

AI作画升级,OpenVINO™ 和英特尔独立显卡助你快速生成视频
描述
在《AI作画,OpenVINO助你在英特尔GPU上随心创作》中,我们介绍了OpenVINO Notebook运行环境搭建,并利用OpenVINO优化和加速Stable Diffusion模型的推理,在英特尔独立显卡上能够根据我们输入的指令(prompt),快速生成我们喜爱的AI画作。
今天,我们对这一应用场景再次升级,除了能够作画,利用OpenVINO对Stable Diffusion v2模型的支持及优化,我们还能够在在英特尔独立显卡上快速生成带有无限缩放效果的视频,使得AI作画的效果更具动感,其效果也更加震撼。话不多说,接下来还是让我们来划划重点,看看具体是怎么实现的吧。
英特尔锐炫 显卡基于Xe-HPG 微架构,Xe HPG GPU 中的每个 Xe 内核都配置了一组 256 位矢量引擎,旨在加速传统图形和计算工作负载,以及新的 1024 位矩阵引擎或 Xe 矩阵扩展,旨在加速人工智能工作负载。
本次无限缩放Stable Diffusion v2视频生成的全部代码请戳这里https://github.com/openvinotoolkit/openvino_notebooks/blob/main/notebooks/236-stable-diffusion-v2/236-stable-diffusion-v2-infinite-zoom.ipynb 。OpenVINO Notebooks运行环境的安装请您参考我们的上一篇《AI作画竟如此简单!蝰蛇峡谷OpenVINO开发者实战》。
此次我们应用的深度学习模型是Stable Diffusion v2模型,相比它的上一代v1模型,它具有一系列新特性,包括配备了一个新的鲁棒编码器OpenCLIP,由LAION创建,并得到了Stability AI的帮助,与V1版本相比,此版本显著增强了生成的照片。另外,v2模型在之前的模型基础上增加了一个更新的修复模块(inpainting)。这种文本引导的修复使切换图像中的部分比以前更容易。也正是基于这一新特性,我们可以利用stabilityai/stable-diffusion-2-inpainting模型,生成带有无限缩放效果的视频。
在图像编辑中,Inpainting是一个恢复图片缺失部分的过程。最常用于重建旧的退化图像,从照片中去除裂纹、划痕、灰尘斑点或红眼。但凭借AI和Stable Diffusion模型的力量,Inpainting可以实现更多的功能。例如,它可以用来在现有图片的任何部分渲染全新的东西,而不仅仅是恢复图像中缺失的部分。只要发挥你的想象力,你可以做出更多炫酷效果的作品来。
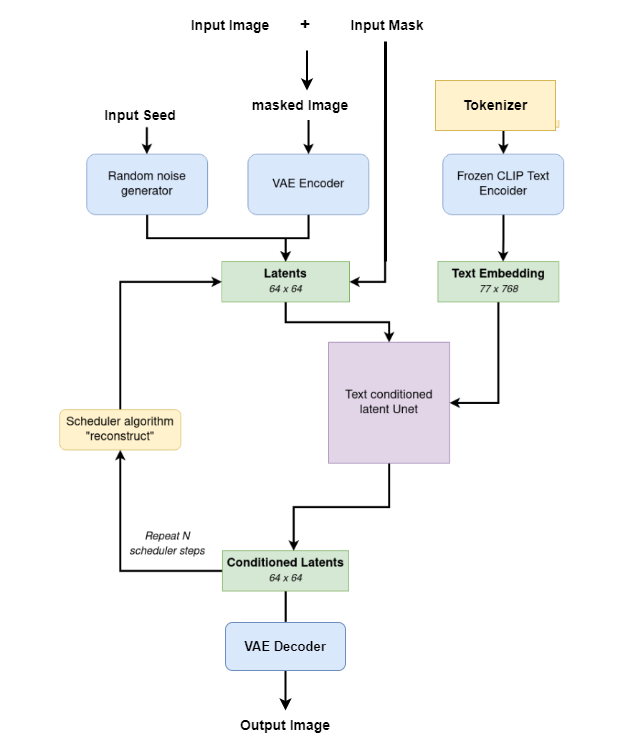
下面的工作流程图解释了用于Inpainting的Stable Diffusion inpainting流水线是如何工作的:
在此次的代码示例中,我们将完成以下几个步骤:
将PyTorch 模型转换为ONNX格式。
利用Model Optimizer 工具,将ONNX 模型转换为OpenVINO IR 格式。
运行Stable Diffusion v2 inpainting 流水线,生成无限缩放效果视频。
现在,让我们来重点来看看如何配置推理流水线的代码。
这里主要分以下三个步骤:
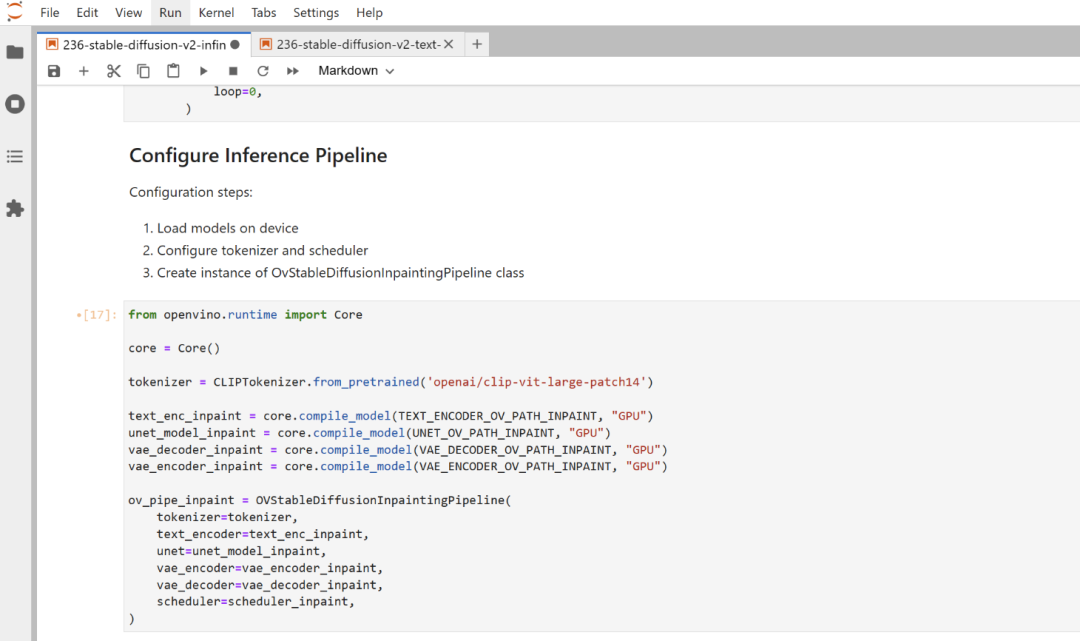
在推理的硬件设备上加载模型Load models on device
配置分词器和调度器Configure tokenizer and scheduler
创建OvStableDiffusionInpaintingPipeline 类的示例
