及Cache和内存的开销,因此即使在多核时代,SIMD扩展部件仍然是程序加速的重要手段之一。
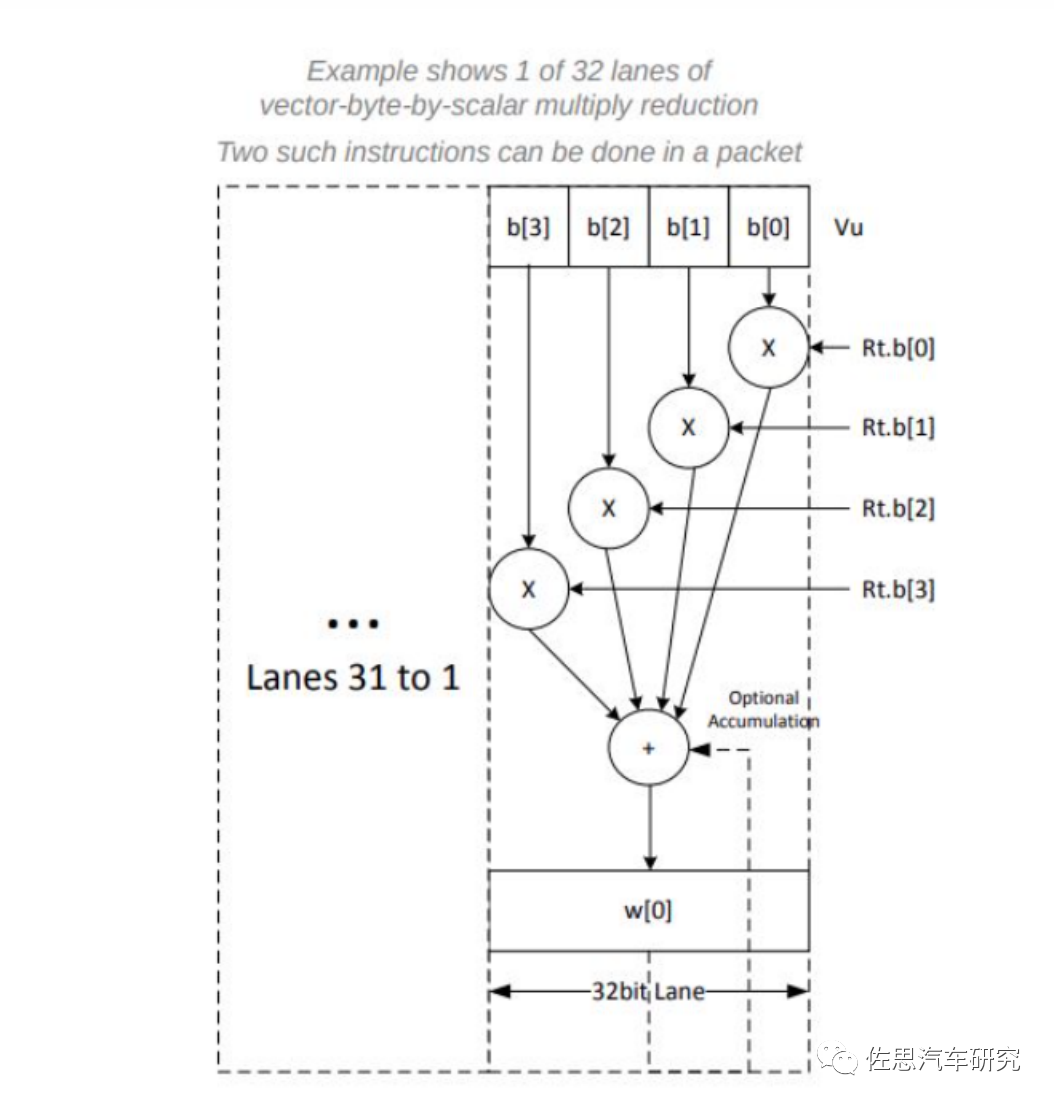
图片来源:高通
高通DSP是一个4slot的VLIW的1024比特宽度的处理器,每个周期可处理4096比特的数据,简单来说,如果数据格式是8比特的,那么可以一次执行512次计算,相当于一个512核心的GPU。缺点是无论要处理多少数据,DSP都是火力全开,这可能导致功耗较高,因此DSP的工作频率一般不高于1GHz,而CPU可以轻易超过2GHz。
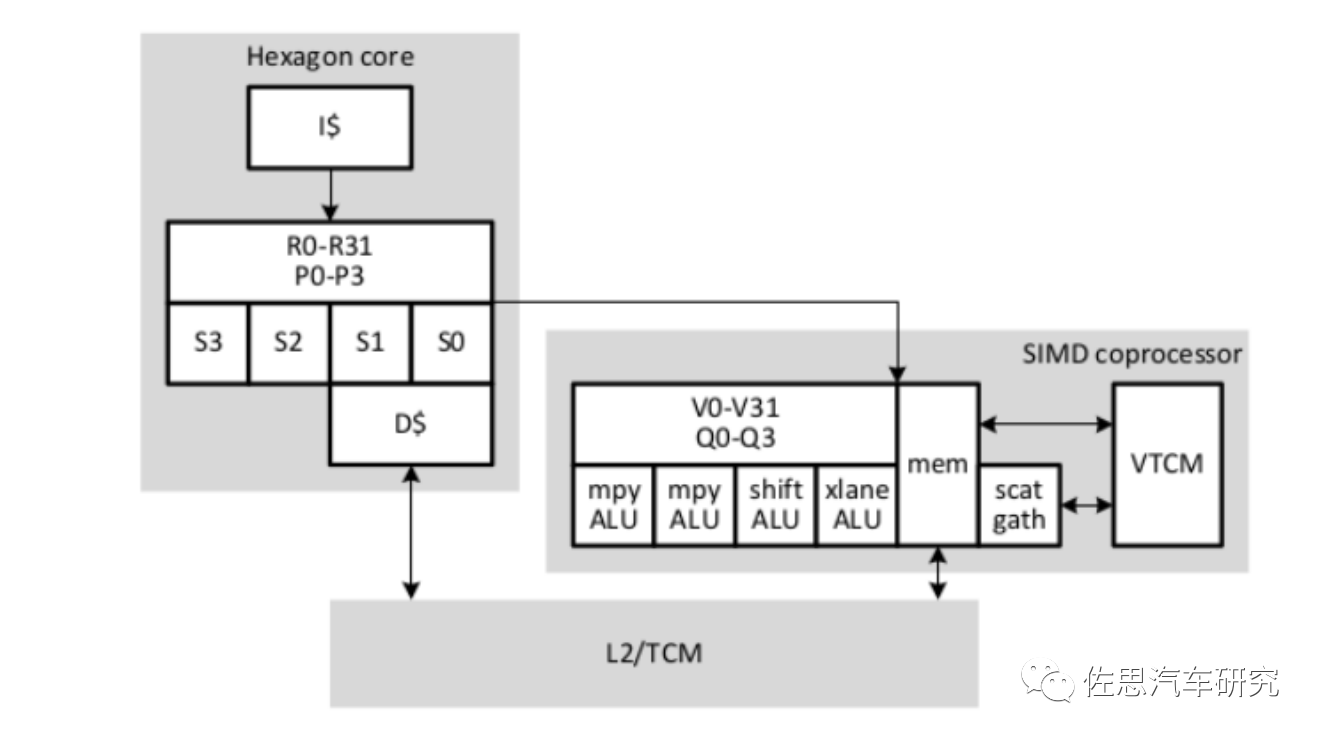
图片来源:高通
拥有32个1024b寄存器R0-R31,4个判断寄存器P0-P3,支持8/16/32/64-bits的定点运算。VLIW可以提供特殊指令比如CNN的滑窗滤波,直方图生成等。
最新的HMX,高通没有公开过其详细信息,不过也无需公开。所谓AI运算就是矩阵的乘积累加,SIMD指令集中很早就有对应乘积累加的指令,最早设计这个指令是对应FFT(快速傅里叶变换)和DCT(离散余弦变换)的,它们的计算过程与今天的AI运算高度重合,几乎完全一致,早在1999年英特尔就推出了SSE,可以实现一条指令完成乘积累加,效率比传统计算单元提高一倍。SSE后来演变为AVX。AVX,全称为:Advanced Vector Extensions(又名,Sandy Bridge New Extensions),是Intel和AMD微服务器x86指令集的extension扩展。