

MiniGPT-4,开源了!
描述
大家好,我是程序羊。
上个月GPT-4发布时,我曾写过一篇文章分享过有关GPT-4的几个关键信息。
当时的分享就提到了GPT-4的一个重要特性,那就是多模态能力。
比如发布会上演示的,输入一幅图(手套掉下去会怎么样?)。

GPT-4可以理解并输出给到:它会掉到木板上,并且球会被弹飞。
再比如给GPT-4一张长相奇怪的充电器图片,问为什么这很可笑?

GPT-4回答道,VGA 线充 iPhone。
用户甚至还可以直接画一个网站草图拍照丢给GPT-4,它就可以立马帮助生成代码。

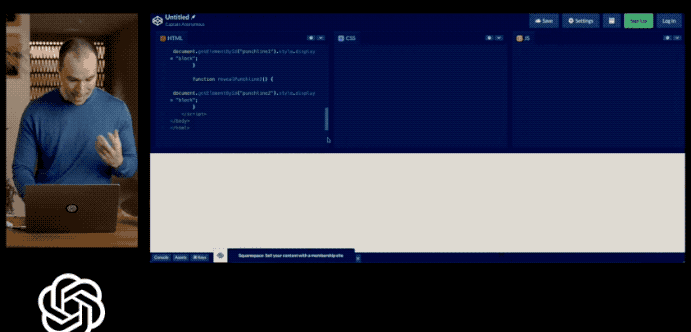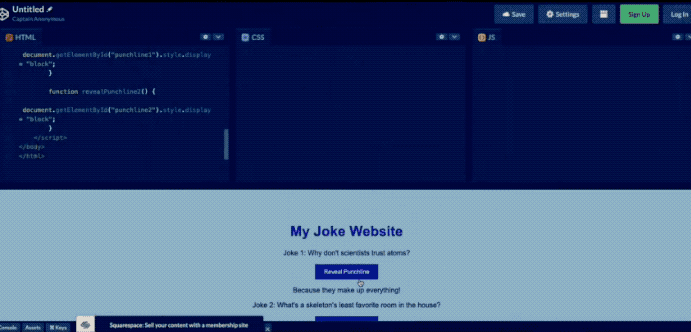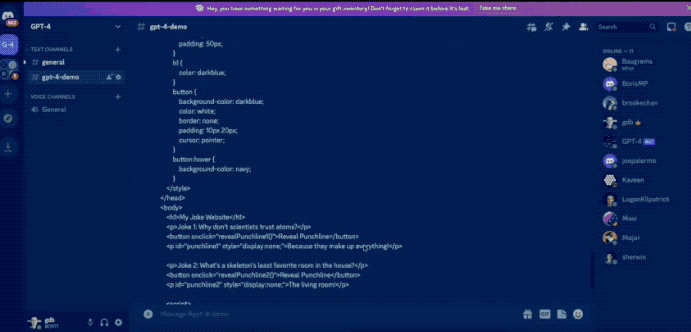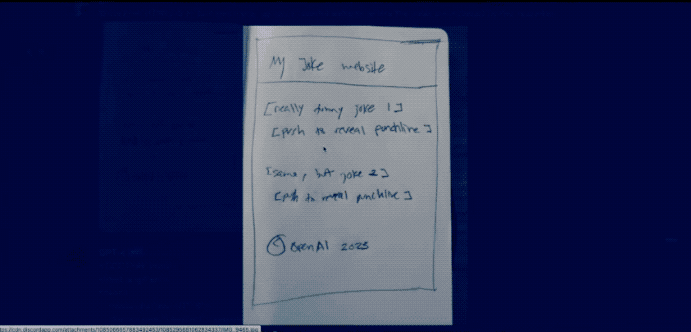
但是时间过去了这么久,GPT-4像这样的识图功能也迟迟没有开放。
就在大家都在等待这个功能开放的时候,一个名为MiniGPT-4的开源项目悄悄做了这件事情。
没错,就是为了增强视觉语言理解。
MiniGPT-4背后团队来自KAUST(沙特阿卜杜拉国王科技大学),项目是几位博士开发的。

