

构造机器学习算法规律介绍
人工智能
描述
构造机器学习算法之前:观察数据,总结规律
随着大数据和深度学习的发展,互联网中已具有开源机器学习算法模型。如果通过收集大量数据,并将数据输入至某种机器学习的开源算法中训练,则大概率无法得到较好的结果。开发人员如果没有对数据感性的认识,难以设计出性能较好的算法,同时,开发人员也难以估计算法的性能极限。
因此,开发人员在构造机器学习算法之前需观察数据,总结规律。
第一步、特征提取(Feature Extraction)
特征提取是指通过样本获得对机器学习任务有帮助的多维度特征数据。特征提取对于机器学习系统的构件是重要的,实践表明,如果开发人员提取了特征较好,那么即使采用较差的机器学习算法,也可获得较好的性能,但如果开发人员提取的特征较差,无法反应样本的内在规律,那么即使采用较好的机器学习算法,也无法获得较好的性能。 不同任务提取特征的方式不同。图像、语音、三维点云(根据百度百科:三维点云是按照规则格网排列的三维坐标点的数据集)等媒质的物理属性各不相同,各种媒质对应机器学习的任务也不同,因此,机器学习算法的特征提取的方式较多,开发人员欲想将各种机器算法特征提取最优方式完全掌握需要较长时间。
第二步、特征选择(Feature Selection)
特征选择需要选择区分度高的特征。如图一所示,图一中上方两张图的红线与蓝线重合较少,可被视为区分度高的特征,图一下方两张图的红线与蓝线重合较高,相比于图一上方两张图的区分度较低。因此,经过特征选择步骤,图一中上方两张图将被选择。
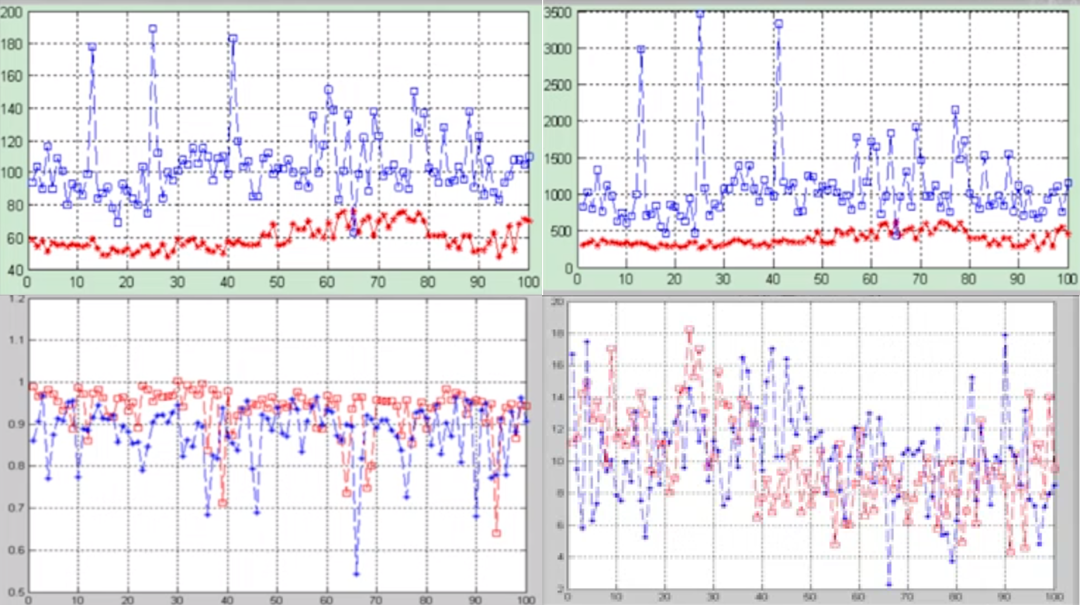
图一,图片来源:根据中国慕课大学《机器学习概论》资料制作
第三步,选择机器学习算法
开发人员选择适合其选择特征的算法。机器学习算法包括:支持向量机(Support Vector Machine)、人工神经网络 (Neural Networks)、深度神经网络(Deep Neural Networks),每种机器学习算法中包含多种内核(可将多种内核理解为多个机器学习算法)。
第四步,得到特征空间(Feature Space),完成机器学习
如图二所示,图二中的三张二维平面图均为特征空间图形,三张特征空间图形内的直线或曲线(红色椭圆框内)是计算机完成不同机器学习后得出的不同分类依据,计算机可依照其所得到的分类依据对新数据进行分类。
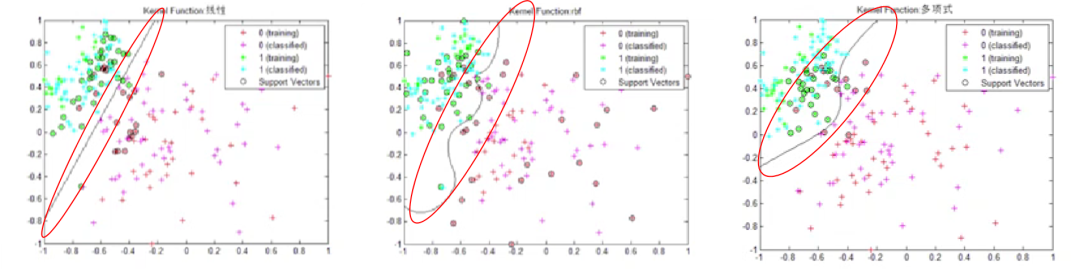
图二,图片来源:根据中国慕课大学《机器学习概论》资料制作 在更复杂的机器学习中,特征空间的维度处于几百至几万数量级的维度,深度学习的特征空间维度可处于几十万量级的维度,机器学习适合在高维度特征空间中的预测。
同时,不同机器学习所得出的分类标准不同(即三张特征空间图形内的直线或曲线的形状不同)。因此,针对某一数据,不同机器学习算法将得出不同的预测结果。但因为开发人员难以穷尽所有数据,所以无法简单确定哪种机器学习算法更优。
编辑:黄飞
-
机器学习和深度学习的区别2023-08-17 5853
-
机器学习算法的基础介绍2022-10-24 2910
-
机器学习算法分享2020-06-09 2419
-
十大机器学习算法中的线性判别分析的详细介绍2020-02-03 8234
-
机器学习算法概念介绍及选用建议2019-01-14 4553
-
机器学习算法分类2018-01-05 3848
-
Spark机器学习库的各种机器学习算法2017-09-28 1360
-
机器学习的算法应用2017-08-24 3271
-
基于领域搜索的构造性学习算法_李萍2017-03-16 1375
全部0条评论

快来发表一下你的评论吧 !