AVX2扩充到了支持256bit的整数运算指令,引入了Fused-Multiply-Add(FMA)运算。所谓FMA,即可通过单一指令实现A=A∗B+C A=A*B+C A=A∗B+C计算,也就是AI运算。英特尔是考虑到了AI训练,因此最高支持到256比特精度,手机上肯定只做推理,8比特就够,最早高通的HTA就只支持8比特定点运算,后来HTP支持混合精度,也支持定点或浮点的8位或16比特运算。高通只需要像HVX那样增加一个或几个SIMD协处理器就行,困难都交给编译器。此外DSP的哈佛架构让数据和指令有不同的总线,AI运算的效率进一步提升,再配合SIMD,效率不逊于ASIC。不过成本还是略高于ASIC。
因为SIMD和DSP的特殊性,高通特别做了SNPE(Snapdragon Neural Processing Engine),是高通公司推出的面向移动端和物联网设备的深度学习推理框架。SNPE提供了一套完整的深度学习推理框架,必须将Caffe,Caffe2,ONNXTM和TensorFlowTM模型转换为SNPE深度学习容器(DLC)文件才能运行,有时可能无法转换为高通DLC,如ONNX模型使用了SNPE不支持的hardsigmoid激活功能。由于ARM和英特尔的深度学习加速也是基于SIMD的,因此SNPE也适用于ARM和英特尔平台,也可以基于Linux平台调整网络。早期的SNPE DLC只支持8位定点精度,近期可能有提升,支持混合精度。因为SNPE的存在,高通芯片的AI算力不单单是HTA或HTP的,还包括了CPU、GPU和DSP,以骁龙888为例,AI算力是包含这4部分的,合计为26TOPS@INT8,这当中HTP可能只贡献了一半,甚至更低。