项目除了是开源的之外,而且还提供了网页版的demo,用户可以直接进去体验。
在线体验:https://minigpt-4.github.io
GitHub仓库:https://github.com/Vision-CAIR/MiniGPT-4
论文:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
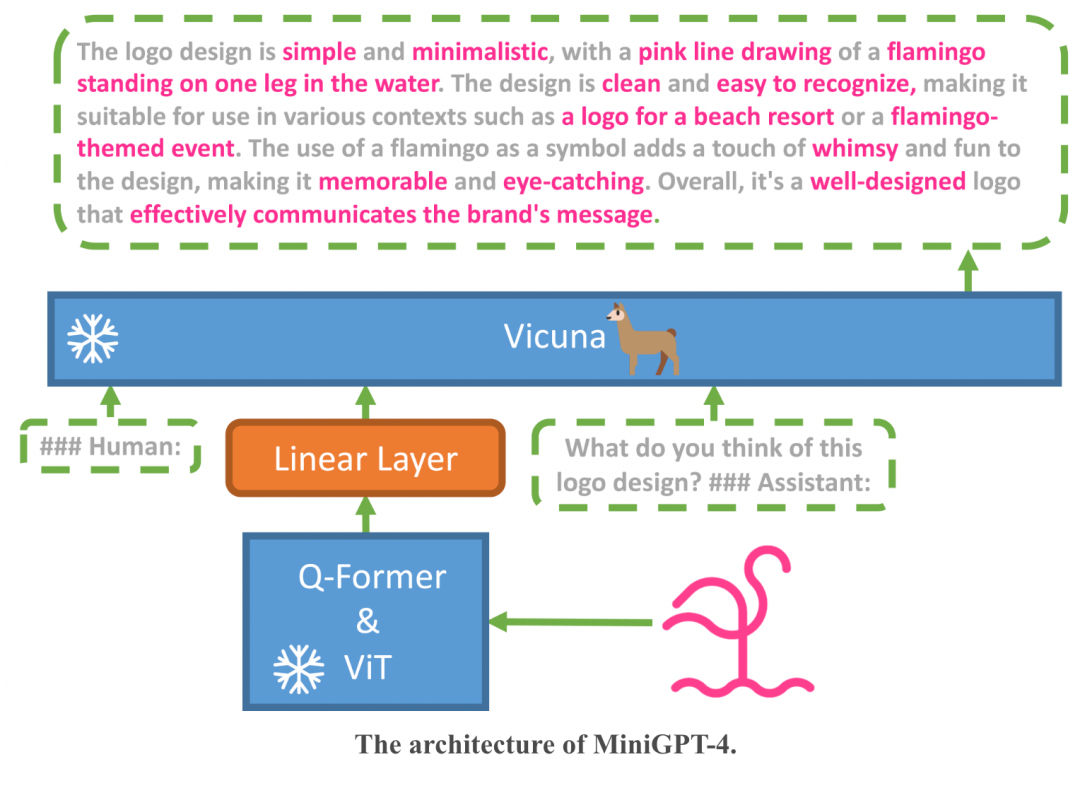
MiniGPT-4也是基于一些开源大模型来训练得到的。 团队把图像编码器与开源语言模型Vicuna(小羊驼)整合起来,并且冻结了两者的大部分参数,只需要训练很少一部分。
训练分为两个阶段。
传统预训练阶段,在4张A100上使用500万图文对,10个小时内就可以完成,此时训练出来的Vicuna已能够理解图像,但生成能力有限。
然后在第二个调优阶段再用一些小的高质量数据集进行训练。这时候的计算效率很高,单卡A100只需要7分钟。
并且团队正在准备一个更轻量级的版本,部署起来只需要23GB显存,这也就意味着未来可以在一些消费级的显卡中或许就可以进行本地训练了。
这里也给大家看几个例子。
比如丢一张食物的照片进去来获得菜谱。