我们在配备英特尔锐炫独立显卡A770m的蝰蛇峡谷上加载模型并运行推理,因此推理设备我们选择“GPU”。默认情况下,它使用“ AUTO”,并会自动切换至检测到的 GPU。代码如下:
1. from openvino.runtime import Core
2.
3. core = Core()
4.
5. tokenizer = CLIPTokenizer.from_pretrained('openai/clip-vit-large-patch14')
6.
7. text_enc_inpaint = core.compile_model(TEXT_ENCODER_OV_PATH_INPAINT, "GPU")
8. unet_model_inpaint = core.compile_model(UNET_OV_PATH_INPAINT, " GPU ")
9. vae_decoder_inpaint = core.compile_model(VAE_DECODER_OV_PATH_INPAINT, "GPU")
10. vae_encoder_inpaint = core.compile_model(VAE_ENCODER_OV_PATH_INPAINT, "GPU")
11.
12. ov_pipe_inpaint = OVStableDiffusionInpaintingPipeline(
13. tokenizer=tokenizer,
14. text_encoder=text_enc_inpaint,
15. unet=unet_model_inpaint,
16. vae_encoder=vae_encoder_inpaint,
17. vae_decoder=vae_decoder_inpaint,
18. scheduler=scheduler_inpaint,
19. )
接下来,我们输入文本提示,运行视频生成的代码吧。
1. import ipywidgets as widgets
2.
3. zoom_prompt = widgets.Textarea(value="valley in the Alps at sunset, epic vista, beautiful landscape, 4k, 8k", description='positive prompt', layout=widgets.Layout(width="auto"))
4. zoom_negative_prompt = widgets.Textarea(value="lurry, bad art, blurred, text, watermark", description='negative prompt', layout=widgets.Layout(width="auto"))
5. zoom_num_steps = widgets.IntSlider(min=1, max=50, value=20, description='steps:')
6. zoom_num_frames = widgets.IntSlider(min=1, max=50, value=3, description='frames:')
7. mask_width = widgets.IntSlider(min=32, max=256, value=128, description='edge size:')
8. zoom_seed = widgets.IntSlider(min=0, max=10000000, description='seed: ', value=9999)
9. zoom_in = widgets.Checkbox(
10. value=False,
11. description='zoom in',
12. disabled=False
13. )
14.