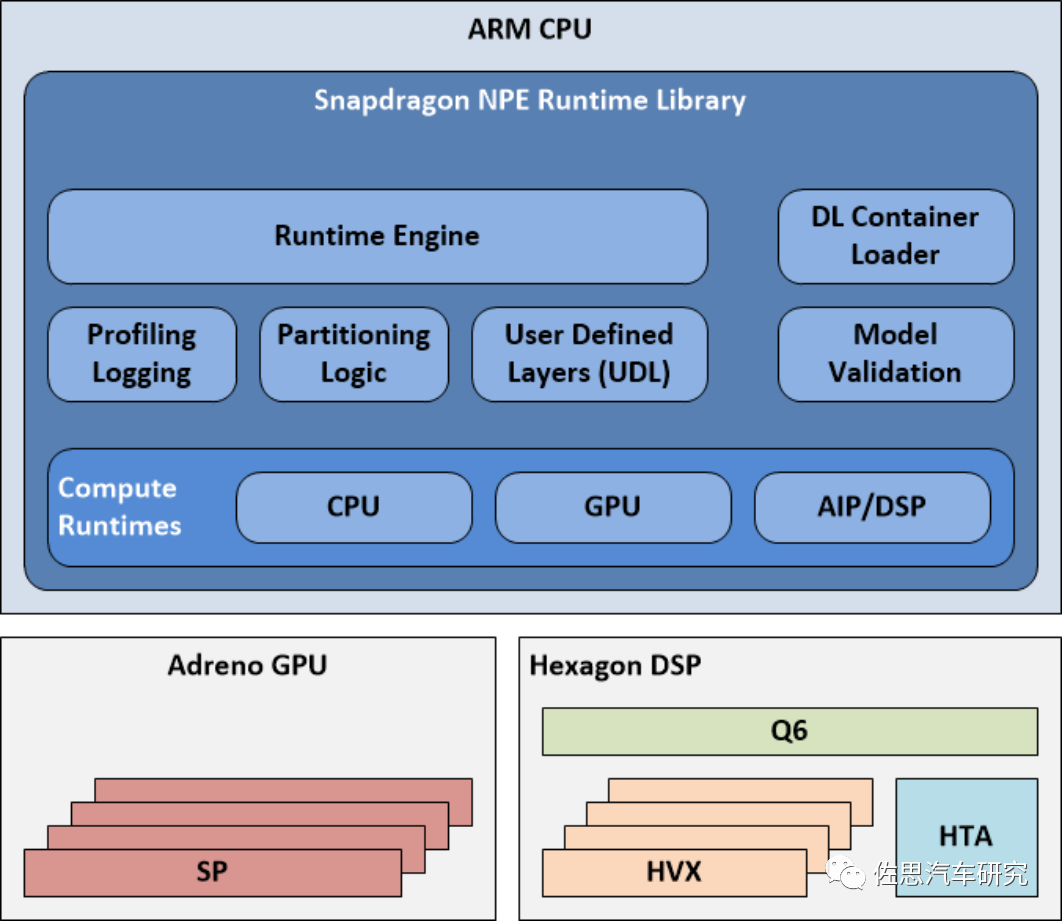
图片来源:高通
SNPE会对所有运算资源进行调度,根据数据类型选择不同的运算资源,比如ARM CPU可以执行32比特浮点或8比特定点运算,GPU可以执行全16比特浮点运算,DSP支持8比特定点,HTA或HTP执行8比特或16比特定点运算。如果在某个运算资源上执行效率不高,SNPE可以退出换其他运算资源执行运算。这里可能有一个缺点,有些运算资源为了对应退出机制,可能需要保持待机状态。而SNPE的调度很难适应高通外的硬件,也就是说如果某个高通芯片的算力不足,必须要增加一个完全一致的高通芯片来弥补,比如高通座舱8155,之所以出现双8155的座舱,推测可能就是这个原因。典型的如亿咖通为路特斯高端车型打造的座舱,用了两片8155,第二片8155只用了GPU资源。
从骁龙8 gen 1开始,高通不再公布具体的TOPS数据,因为SIMD这种方式,占的die面积比ASIC还是要大,毕竟它是靠寄存器硬件来实现的。在没有制造工艺明显提升情况下,高通对DSP硬件改进会很小,高通精力似乎主要在ISP上,改进ISP,减少DSP的负荷。此外,高通还降低精度,最新的8 gen 2支持4比特精度,未来支持单比特也有可能,这样数字上比较好看。
高通第一代座舱与智能驾驶二合一的SA8795P,AI算力高达60TOPS,成本可能比较高,座舱主流SA8155P的更新换代产品SA8255P其AI算力可能与SA8155P差不多,提升主要在CPU领域。