或者给出一张商品的照片来让其帮忙写一篇文案。

当然也可以像之前GPT-4发布会上演示的那样,画出一个网页,让其帮忙生成代码。

可以说,GPT-4发布会上演示过的功能,MiniGPT-4基本也都有。
这一点可以说非常amazing了!
可能由于目前使用的人比较多,在MiniGPT-4网页demo上试用时会遇到排队的情况,需要在队列中等待。
但是用户也可以自行本地部署服务,过程并不复杂。
首先是下载项目&准备环境:
git clone https://github.com/Vision-CAIR/MiniGPT-4.git cd MiniGPT-4 conda env create -f environment.yml conda activate minigpt4
然后下载预训练模型:
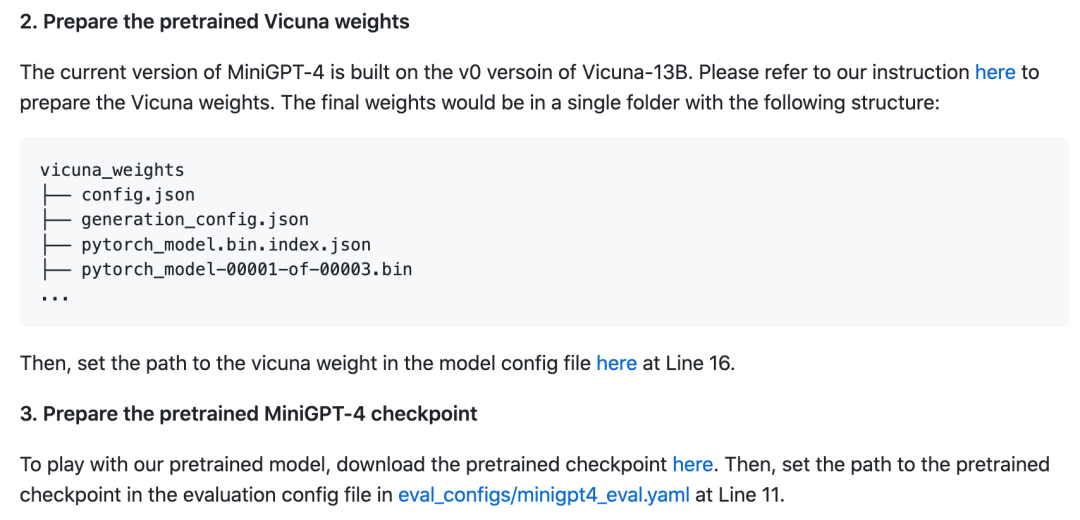
最后在本地启动Demo:
python demo.py --cfg-path eval_configs/minigpt4_eval.yaml
通过这个项目我们也再一次看出大模型在视觉领域的可行性,未来在图像、音频、视频等方面的应用前景应该也是非常不错的,我们可以期待一下。
审核编辑 :李倩
-
开源硬件板块正式开版了,回帖有奖!!!2013-10-07 120223
-
【开源】4G远程GPS定位器2023-05-30 1137
-
【开源】智慧气象盒子(4G_GPS)2023-06-05 1462
-
iOS版饿了么使用的开源项目2018-05-31 9684
-
4路交通灯开源项目2022-07-07 675
-
4位加法器开源分享2022-07-08 1035
-
iv-4数码时钟开源项目2022-07-11 586
-
名片大小4位时钟开源项目2022-07-12 707
-
树莓派4RGB帽子开源2022-07-25 823
-
模拟开关模块4通道开源2022-07-26 772
-
4ChannelLedStrip控制与Nodemcu开源分享2022-08-18 530
-
ProDOS ROM Drive v4开源2022-08-22 858
-
4乘4键盘开源分享2022-10-19 797
-
4位RTC时钟开源分享2022-10-31 734
-
4芯18650充电模块开源分享2023-06-09 2016
全部0条评论

快来发表一下你的评论吧 !