15. widgets.VBox([zoom_prompt, zoom_negative_prompt, zoom_seed, zoom_num_steps, zoom_num_frames, mask_width, zoom_in])
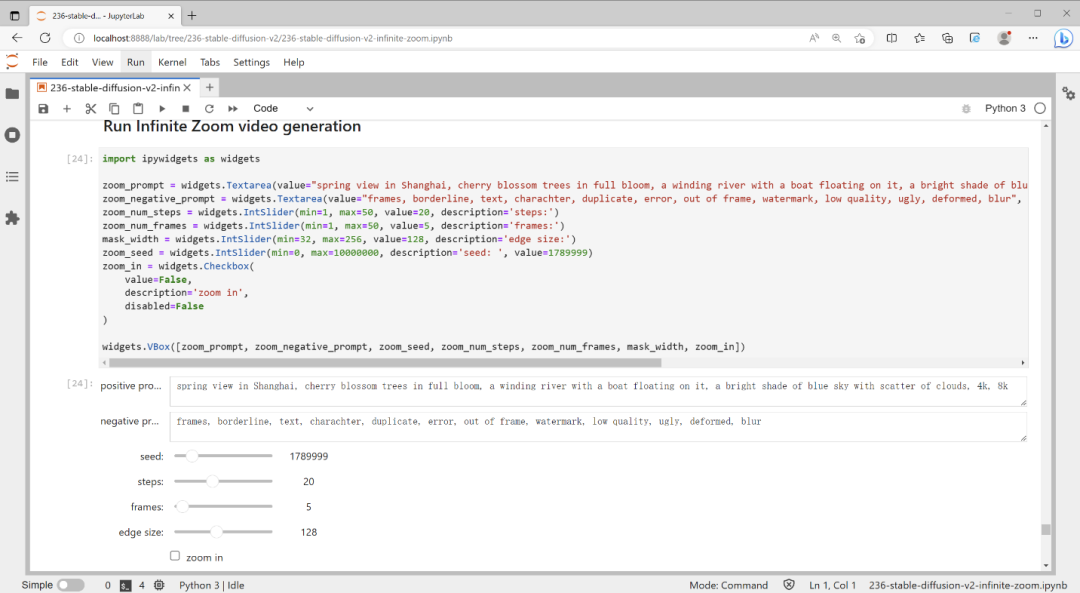
在这一步中,我把步骤设置为 20。理想情况下,我将使用 50,以提供最好看的结果。另外,这里还可以自行设置生成的图画数量,所有生成的图画将组合起来构成最后的无限缩放效果视频。当然,我们同样还生成了 GIF 文件,以便大家多种形式可视化展示生成结果。
最终结果。

结 论
当下,如果您想了解“Stable Diffusion”的工作原理,以及英特尔硬件的加速方式,OpenVINO Notebooks 无疑是首选。如果您有任何疑问或想要展示您的一些最佳成果,请在这里或通过我们的 GitHub 讨论板发表评论! 祝您编码快乐。
审核编辑 :李倩
-
将英特尔®独立显卡与OpenVINO™工具套件结合使用时,无法运行推理怎么解决?2025-03-05 802
-
使用PyTorch在英特尔独立显卡上训练模型2024-11-01 3441
-
支持140亿参数AI模型,229TOPS!英特尔重磅发布第一代车载独立显卡2024-08-12 15239
-
华擎推出AI QuickSet软件,支持英特尔锐炫Arc A系列显卡2024-05-11 1508
-
使用OpenVINO优化并部署训练好的YOLOv7模型2023-08-25 2986
-
在英特尔独立显卡上部署YOLOv5 v7.0版实时实例分割模型2022-12-20 6161
-
基于C#和OpenVINO™在英特尔独立显卡上部署PP-TinyPose模型2022-11-18 3935
-
英特尔推出锐炫A系列独立显卡 微星推出GeForce RTX 3090 Ti系列显卡2022-03-31 4845
-
介绍英特尔®分布式OpenVINO™工具包2021-07-26 1863
-
英特尔推出面向OEM市场的入门级Xe独立显卡2021-01-27 2745
-
英特尔Iris Xe MAX独立显卡性能公布2020-11-06 13671
-
英特尔推出了英特尔锐炬Xe MAX独立显卡2020-11-01 9919
-
英特尔独立显卡预计将在2020年正式推出 将采用全新的XeGPU2019-05-05 4066
-
英特尔高清显卡4600帮助2018-10-26 6873
全部0条评论

快来发表一下你的评论吧 !