编辑:黄飞
-
当我问DeepSeek AI爆发时代的FPGA是否重要?答案是......2025-02-19 6558
-
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构2025-09-12 2490
-
使用NORDIC AI的好处2026-01-31 1784
-
MCU厂推多样解决方案 DSP/FPU硬件加速芯片整合2016-10-14 2278
-
新型DSP设计架构助力加速5G和AI开发2019-06-18 2126
-
深度学习推理和计算-通用AI核心2020-11-01 3640
-
【米尔FZ3深度学习计算卡试用体验】搭建Vitis Ai系统平台并测试2020-12-03 4268
-
ai加速芯片2021-07-28 1463
-
嵌入式边缘AI应用开发指南2022-11-03 1486
-
【书籍评测活动NO.18】 AI加速器架构设计与实现2023-07-28 42467
-
《 AI加速器架构设计与实现》+第2章的阅读概括2023-09-17 4041
-
DSP分析工具箱的加速DSP仿真系统的详细资料概述2018-05-07 1081
-
如何选合适的AI硬件加速方案2018-10-29 5141
-
Atlas 200 AI加速模块硬件开发指南.pdf2021-12-22 1292
-
移远通信×扣子:AI与硬件深度融合,加速AI智能体高效开发新生态2025-03-22 1360
全部0条评论

快来发表一下你的评论吧 !
